deepseek-r1 api部署和镜像
背景
本文提供一个deepseek-r1-14b/32b的镜像,支持vllm api部署,提供客户端调用api代码,支持history和functioncall。
deepseek镜像
使用auto-dl平台:https://www.autodl.com/create
选择社区镜像
找到Tecioon4的镜像
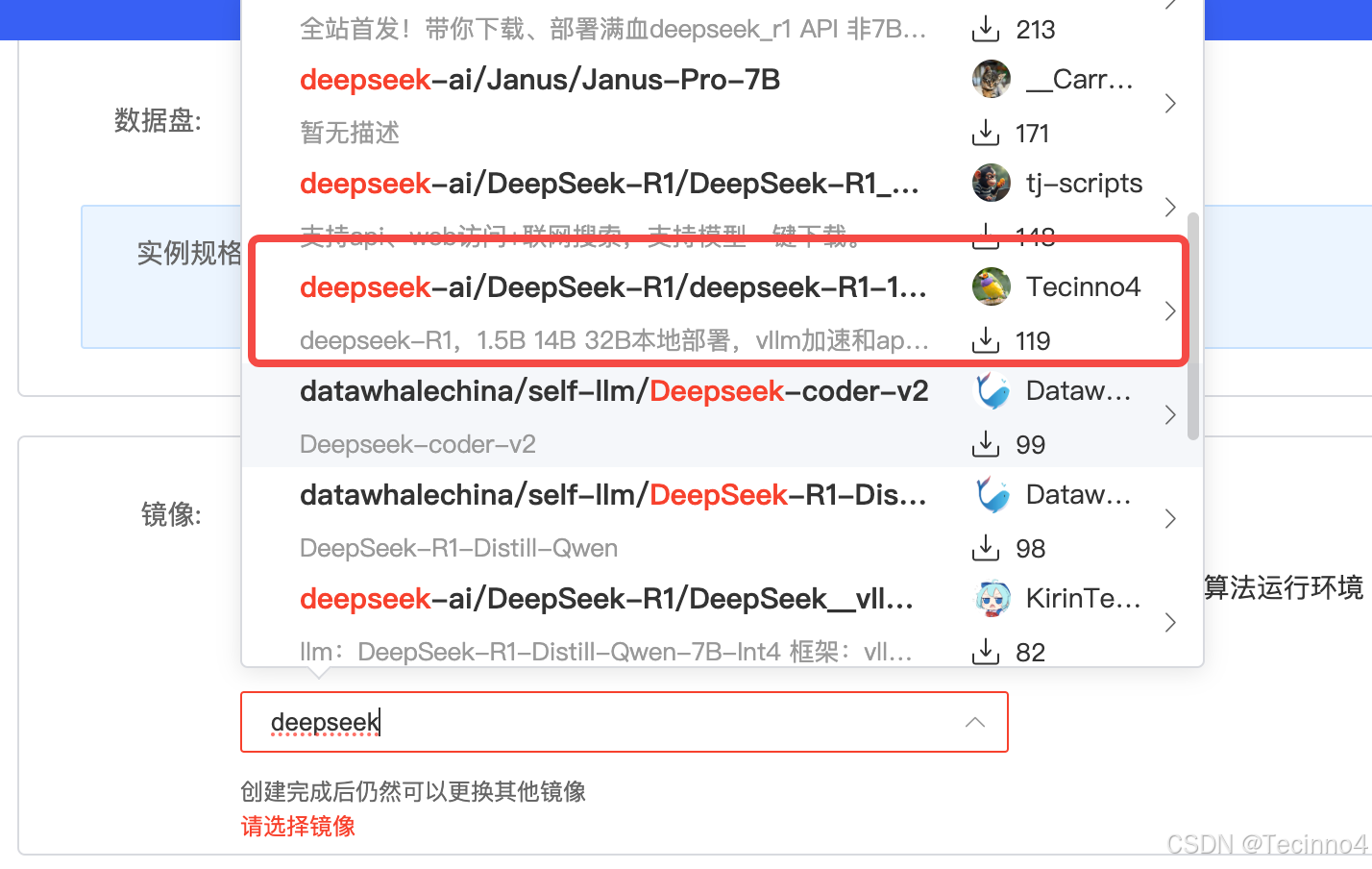
镜像详情:
https://www.codewithgpu.com/i/deepseek-ai/DeepSeek-R1/deepseek-R1-14B-32B-vllm-api
镜像构建
镜像已预装 1.5B 模型和部分14B模型,开箱即用,支持多轮对话推理。
如需使用更大的模型版本,可根据算力按需下载。
须知
- 章节一是快速尝试
- 章节二、三是准备环境和模型
- 章节四是在服务器上使用模型进行对话
- 章节五是在服务器上进行API部署,方便你远程调用API
- 章节六是在客户端(本地电脑)上调用服务器API
模型选择:
本镜像支持不同规格的模型,内置1.5B的和部分14B模型,如果你只是想使用1.5B,就不用下载模型,直接使用章节一,四、五、六。如果你需要使用14B和32B或者其他模型,请先使用章节二、三下载模型,再用章节四、五、六。
交互方式选择:
只是想在服务器上进行对话,使用章节四即可。
如果需要部署API,使用章节五和六。
一、快速上手使用
镜像中有1.5B的模型,可以直接测试效果
cd ~
conda activate torch_env
python deepseek_multichat.py
二、基本环境
-
框架及版本
- Python: 3.8.10
- PyTorch: 2.4.1
- Transformers: 4.46.3
- Triton: 3.0.0
- Safetensors: 0.4.5
-
CUDA 版本
- CUDA 12.1
三、构建过程
默认下载了1.5B的模型,以及部分14B模型
1.5B: /root/DeepSeek-R1
14B: /root/DeepSeek-R1-Distill-Qwen-14B
环境配置
进入root目录
cd ~
激活环境
conda activate torch_env
设置下载源
export HF_ENDPOINT=https://hf-mirror.com
在数据盘创建目录
mkdir -p /root/autodl-tmp/model
将14B模型移动到数据盘
mv /root/DeepSeek-R1-Distill-Qwen-14B /root/autodl-tmp/model/
下载模型
默认使用1.5B的本地模型,其他类型的模型需要根据以下指令下载。
!!!下载失败的话进行多次尝试,我本地网络不太好重试了十几次,最后还是可以成功下载完!!!!
1.5B
已经下载在/root/DeepSeek-R1中。
14B
下载了一部分,需要继续下载
huggingface-cli download deepseek-ai/DeepSeek-R1-Distill-Qwen-14B \
--local-dir /root/autodl-tmp/model/DeepSeek-R1-Distill-Qwen-14B \
--resume-download
32B,需要重头开始下,有点慢
huggingface-cli download deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \
--local-dir /root/autodl-tmp/model/DeepSeek-R1-Distill-Qwen-32B \
--resume-download
更多模型
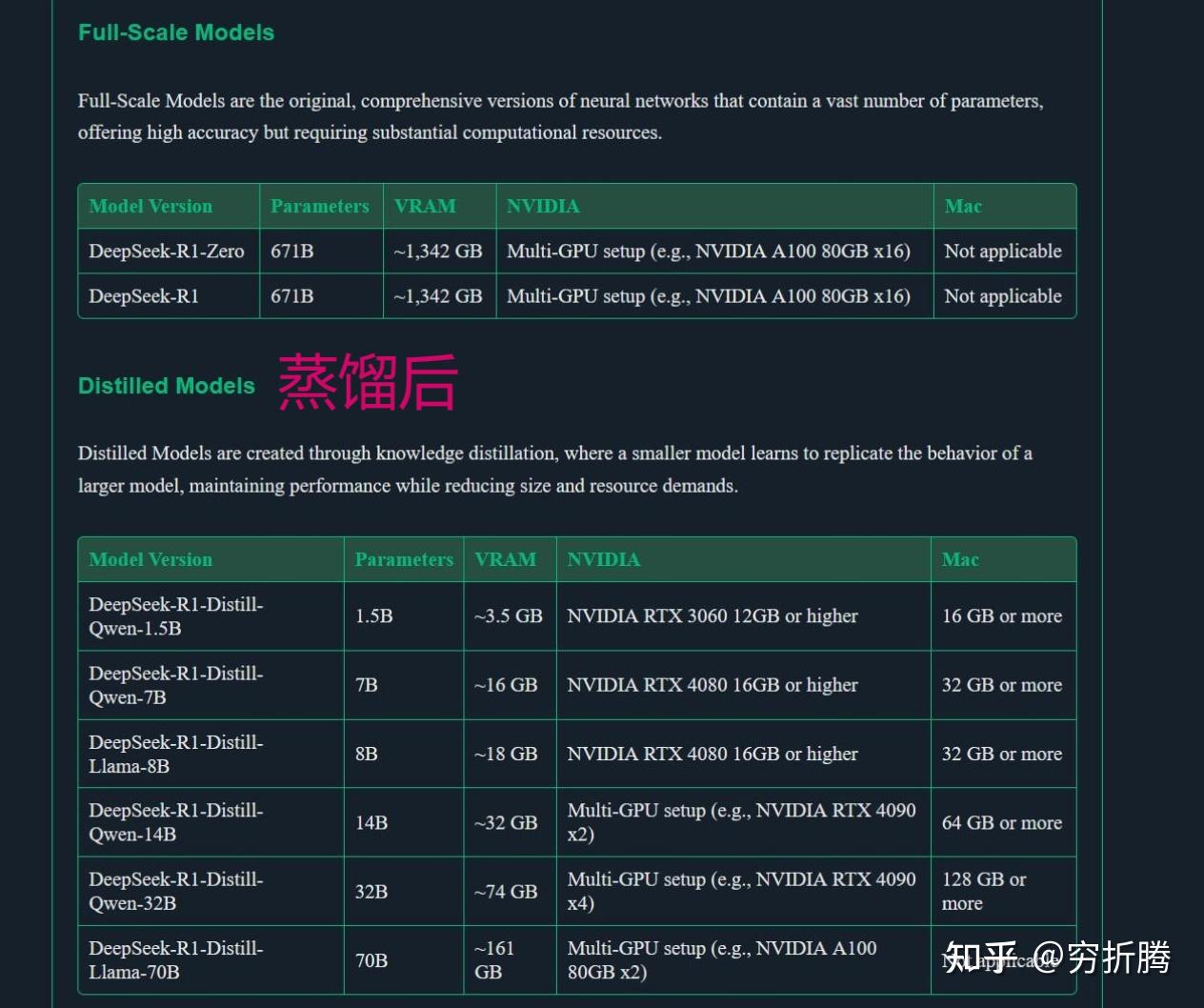
- DeepSeek-R1 Models(未蒸馏版)
| Model | #Total Params | #Activated Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K | ? HuggingFace |
| DeepSeek-R1 | 671B | 37B | 128K | ? HuggingFace |
- DeepSeek-R1-Distill Models(蒸馏版)
| Model | Base Model | Download |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | ? HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | ? HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | ? HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | ? HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | ? HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | ? HuggingFace |
参考:
https://huggingface.co/collections/deepseek-ai/deepseek-r1-678e1e131c0169c0bc89728d
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
四、对话、推理
环境搭建完成后,下次就直接调用deepseek_multichat或者vllm_model就可以启动模型
推理,有以下3中方式
-
终端对话,可以在代码中修改变量config_path来选择模型
python deepseek_multichat.py -
vllm加速,默认用的14B,可以在代码中修改变量model来选择模型
python vllm_model.py参考:
https://github.com/datawhalechina/self-llm/blob/master/models/DeepSeek-R1-Distill-Qwen/04-DeepSeek-R1-Distill-Qwen-7B%20vLLM%20%E9%83%A8%E7%BD%B2%E8%B0%83%E7%94%A8.md
- 官方方式,https://github.com/deepseek-ai/DeepSeek-V3
五、vllm-api部署
1.5B
python -m vllm.entrypoints.openai.api_server
–model /root/autodl-tmp/model/DeepSeek-R1
–served-model-name DeepSeek-R1
–max-model-len=19000
14B
需要先下载14B模型
python -m vllm.entrypoints.openai.api_server
–model /root/autodl-tmp/model/DeepSeek-R1-Distill-Qwen-14B
–served-model-name DeepSeek-R1-Distill-Qwen-14B
–max-model-len=19000
32B
需要先下载32B模型
python -m vllm.entrypoints.openai.api_server
–model /root/autodl-tmp/model/DeepSeek-R1-Distill-Qwen-32B
–served-model-name DeepSeek-R1-Distill-Qwen-32B
–max-model-len=19000
六、客户端调用
1.端口映射
先使用autodl自带的"自定义服务"进行端口映射,例如:
ssh -CNg -L 8000:127.0.0.1:8000 root@region-9.autodl.pro -p 26901
在客户端终端运行自定义服务的指令,需要将两个6006都改成8000,第一个是你客户端用的端口,第二个是你服务器的端口,也可以自己设置。
2. 代码调用
将/model.py和/test.py拷贝到客户端同一个目录下,直接运行test.py
3. 也可以直接终端测试
终端运行以下指令:
curl http://localhost:8000/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "DeepSeek-R1-Distill-Qwen-14B",
"messages": [
{"role": "user", "content": "我想问你,5的阶乘是多少?<think>\n"}
]
}'
4. 更多玩法参考以下链接
https://github.com/datawhalechina/self-llm/blob/master/models/DeepSeek-R1-Distill-Qwen/04-DeepSeek-R1-Distill-Qwen-7B%20vLLM%20%E9%83%A8%E7%BD%B2%E8%B0%83%E7%94%A8.md