Python数据分析及相关库(一)
目录
一、多维数组库numpy
1、特点
2、相关函数
3、创建数组
4、numpy常用属性及函数
5、numpy数组的元素增删改查
①numpy的增加
②numpy的删除
③numpy的查找
6、numpy数组的数学运算
7、numpy数组的切片
二、pandas数据分析库
1、认识pandas
2、Series类
3、DataFrame的构造访问
4、DataFrame的切片
数据分析我们主要涉及到numpy和pandas。
一、多维数组库numpy
numpy是Python中用于科学计算的库,它提供了强大的多维数组的对象,以及大量用于操作这些数组的函数(Python数组是存储同类型数据的高效结构)
1、特点
它具有以下特点:
①多维数组库,创建多为数组很方便,可以代替多维列表
②速度比多维列表快很多
③支持向量和矩阵的各种数学运算
④所有的元素类型必须相同
2、相关函数
| 函数 | 功能 |
| array(x) | 根据列表或元组x创建数组 |
| arange(x,y,i) | 创建一堆数组,元素等价于range(x,y,i) |
| linespace(x,y,n) | 创建一个由区间[x,y]的n-1等分点构成的一维数组,包含x和y |
| random.randint(...) | 创建一个元素为随机整数的数组 |
| zeros(n) | 创建一个元素全为0.0的长度为m的数组 |
| ones(n) | 创建一个元素全为1.0的长度为n的数组(后面可加dtype=int,即均为整数) |
3、创建数组
我们可以根据上面的函数创建几个数组的示例:
import numpy as np
a = np.array([1,2,3])
print(a)
b = np.arange(1,9,2)
print(b)
c = np.linspace(1,10,4)
print(c)
d = np.random.randint(10,20,[2,3]) #输出一些从10到20(包含端点)的随机数,构成生成一个两行三列的数组
print(d)输出:
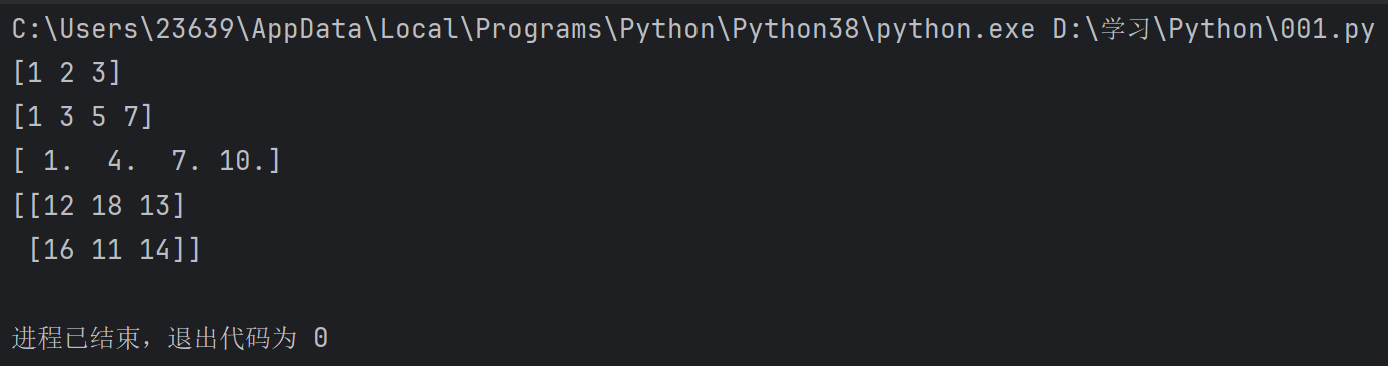
从这些输出中,我们就能看见这些数组和一些列表之类的数据类型的不同
4、numpy常用属性及函数
| 属性或函数 | 含义及功能 |
| dtype | 数组元素的类型 |
| ndim | 数组是几维的 |
| shape | 数组每一维的长度 |
| size | 数组元素的个数 |
| argwhere(...) | 查找元素 |
| tolist() | 转换为list |
| min() | 求最小元素 |
| max() | 求最大元素 |
| reshape() | 改变数组的形状 |
| flatten() | 转换为一维的数组 |
下面我们来把这些函数结合到代码中:
import numpy as np
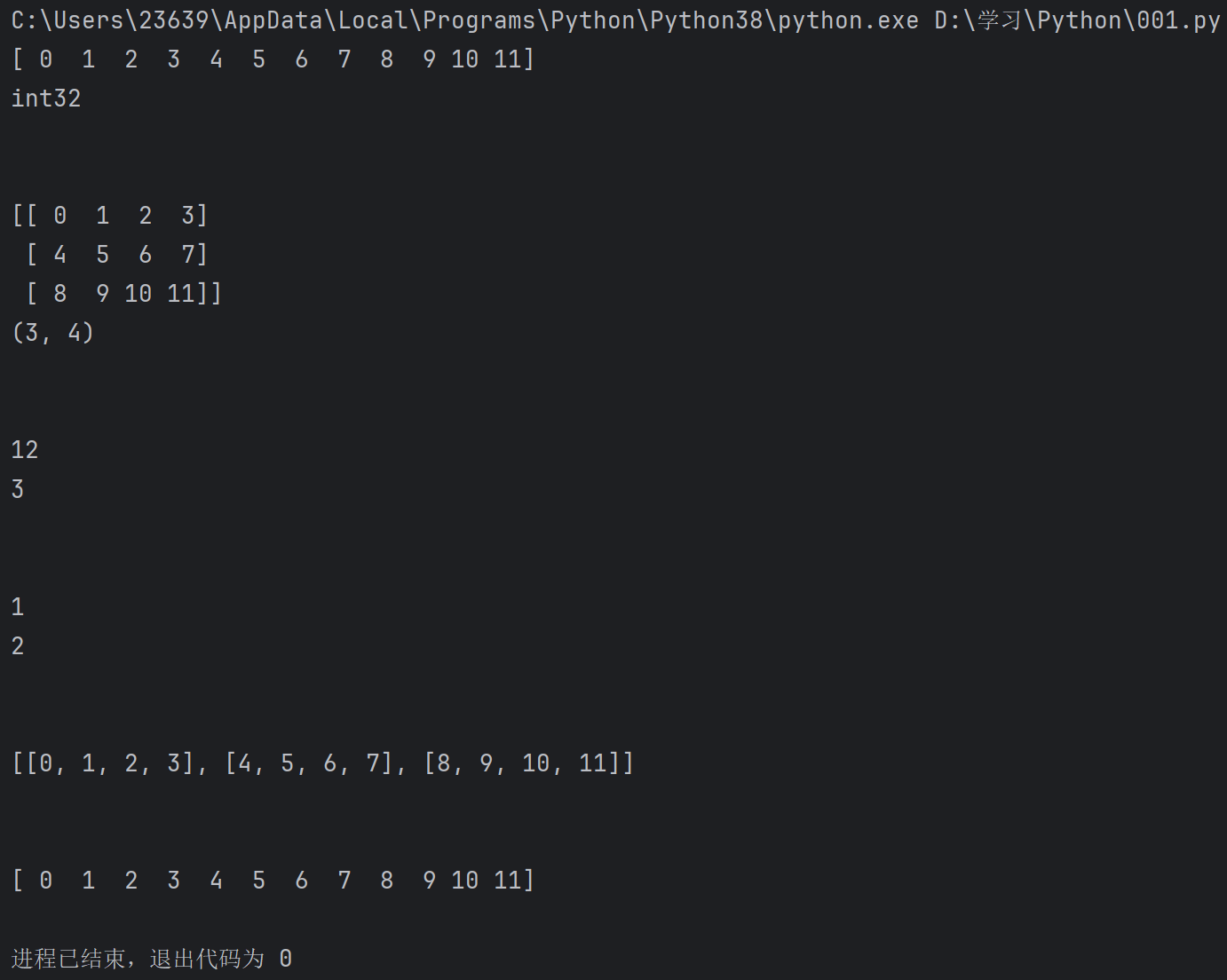
a = np.array([i for i in range(12)]) #我们先用列表生成式生成了一个从0到11的数组
print(a)
print(a.dtype) #输出a的类型
print("\n")
b = a.reshape(3,4) #转化为三行四列的数组
print(b)
print(b.shape)
print("\n")
print(b.size) #注意区分这两个size是指元素的个数,而此时的len就是说这个数组有几行
print(len(b))
print("\n")
print(a.ndim) #看数组的维度,一维就是只有一行或者一列,二维就是有行有列,三维就是还有深度
print(b.ndim)
print("\n")
listone = b.tolist() #转化为列表
print(listone)
print("\n")
c = b.flatten() #拉直,就是变成一维的
print(c)输出:
5、numpy数组的元素增删改查
在Python的numpy数组中,当我们生成了这个数组,这个数组的元素个数,形状是不能进行改变的,而上面和一会下面提到的增删元素的函数都是生成了一个新的数组
函数:
| 函数 | 功能 |
| append(x,y) | 若y是数组,列表,元组之一,就将y的元素添加进数组x得到新数组,否则就将y本身添加进数组x得到新的数组 |
| concatenate(...) | 拼接多个列表 |
| delete(...) | 删除数组元素得到新数组 |
我们把这些函数应用到代码中:
①numpy的增加
import numpy as np
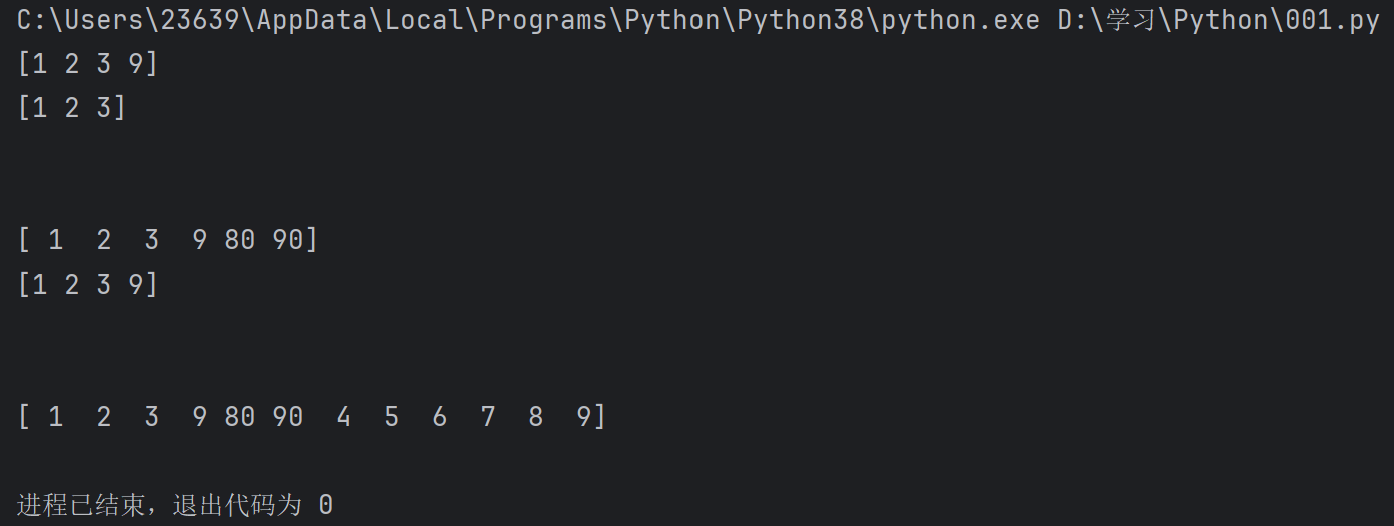
a = np.array((1,2,3))
b = np.append(a , 9)
print(b)
print(a)
print("\n")
c = np.append(b, [80 , 90]) #这些函数都只会创建一个新的数组,输出旧的依旧不变
print(c)
print(b)
print("\n")
d = np.concatenate((c , [4,5,6] , [7,8,9])) #concatenate函数的值必须是一个元组,元组内部包含需要拼接到一起的各个数据
print(d)
输出:
②numpy的删除
代码:
import numpy as np
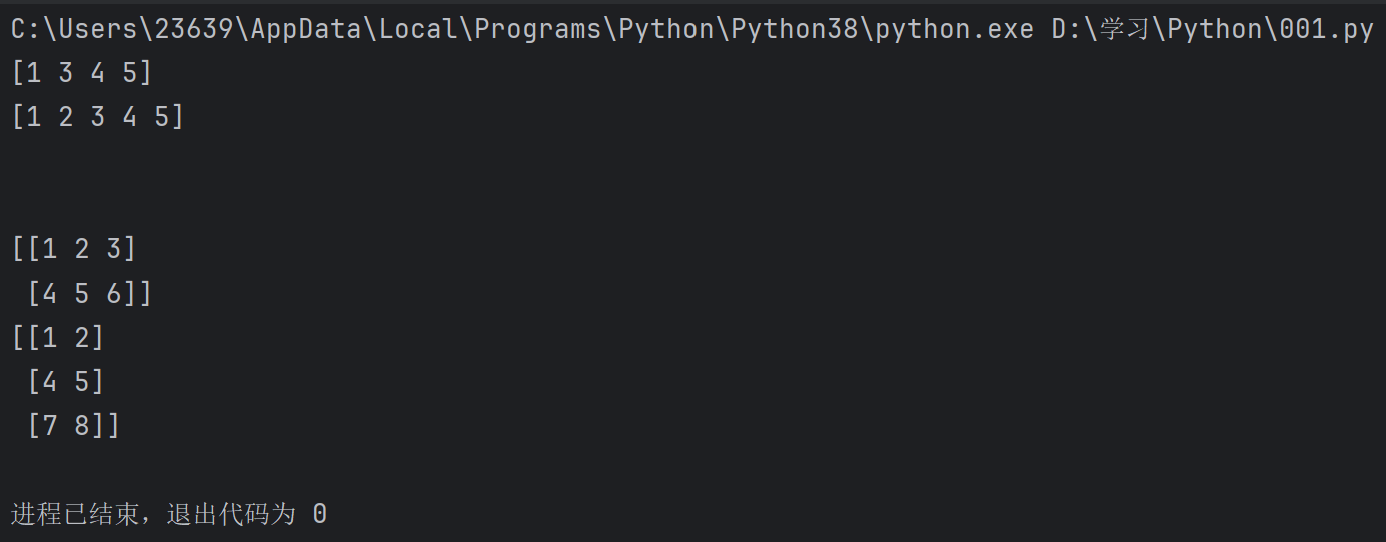
a = np.array((1,2,3,4,5))
b = np.delete(a , 1)
print(b)
print(a)
print("\n")
c = np.array([[1,2,3] , [4,5,6] , [7,8,9]])
d = np.delete(c , 2 , axis=0) #axis就是用来知名具体的行或轴,0就是行,1就是列,代码中的就是分别指删除第二行和删除第二列
e = np.delete(c , 2 , axis=1)
print(d)
print(e)
输出:
③numpy的查找
在numpy中,我们可以通过元素的数值来查找其对应的下标,我们也可以简单的判断某个元素是否在数组内部:
代码:
import numpy as np
a = np.array((1,2,3,4,5,2,8,9))
posone = np.argwhere(a == 2)
print(posone)
print(2 in a)输出:

我们也可以选出符合某个范围的数值:
import numpy as np
a = np.array((1,2,3,4,5,2,8,9))
b = a[a > 5]
print(b)
a[a < 5] = 0 #虽然不能改变数组的长度,形状,但是可以更改元素的数值!
print(a)输出:

6、numpy数组的数学运算
numpy数组拥有强大的数学运算,它身为一个数组居然能直接和数字进行运算!(向量化运算,简直不要太强)
import numpy as np
a = np.array((1,2,3,4,5))
b = a + 1 #数组与数字
print(b)
c = a * b #数组与数组
print(c)输出:

7、numpy数组的切片
numpy身为一个数组,当然可以进行切片操作了,但是它有一个特点,在我们前面的列表,元组中,一个切片就相当于是一个新的元素了,但是在numpy数组中,他的切片是一个“视图”,也就是说这个切片是原数组的一部分,而不是一部分的拷贝(即我们改变了切片,原数组也会改)
但如果我们就是想要一个独立的切片,我们可以使用copy函数
import numpy as np
a = np.array((1,2,3,4,5,6,7,8,9))
b = a[1:6]
print(b)
c = np.copy(a[1:6])
print(c)
b[1] = 999
print(a)
print(c)我们在上面的代码中用b直接截取了一部分的切片,而我们的c则是这个切片的拷贝
当我们改变了这个切片b时,身为原数组的a受到了影响,但是我们的拷贝c却无变化
二、pandas数据分析库
1、认识pandas
pandas的核心功能是在二维表格上进行各种操作,如增删,修改,求一列数据的和,差,方差中位数,平均数等
它需要有numpy的支持
如果把pandas与openpyxl等库结合,还可以读写excel文档
而在pandas中最重要的类就是DataFrame,表示二维表格。
(这是一个第三方库,需要pip下载)
2、Series类
Series类是一个一维表格,每个元素带有标签,且含有下标,兼具列表和字典的访问形式
我们现在就创建一个一维表格,并对他进行一些基础操作:
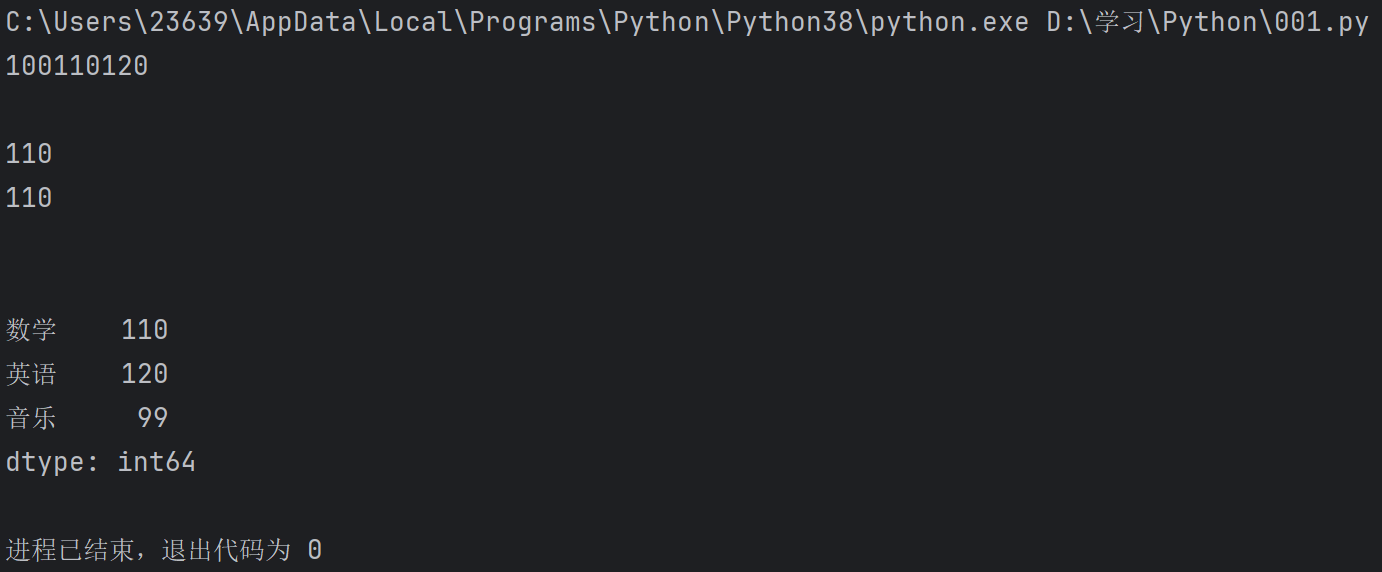
import pandas as pd
s = pd.Series(data = [100 , 110 , 120] , index = ["语文" , "数学" , "英语"])
for i in s :
print(i , end = "")
print("\n")
print(s[1])
print(s["数学"])
print("\n")
s["音乐"] = 99
s.pop("语文")
print(s)看看输出:
以及一些计算和具体的查找:
import pandas as pd
s = pd.Series(data = [100 , 110 , 120] , index = ["语文" , "数学" , "英语"])
print(s.sum() , s.min() , s.max() , s.mean() , s.median())
#输出总和,最小值,最大值,平均值,中位数
print(s.idxmax() , s.argmax())
#输出最大值的元素以及下标输出:

3、DataFrame的构造访问
DataFrame是带有行列标签的二维表格,每一列都是一个Series
我们先试着创建一个简单的二维表格:
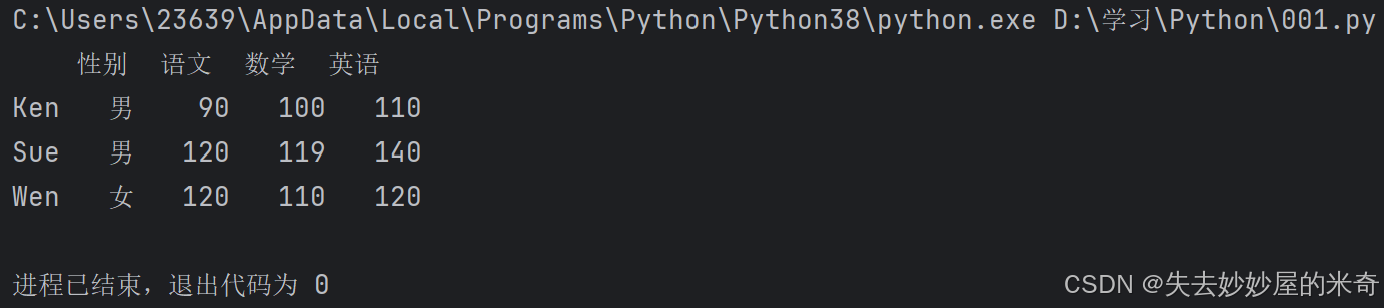
import pandas as pd
pd.set_option("display.unicode.east_asian_width" , True) #这一行的作用是防止中文字符的宽度导致表格显示错误
scores = [['男',90,100,110] , ['男',120,119,140] , ['女',120,110,120]]
names = ["Ken" , "Sue" , "Wen"]
courses = ["性别" , "语文" , "数学" , "英语"]
df = pd.DataFrame(data = scores , index = names , columns = courses) #先用DataFrame创建一个函数,里面分别是二维表格的数据,行标签,列标签
print(df)看看输出:
二维表格的访问十分灵活,我们可以用一些函数来访问二维表格的各种数据或标签:
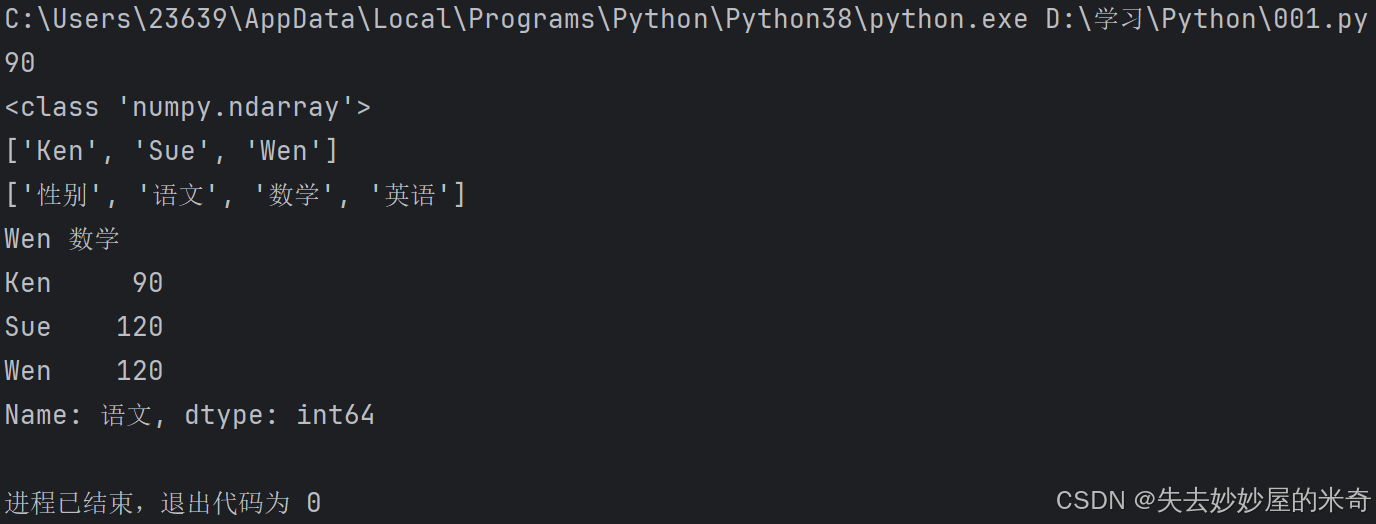
import pandas as pd
pd.set_option("display.unicode.east_asian_width" , True) #这一行的作用是防止中文字符的宽度导致表格显示错误
scores = [['男',90,100,110] , ['男',120,119,140] , ['女',120,110,120]]
names = ["Ken" , "Sue" , "Wen"]
courses = ["性别" , "语文" , "数学" , "英语"]
df = pd.DataFrame(data = scores , index = names , columns = courses) #先用DataFrame创建一个函数,里面分别是二维表格的数据,行标签,列标签
#————————————————————————以上是创建了一个二维表格————————————————————————
print(df.values[0][1]) #求数据中第0行第1列
print(type(df.values)) #返回表格的数据类型
print(list(df.index)) #以列表的形式返回行标签
print(list(df.columns)) #以列表的形式返回列标签
print(df.index[2] , df.columns[2]) #定位到列标签和行标签
print(df["语文"]) #输出语文标签所包含的数据看看输出:
4、DataFrame的切片
在DataFrame中,我们可以用下标做切片,也可以用标签做切片
在DataFrame中,它的切片也是一个视图!
二维列表就像一个平面,我们可以切一个条(行或列),也可以切一个小面(行列均包含)
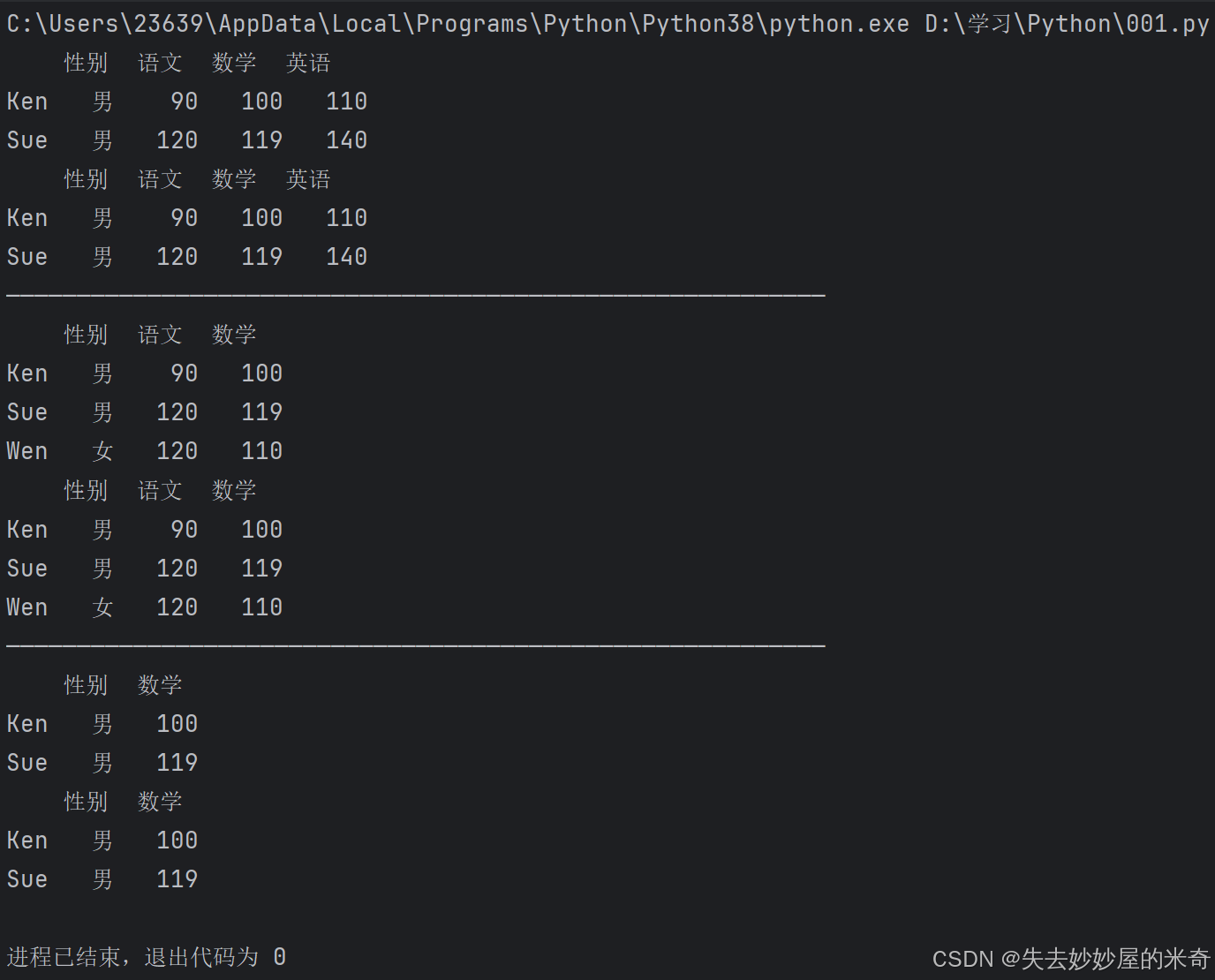
import pandas as pd
pd.set_option("display.unicode.east_asian_width" , True) #这一行的作用是防止中文字符的宽度导致表格显示错误
scores = [['男',90,100,110] , ['男',120,119,140] , ['女',120,110,120]]
names = ["Ken" , "Sue" , "Wen"]
courses = ["性别" , "语文" , "数学" , "英语"]
df = pd.DataFrame(data = scores , index = names , columns = courses) #先用DataFrame创建一个函数,里面分别是二维表格的数据,行标签,列标签
#————————————————————————以上是创建了一个二维表格————————————————————————
df2 = df.iloc[0:2]
df3 = df.loc["Ken":"Sue"] #①iloc是用于下标索引,loc是基于标签索引 ②注意一点:用下标切片是不包含结束端的,而用标签索引是包含的
#上面两个等价!
print(df2)
print(df3)
print("——————————————————————————————————————————————————————————")
df4 = df.iloc[: , 0:3] #前面的冒号没写默认全选
df5 = df.loc[: , "性别":"数学"]
print(df4)
print(df5)
print("——————————————————————————————————————————————————————————")
df6 = df.iloc[:2 , [0,2]] #也可以这样表示,里面有那个数字,就单只哪行或列(不是范围)(里面是逗号)
df7 = df.loc[:"Sue" , ["性别" , "数学"]]
print(df6)
print(df7)输出:
以上就是Python数据分析及相关库(一)的相关内容:)