操作系统 4.5-文件使用磁盘的实现
通过文件进行磁盘操作入口

// 在fs/read_write.c中
int sys_write(int fd, const char* buf, int count)
{
struct file *file = current->filp[fd];
struct m_inode *inode = file->inode;
if (S_ISREG(inode->i_mode))
return file_write(inode, file, buf, count);
}-
进程控制块(PCB):
-
current是指向当前进程控制块(PCB)的指针。PCB 包含了进程的所有信息,包括打开的文件列表。
-
-
文件指针数组(filp):
-
current->filp[fd]访问当前进程的文件指针数组,获取与文件描述符fd关联的file结构。
-
-
文件结构(file):
-
struct file包含了打开文件的所有信息,包括指向inode的指针。
-
-
inode 结构:
-
struct m_inode是文件的元数据结构,包含了文件的属性(如权限、大小、数据块位置等)。 -
inode->i_mode包含了文件的类型和权限信息。
-
-
文件写入操作:
-
file_write(inode, file, buf, count)是实际执行文件写入操作的函数,它将buf中的count字节数据写入到由inode和file描述的文件中。
-
-
文件类型检查:
-
S_ISREG(inode->i_mode)检查inode表示的是否是一个普通文件。如果是,才执行写入操作。
-
-
数据流和控制流:
-
图中展示了从
write(fd)调用开始,通过 PCB 和文件表,最终访问到inode和数据盘块的过程。
-
File_write

工作流程分析
-
确定要写入的字符段:
-
首先,需要确定要写入文件的字符段。这通常由文件的读写指针决定,该指针指示了文件中的当前位置。通过修改这个指针(例如使用
fseek),可以改变写入的起始位置,然后加上要写入的字符数量(count)来确定结束位置。
-
-
找到要写的盘块号:
-
确定了要写入的字符段后,下一步是找到这些字符对应的磁盘块号。这是通过文件的
inode结构来实现的,inode包含了文件的元数据,包括文件数据块的位置信息。
-
-
形成写入请求并执行写入:
-
使用找到的盘块号和要写入的数据(
buf),形成一个写入请求(request),然后将这个请求放入磁盘调度算法(如电梯算法)中进行处理,以优化磁盘I/O操作。
-
函数参数解释:
-
inode:-
这是一个指向文件的
inode结构的指针。inode包含了文件的元数据,如文件类型、权限、所有者、文件大小以及指向文件数据块的指针等。在写入操作中,inode用于查找文件数据块的位置。
-
-
file:-
这是一个指向文件结构的指针。文件结构包含了打开文件的所有信息,包括文件状态标志、文件的读写指针等。在写入操作中,
file结构用于获取文件的当前位置和状态。
-
-
buf:-
这是一个指向要写入文件的数据缓冲区的指针。
buf包含了实际要写入文件的数据。
-
-
count:-
这是一个整数,表示要写入文件的字节数。
count与buf参数一起,指定了要写入文件的数据量。
-
实现

以下是带有详细注解的 file_write 函数代码,解释了每一部分的功能和作用:
// file_write函数用于将数据从用户缓冲区写入到文件对应的磁盘块中
int file_write(struct m_inode *inode, struct file *filp, char *buf, int count)
{
off_t pos; // 定义一个变量pos,用于记录写入文件的起始位置
// 根据文件的读写标志(O_APPEND)和当前文件位置(filp->f_pos)确定写入的起始位置
if (filp->f_flags & O_APPEND)
pos = inode->i_size; // 如果设置了追加标志,则从文件末尾开始写入
else
pos = filp->f_pos; // 否则,从文件当前位置开始写入
// 当还有字节需要写入时,继续循环
while (i < count) {
block = create_block(inode, pos / BLOCK_SIZE); // 创建或分配一个新的磁盘块
bh = bread(inode->i_dev, block); // 读取指定的磁盘块到内存中,并将块地址存储在bh中
int c = pos % BLOCK_SIZE; // 计算当前块内的偏移
char *pc = c + bh->b_data; // 计算内存中块数据区域的起始地址
bh->b_dirt = 1; // 标记块为脏块,表示该块已被修改,需要写回磁盘
c = BLOCK_SIZE - c; // 计算剩余需要写入的字节数
pos += c; // 更新文件位置
// 将用户缓冲区buf中的数据逐字节写入到内存中的块数据区域bh->b_data
while (c-- > 0)
*(pc++) = get_fs_byte(buf++);
brelse(bh); // 释放缓冲区,将其返回到缓冲区管理中
}
filp->f_pos = pos; // 更新文件的当前位置
}-
确定写入位置:
-
通过检查文件的读写标志和当前文件位置,确定写入操作的起始位置。
-
-
循环写入数据:
-
使用
while循环,根据要写入的字节数count,逐块写入数据。
-
-
创建和读取磁盘块:
-
create_block函数用于创建或分配一个新的磁盘块。 -
bread函数用于读取指定的磁盘块到内存中,并将块地址存储在bh(缓冲头)中。
-
-
计算块内偏移和剩余字节数:
-
计算当前块内的偏移
c和剩余需要写入的字节数。
-
-
写入数据:
-
将用户缓冲区
buf中的数据逐字节写入到内存中的块数据区域bh->b_data。
-
-
标记块为脏块:
-
将
bh->b_dirt设置为 1,表示该块已被修改,需要写回磁盘。
-
-
释放缓冲区:
-
使用
brelse函数释放缓冲区,将其返回到缓冲区管理中。
-
-
更新文件位置:
-
更新文件的当前位置
filp->f_pos,以便后续操作可以从正确的位置开始。
-
通过这些步骤,file_write 函数实现了将用户数据写入文件的完整过程,包括确定写入位置、创建和读取磁盘块、写入数据、标记块为脏块以及更新文件位置等。
Create_block

图中展示了 create_block 函数和 _bmap 函数的代码,这些函数用于在文件系统中创建和映射磁盘块。以下是提取的代码和注解:
提取的代码:
// create_block函数用于根据inode和块号分配或创建一个新的磁盘块
int create_block(struct m_inode *inode, int block)
{
while (i < count) {
block = create_block(inode, pos / BLOCK_SIZE);
bh = bread(inode->i_dev, block);
}
int _bmap(m_inode *inode, int block, int create)
{
if (block < 7) {
if (create && !inode->i_zone[block]) {
inode->i_zone[block] = new_block(inode->i_dev);
inode->i_ctime = CURRENT_TIME;
inode->i_dirt = 1;
}
return inode->i_zone[block];
}
block -= 7;
if (block < 512) {
bh = bread(inode->i_dev, inode->i_zone[7]);
return (bh->b_data)[block];
}
}
}代码注解:
-
create_block函数:
-
这个函数用于根据给定的
inode和块号block分配或创建一个新的磁盘块。 -
它通过调用
_bmap函数来实现块的映射和创建。
-
-
_bmap函数:
-
这是一个辅助函数,用于处理块号的映射。
-
它首先检查块号是否小于7,这7个块号直接存储在
inode的i_zone数组中。 -
如果块号小于7,并且需要创建新块(
create为真且当前块号未分配),则调用new_block函数分配新块,更新inode的i_ctime和i_dirt标志。 -
如果块号大于等于7且小于512,表示这是一个一重间接块,需要读取间接块表并找到对应的块号。
-
-
new_block函数:
-
这个函数用于分配一个新的磁盘块。具体实现未在图中展示,但通常涉及查找空闲块、分配块号等操作。
-
-
bread函数:
-
这个函数用于读取指定的磁盘块到内存中。它将块地址存储在
bh(缓冲头)中,以便后续操作。
-
总结:
这段代码实现了文件系统中磁盘块的分配和映射机制。通过 create_block 和 _bmap 函数,系统可以根据文件的 inode 和块号动态分配和映射磁盘块。这种机制支持文件的动态增长和高效的磁盘空间管理。
通过间接块表(如一重间接和二重间接块表),文件系统还可以支持非常大的文件,即使单个文件的数据量超过了直接块表所能表示的范围。
m_inode

图中展示了与设备文件的 inode 结构相关的代码,以及如何通过 sys_open 函数打开设备文件。以下是提取的代码和注解:
提取的代码:
// m_inode结构体定义,用于表示设备文件的inode
struct m_inode {
unsigned short i_mode; // 文件的类型和属性
unsigned short i_zone[9]; // 指向文件内容数据块
struct task_struct *i_wait; // 多个进程共享的打开这个inode,有的进程等待...
unsigned short i_count; //
unsigned char i_lock; //
unsigned char i_dirt; //
};
// sys_open函数用于打开文件或设备
int sys_open(const char* filename, int flag)
{
if (S_ISCHR(inode->i_mode)) { // 检查是否为字符设备文件
if (MAJOR(inode->i_zone[0]) == 4) { // 检查设备文件类型
current->tty = MINOR(inode->i_zone[0]); // 设置当前进程的tty
}
}
}
// 宏定义,用于从设备号中提取主设备号和次设备号
#define MAJOR(a) ((((unsigned)(a)) >> 8)) // 取高字节
#define MINOR(a) ((a) & 0xff) // 取低字节代码注解:
-
m_inode结构体:
-
i_mode:表示文件的类型和属性,例如普通文件、目录、字符设备等。 -
i_zone:一个数组,用于存储指向文件内容数据块的指针或设备号等信息。 -
i_wait:指向等待该inode的进程的task_struct结构体。 -
i_count:表示当前有多少个进程打开了该inode。 -
i_lock:用于控制对inode的访问,防止并发访问导致的问题。 -
i_dirt:表示inode是否被修改,需要写回磁盘。
-
-
sys_open函数:
-
该函数用于打开文件或设备。
-
S_ISCHR(inode->i_mode):检查文件是否为字符设备文件。 -
MAJOR(inode->i_zone[0])和MINOR(inode->i_zone[0]):从设备号中提取主设备号和次设备号。 -
current->tty:设置当前进程的tty(终端设备)。
-
-
宏定义:
-
MAJOR(a):从设备号中提取主设备号(高字节)。 -
MINOR(a):从设备号中提取次设备号(低字节)。
-
总结:
这段代码展示了如何使用 m_inode 结构体来表示设备文件的inode,并演示了如何通过 sys_open 函数打开设备文件。
文件视图的两条路
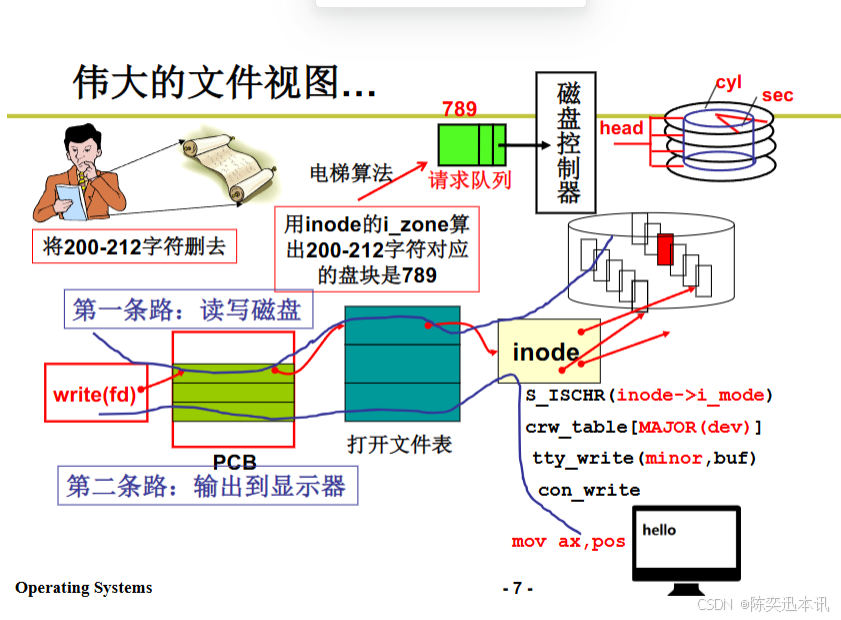
读写磁盘的过程:
-
用户发起文件操作
-
用户通过
write或read系统调用操作文件。 -
传递参数:文件描述符(FD)、内存缓冲区(buff)、操作字节数(count)。
-
-
系统调用转换
-
write调用内核中的sys_write,read调用sys_read。 -
需要获取文件的
inode(索引节点)信息。
-
-
计算目标磁盘块
-
通过文件结构
file获取文件指针f_pos,确定字符流中的位置。 -
根据
inode及索引结构,计算出对应的磁盘块号(block)。 -
采用直接索引、一级索引、二级索引等方式解析出数据块。
-
-
磁盘操作
-
读操作:调用
bread()读取磁盘数据到缓存,再复制到用户缓冲区。 -
写操作:调用
bwrite()将用户缓冲区数据写入磁盘缓存,并同步到磁盘。
-
-
磁盘调度与完成
-
磁盘请求加入电梯调度队列。
-
设备驱动完成磁盘读写,系统中断通知完成。
-
若是写操作,需更新
f_pos以维护文件流的连续性。
-
输出到显示器的过程:
-
用户发起输出请求
-
例如
printf()、write(1, buff, count),其中1代表标准输出(stdout)。
-
-
系统调用转换
-
进入内核,调用
sys_write处理。 -
识别文件描述符
1代表标准输出(显示器)。
-
-
数据传输到终端设备
-
由于 stdout 不是磁盘文件,而是字符设备,直接走
tty终端驱动。 -
终端驱动
tty_write处理输出,将数据放入tty缓冲区。
-
-
驱动程序与硬件交互
-
tty设备驱动调用console_driver,执行putc()逐字符输出到屏幕。 -
可能涉及
VGA、framebuffer或UART串口等设备。
-
-
显示完成
-
终端驱动完成数据输出,可能触发屏幕刷新或回显。
-
若是行缓冲模式,遇到
\n或缓冲区满才实际输出。
-
对比总结:
-
读写磁盘涉及块设备(block device),数据按块存取,可能需要磁盘调度与缓冲管理。
-
输出到显示器涉及字符设备(char device),数据按字符流传输,即时性更强。
-
两者都通过系统调用进入内核,但处理方式不同,磁盘用
bread/bwrite,显示器用tty_write。
