【学习篇】pandas进行数据清洗
背景:最近做项目需要用到pandas进行数据清洗转化,一边DS一边开展工作,现在记录下学习到的pandas常用方法。
学习链接:https://www.runoob.com/pandas/pandas-tutorial.html
1. Pandas 特性介绍
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 提供了丰富的功能,包括:
数据清洗:处理缺失数据、重复数据等。
数据转换:改变数据的形状、结构或格式。
数据分析:进行统计分析、聚合、分组等。
数据可视化:通过整合 Matplotlib 和 Seaborn 等库,可以进行数据可视化。
需要记住的示例,对自己理解pandas的数据结构有很大的帮助
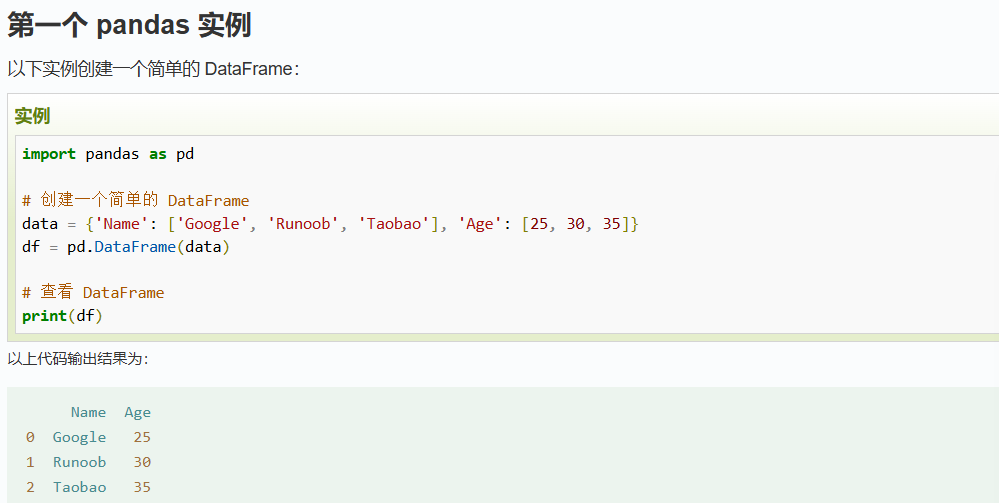
2. Pandas 数据结构
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据)。
Series 是一种类似于一维数组的对象,它由一组数据(各种 Numpy 数据类型)以及一组与之相关的数据标签(即索引)组成。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
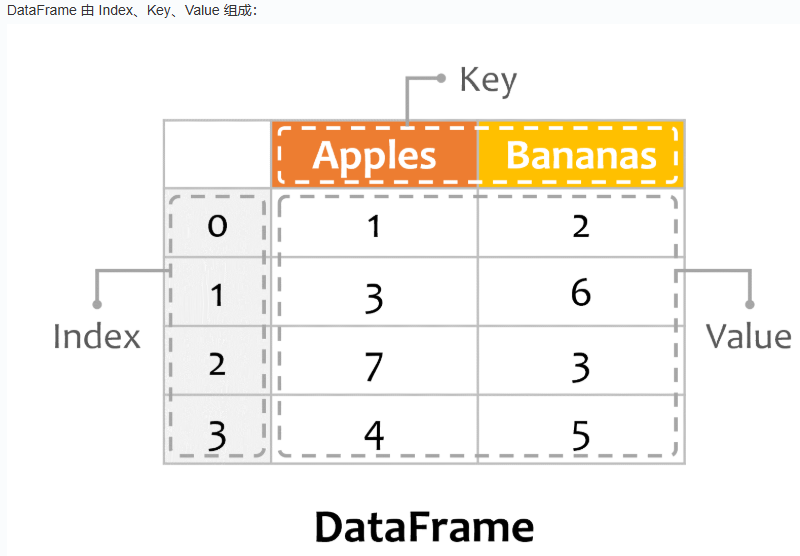
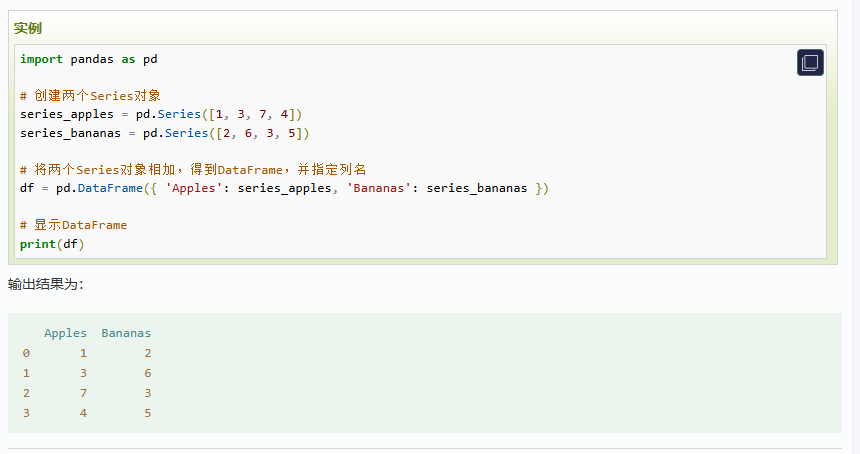
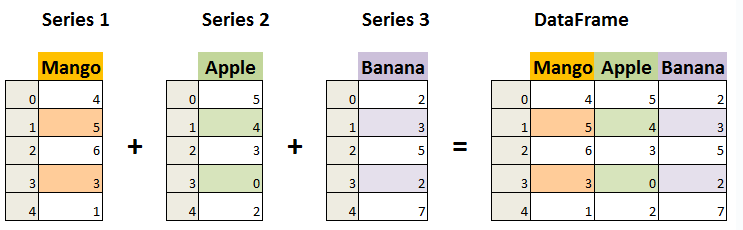
从下面的例子可以记住Series 和 DataFrame的关系:
2.1 Series 方法
注意:Series可以自定义索引。
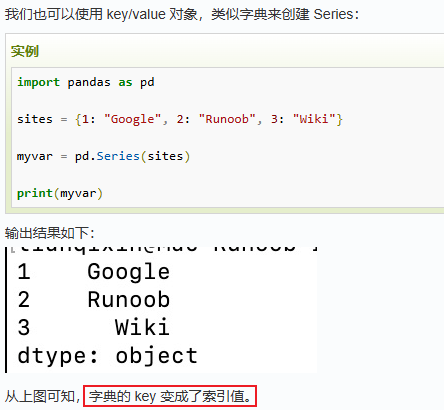
此处,只列举我目前实际用到的方法,按照方法使用的频率高低进行排序:


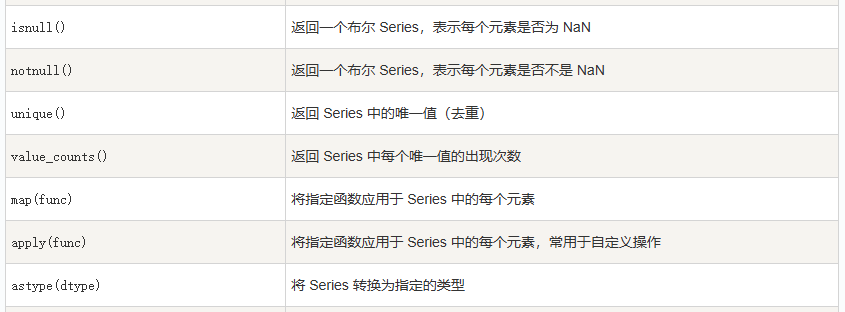
2.2 DataFrame 方法
DataFrame可以将其视为多个 Series 对象组成的字典。
此处,只列举我目前实际用到的方法,按照方法使用的频率高低进行排序:
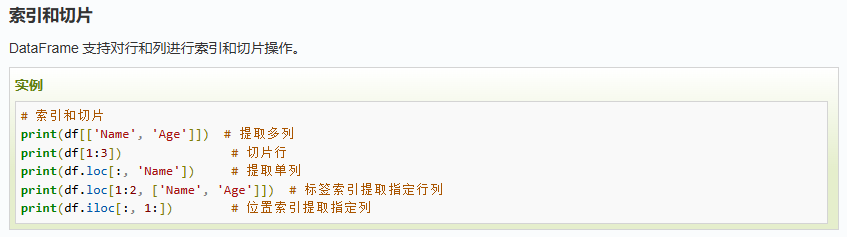


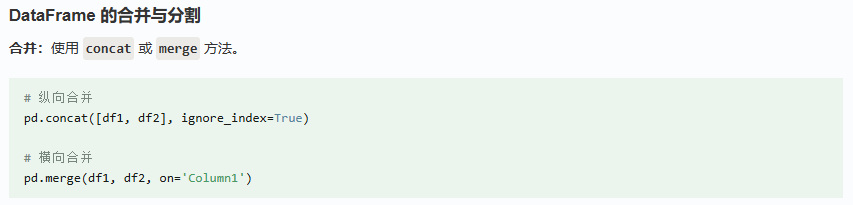
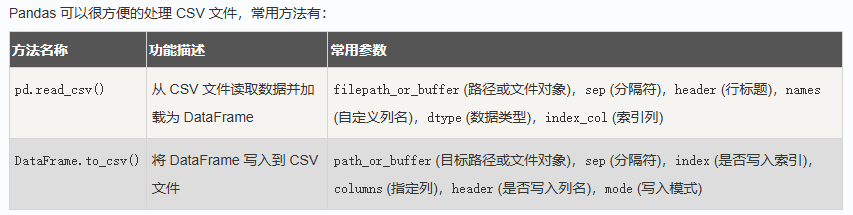
常遇到的应用场景是读取CSV表格数据和将DataFrame写入取CSV表格:
3. Pandas 进行数据清洗
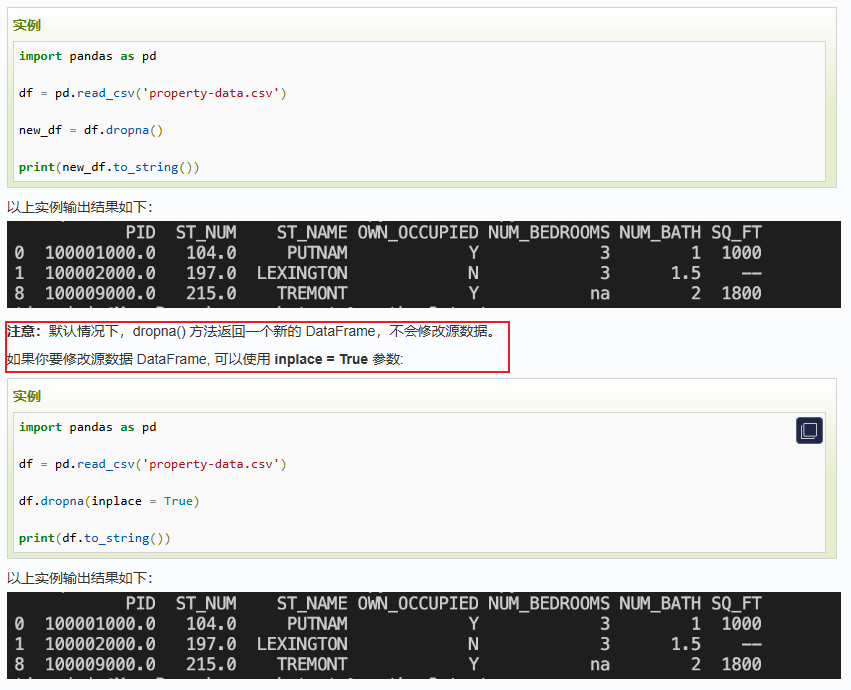
3.1 Pandas 清洗行列空值

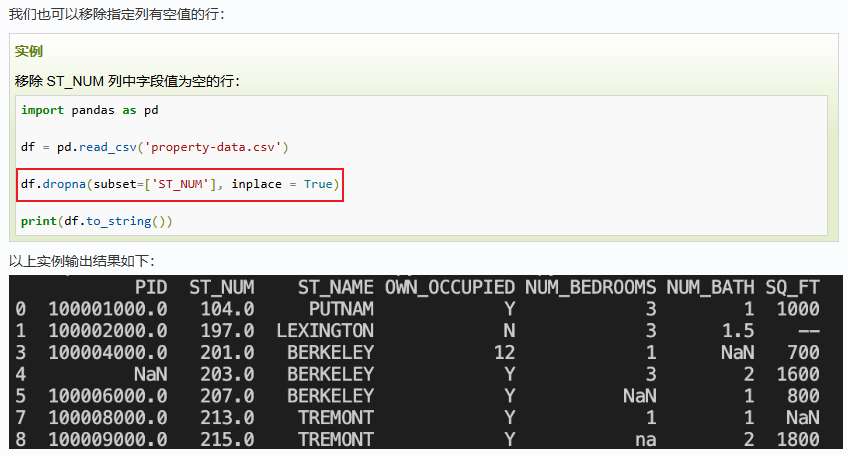
3.2 Pandas 数据清洗常用方法
一如既往,此处,只列举我目前实际用到的方法,按照方法使用的频率高低进行排序:



