【C++】Cplusplus进阶
模板的进阶:
非类型模板参数
是C++模板中允许使用具体值(而非类型)作为模板参数的特性。它们必须是编译时常量,且类型仅限于整型、枚举、指针、引用。(char也行)

 STL标准库里面也使用了非类型的模板参数。
STL标准库里面也使用了非类型的模板参数。
// 非类型模板参数示例:固定大小的数组
template <typename T, int Size>
class FixedArray
{
private:
T data[Size];
public:
T& operator[](int index)
{
return data[index];
}
constexpr int getSize() const
{
return Size;
}
};
int main() {
FixedArray<int, 5> arr; // Size=5在编译时确定
arr[2] = 42;
static_assert(arr.getSize() == 5);
} 在 C++ 标准中,非类型模板参数不能直接使用 std::string,但可以使用字符数组或字符指针的形式间接实现类似效果。
template<const char* str>
struct MyTemplate { /* ... */ };
// 定义外部链接的字符数组(C++17 起可用)
extern const char my_str[] = "Hello";
MyTemplate<my_str> obj; // 合法模板特化
是C++中针对特定类型或条件提供定制化模板实现的技术,就是模板的特殊化处理,特化不能单独存在。它分为全特化和偏特化,两种形式。
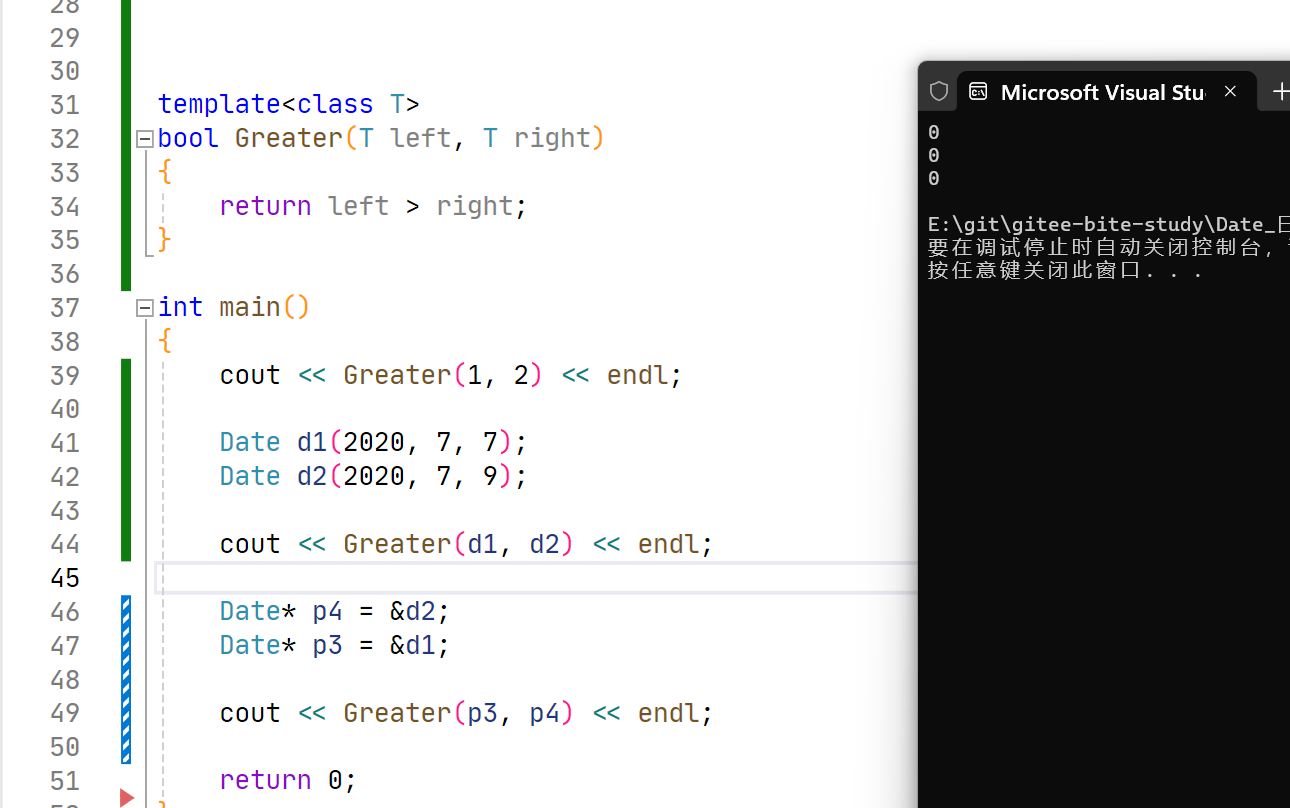
这里最后一次比较,其实变成了指针与指针比较,比较的是地址的大小。那么这里如果要让指针里面的数据进行比较,那么就要用到模板的特化。
template<class T>
bool Greater(T left, T right)
{
return left > right;
}
template<>
bool Greater<Date*>(Date* left,Date* right)
{
return *left > *right;
}这样走Date* 比较的时候,就会走第二个模板函数。
除了函数能特化,类也可以特化。
template<class T>
struct Less
{
bool operator()(const T& x1,const T& x2) const
{
return x1 < x2;
}
};
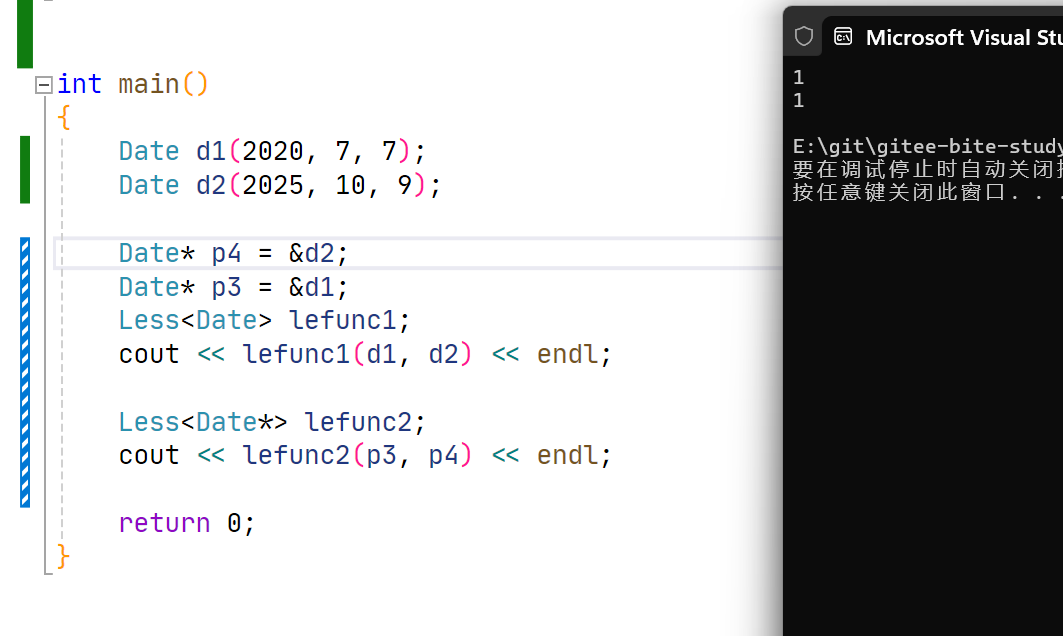
template<>
struct Less<Date*>
{
bool operator()(Date* x1,Date * x2) const
{
return *x1 < *x2;
}
};
上面仿函数也可以使用class,但是要注意在public下面操作,不然调不到函数。
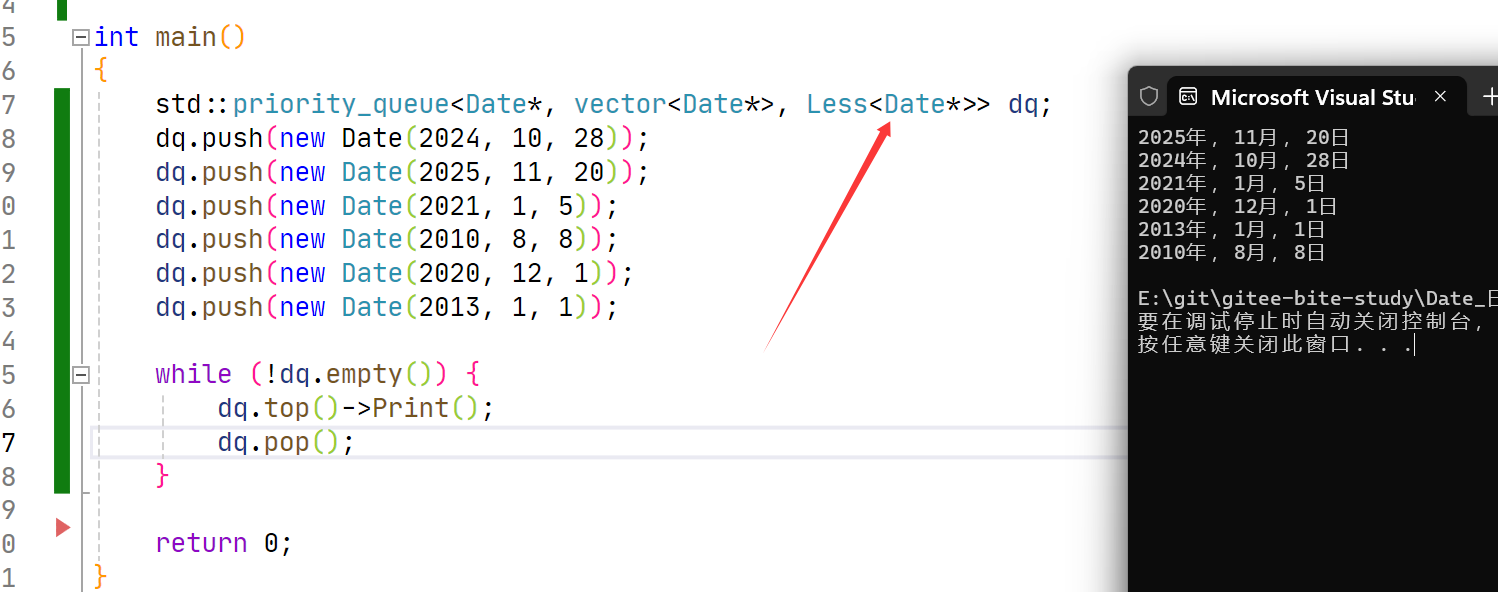
这里使用STL库里面的优先级队列,用自己写的模板特化,发现也是可以使用的。
偏特化
允许为模板参数的一部分或特定条件提供特殊实现。它适用于类模板,但不支持函数模板。
// 通用模板
template <class T, class U>
class MyClass
{
public:
void print() { cout << "General template\n"; }
};
// 偏特化:当第二个参数为 int 时
template <class T>
class MyClass<T, int>
{
public:
void print() { cout << "Partial specialization (U = int)\n"; }
};
// 偏特化:当两个参数均为指针类型时
template <class T, class U>
class MyClass<T*, U*>
{
public:
void print() { cout << "Partial specialization (both pointers)\n"; }
};
// 使用示例
int main()
{
MyClass<double, char> a; // 通用模板
MyClass<float, int> b; // 偏特化(U = int)
MyClass<int*, double*> c; // 偏特化(指针类型)
a.print(); // 输出: General template
b.print(); // 输出: Partial specialization (U = int)
c.print(); // 输出: Partial specialization (both pointers)
}template <class T, class U>
class MyClass<T&, U&>
{
public:
void print() { cout << " T& , U& \n"; }
};模板不支持分离编译
声明(.h),定义(.cpp)分离。

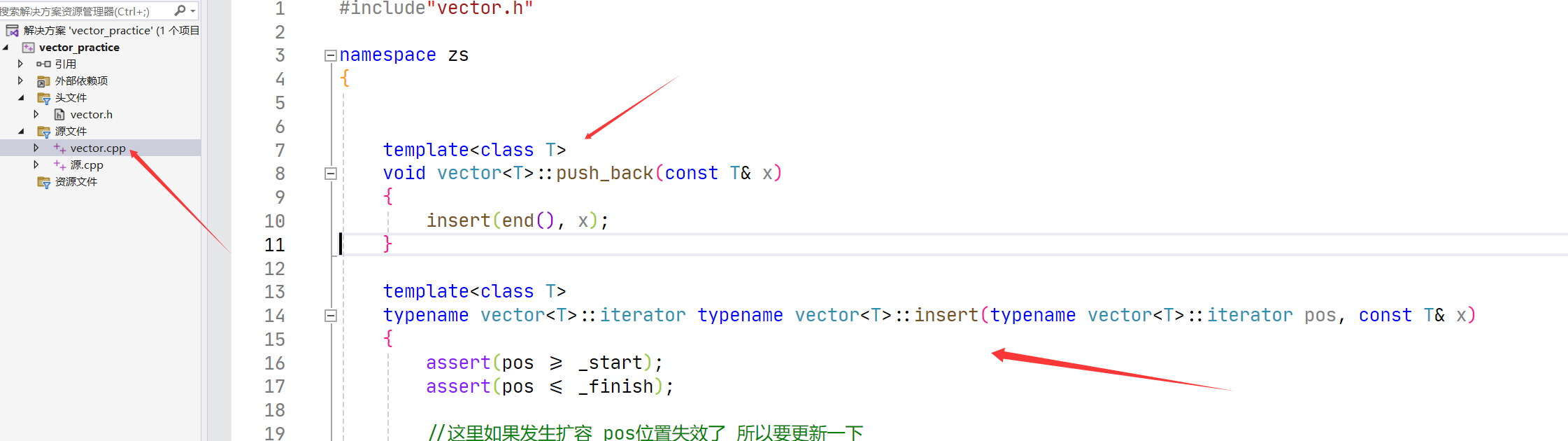
PS:模板在同一文件下可以类外定义。
在类模板中使用typename关键字加在内嵌类型(iterator)前是为了告诉编译器该名称是一个类型,而非静态成员或变量。这种情况发生在模板参数未实例化时,当访问嵌套的依赖类型时,必须使用typename消除歧义。
zs : : vector<T> : : iterator ,这里要加 typename 。不然编译器区分不清楚这里是类型还是变量。因为静态函数、变量也可以指定类域就可以访问。
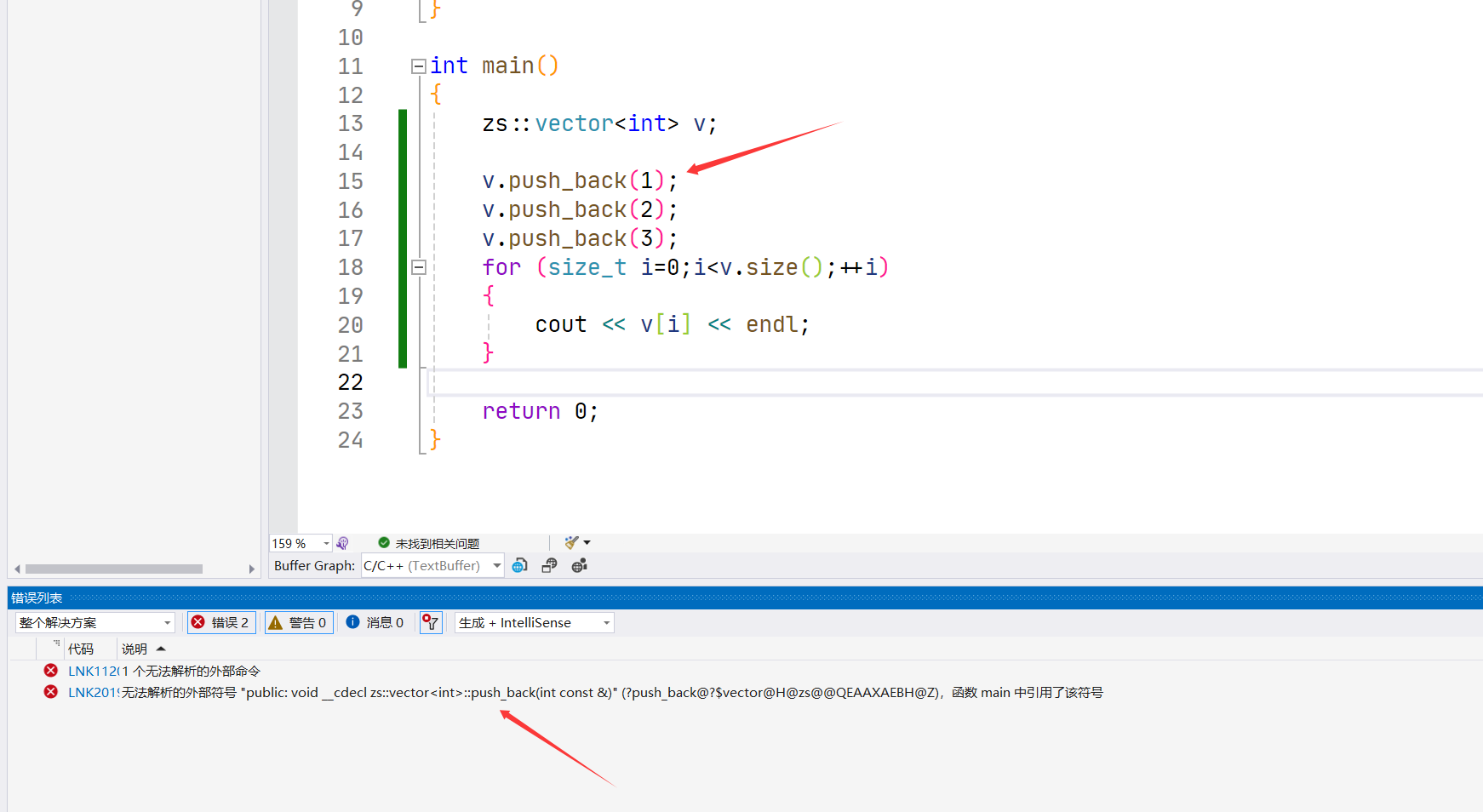
这里把push_back() 分开定义后,使用出现链接错误。

因为构造函数、size()函数、operator[ ],在vector.h中有定义,所以vector 实例化 v 的时候,这些成员函数同时实例化,直接就有定义。编译阶段直接确定地址。
而 push_back()、insert()在 vector.h 中只有声明,没有定义。那么只有在链接阶段去确认地址。
但是这里 vector.cpp 中模板类型的 T 无法确定,所以没有实例化,就无法进入符号表。进入不了符号表后面链接阶段就会发生错误。
根本原理:
C++标准规定模板是编译期多态机制,编译器需要根据调用处的具体类型生成代码。若模板实现不可见(如分离到.cpp文件),则无法完成实例化。
解决方案:
1.模板声明和定义不要分离到 .h 和 .cpp (推荐)。
2.在cpp 显示实例化。(不推荐,换个类型就要实例化一次,麻烦)

模板总结:
一、优点:
- 类型安全:模板在编译期进行类型检查,比宏更安全(如
std::vector<int>只能存储int类型)- 代码重用:通过泛型编程减少重复代码(如一个
max()模板可处理int/double/string等类型)- 零运行时开销:模板实例化在编译期完成,无额外运行时成本
- 高性能泛型算法:STL算法(如sort)能针对不同类型生成优化代码
二、缺点:
- 编译错误晦涩:类型不匹配时错误信息冗长(如缺少某个成员函数的错误可能长达数十行)
- 编译时间膨胀:每个模板实例化都会生成新代码,大型项目编译时间显著增加
- 代码膨胀风险:多个类型实例化可能导致二进制文件增大(如vector<int>和vector<string>会生成两份代码)
- 调试困难:调试器难以跟踪模板实例化代码
C++的继承:
C++继承是面向对象编程的核心机制之一,允许派生类复用基类的属性和方法,同时扩展或修改其行为。
一个学校里面,人有很多种身份,比如学生、老师、校长、保洁工作人员等。他们有共同的特点也有不同的地方。那么如果对每个人单独的来写一份代码以表明其全部特征,那么代码会非常的冗余。
因为其作为人这个个体在很多的特征上是相似的,那么使用C++的继承就可以很好的解决这方面的问题。
// 基类:个人
class Person
{
public:
string name;
int age;
string gender;
void display() const
{
cout << "姓名: " << name << "\n年龄: " << age
<< "\n性别: " << gender << endl;
}
};
// 学生类
class Student : public Person
{
private:
string studentID;
};
// 教师类
class Teacher : public Person {
private:
string employeeID;
};继承允许一个类(派生类,student,teacher )基于另一个类(基类,Person )来创建,从而获得基类的属性和方法,同时可以添加新的特性或覆盖已有的方法。
基本语法,派生类通过冒号后跟访问说明符(如public、protected、private)和基类名称来继承基类。
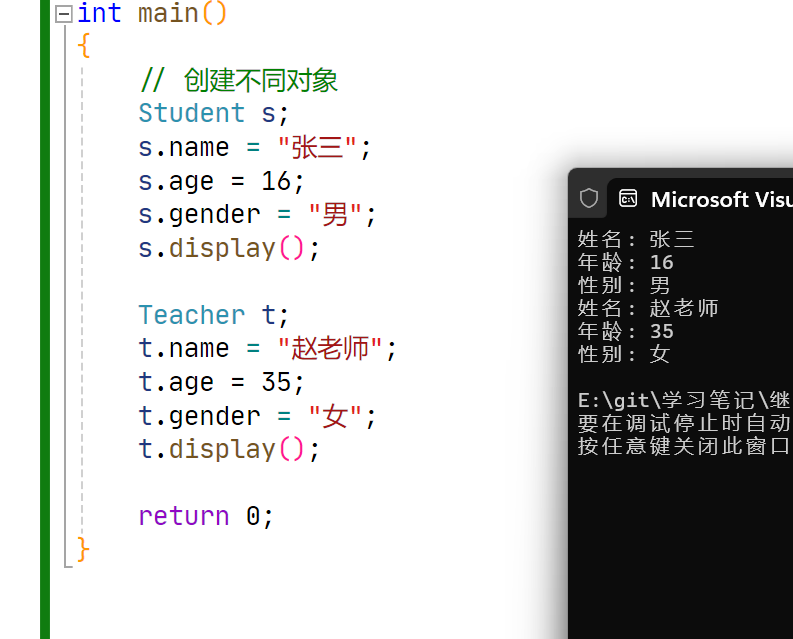
派生类既有基类的属性 (name、age、 gender),也有自己拓展的属性( studentID、employeeID )。
代码复用:继承允许派生类直接使用基类的成员(变量和函数),避免重复编写相同逻辑。
层次化建模:通过继承表达现实世界的分类关系(如"动物→哺乳动物→狗"),使代码结构更符合逻辑认知。
继承方式:
public、protected和private继承。public继承是最常用的,它保持基类成员的访问权限不变。protected继承会将基类的public和protected成员变为派生类的protected成员。private继承则将所有基类成员变为派生类的private成员。这些不同继承方式会影响派生类及其后续派生类对基类成员的访问权限。
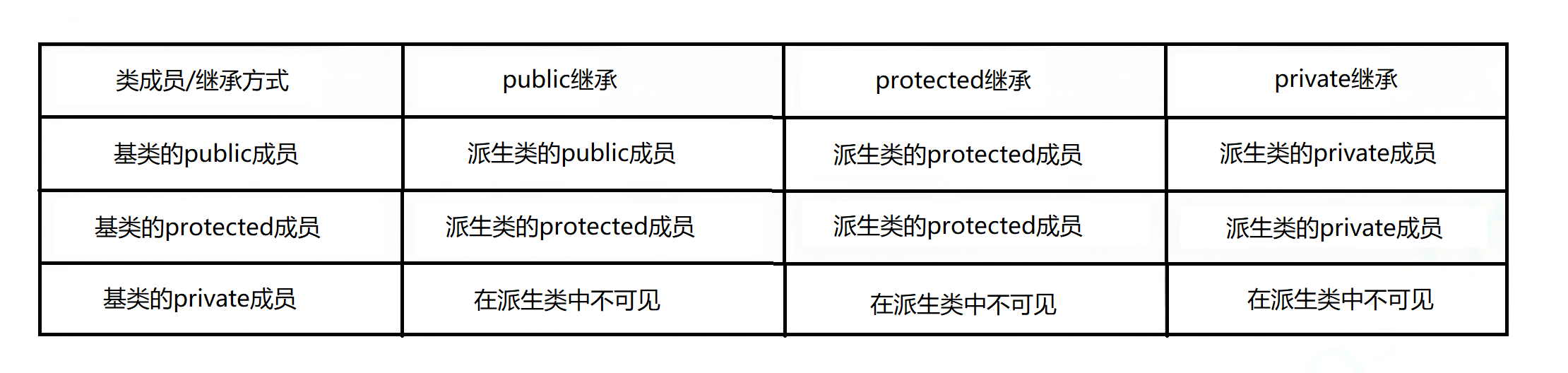
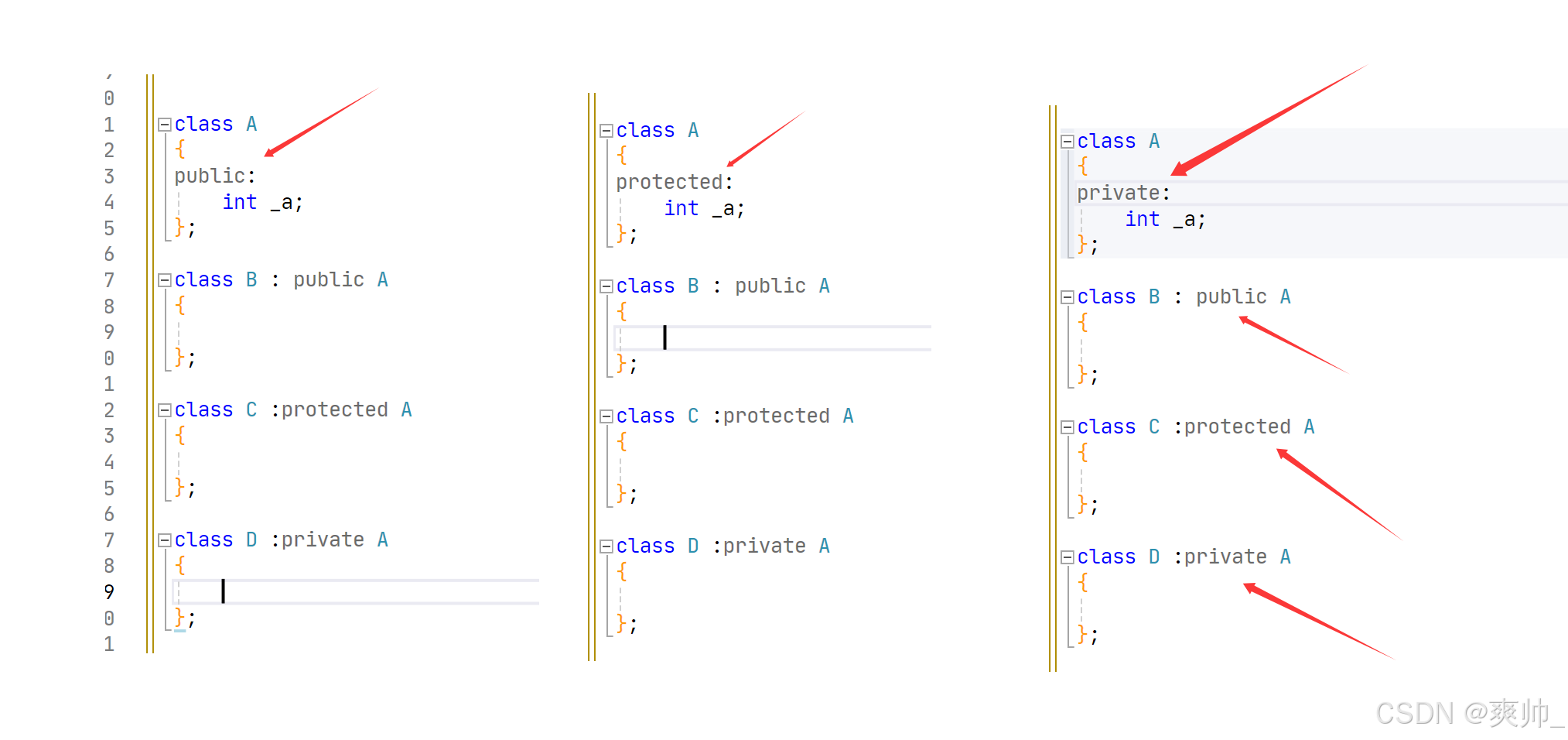
其实有规律,直接由权限更小的那个控制。实际上就只有public继承用的比较多。
protected\priveate:类外不能访问,类里面可以访问。
不可见:隐身,类里面外面都无法访问。
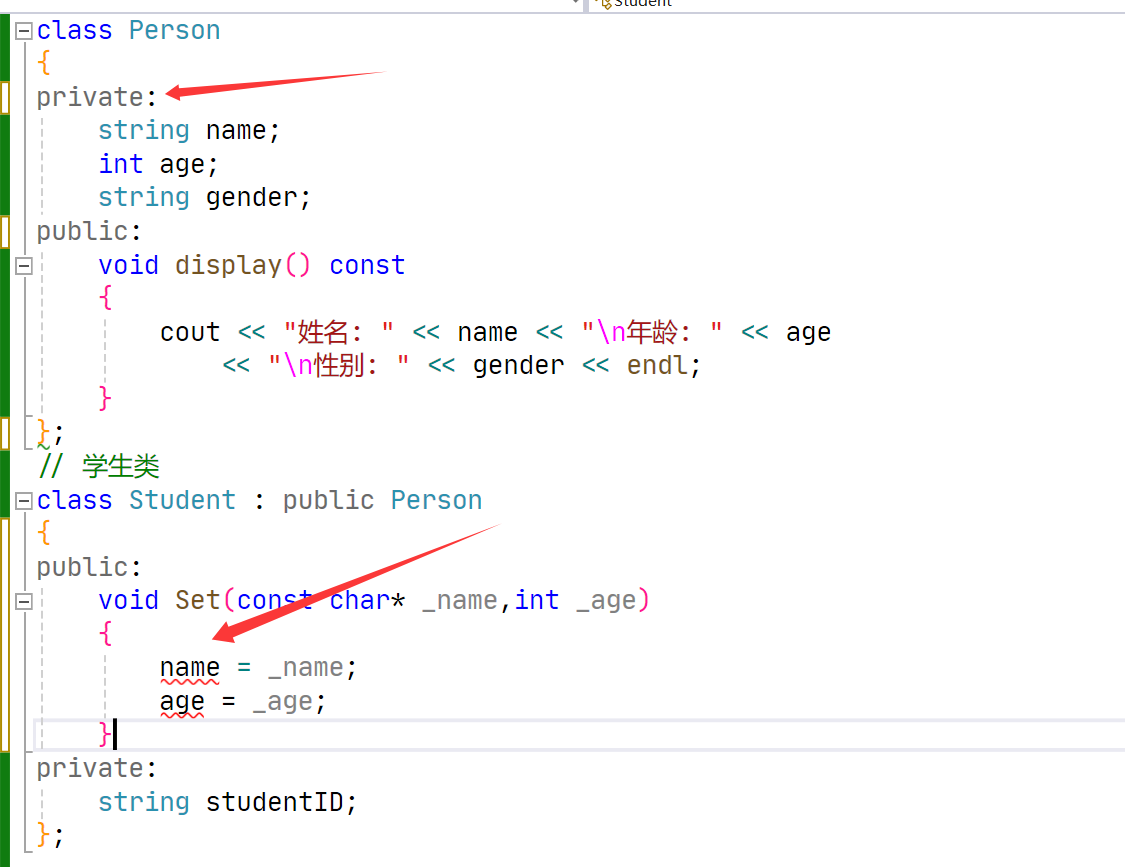
私有成员的意义:不想被子类继承的成员。
基类中想给子类复用,但是又不想暴露直接访问的成员,就应该定义成保护
class Parent
{
public:
string name = "Parent";
};
class Child : public Parent
{
public:
string name = "Child"; // 隐藏父类的name
void printNames()
{
cout << "子类 name: " << name << endl; // 输出 Child
cout << "父类 name: " << Parent::name << endl; // 输出 Parent
}
};
int main()
{
Child obj;
obj.printNames();
return 0;
} 
当子类和父类都定义了同名成员变量name时,子类会隐藏父类的同名成员。若需访问父类成员,需通过作用域解析运算符显式指明。
1.在继承体系中基类和派生类都有独立的作用域。
2.子类和父类中有同名成员,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫隐藏,也叫重定义。(在子类成员函数中,可以使用 基类::基类成员 显示访问)
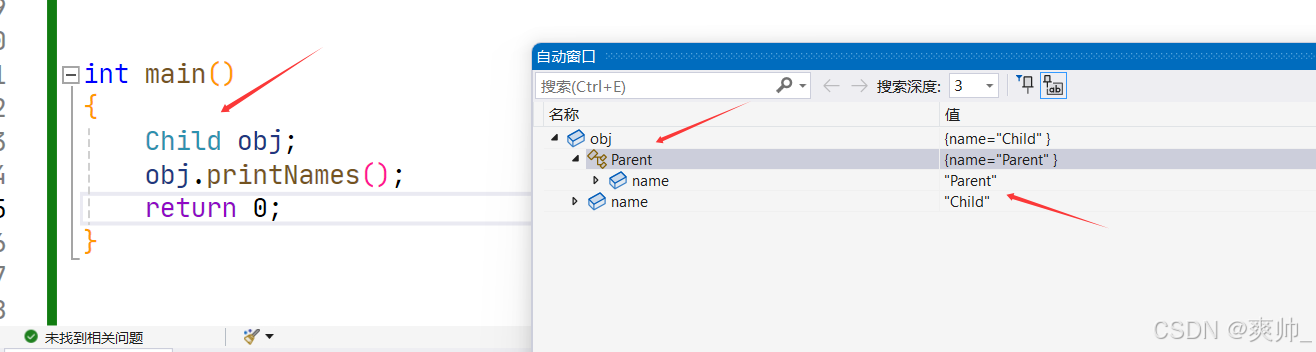 实际上的内存存储中,子类对象包含了基类的数据(name)。.
实际上的内存存储中,子类对象包含了基类的数据(name)。.
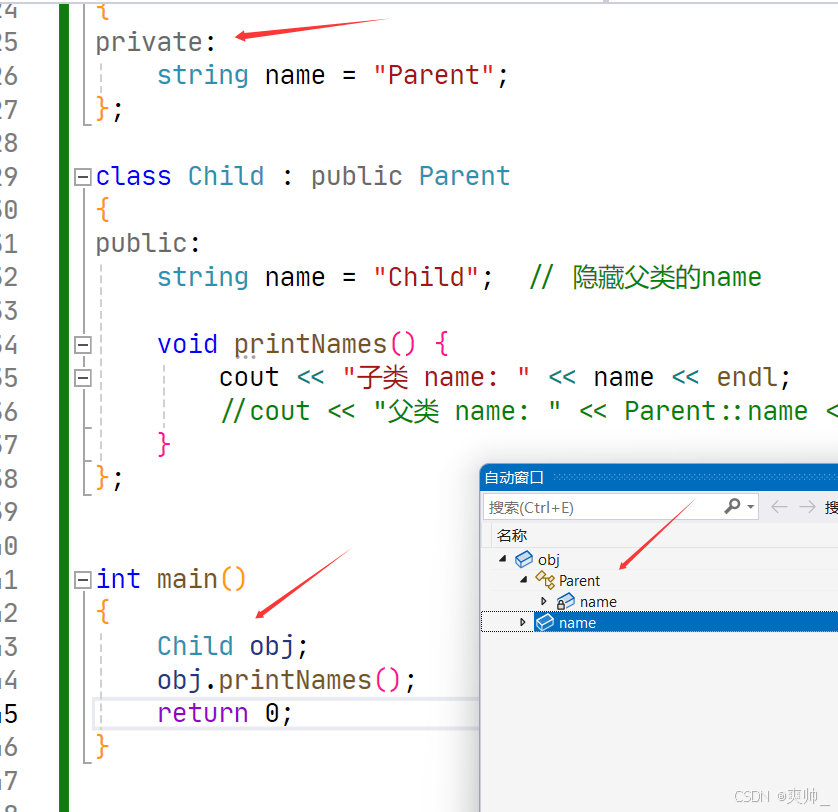
若父类的name是private:
此时子类定义的name是独立的新成员,不会产生命名冲突(但父类成员仍然存在,只是不可直接访问)。
class A
{
public:
void func()
{
cout << "fucn()" << endl;
}
};
class B : public A
{
public:
void func(int i)
{
cout << "func(int i)->" << endl;
}
}; 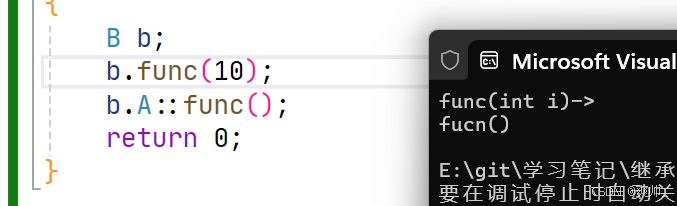
有的地方就会提问这里两个 func() 是不是构造函数重载?因为这里是两个不同的类域,所以其构成隐藏。
当子类对象赋值给父类对象时,会发生对象切片(切割)。这个过程会自动截断子类特有的成员,只保留父类部分。

子类对象可以赋值给父类对象/指针/引用。这里虽然是不同类型,但是不是隐式类型转换。赋值兼容转换,第三个就能看出来,这里是个特殊支持,语法天然支持。
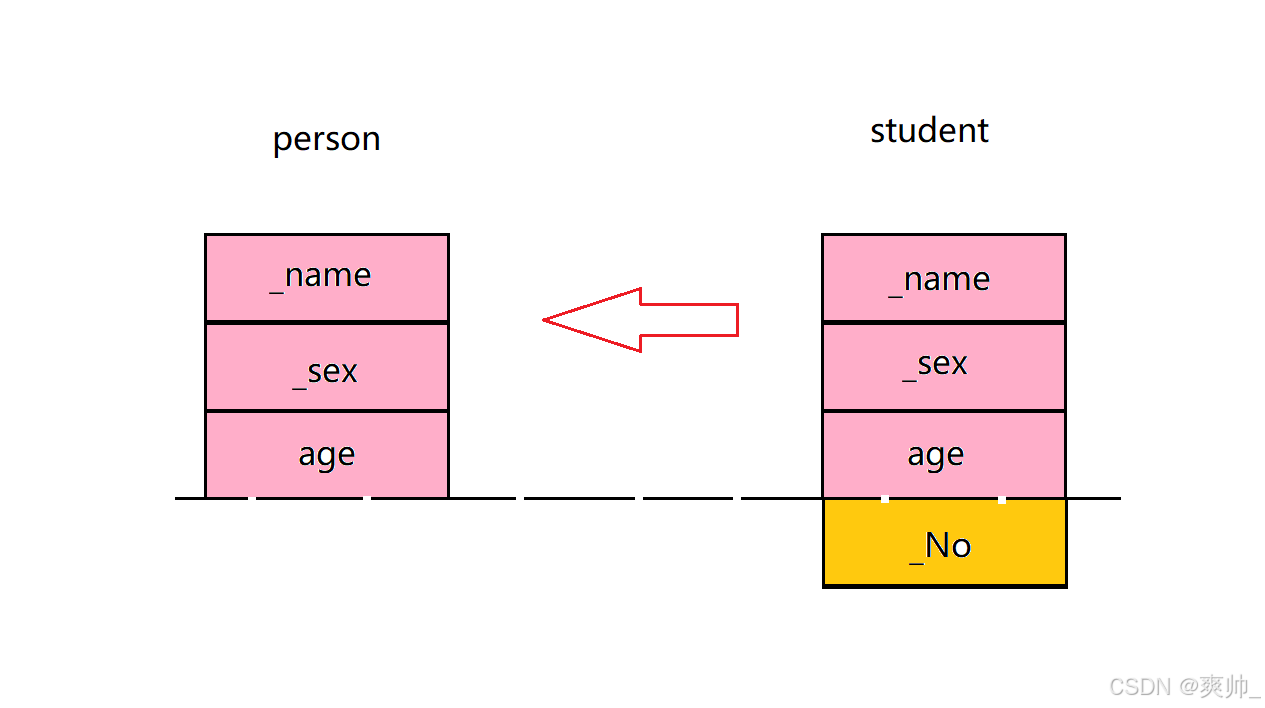
子类切割对象赋值给父类,但是不能把父类对象反向赋值给子类对象。
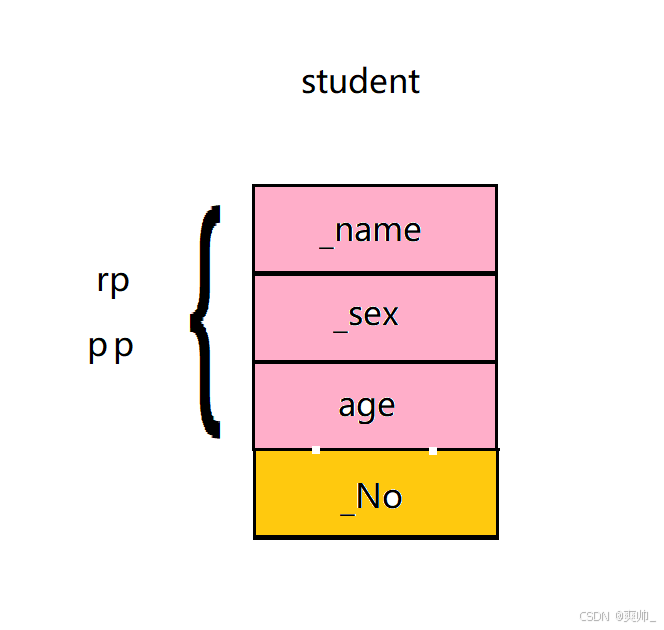
指针或者引用,其指向父类那一部分的地址或者是那一部分的别名。
继承关系中的默认函数表现:
子类编译器默认生成的 构造函数:
1、自己的成员,跟类和对象一样。内置类型不处理,自定义类型调用它自己的默认构造。
2、继承父类成员,必须调用父类的构造函数初始化。
class Person
{
public:
string _name;
string _sex;
int _age;
Person(const char* name)
:_name(name)
,_sex("男")
,_age(10)
{
cout << "Person()" << endl;
}
};
// 学生类
class Student : public Person
{
public:
int _num;
Student(const char* name, int num)
:Person(name) /*显式调用父类构造函数*/
, _num(num)
{
cout << "Studet()" << endl;
}
};
int main()
{
Student s1("张三",001);
return 0;
}

注意上面子类再初始化列表里,调用父类的构造函数,初始化继承成员。
子类编译器生成默认生成的 拷贝构造:
1、自己成员,跟类和对象一样。内置类型值拷贝,自定义类型调用它的拷贝构造。
2、继承的父类成员,必须调用父类拷贝构造初始化。
Person(const Person& p)
:_name(p._name)
,_sex(p._sex)
,_age(p._age)
{
cout << "Person(const Person& )" << endl;
}
Student(const Student& s)
:Person(s) /*子类成员拷贝*/
,_num(s._num)
{
cout << "Studet(const Student& )" << endl;
}
int main()
{
Student s1("张三",001);
Student st2(s1);
return 0;
} 
这里子类拷贝构造函数(Student(const Student& s))初始化列表位置,传入基类拷贝构造函数(Person(const Person& p) )的参数,直接使用了子类对象(s)。这里其实是前面切片的应用。
子类编译器默认生成的 赋值运算符:
1、自己成员,跟类和对象一样。内置类型值拷贝,自定义类型调用它 operator= 的。
2、继承的父类成员,必须调用父类的 operator=
Person& operator=(const Person& p)
{
cout << "Person& operator=(const Person& )" << endl;
_name = p._name;
_sex = p._sex;
_age = p._age;
return *this;
}
Student& operator=(const Student& s)
{
if (this != &s)
{
Person::operator=(s); // 调用父类赋值
_num = s._num;
}
cout << "Student& operator=(const Student& )" << endl;
return *this;
}
int main()
{
Student s1("张三",001);
Student st2(s1);
Student st3("李四",002);
st2 = st3;
return 0;
} 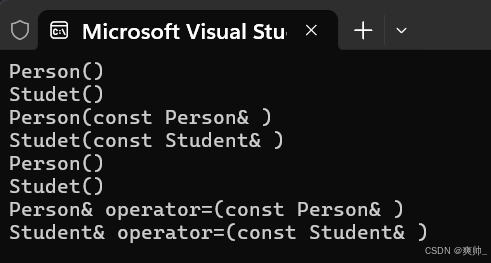
这里有个注意的点,调用父类的赋值运算符时要使用类域指定,如果不指定类域,子类默认会去调用自己的赋值运算符,构成死循环。
子类编译器默认生成的 析构函数:
1、自己的成员内置类型不处理,自定义类型调用它的析构函数。
2、继承父类的成员,调用父类析构函数处理。
~Person()
{
cout << "~Person" << endl;
}
~Student()
{
Person::~Person();
cout << "~Student() " << endl;
//...
}
子类的析构函数跟父类的析构函数构成隐藏。直接调用调不到,要指定类域。

这里会发现Peson的构造函数调用了三次但是,析构函数调用了六次。这里其实是因为析构函数很特殊。不需要去显示的掉用基类的析构函数,编译器会自己自动的去调用。
~Student()
{
//Person::~Person(); //不用显示调用
cout << "~Student() " << endl;
//...
}这是因为其数据存储结构,比如一个子类 (Student),它会先存储父类(Person)的成员,然后在下面存储自己的成员。因为其数据存在栈帧上的,要遵循后进先出规则,所以后构造的先析构(与构造顺序相反,子类数据后构造),先调用派生类的析构函数,再调用基类的析构函数。
每个子类析构函数后面会自动调用父类析构函数,这样才能保证先析构子类,再析构父类。(自己手写编译器无法保证顺序)
继承和友元:
PS:友元关系不能被继承。基类的友元不会自动成为派生类的友元。
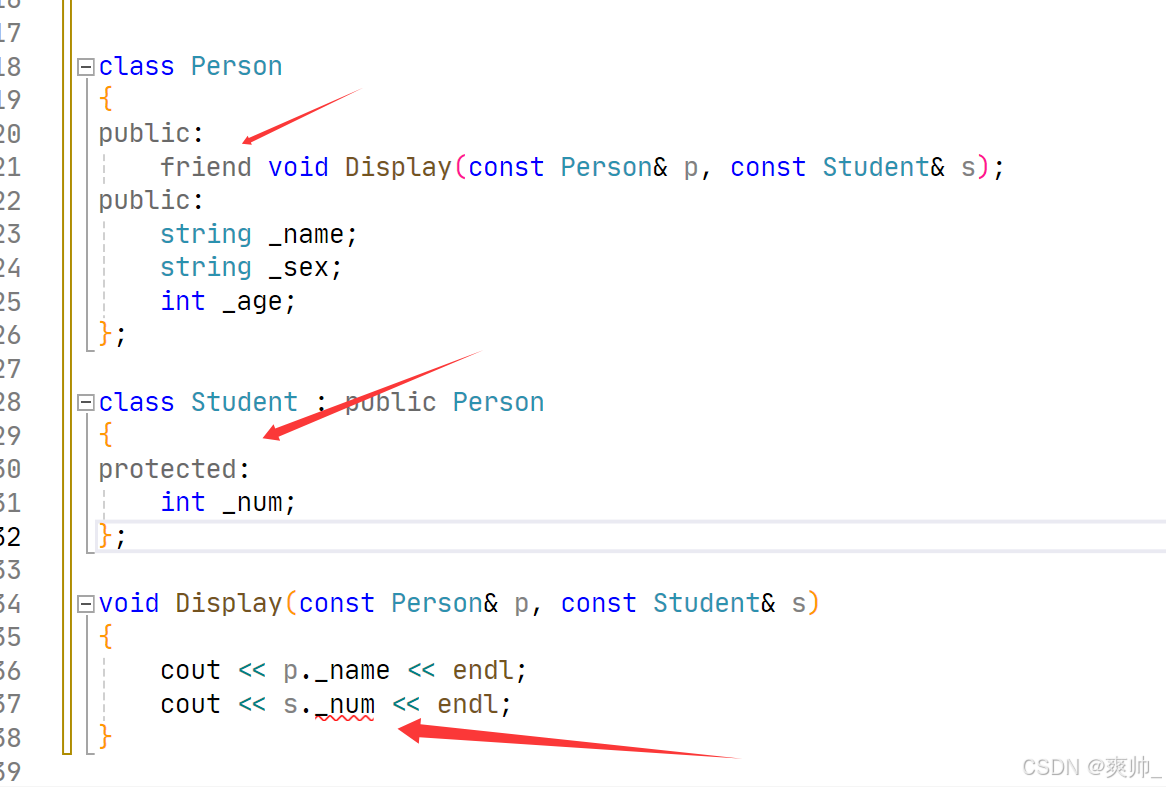
如果想访问子类的私有数据,设置为子类的友元就行。
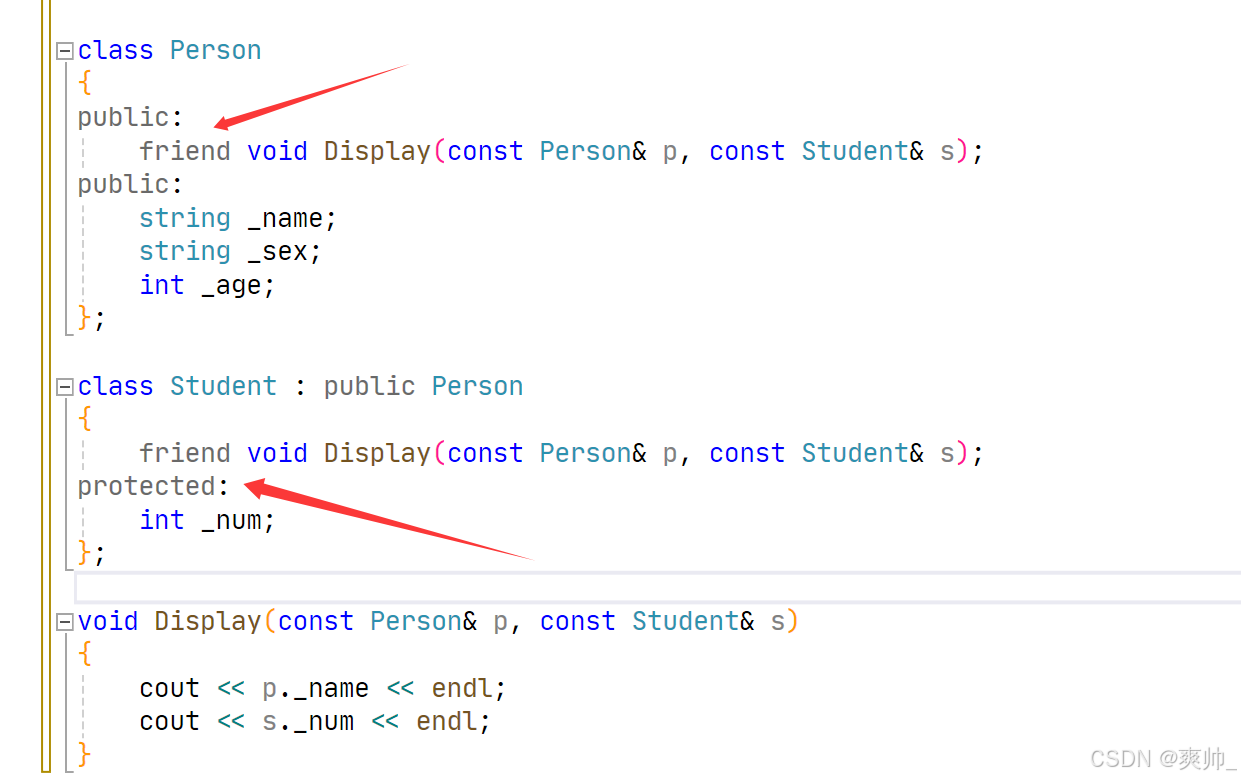
继承中静态成员的作用与访问规则
静态成员(静态变量、静态方法)属于类本身,而非类的实例。所有实例共享静态成员,且通过类名直接访问。
class Person
{
public:
Person() { ++_count; }
string _name;
static int _count; //静态成员变量
};
int Person::_count = 0;
class Student : public Person
{
protected:
int _num;
};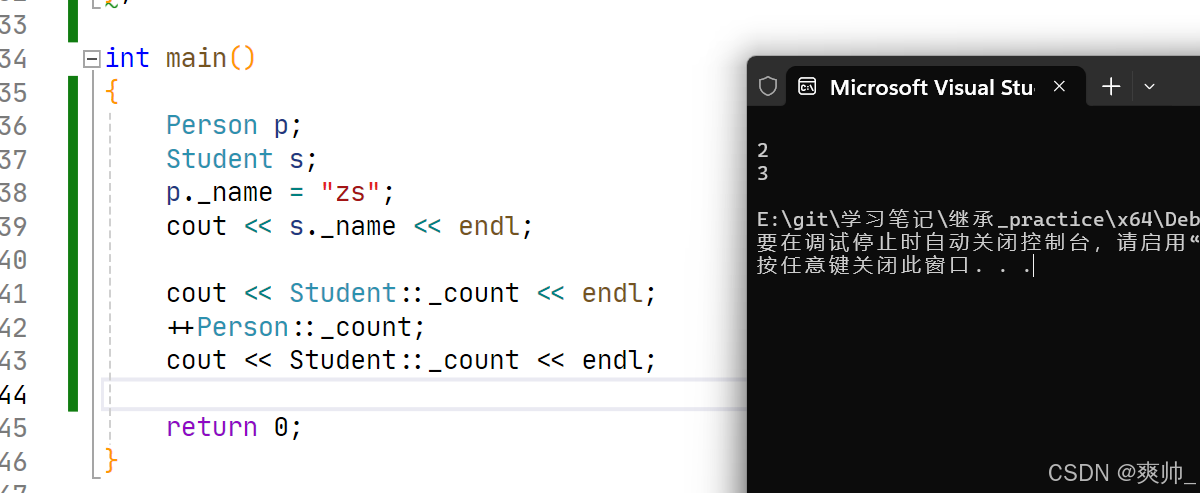 共享性:父类的静态成员会被子类继承,但子类与父类共享同一份静态成员。
共享性:父类的静态成员会被子类继承,但子类与父类共享同一份静态成员。
class Parent
{
public:
static int value;
};
class Child : public Parent
{
public:
static int value;
};
Parent::value = 10; // 父类静态成员
Child::value = 20; // 子类静态成员(隐藏父类的同名成员)隐藏:若子类定义了同名静态成员,父类的静态成员会被隐藏,但未被覆盖(通过父类名仍可访问)。
多继承:
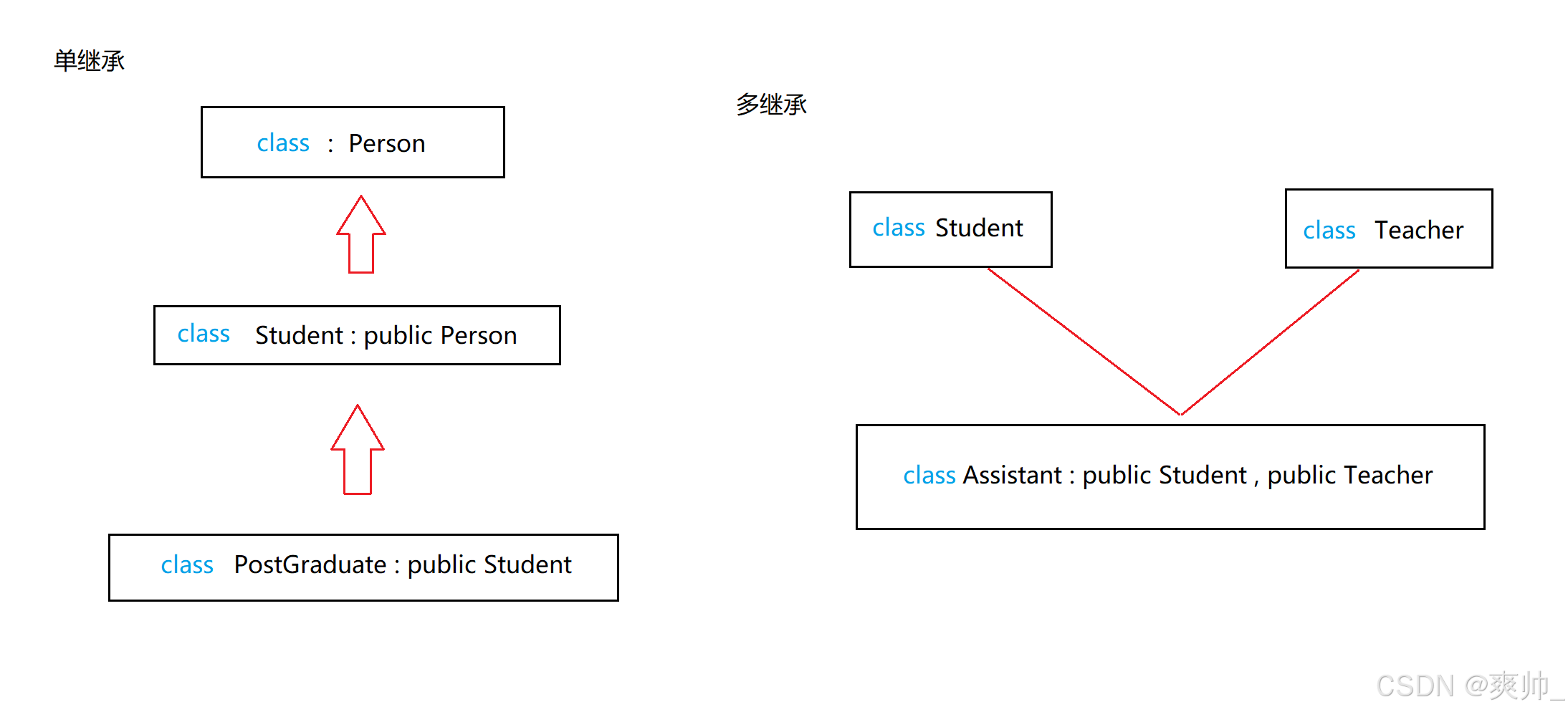
单继承:单继承指一个子类仅能继承一个父类的属性和方法。这是大多数面向对象编程语言的基础特性,能简化代码结构并减少复杂性。
class Animal {
public:
void eat() { cout << "Eating" << endl; }
};
class Dog : public Animal {
public:
void bark() { cout << "Barking" << endl; }
};多继承:多继承允许一个子类同时继承多个父类,增强了代码复用能力,但可能引发命名冲突(如多个父类有同名成员)和复杂性。
class Base1 { public: int a = 100; };
class Base2 { public: int b = 200; };
class Derived : public Base1, public Base2
{
public:
int sum() { return a + b; }
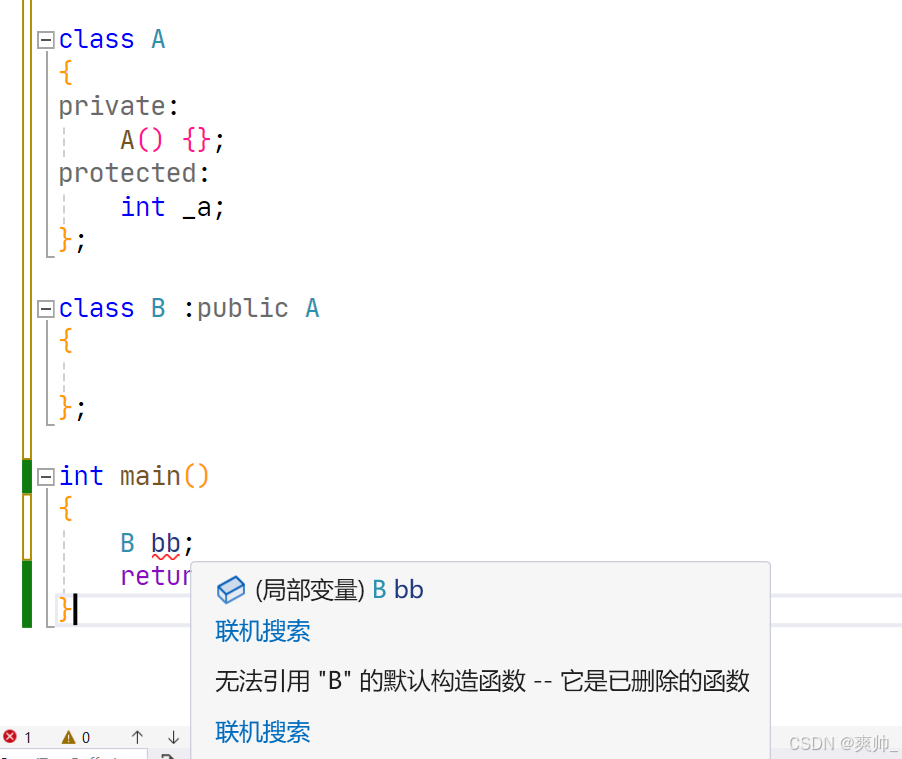
};Q:如何定义一个不能被继承的类?
1.父类构造私有化。子类对象实例化不能调用构造函数。
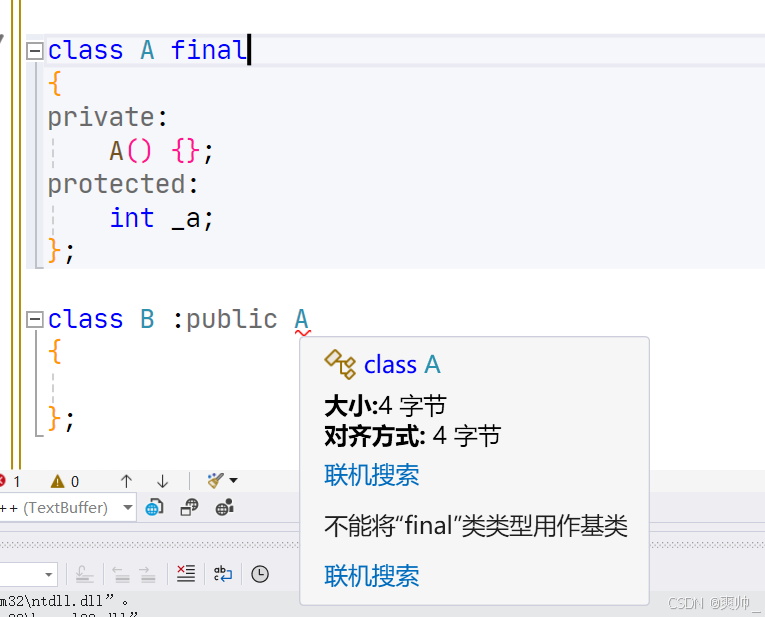
2. final 关键字 修饰 不能被继承的类。 (C++11)
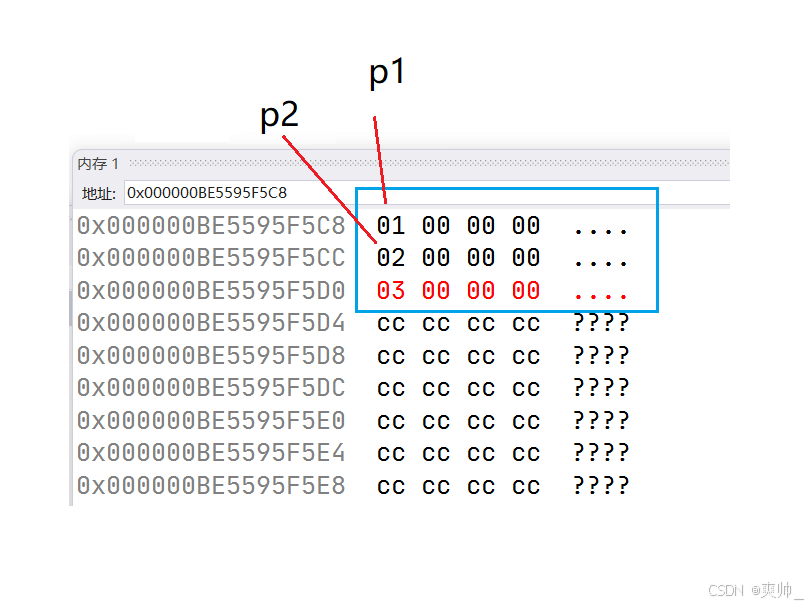
Q:下面代码 p1、p2、p3的大小关系?
class Base1 { public: int _a; };
class Base2 { public: int _b; };
class Derived : public Base1, public Base2
{
public:
int _d;
};
int main()
{
Derived d;
Base1* p1 = &d;
Base2* p2 = &d;
Derived* p3 = &d;
return 0;
}A:p1=p3!=p2
这里其实是看对切割的理解深不深。

这里p1指向的是base1,p2指向的是base2,都是指向对应数据的开头。p3指向的是整体,指向的是整体数据的首地址。
class Derived : public Base2, public Base1 //先继承 Base2
{
public:
int _d;
};PS:子类先继承谁,谁的数据在前面。

这里数据位置改变,p1、p2指向的位置也会改变。p2=p3!=p1。

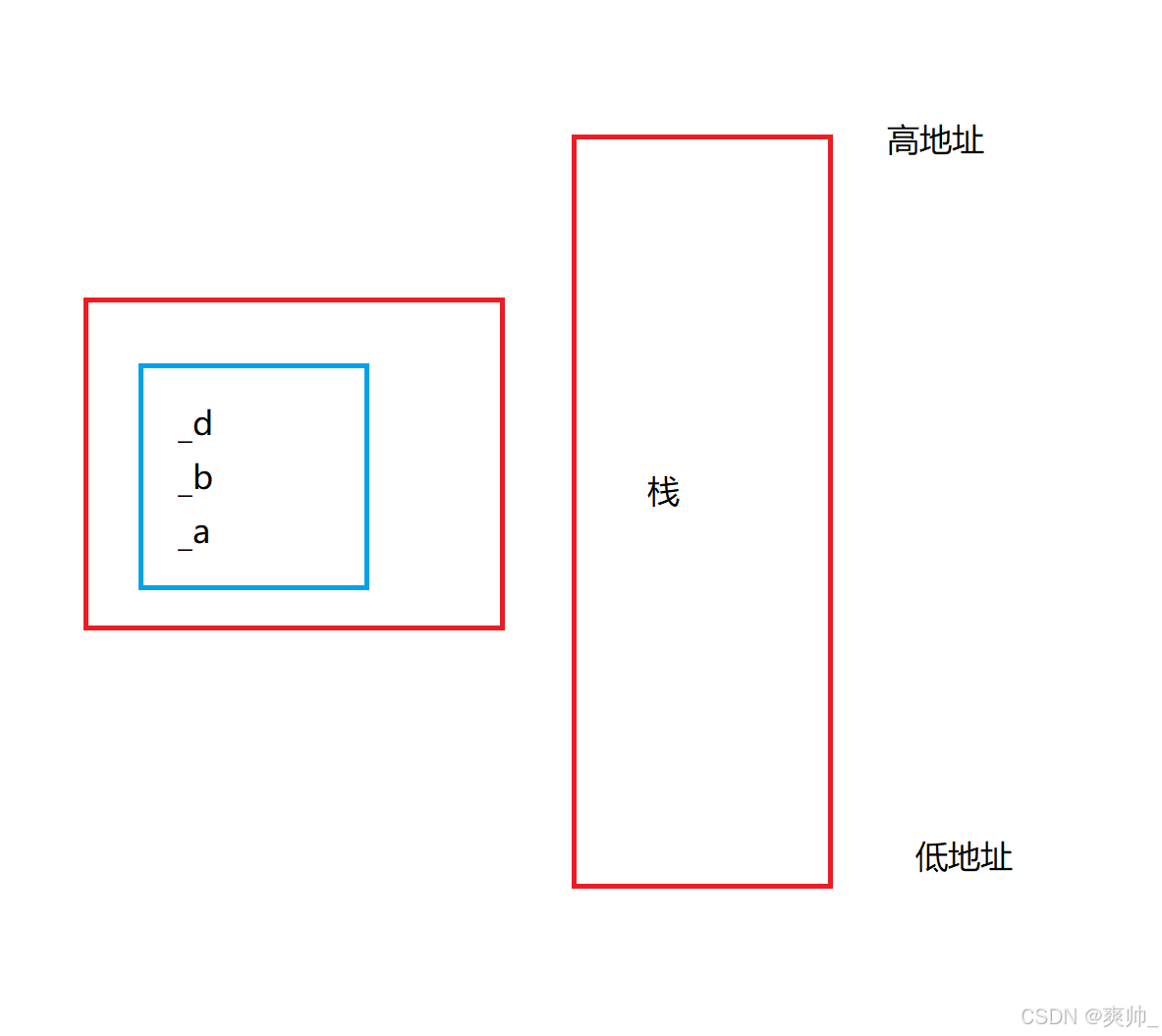
Q:这里p1、p2谁的地址大(先继承Base1,再继承Base2)?
因为数据存储在栈帧中,是先存低地址再存高地址(这里先存的_a、_b、_c)。所以 p2 > p1、p3。

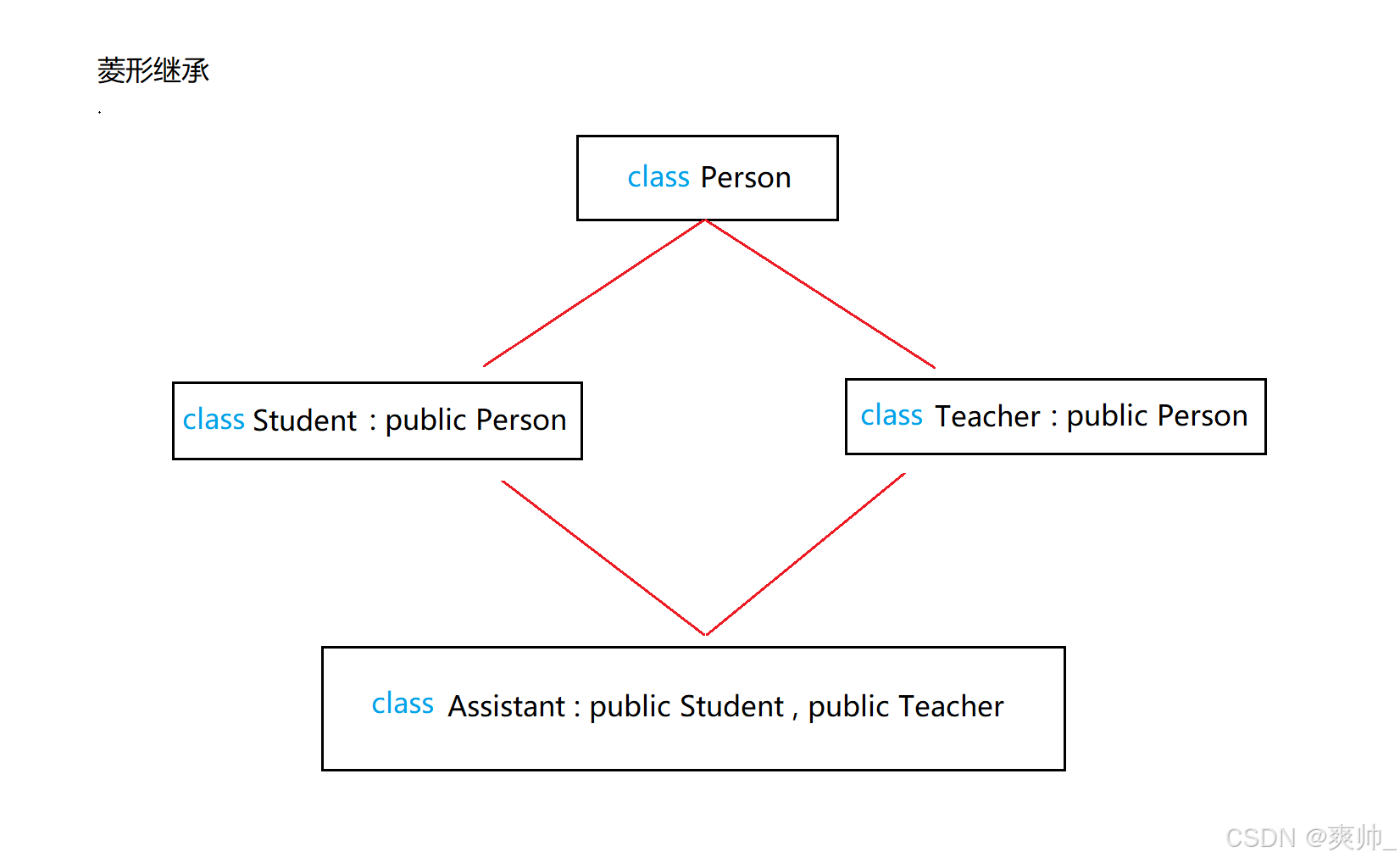
菱形继承:
菱形继承是多继承的特殊情况,指一个子类的多个父类继承自同一个基类,导致基类的成员在子类中存在多份副本。
class Person
{
public:
string _name;
};
class Student : public Person
{
protected:
int _num;
};
class Teacher :public Person
{
};
class Assistant :public Student, public Teacher
{
};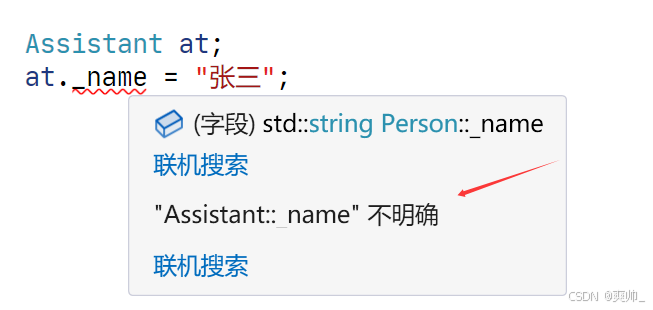
当多个父类继承自同一个祖先类时,可能导致成员重复和调用歧义。菱形继承有数据冗余和二义性的问题。在 Assistant 的对象中 Person 成员会有两份。
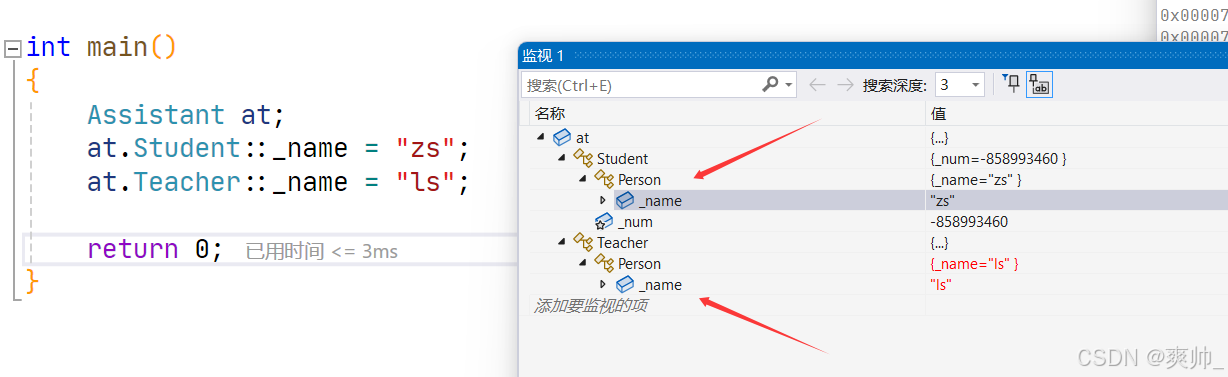
指定类域调用就明确了。监视窗口能看到有多份的数据。