【深度学习】处理crowdhuman数据集
因为要把crownhuman的数据集处理成yolov格式
id 0 是人头
id 1 是人
因为它吧所有文件写入到了*.odgt文件中, 我以annotation_val.odgt为例进行解析。
其实它是一个巨大的json

然后每个item是一个图片的标注信息
print(bbox[0])
{'ID': '273271,c9db000d5146c15', 'gtboxes': [{'fbox': [72, 202, 163, 503], 'tag': 'person', 'hbox': [171, 208, 62, 83], 'extra': {'box_id': 0, 'occ': 0}, 'vbox': [72, 202, 163, 398], 'head_attr': {'ignore': 0, 'occ': 0, 'unsure': 0}}, {'fbox': [199, 180, 144, 499], 'tag': 'person', 'hbox': [268, 183, 60, 83], 'extra': {'box_id': 1, 'occ': 0}, 'vbox': [199, 180, 144, 420], 'head_attr': {'ignore': 0, 'occ': 0, 'unsure': 0}}, {'fbox': [310, 200, 162, 497], 'tag': 'person', 'hbox': [363, 219, 54, 71], 'extra': {'box_id': 2, 'occ': 0}, 'vbox': [310, 200, 162, 400], 'head_attr': {'ignore': 0, 'occ': 0, 'unsure': 0}}, {'fbox': [417, 182, 139, 518], 'tag': 'person', 'hbox': [455, 190, 53, 78], 'extra': {'box_id': 3, 'occ': 0}, 'vbox': [417, 182, 139, 418], 'head_attr': {'ignore': 0, 'occ': 0, 'unsure': 0}}, {'fbox': [429, 171, 224, 511], 'tag': 'person', 'hbox': [537, 187, 55, 73], 'extra': {'box_id': 4, 'occ': 1}, 'vbox': [534, 171, 113, 431], 'head_attr': {'ignore': 0, 'occ': 0, 'unsure': 0}}, {'fbox': [543, 178, 262, 570], 'tag': 'person', 'hbox': [602, 186, 71, 93], 'extra': {'box_id': 5, 'occ': 0}, 'vbox': [543, 178, 257, 422], 'head_attr': {'ignore': 0, 'occ': 0, 'unsure': 0}}]}
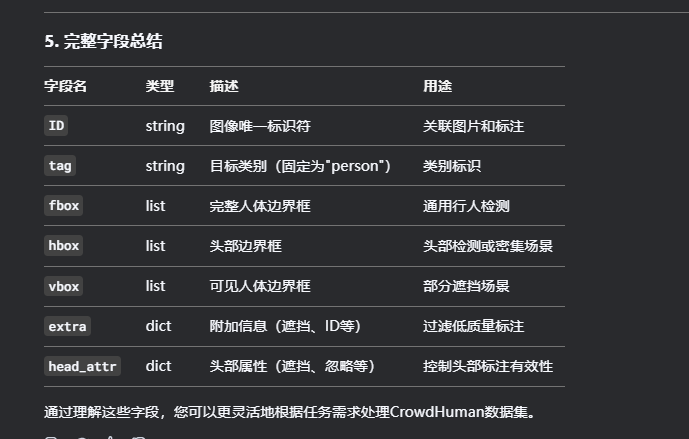
字段解析:
id 图片名称
gtboxes ground truth 标注
fbox 完整人体框
“extra”: { “ignore”: 0 }, // 是否忽略该标注(0=有效,1=忽略)
“head_attr”: { “ignore”: 0 } // 头部是否有效
{
"fbox": [72, 202, 163, 503], // 完整人体框 (x1=72, y1=202, w=163, h=503)
"tag": "person",
"hbox": [171, 208, 62, 83], // 头部框 (x1=171, y1=208, w=62, h=83)
"extra": {"box_id": 0, "occ": 0}, // 未被遮挡
"vbox": [72, 202, 163, 398], // 可见框 (x1=72, y1=202, w=163, h=398)
"head_attr": {"ignore": 0, "occ": 0, "unsure": 0} // 头部有效、未遮挡、确定
}