字体格式如何解析(open-type)
字体格式如何解析(open-type)
当前项目源码
首先需要了解字体的格式,字体的格式是ttf(TrueType Font),它是一种用于计算机显示的矢量字体格式。
字体是一种二进制文件,需要用二进制解析的思想进行解析。
比如:我们参考微软的字体文档
当然还有苹果字体文档
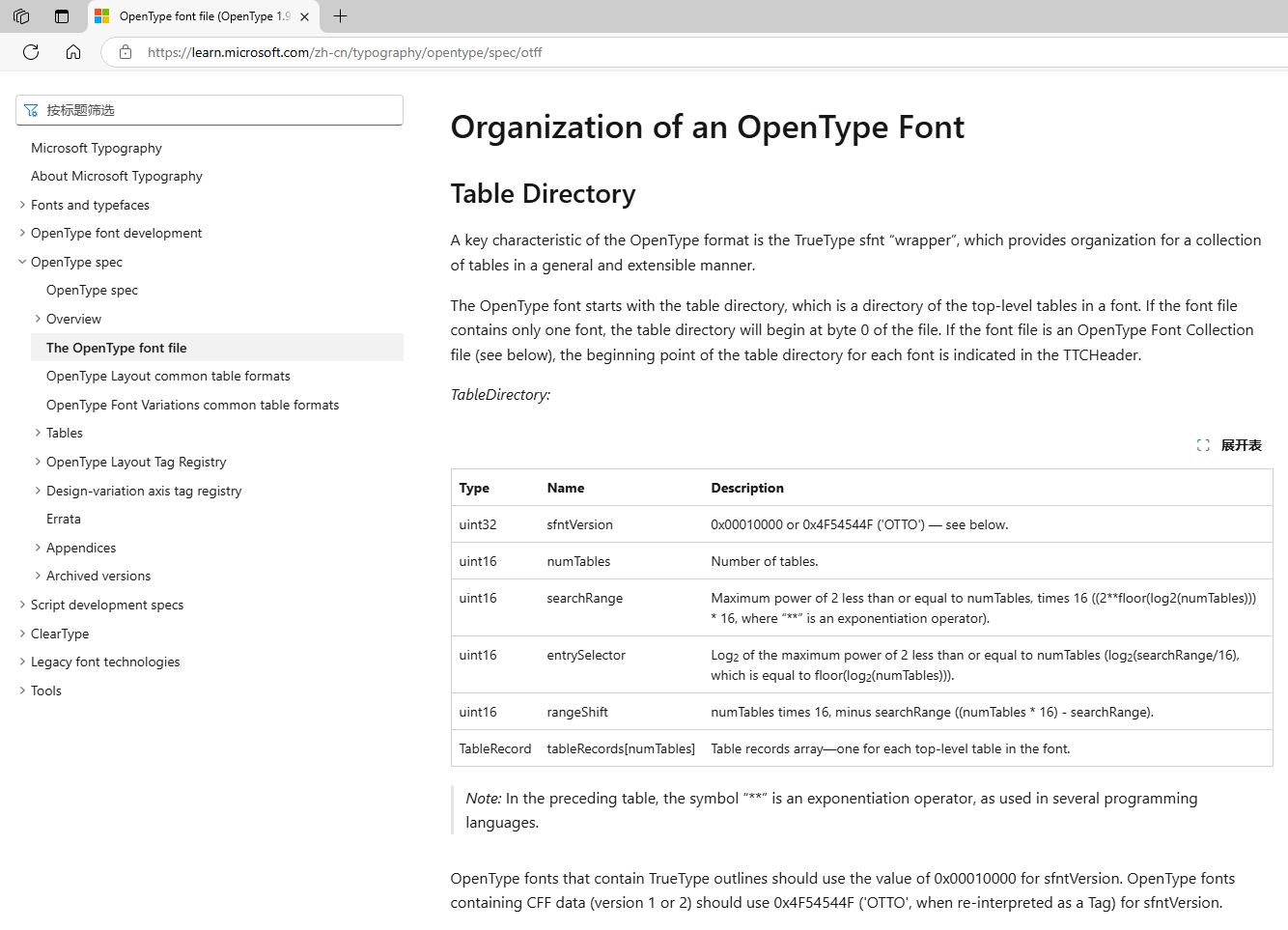
第一个参数是 uint32类型 解释为:sfntVersion 就是字体的版本号,如果是0x00010000就是ttf格式,如果是0x00020000就是otf格式
如何读取呢?:
<input type="file" onchange="fileChange(this.files[0])" accept=".ttf"/>
<script>
function fileChange(file) {
let reader = new FileReader();
reader.readAsArrayBuffer(file);
reader.onload = function () {
const arrayBuffer = reader.result;
const dataView = new DataView(arrayBuffer);
const version = dataView.getUint32(0);
console.log("字体版本: 0x" + version.toString(16));
}
}
</script>
输出结果:字体版本: 0x10000
按照文档读取字体文件
文档表格中的最后一条记录TableRecord表示一个数据集合,就是一个"对象"的概念。它包含多个参数。
<input type="file" onchange="fileChange(this.files[0])" accept=".ttf"/>
<script>
function parseFont(arrayBuffer) {
let offset = 0;
const dataView = new DataView(arrayBuffer);
const version = dataView.getUint32(offset);
offset += 4;
console.log("字体版本: 0x" + version.toString(16));
const numTables = dataView.getUint16(offset);
offset += 2;
console.log("字体表数量: " + numTables);
// searchRange到rangeShift变量用于快速查找字体表,暂未用到。好像也不建议用这个参数了。直接跳过
offset += 6;
const tableDirectory = {};// 字体表的定义集合: tag-name={checksum , offset , length}
for (let i = 0; i < numTables; i++) {
// const tag = dataView.getUint32(offset);
// 将标签值转换为字符串,更容易理解
const tag = String.fromCharCode(
dataView.getUint8(offset),
dataView.getUint8(offset + 1),
dataView.getUint8(offset + 2),
dataView.getUint8(offset + 3)
);
offset += 4;
const checksum = dataView.getUint32(offset);
offset += 4;
const tableOffset = dataView.getUint32(offset);
offset += 4;
const length = dataView.getUint32(offset);
offset += 4;
tableDirectory[tag] = {checksum, offset: tableOffset, length};
}
console.log(tableDirectory);
return tableDirectory;
}
function fileChange(file) {
let reader = new FileReader();
reader.readAsArrayBuffer(file);
reader.onload = function () {
const headers = parseFont(reader.result);
}
}
</script>
-
控制台结果应该是这样的:
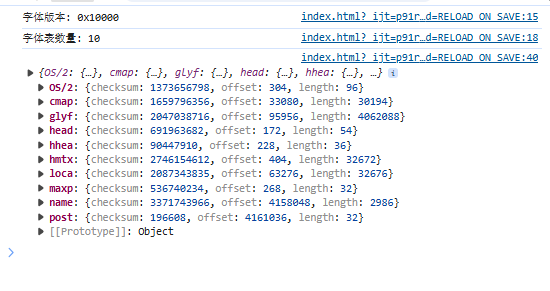
-
前面的TableRecord就是每个表的Header信息。读取完成后紧接着就是具体表的数据内容。
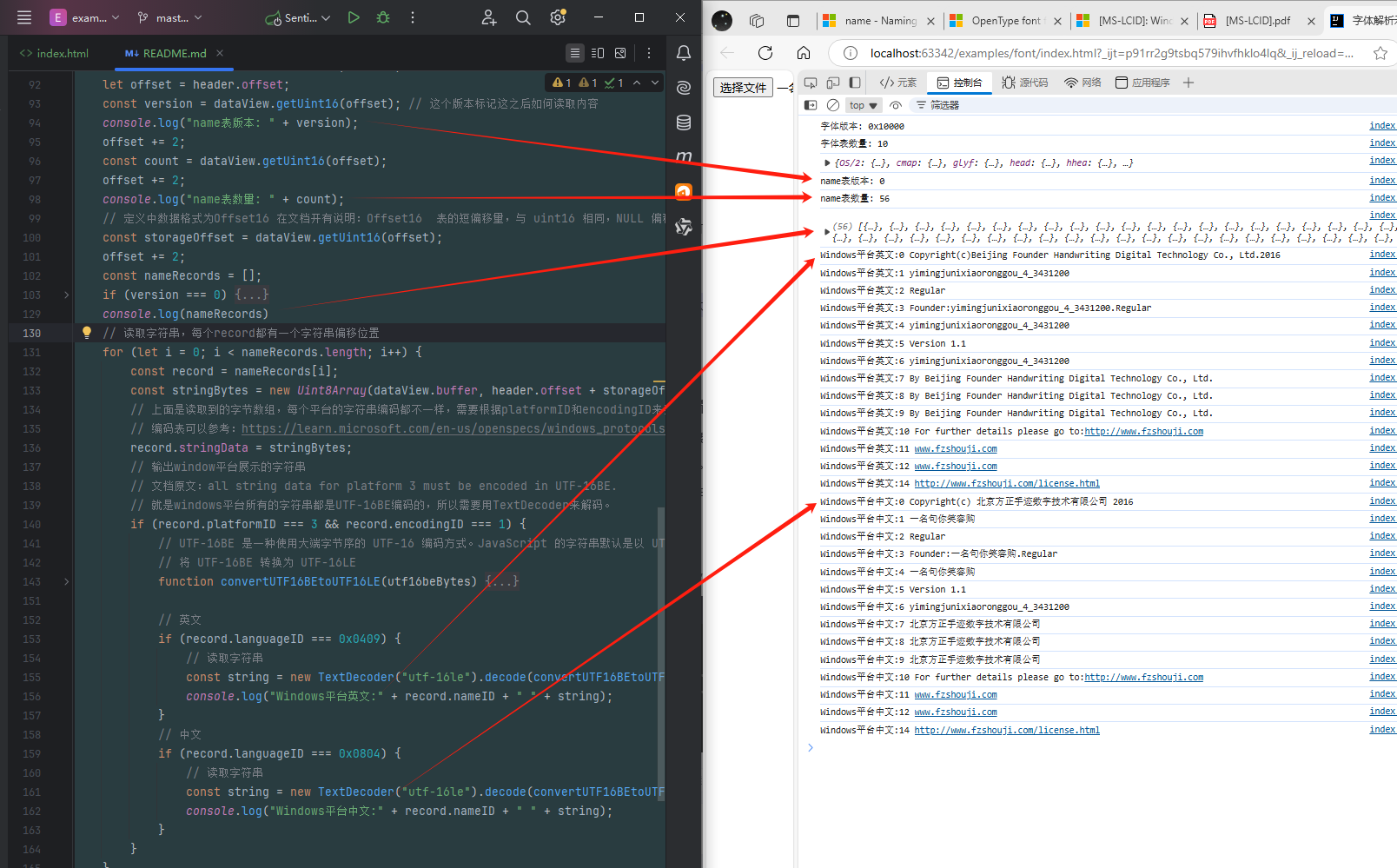
解析字体名称表(name)
解析名称表应该跳转到名称表的偏移位置,就是tableDirectory中name
查看文档字体结构name
function parseName(arrayBuffer, header) {
const dataView = new DataView(arrayBuffer);
let offset = header.offset;
const version = dataView.getUint16(offset); // 这个版本标记这之后如何读取内容
console.log("name表版本: " + version);
offset += 2;
const count = dataView.getUint16(offset);
offset += 2;
console.log("name表数量: " + count);
// 定义中数据格式为Offset16 在文档开有说明:Offset16 表的短偏移量,与 uint16 相同,NULL 偏移量 = 0x0000
const storageOffset = dataView.getUint16(offset);
offset += 2;
const nameRecords = [];
if (version === 0) {
// 版本0就按照版本0格式读取
// 有count个NameRecord
for (let i = 0; i < count; i++) {
const platformID = dataView.getUint16(offset);
offset += 2;
const encodingID = dataView.getUint16(offset);
offset += 2;
const languageID = dataView.getUint16(offset);
offset += 2;
const nameID = dataView.getUint16(offset);
offset += 2;
const length = dataView.getUint16(offset);
offset += 2;
const stringOffset = dataView.getUint16(offset);
offset += 2;
nameRecords.push({
platformID,
encodingID,
languageID,
nameID,
length,
stringOffset
});
}
}
console.log(nameRecords)
// 读取字符串,每个record都有一个字符串偏移位置
for (let i = 0; i < nameRecords.length; i++) {
const record = nameRecords[i];
const stringBytes = new Uint8Array(dataView.buffer, header.offset + storageOffset + record.stringOffset, record.length);
// 上面是读取到的字节数组,每个平台的字符串编码都不一样,需要根据platformID和encodingID来判断。
// 编码表可以参考:https://learn.microsoft.com/en-us/openspecs/windows_protocols/ms-lcid/70feba9f-294e-491e-b6eb-56532684c37f
record.stringData = stringBytes;
// 输出window平台展示的字符串
// 文档原文:all string data for platform 3 must be encoded in UTF-16BE.
// 就是windows平台所有的字符串都是UTF-16BE编码的,所以需要用TextDecoder来解码。
if (record.platformID === 3 && record.encodingID === 1) {
// UTF-16BE 是一种使用大端字节序的 UTF-16 编码方式。JavaScript 的字符串默认是以 UTF-16 编码存储的,但需要手动处理字节序问题。
// 将 UTF-16BE 转换为 UTF-16LE
function convertUTF16BEtoUTF16LE(utf16beBytes) {
const utf16leBytes = new Uint8Array(utf16beBytes.length);
for (let i = 0; i < utf16beBytes.length; i += 2) {
utf16leBytes[i] = utf16beBytes[i + 1]; // 高位字节
utf16leBytes[i + 1] = utf16beBytes[i]; // 低位字节
}
return utf16leBytes;
}
// 英文
if (record.languageID === 0x0409) {
// 读取字符串
const string = new TextDecoder("utf-16le").decode(convertUTF16BEtoUTF16LE(stringBytes));
console.log("Windows平台英文:" + record.nameID + " " + string);
}
// 中文
if (record.languageID === 0x0804) {
// 读取字符串
const string = new TextDecoder("utf-16le").decode(convertUTF16BEtoUTF16LE(stringBytes));
console.log("Windows平台中文:" + record.nameID + " " + string);
}
}
}
}
- 结果就是这样的
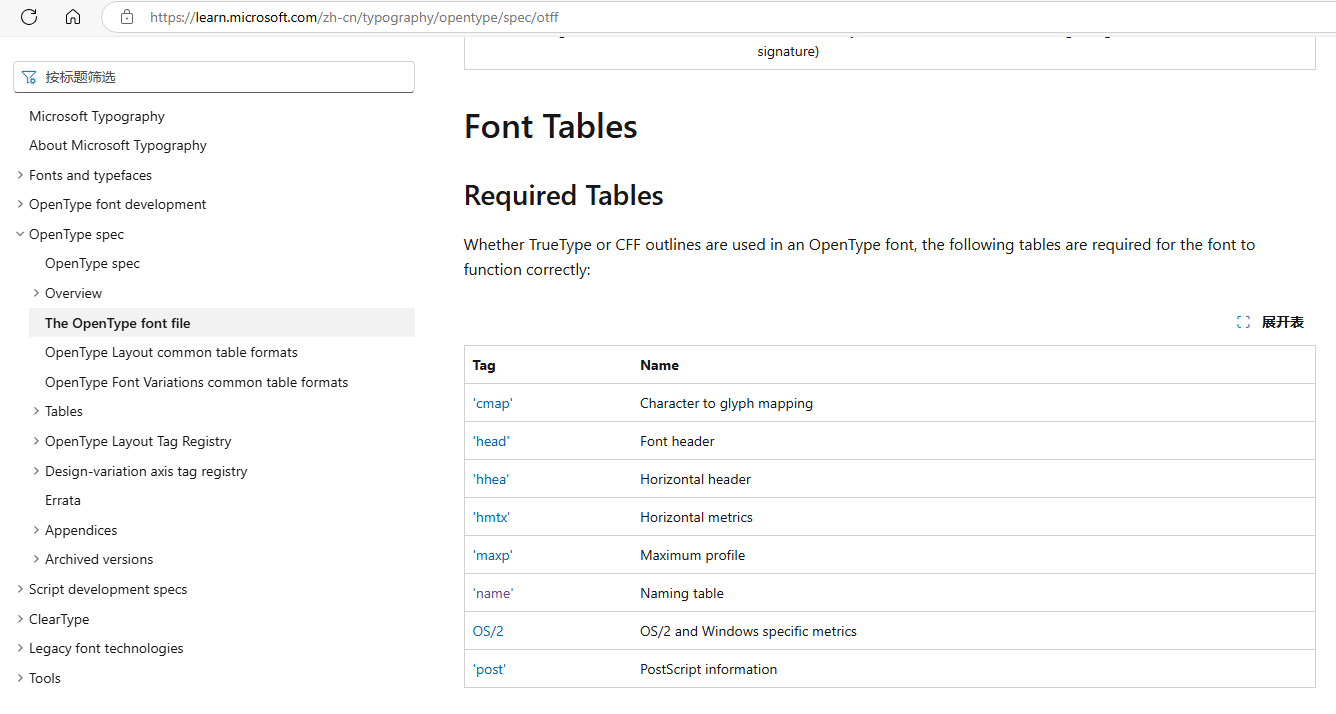
其他关键表
- TTF必要的表有:
- 假如你想看当前字体中有哪些字形
- 可以读取cmap表,这个表就是字形到字符的映射关系,也就可以找到unicode对应的第几个字形。
- 假如你想读取字形的具体坐标
- 可以读取glyf表,这个表就是字形的具体坐标。
- 当然要用loca这个表定位到具体的偏移位置,这个表就是第几个字形对应的glyf表中的偏移位置,从哪到哪。