链表基本操作
文章目录
- 1、单链表
- 1.1 链表的创建
- 1.2 链表的遍历
- 1.3 链表的删除
- 1.4 链表的插入
- 1.5 链表和数组
- 2、双向链表
- 2.1 双链表的创建
- 2.2 双链表的删除
- 2.3 双链表的插入
- 2.4 双向循环链表
- 2.5 双链表优缺点
1、单链表
链表是一种物理存储单元上非连续、非顺序的存储结构,插入和删除速度快,并且不需要像数组一样预先开辟空间链表结构可以充分利用计算机内存空间,实现灵活地内存动态管理。
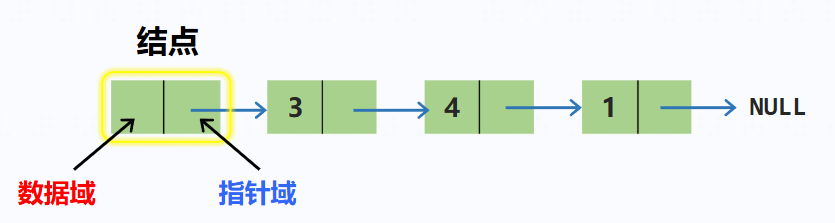
链表由一系列结点组成,每个结点包括两个部分:
- 存储数据元素的数据域
- 存储下一个结点地址的指针域
1.1 链表的创建
1.定义结构体存储结点信息
struct node {
int data; //存储当前结点的数据值
node *next; /存储下一个结点的地址
}
2.创建头尾节点
- 使用
new运算符来动态申请空间 - 使用
->结构体指针运算符来访问内部成员 - 头结点数据域通常不做存储(删除结点只能通过它前一个结点指向它后一个结点,头结点没有前一个结点)
*head.data 和 head->data 效果是一样的。
node *head, *tail; //定义头结点和尾结点
head = new node; //动态申请内存空间
head->next = NULL; //指针域初始化为空
tail = head; //此时的头结点也是尾结点
3.添加新结点
int x;
while(cin >> x) { //会自动获取到输入内容的结束位置,再终止输入
node *p = new node; //定义新结点p,动态申请新的空间
p->data = x; //给数据域赋值
p->next = NULL; //指针域初始化为空
tail->next = p; //连到尾结点后面
tail = p; //尾结点更新为当前的p
}
1.2 链表的遍历
node *p = head; //使用p作为当前结点,从头开始遍历
while(p->next != NULL) { //判断下一个结点是否为空
cout << p->next->data << " "; //输出下一个结点的数据,因为头结点无数据
p = p->next; //p更新为下一个结点
}
1.3 链表的删除
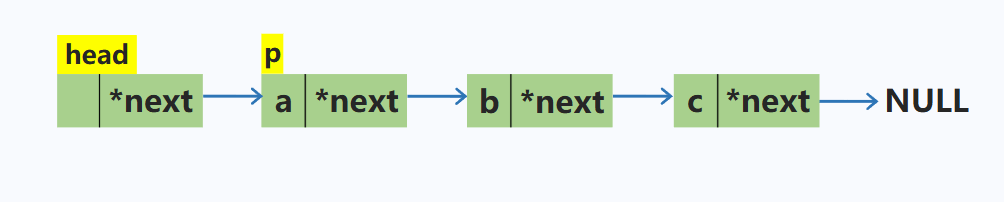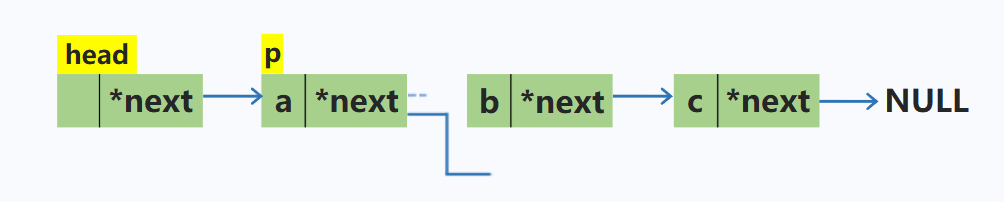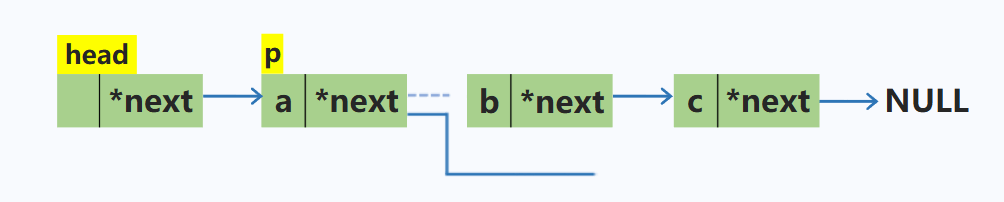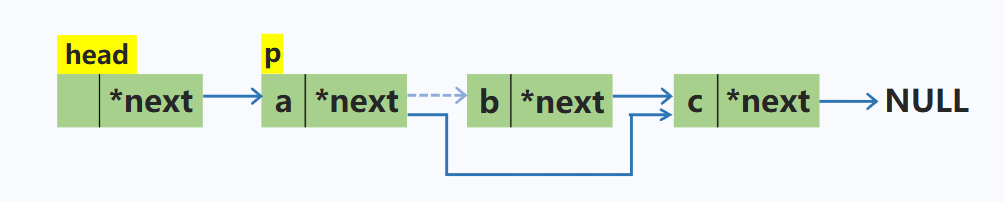
删除单链表中p结点的下一个结点
p->next = p->next->next; //将p所指的下一个结点修改为下一个结点的下一个结点
1.4 链表的插入
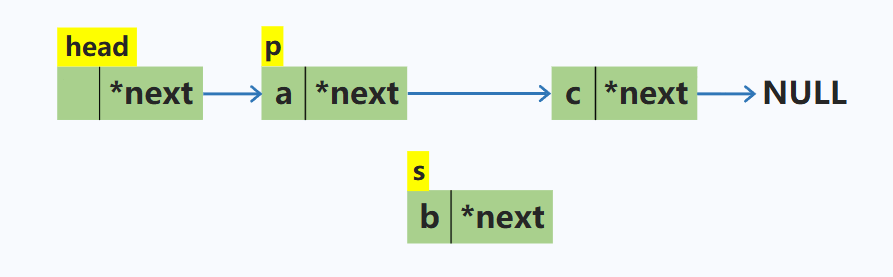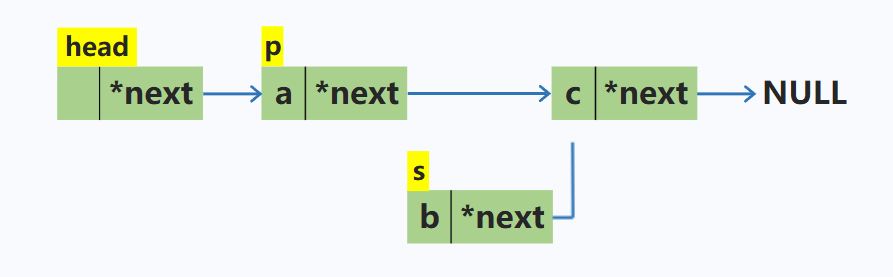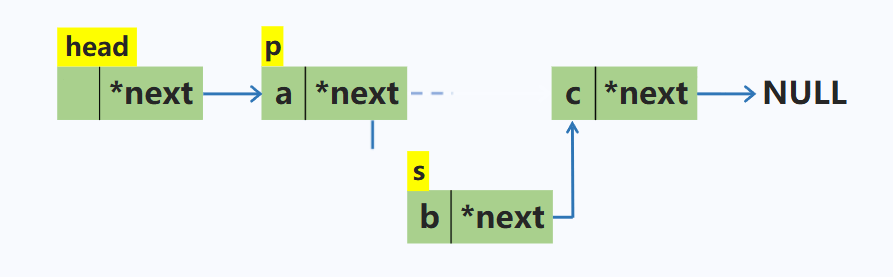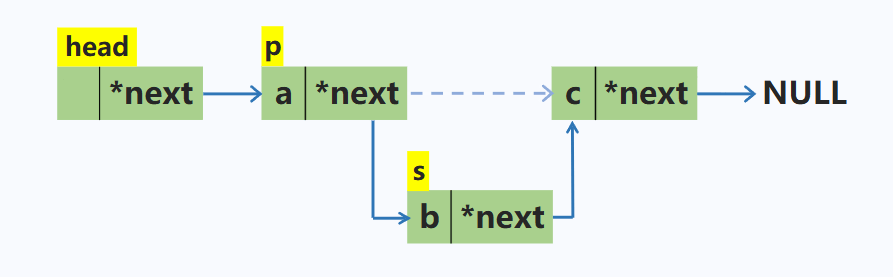
在p结点之后插入一个结点s
node *s = new node; //动态申请新的空间
s->next = p->next; //先将新结点的指针域指向p的下一个结点
p->next = s; //再将p的下一个结点修改为s
1.5 链表和数组
数组:
- 优点:
随机访问性强,查找速度快。 - 缺点:
插入和删除效率低,,可能浪费内存,,内存空间要求高,数组大小固定,不能动态拓展。
链表:
- 优点:
插入删除速度快;内存利用率高,不会浪费内存;大小没有固定,拓展很灵活。 - 缺点:
不能随机查找,必须从第一个开始遍历,查找效率低。
| 查找 | 插入 | 删除 | |
|---|---|---|---|
| 数组 | O(1) | O(n) | O(n) |
| 链表 | O(n) | O(1) | O(1) |
2、双向链表
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱,所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
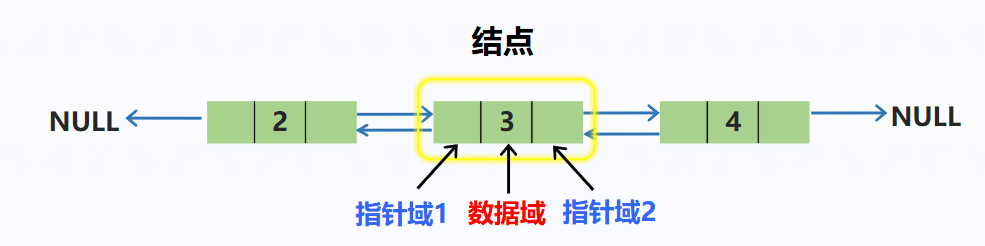
双向链表每个节点有三个部分:
- 存储数据元素的数据域
- 存储上一个节点地址的指针域
- 存储下一个结点地址的指针域
2.1 双链表的创建
1.定义结构体存储结点信息
struct node {
int data; //存储当前结点的数据值
node *pre, *next; /存储前驱和后继结点的地址
}
2.创建头尾节点
node *head, *tail; //定义头结点和尾结点
head = new node; //动态申请内存空间
head->pre = NULL; //前驱指针初始化为空
head->next = NULL; //后继指针初始化为空
tail = head; //此时的头结点也是尾结点
3.添加新结点
int x;
while(cin >> x) { //会自动获取到输入内容的结束位置,再终止输入
node *p = new node; //定义新结点p,动态申请新的空间
p->data = x; //给数据域赋值
p->pre = tail; //前驱指针指向前驱节点tail
p->next = NULL; //后继指针初始化为空
tail->next = p; //尾结点的后继指针指向p
tail = p; //尾结点更新为当前的p
}
2.2 双链表的删除
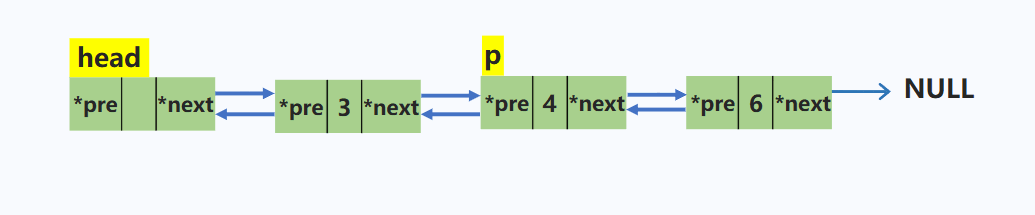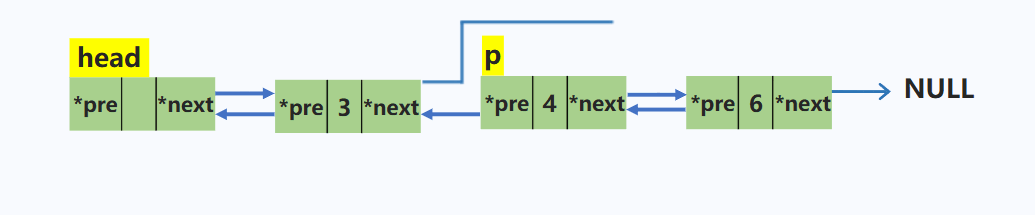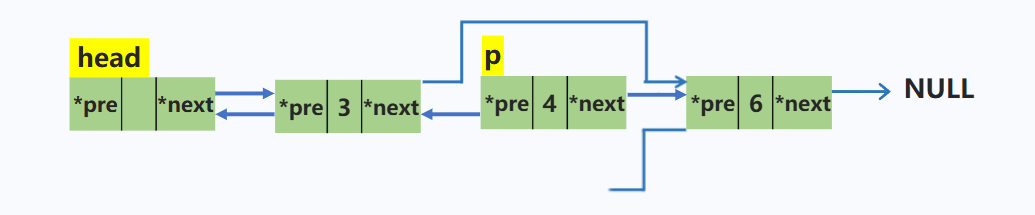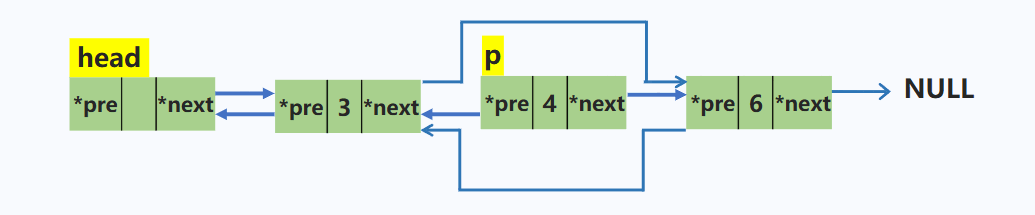
删除双链表中p结点
p->pre->next = p->next; //将p上一个结点的后继指针指向p的下一个结点
p->next->pre = p->pre; //将p下一个结点的前驱指针指向p的上一个结点
2.3 双链表的插入
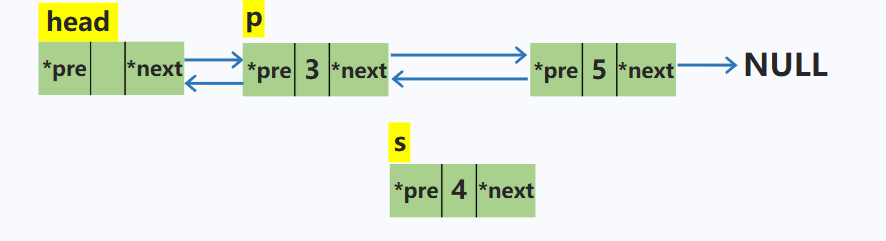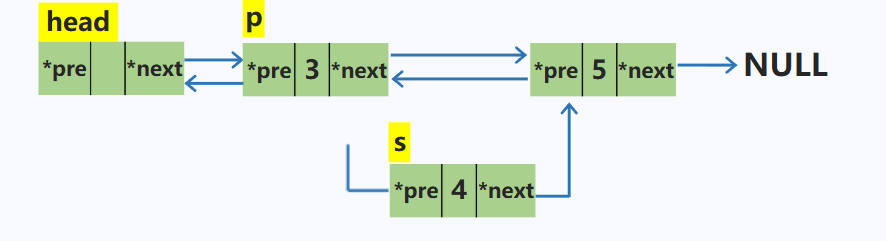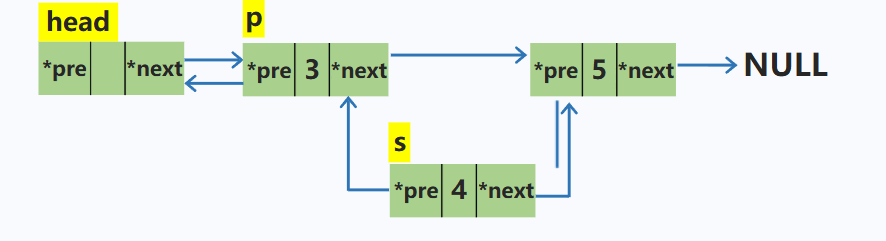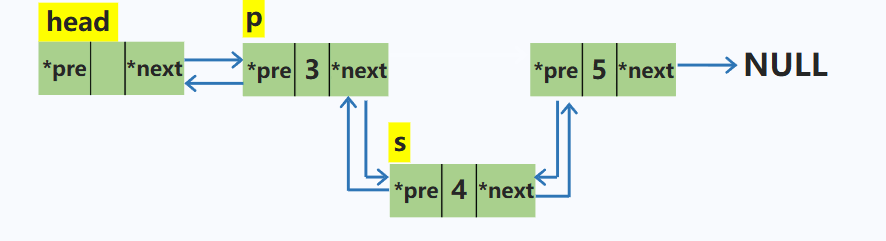
在p结点之后插入一个结点s
node *s = new node; //动态申请新的空间
s->next = p->next; //新结点的后继指针域指向p的下一个结点
s->pre = p; //新结点的前驱指针指向p
p->next->pre = s; // p的下一个结点的前驱指针指向s
p->next = s; //p的后继指针指向s
2.4 双向循环链表
双向循环链表:最后一个结点的后继指针指向头结点,且头结点的前驱指针指向最后一个结点。
head->pre = tail;
tail->next = head;
2.5 双链表优缺点
- 优点:
从双向链表中的任意一个结点开始,都可以很方便地访问前驱结点和后继结点 - 缺点:
增加删除节点复杂,需要多分配一个指针存储空间