Mybatis-Plus学习笔记
文章目录
- 认识
- 简介
- 特性
- 依赖&配置
- CRUD(IService)
- 功能概念
- 自动填充useFill
- 转换函数
- 翻页查询
- 增
- 删
- 改
- 查
- 常用注解
- @TableName
- 全局配置
- @TableId
- 全局配置主键策略
- 雪花算法
- 背景
- 什么是雪花算法
- @TableField
- 默认的驼峰转下划线
- 使用注释&自动填充
- @EnumValue
- @TableLogic
- 条件构造器
- wrapper介绍
- QueryWrapper
- 组装查询条件
- 组装排序条件
- 组装select子句
- 实现子查询
- UpdateWrapper
- condition参数
- LambdaQueryWrapper&LambdaUpdateWrapper
- 插件
- 分页插件
- 作用
- 配置
- 乐观锁
- 概念
- 案例
- 使用
- 通用枚举
- 创建通用枚举类型
- @EnumValue
- 配置扫描通用枚举
- 多数据源
- 依赖
- 配置
认识
简介
MyBatis-Plus (简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为 简化开发、提高效率而生。Mybatis-Plus提供了通用的Mapper和Service,可以在不编写任何SQL语句的前提下,快速的实现单表的增删改查(CURD),批量,逻辑删除,分页等操作。只要把MyBatis-Plus的特性到优秀插件,以及多数据源的配置进行详细讲解。
特性
- 无侵入性:只增强不改变,引入后对现有工程无影响。
- 损耗小:启动自动注入基本 CURD,性能基本无损耗,可直接面向对象操作。
- 强大的 CRUD 操作:内置通用 Mapper 和 Service,少量配置实现单表大部分 CRUD;拥有强大条件构造器满足各种需求。
- 支持 Lambda 形式调用:通过 Lambda 表达式方便编写查询条件,避免字段写错。
- 支持主键自动生成:有 4 种主键策略,含分布式唯一 ID 生成器 - Sequence,可自由配置解决主键问题。
- 支持 ActiveRecord 模式:实体类继承 Model 类即可进行强大的 CRUD 操作。
- 支持自定义全局通用操作:支持全局通用方法注入,一次编写多处使用。
- 内置代码生成器:通过代码或 Maven 插件快速生成 Mapper、Model、Service、Controller 层代码,支持模板引擎,有超多自定义配置。
- 内置分页插件:基于 MyBatis 物理分页,配置后分页操作如同普通 List 查询。
- 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等。
- 内置性能分析插件:可输出 SQL 语句及其执行时间,开发测试时启用能快速找出慢查询。
- 内置全局拦截插件:智能分析阻断全表 delete、update 操作,也可自定义拦截规则防止误操作。
依赖&配置
依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
配置文件:
spring:
datasource:
url: jdbc:mysql://localhost:3306/team_blog?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl//开启日志
CRUD(IService)
IService中的约40个方法都理解了,BaseMapper中的18个都可以理解。
BaseMapper包含Map(代表字段–值),Batch(批量),QueryWrapper,比较好理解。
功能概念
自动填充useFill
自动填充功能能够在插入、更新操作时自动为实体类的某些字段赋值,比如创建时间、更新时间等。当 useFill 为 true 时,会启用自动填充功能;为 false 时,则不启用。
启用自动填充功能,在执行删除操作时,如果使用的是逻辑删除,系统会自动为逻辑删除相关的字段(如删除时间)进行赋值。例如,当你调用 removeById 方法时,除了将 deleted 字段标记为已删除状态,还会自动填充删除时间字段。
而其中 @TableField()z中的 fill 属性则用于指定该字段在特定操作时的自动填充策略。
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createTime;
@TableField(fill = FieldFill.UPDATE)
private LocalDateTime updateTime;
转换函数
Function<? super Object, V> mapper:这是一个 Java 8 的函数式接口 Function,它接收一个参数并返回一个结果。? super Object 表示该函数可以接收 Object 类型或者其超类型的参数,V 是泛型类型,代表转换后结果的类型。此函数用于将查询结果转换为你期望的类型。
拿这个函数举例:
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
-----------测试类-----------
@Test
public void getObj(){
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.lambda().eq(User::getUsername,"lilililili");
//使用传入的转换函数 mapper 对查询结果进行转换,最终返回转换后的结果。
Function<User, String> mapper = user -> {
return "---------------"+user.getUsername()+"xxxxxxxxxxx";
};
System.out.println(userService.getObj(queryWrapper, mapper));
}
------------------UserService--------------
String getObj(QueryWrapper<User> queryWrapper, Function<User, String> mapper);
------------UserServiceImpl-----------
@Override
public String getObj(QueryWrapper<User> queryWrapper, Function<User, String> mapper) {
User user = userMapper.selectOne(queryWrapper);
if (user != null) {
return mapper.apply(user);
}
return null;
}
翻页查询
-----------UserServiceImpl-------------
@Override
public IPage<User> pageMaps(Page<User> userPage, QueryWrapper<User> queryWrapper) {
Page<User> userPage1 = userMapper.selectPage(userPage, queryWrapper);
IPage<User> mapIPage = new Page<>(userPage1.getCurrent(), userPage1.getSize(),userPage1.getTotal());
mapIPage.setRecords(userPage1.getRecords());
return mapIPage;
}
-------------UserService--------
IPage<User> pageMaps(Page<User> userPage, QueryWrapper<User> queryWrapper);
-----------测试类---------
@Test
public void pageMaps(){
Page<User> userPage = new Page<>(1,2);
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.lambda().eq(User::getUsername,"luxiya");
IPage<User> page = userService.pageMaps(userPage, queryWrapper);
System.out.println(page.getRecords());
}
增
//传实体类,插入一条对象
default boolean save(T entity)
//传入实体类集合(如List),插入集合中的所有对象。即批量插入
default boolean saveBatch(Collection<T> entityList)
//batchSize是插入批次数量,每次插入batchSize条记录
boolean saveBatch(Collection<T> entityList, int batchSize);
//批量插入或修改,有记录就修改,没有就插入
default boolean saveOrUpdateBatch(Collection<T> entityList)
//有batchSize的插入或修改
boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize);
删
//根据主键id删除
default boolean removeById(Serializable id)
//是否启用自动填充功能
default boolean removeById(Serializable id, boolean useFill)
//传实体类进行删除,其余条件为where
default boolean removeById(T entity)
//Map相当于“字段--值”,根据字段进行删除。sql语句就是where
default boolean removeByMap(Map<String, Object> columnMap)
//根据wrapper进行删除
default boolean remove(Wrapper<T> queryWrapper)
//批量删除,集合可以是实体类或主键id
default boolean removeByIds(Collection<?> list)
//是否其中自动填充的批量删除
default boolean removeByIds(Collection<?> list, boolean useFill)
//根据主键id进行批量删除
default boolean removeBatchByIds(Collection<?> list)
//根据主键id进行批量删除,可开启自动填充
default boolean removeBatchByIds(Collection<?> list, boolean useFill)
//指定每批次插入数量
default boolean removeBatchByIds(Collection<?> list, int batchSize)
改
default boolean update(T entity, Wrapper<T> updateWrapper)
//批量更改
boolean updateBatchById(Collection<T> entityList, int batchSize);
//指定每批次插入数量
boolean updateBatchById(Collection<T> entityList, int batchSize);
//有就更新,没有就插入
boolean saveOrUpdate(T entity);
查
//主键id进行查询
default T getById(Serializable id)
//批量查询
default List<T> listByIds(Collection<? extends Serializable> idList)
//mp的键--值代表:字段--值,根据map进行查询
default List<T> listByMap(Map<String, Object> columnMap)
//获取一个,如果有多个,报错
default T getOne(Wrapper<T> queryWrapper)
//有多个是否抛出异常。如果否,会返回查询的第一个记录。
T getOne(Wrapper<T> queryWrapper, boolean throwEx);
//用键值对接收,键--值代表:字段--值。只有一个
Map<String, Object> getMap(Wrapper<T> queryWrapper);
default List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper)
default List<Map<String, Object>> listMaps()
//mapper是转换函数
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
default List<Object> listObjs()
default <V> List<V> listObjs(Function<? super Object, V> mapper)
default List<Object> listObjs(Wrapper<T> queryWrapper)
//查询总记录数
default long count()
default long count(Wrapper<T> queryWrapper)
//查询列表
default List<T> list(Wrapper<T> queryWrapper)
default List<T> list()
//翻页查询
default <E extends IPage<T>> E page(E page, Wrapper<T> queryWrapper)
常用注解
@TableName
用于指定实体类对应的数据库表名。@TableField("username") 表明 name 字段对应数据库表中的 username 列;@TableField(fill = FieldFill.INSERT) 表示 createTime 字段在插入操作时自动填充。
@TableName(value ="user")
@Data
public class User implements Serializable {
//........
}
全局配置
也可以在配置文件中进行全局配置:
mybatis-plus:
global-config:
db-config:
#配置表的默认前缀
table-prefix: t_
一旦你在实体类里用 @TableName 注解指定了表名,全局表前缀配置就不会对该实体类起作用。
@TableId
mybatis-plus只会默认id为主键,如果是uid或者主键不是id,则需要使用该注解。
用于指定实体类中的主键字段,同时可以设置主键的生成策略。 value 属性指定了数据库表中的主键字段名,type 属性指定了主键的生成策略,IdType.AUTO 表示使用数据库的自增策略。
@Data
public class User {
@TableId(value = "id", type = IdType.AUTO)
private Long id;
// 其他字段
}
全局配置主键策略
一旦你在实体类里用 @TableName 注解指定了表名,全局表前缀配置就不会对该实体类起作用。
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
#配置主键生成策略
id-type: auto
#配置表的默认前缀
table-prefix: t_
雪花算法
背景
数据库的扩展方式主要包括:业务分库、主从复制,数据库分表。
- 业务分库:电商平台,包含了用户、商品、评价、订单等几大模块,最简单的做法就是在一个数据库中分别创建users、shops、comment、order四张表。但是,随着业务规模的增大,访问量的增大,每一个模块都使用单独的数据库来进行存储,不同的业务访问不同的数据库,将原本对一个数据库的依赖拆分为对4个数据库的依赖,这样的话就变成了4个数据库同时承担压力,系统的吞吐量自然就提高了。
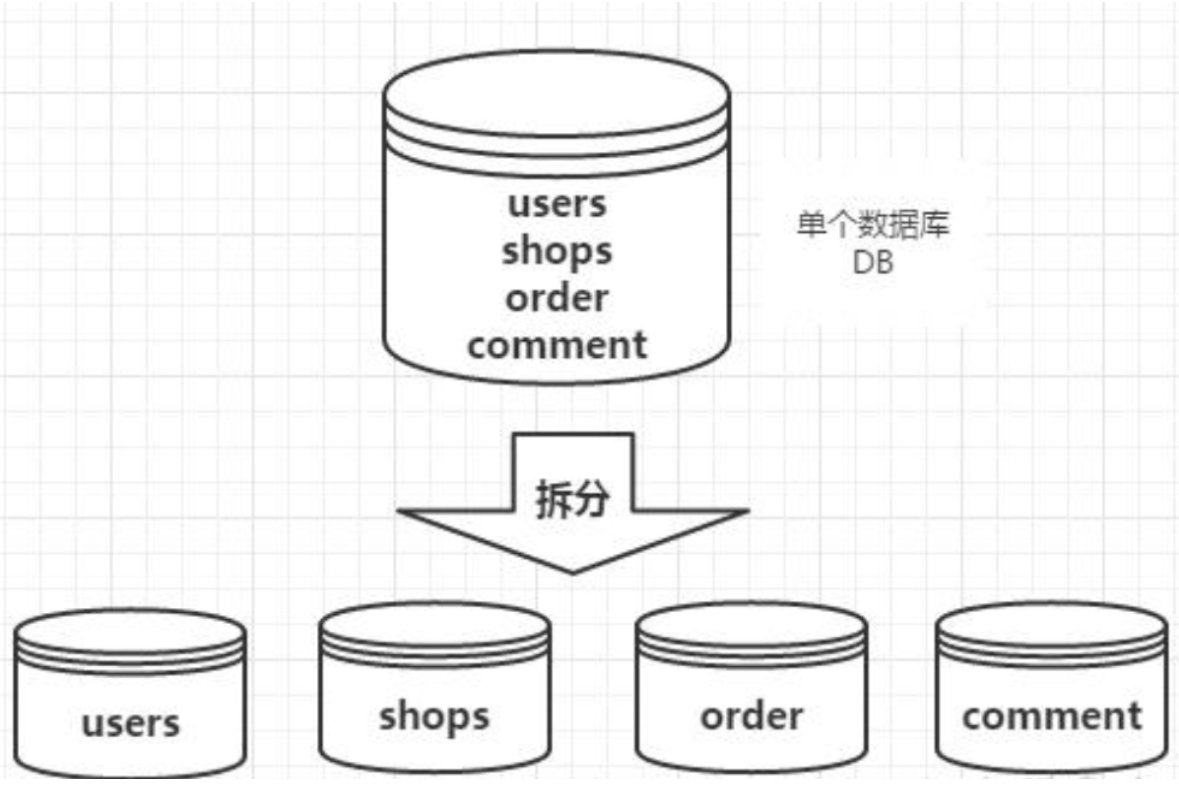
-
主从复制:置一个主数据库(Master)和多个从数据库(Slave)。主数据库负责处理所有的写操作(如插入、更新、删除数据),并将数据变更记录通过复制机制同步到从数据库。从数据库主要用于处理读操作,分担主数据库的读压力。复制方式通常有异步复制、半同步复制和全同步复制等。
-
数据库分表:单表数据拆分有两种方式:垂直分表和水平分表。
-
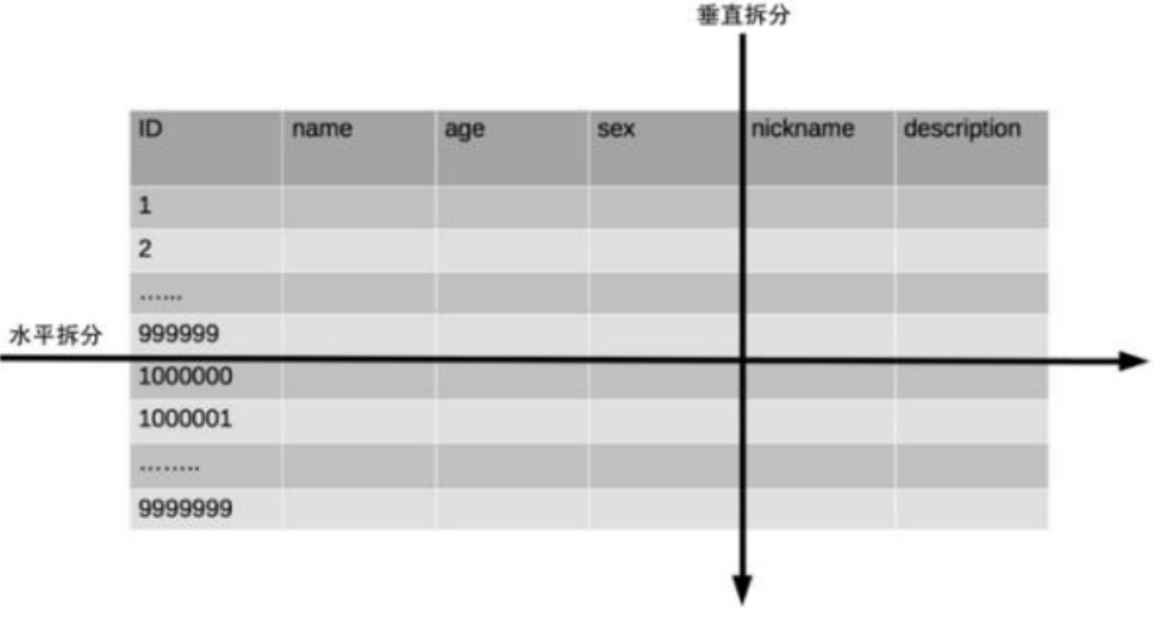
垂直分表:假设我们是一个婚恋网站,用户在筛选其他用 户的时候,主要是用 age 和 sex 两个字段进行查询,而 nickname 和 description 两个字段主要用于展 示, 一般不会在业务查询中用到。description 本身又比较长,因此我们可以将这两个字段独立到另外 一张表中,这样在查询 age 和 sex 时,就能带来一定的性能提升。
-
水平分表:水平分表相比垂直分表,会引入更多的复杂性,例如要求全局唯一的数据id该如何处理。
-
主键自增:优点——>可以随着主键递增平滑扩充数据。
缺点——>分布不均。
-
取模:优点——>表分布比较均匀。
缺点——>扩充新的表很麻烦,所有数据都需要重新分布。
-
雪花算法:优点——>整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞,并且效率较高。
-
-
什么是雪花算法
雪花算法是由Twitter公布的分布式主键算法,它能够保证不同表主键的不重复性和同一张表主键的有序性。
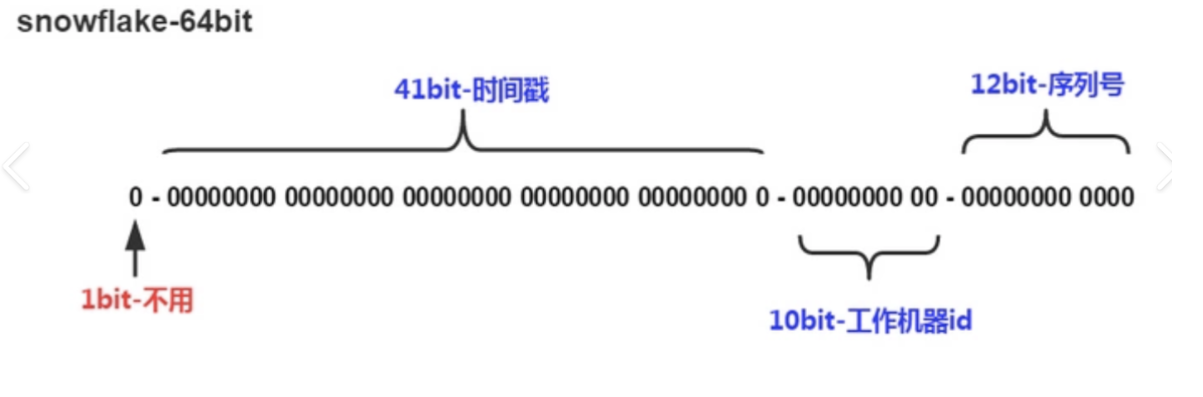
长度共64bit(一个long型)。
首先是一个符号位, 1bit标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负 数是1,id一般是正数,最高位是固定值0。
41bit时间截(毫秒级),存储的是时间截的差值(当前时间截 - 开始时间截),结果约等于69.73年。(开始时间戳是一个自定义的固定时间点,例如在某些应用中可能把系统首次启动时间设置为开始时间戳)
10bit作为机器的ID( 5个bit是数据中心, 5个bit的机器ID,可以部署在1024个节点)。
12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID)。
@TableField
默认的驼峰转下划线
若实体类中的属性使用的是驼峰命名风格,而表中的字段使用的是下划线命名风格。
例如实体类属性userName,表中字段user_name。
此时MyBatis-Plus会自动将下划线命名风格转化为驼峰命名风格。
但是如果不满足上述情况,例如实体类属性name ,表中字段username,就需要用到该注释
使用注释&自动填充
用于指定实体类字段与数据库表列的映射关系,还可以设置字段的自动填充策略等。
在IService提供的默认方法中和BaseMapper的方法中,有的方法会提供boolean useFill参数来提供是否开启自动填充服务。如下例子,在插入时就会自动填充creatTime字段,不需要人为赋值。
@Data
public class User {
private Long id;
@TableField("username")
private String name;
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createTime;
// 其他字段
}
@EnumValue
用于标记枚举类中的字段,该字段会作为枚举值存储到数据库中。在这个例子中,sex 字段会被存储到数据库中。eg:User类中的性别是SexEnum类型,user.setSex(SexEnum.MALE)插入的数据是sexName所代表的’男’。
public enum SexEnum {
MALE(1, "男"),
FEMALE(2, "女");
private Integer sex;
@EnumValue
private String sexName;
SexEnum(Integer sex, String sexName) {
this.sex = sex;
this.sexName = sexName;
}
}
@TableLogic
在数据库操作中,有时候我们不希望真正地从数据库中删除数据,而是通过修改数据的某个字段状态来标记该数据已被删除,这种方式称为逻辑删除。
@Data
@TableName("user")
public class User {
private Long id;
private String username;
// 逻辑删除字段,使用 @TableLogic 注解标记
@TableLogic
private Integer deleted;
}
配置文件:
mybatis-plus:
global-config:
db-config:
logic-not-delete-value: 0 # 未删除的值
logic-delete-value: 1 # 已删除的值
条件构造器
wrapper介绍
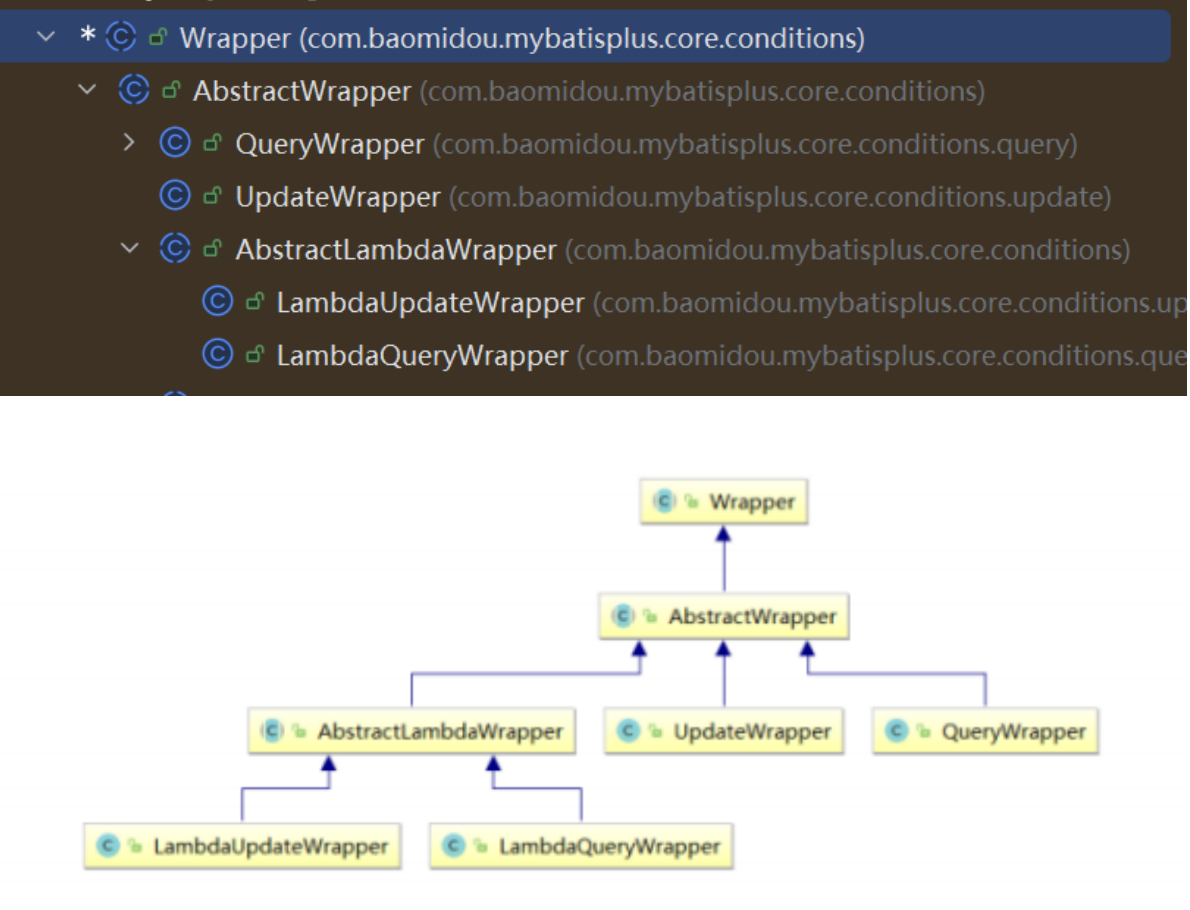
- Wrapper:最顶端父类,条件构造抽象类。
- AbstractWrapper:用于封装查询条件,最终在生成 SQL 语句时对应
where条件部分。- QueryWrapper:专门用来封装查询条件。
- UpdateWrapper:Update条件封装。
- AbstractWrapper:使用Lamda语法。
- LambdaQueryWrapper :用于Lambda语法使用的查询Wrapper
- LambdaUpdateWrapper :Lambda 更新封装Wrapper
- AbstractWrapper:用于封装查询条件,最终在生成 SQL 语句时对应
QueryWrapper
组装查询条件
- like()
- between()
- isNotNUll()
- eq()
- 大于(gt - greater than)小于(lt - less than)小于等于(le - less equal)大于等于(ge - greater equal)
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.like("username", "a")
.between("age", 20, 30)
.isNotNull("email");
组装排序条件
- orderByDesc()
- orderByAsc()
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper
.orderByDesc("age")
.orderByAsc("id");
组装select子句
查询username和age两个字段。
queryWrapper.select("username", "age");
实现子查询
queryWrapper.inSql("id", "select id from t_user where id <= 3");
这行代码在 QueryWrapper 中设置了一个 IN 类型的查询条件。IN 条件用于筛选字段值在指定集合内的记录。这里不是直接给定一个固定值的集合,而是通过子查询 select id from t_user where id <= 3 来动态获取集合。它的作用是筛选出当前操作表中,id 字段值在子查询结果(t_user 表中 id 小于等于 3 的记录的 id 值集合 )内的记录。
UpdateWrapper
//组装set子句以及修改条件
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
//lambda表达式内的逻辑优先运算
updateWrapper
.set("age", 18)
.set("email", "user@qcby.com")
.like("username", "a")
.and(i -> i.gt("age", 20).or().isNull("email"));
//这里必须要创建User对象,否则无法应用自动填充。如果没有自动填充,可以设置为null
//UPDATE t_user SET username=?, age=?,email=? WHERE (username LIKE ? AND (age > ? OR email IS NULL))
condition参数
queryWrapper.gt(condition, "age", 18); // 如果condition为true,添加age > 18的条件
//StringUtils.isNotBlank()判断某字符串是否不为空且长度不为0且不由空白符(whitespace) 构成
queryWrapper
.like(StringUtils.isNotBlank(username), "username", "a")
.ge(ageBegin != null, "age", ageBegin)
.le(ageEnd != null, "age", ageEnd);
LambdaQueryWrapper&LambdaUpdateWrapper
避免使用字符串表示字段,防止运行时错误
queryWrapper
.like(StringUtils.isNotBlank(username), User::getName, username) .ge(ageBegin != null, User::getAge, ageBegin)
.le(ageEnd != null, User::getAge, ageEnd);
List<User> users = userMapper.selectList(queryWrapper);
updateWrapper
.set(User::getAge, 18)
.set(User::getEmail, "user@qcby.com")
.like(User::getName, "a")
.and(i -> i.lt(User::getAge, 24).or().isNull(User::getEmail));
插件
分页插件
作用
- 简化分页操作:使用 MyBatis-Plus 分页插件,只需在业务代码中简单配置和调用相关方法,就能轻松实现分页查询,避免了手动编写复杂的分页 SQL 语句。例如,在执行分页查询时,只需创建一个
Page对象并传入页码和每页记录数,然后调用selectPage方法即可完成分页操作,大大减少了开发工作量。 - 支持多种数据库:MyBatis-Plus 分页插件支持多种主流数据库,如 MySQL、Oracle、SQL Server 等。这使得项目在切换数据库时,无需重新编写分页逻辑,提高了项目的可移植性和灵活性。
- 自动处理分页参数:分页插件会自动处理分页相关的参数,如计算总页数、总记录数等。开发人员可以通过返回的
IPage对象获取这些信息,方便在前端展示分页导航栏等功能。
配置
@Configuration
@MapperScan("com.luxiya.mybatis_plus.mapper")
public class MybatisPlusConfiguration {
/**
* 配置分页插件
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
------------测试----------
//设置分页参数
Page<User> page = new Page<>(1, 5);
userMapper.selectPage(page, null);
//获取分页数据
List<User> list = page.getRecords();
乐观锁
概念
-
乐观锁:在更新数据时去检查数据是否被其他事务修改过,如果被修改过,则重新获取数据,重新进行事物的相关操作。
- 乐观锁不会在读取数据时锁定数据,多个事务可以同时读取相同的数据,而不会相互阻塞。这在读取操作频繁的场景中,大大提高了系统的并发处理能力。
- 有数据不一致的风险(如再次读取时数据被删除),不适合实时性要求高的场景。额外的处理逻辑,这增加了代码的复杂性和开发工作量,并且需要考虑各种可能的情况,以确保系统的稳定性和用户体验。
-
悲观锁则持相反的观点,它认为在并发环境下,数据很容易被其他事务修改,因此在操作数据之前就会先对数据进行锁定,以防止其他事务同时对该数据进行修改。只有持有锁的事务才能对数据进行读取和修改操作,其他事务需要等待锁被释放后才能进行相应的操作。
- 可以有效地防止数据冲突,保证数据的一致性。
- 但由于锁定数据会导致其他事务等待,所以在高并发环境下可能会降低系统的并发性能。
案例
一件商品,成本价是80元,售价是100元。老板先是通知小李,说你去把商品价格增加50元。小 李正在玩游戏,耽搁了一个小时。正好一个小时后,老板觉得商品价格增加到150元,价格太高,可能会影响销量。又通知小王,你把商品价格降低30元。
此时,小李和小王同时操作商品后台系统。小李操作的时候,系统先取出商品价格100元;小王 也在操作,取出的商品价格也是100元。小李将价格加了50元,并将100+50=150元存入了数据 库;小王将商品减了30元,并将100-30=70元存入了数据库。是的,如果没有锁,小李的操作就 完全被小王的覆盖了。
现在商品价格是70元,比成本价低10元。几分钟后,这个商品很快出售了1千多件商品,老板亏1 万多。
上面的故事,如果是乐观锁,小王保存价格前,会检查下价格是否被人修改过了。如果被修改过 了,则重新取出的被修改后的价格, 150元,这样他会将120元存入数据库。如果是悲观锁,小李取出数据后,小王只能等小李操作完之后,才能对价格进行操作,也会保证 最终的价格是120元。
使用
- @Version
- 添加乐观锁插件
@Data
public class Product {
private Long id;
private String name;
private Integer price;
@Version
private Integer version;
}
------配置类-----
@Configuration
@MapperScan("com.luxiya.mybatis_plus.mapper")
public class MybatisPlusConfiguration {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
//乐观锁插件
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
}
----------测试类--------
@SpringBootTest
public class AccountsTest {
@Autowired
private AccountsMapper accountsMapper;
@Test
public void testSelect() {
Accounts a1 = accountsMapper.selectById(2);
Accounts a2 = accountsMapper.selectById(2);
a1.setBalance(a1.getBalance() + 50);
a2.setBalance(a2.getBalance() - 30);
accountsMapper.updateById(a1);
accountsMapper.updateById(a2);
Accounts a3 = accountsMapper.selectById(2);
System.out.println(a3.getBalance());
}
}
通用枚举
表中的有些字段值是固定的,例如性别(男或女),此时我们可以使用MyBatis-Plus的通用枚举 来实现。
创建通用枚举类型
@Getter
public enum SexEnum {
MALE(1, "男"),
FEMALE(2, "女");
@EnumValue
private final Integer sex;
private final String sexName;
SexEnum(Integer sex, String sexName) {
this.sex = sex;
this.sexName = sexName;
}
}
@EnumValue
@EnumValue注解能够把枚举类里的某个属性和数据库中的字段值进行映射,这样 MyBatis-Plus 在进行数据库操作时,就能自动完成枚举类型和数据库字段值之间的转换。
@Getter
public enum SexEnum {
MALE(1, "男"),
FEMALE(2, "女");
@EnumValue
private final Integer sex;
private final String sexName;
SexEnum(Integer sex, String sexName) {
this.sex = sex;
this.sexName = sexName;
}
}
----------实体类修改--------
private SexEnum sex;
---------测试类-----------
@Test
public void enumTest(){
User user = new User();
user.setUsername("luxiya");
user.setPassword("123456");
user.setSex(SexEnum.MALE);
user.setName("luxiya");
user.setBirth("1999-01-01");
userService.save(user);
}
配置扫描通用枚举
多数据源
依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>3.5.0</version>
</dependency>
配置
spring:
datasource:
dynamic:
# 设置默认的数据源或者数据源组 ,默认值即为master
primary: master
# 严格匹配数据源 ,默认false.true未匹配到指定数据源时抛异常 ,false使用默认数据源
strct: false
datasource:
master:
url: jdbc:mysql://localhost:3306/team_blog?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
slave:_1:
url: jdbc:mysql://localhost:3306/team_blog?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource