ReBot:通过真实-到-模拟-到-真实的机器人视频合成扩展机器人学习
25年3月来自UNC Chapel Hill、robotics & AI inst 和西雅图华盛顿大学的论文“ReBot: Scaling Robot Learning with Real-to-Sim-to-Real Robotic Video Synthesis”。
视觉-语言-动作 (VLA) 模型通过直接在 Open X-Embodiment 等真实机器人数据集上训练策略,是一种有前途的范例。然而,现实世界数据收集的高成本阻碍了进一步的数据扩展,从而限制 VLA 的泛化。本文介绍 ReBot,一种真实-到-模拟-到-真实的方法,用于扩展真实机器人数据集并将 VLA 模型适配到目标领域,这是机器人操作中的“最后一英里”部署挑战。具体而言,ReBot 在模拟中重放真实世界的机器人轨迹以使操作目标多样化(真实-到-模拟),并将模拟运动与修复的真实世界背景相结合,以合成物理上逼真且时间上一致的机器人视频(模拟-到-真实)。该方法有几个优点:1)它享受真实数据的好处,以最大限度地减少模拟-到-真实的差距;2)它利用模拟的可扩展性; 3)它可以通过全自动数据管道将预训练的 VLA 推广到目标域。在模拟和真实环境中进行的大量实验表明,ReBot 显著提高 VLA 的性能和鲁棒性。例如,在 SimplerEnv 中,使用 WidowX 机器人,ReBot 分别将 Octo 的域内性能提高 7.2% 和将 OpenVLA 的域内性能提高 21.8%,域外泛化性能提高 19.9% 和 9.4%。在使用 Franka 机器人进行真实世界评估时,ReBot 将 Octo 的成功率提高 17%,将 OpenVLA 的成功率提高 20%。
大规模真实机器人数据集已证明其对机器人学习的快速发展做出了重大贡献 [1–3],使视觉-语言-动作 (VLA) 模型能够在各种任务、环境和具身中进行学习。尽管取得了这些成就,但 VLA 在有效泛化到新场景方面仍然面临挑战,这激发对扩展数据以增强其在新目标领域性能的需求。然而,收集大规模真实机器人数据集非常昂贵,通常需要大量的精力和资源,例如机器人和人类遥控操作员,这大大限制可用性和可扩展性 [4, 5]。另一方面,模拟数据集是更易于访问且更具成本效益的替代方案,因为它们可以在没有真实世界设置的模拟环境中生成 [6– 11]。不幸的是,动作空间和观察空间中的模拟与现实差距,阻碍了机器人策略泛化到现实世界的应用 [12, 13],限制了模拟数据对推进 VLA 的有效性。
为了应对这些挑战,扩展机器人学习的一个直接策略,是从真实机器人数据集生成合成机器人视频。随着计算机视觉和生成式人工智能基础模型的快速发展,研究人员引入用于生成合成机器人视频的生成模型 [14–16]。例如,方法 [17–19] 利用文本-到-图像的修复将真实的机器人图像扩展到多样的场景。然而,它们通常面临人工智能生成的伪影问题,例如可见的瑕疵或不一致的纹理,无法生成物理上逼真且时间上一致的机器人视频。这种畸变引入新的域差距,使 VLA 难以学习稳定和连续的机器人动作,同时引发可靠性问题。此外,生成的图像可能无法精确遵循指令条件,从而限制此类方法在将 VLA 适应特定目标领域方面的有效性,导致机器人操作中的“最后一英里”部署挑战尚未解决。
本文提出Rebot,一种从真实-到-模拟-再到-真实的方法,用于扩展真实机器人数据集,如图所示。ReBot 在模拟环境中重播真实世界的机器人轨迹,以多样化操纵目标(真实-到-模拟),并将模拟动作与修复的真实世界背景相结合,以生成逼真的合成视频(模拟-到-真实),从而有效地将 VLA 模型适应目标领域。
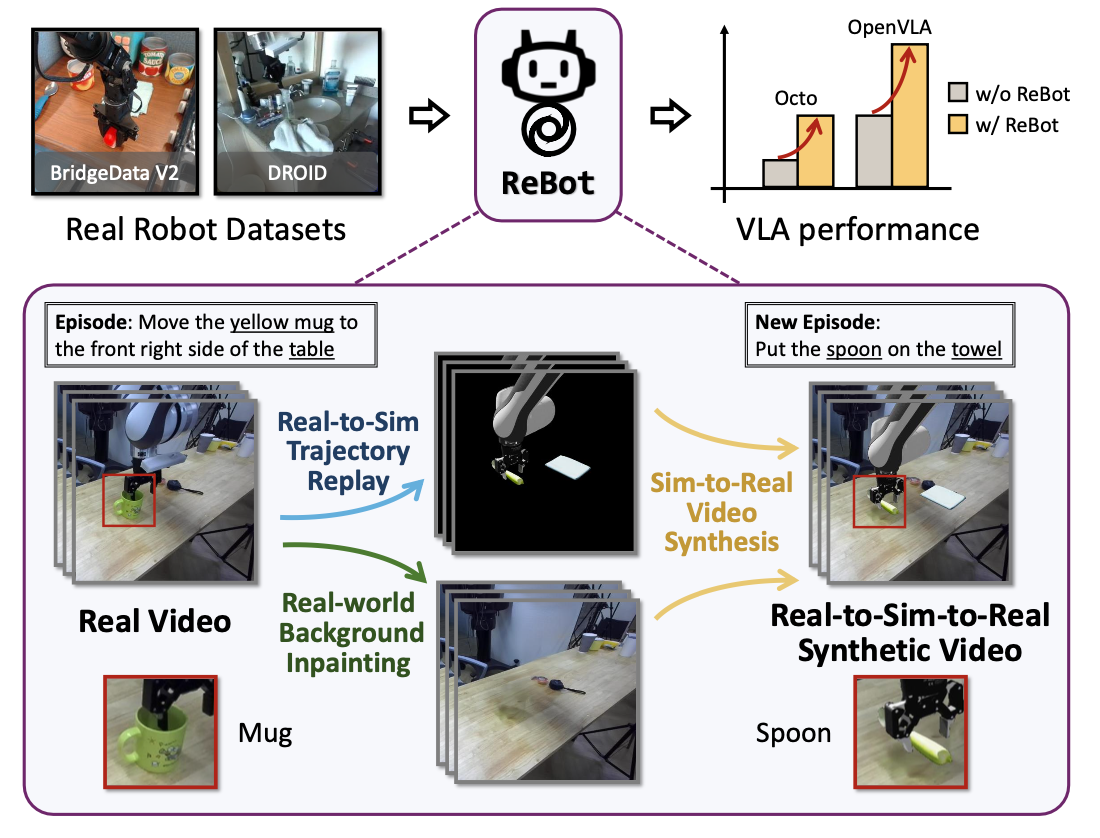
将真实机器人数据集定义为 D = {τ_i },M 个 episodes 表示为 τ_i = {o_t , a_t , L}。这里,t 表示时间步长,o_t 是视频帧,a_t 是动作,L 是语言指令。目标是基于 τ_i 生成新的合成情节 τ’_j = {o′_t , a_t , L′},以构建合成数据集 D′ = {τ’_j},用于将 VLA 模型适配到目标域。如图所示,ReBot 有三个关键步骤:A) 真实-到-模拟轨迹重放,以在模拟环境中获得模拟运动 {o_tsim};B) 在视频帧 {o_t} 上进行真实世界背景修复,以获得与任务无关的真实世界背景 {o_t^real};最后 C) 模拟-到-真实视频合成获得新帧 {o′_t}。

真实-到-模拟轨迹重放
真实到模拟过程包括:1) 在模拟环境中创建场景的空间对齐数字孪生,2) 重放真实世界的机器人轨迹以产生模拟机器人运动 {o_t^sim},3) 验证每个重放的轨迹以确保成功操纵物体。
场景解析和对齐。为了确保忠实的轨迹重放,构建机器人、摄像机和桌子的数字孪生,并将它们与初始视频帧 o_1 对齐。机器人和摄像机的原型是提前准备好的,只需要调整姿势即可完成设置。为了确定桌子的高度,从初始视频帧 o_1 获取度量深度并创建场景的点云。使用 GroundingDINO [40],自动用文本提示(“桌子”)分割桌子,并在使用四分位距(interquartile)去除异常值后,提取点云的子集。最终将过滤点的平均高度设置为桌子高度。
轨迹重放。重用现实世界的轨迹来多样化操纵的目标。首先,为了确保机器人能够成功到达模拟物体,需要将其准确地放置在原始真实物体的位置。分析夹持器动作序列以确定 t_start(夹持器闭合以抓取物体的时间)和 t_end(夹持器打开以放置物体的时间)。为了估计物体的位置,通过重放 {a_t} 获取 t_start 时的夹持器位置,并相应地放置模拟物体。同样,也可以选择性地将容器放在 t_end 时夹持器位置的桌子上。最后,使用动作序列 {a_t} 重放机器人轨迹,并记录用于操纵新物体的模拟动作 {o_t^sim}。注:所有数字孪生都忠实地与现实世界场景对齐,这确保记录的动作与现实世界背景保持一致。
重放验证。值得注意的是,轨迹重放可能会成功或失败地操纵新物体,这取决于新物体与原始现实世界物体之间的兼容性。自动验证每个合成场景中物体是否被成功操纵,并从 t_start 到 t_end 通过监控物体和夹持器之间的笛卡尔距离来丢弃失败的场景。上图中提供了一个代表性示例,表明尽管物体形状不同,但现实世界的轨迹可以成功地重复用于操纵各种物体,证明了方法的可扩展性。
真实世界背景修复
在此步骤中,通过删除原始真实机器人视频 {o_t} 中特定任务的元素(即原始真实物体和机器人),准备与模拟运动集成的任务无关真实世界背景 {o_t^real}。
物体和机器人分割。用 GroundedSAM2 [20](结合 GroundingDINO [40] 和 SAM2 [41])自动分割和跟踪原始真实物体和机器人。更具体地说,首先使用 GroundingDINO 在 o_tstart 上使用文本提示(“机器人”)来识别和分割机器人,因为机器人最可见时,性能最佳。然而,自动识别原始真实物体极具挑战性,因为其外观的详细描述(对于有效的文本提示至关重要)通常在真实机器人数据集中不可用。此外,文本提示很容易受到干扰或类似情况的影响,因此无法准确定位被操纵的物体。幸运的是,在真实-到-模拟轨迹重放期间,已经估计出 t_start 处的物体位置,现在可作为在 o_t_start 上分割真实物体的关键线索。使用相机姿势,可将 3D 物体位置投影到 o_t_start 上,为使用 SAM2 进行真实物体分割提供 2D 点提示。获得语义掩码 m_t_start(即 t_start 处的机器人和物体掩码)后,用 SAM2 将其传播到所有视频帧 {o_t},生成相应的语义掩码 {m_t}。
物体和机器人移除。给定 {o_t , m_t},最终应用 ProPainter [21](一种最先进的视频修复模型)从原始视频中删除原始真实物体和机器人,从而获得任务无关背景 {o_t^real}。注:在此步骤中还删除真实机器人,然后在合成视频 {o′_t} 中使用虚拟机器人。这可确保在目标操作过程中实现正确的遮挡和逼真的物理交互。
模拟-到-现实视频合成
最终将模拟运动 {o_tsim} 与任务无关现实世界背景 {o_treal} 结合起来,以构建新的视频帧 {o′_t}。具体来说,为了获得 o′_t,从 o_tsim 中提取机器人和被操纵的物体,并将它们合并到 o_t^real 上。然后,通过将原始指令 L 中的目标(例如,“黄色杯子”替换为“勺子”)和容器(例如,“桌子”替换为“毛巾”)替换为在轨迹重放期间使用的指令,分配新的语言指令 L′。最终,构建一个新的情节 τ’_j = {o_t′, a_t, L′}。注:由于忠实地重现现实世界的机器人轨迹,因此现实世界的动作在合成情节中保持不变。在实验中,验证使用合成数据集 D′ = {τ’_j} 调整 VLA 模型的方法有效性。
对于真实机器人数据集,利用 BridgeData V2 [42] 和 DROID [5] 中的桌面拾取和放置场景。为了对真实环境进行评估,收集 220 个真实场景来构建数据集。在 DROID 数据集中,利用从机器人相对两侧捕获的两个外部视频。对于真实-到-模拟轨迹重放中使用的模拟目标,遵循 [11, 39] 并从 Objaverse [43] 收集厨房资产。
使用 Isaac Sim 4.1 作为模拟环境,因为它具有出色的渲染质量和灵活性。基于 Isaac Lab [34] 实现真实-到-模拟轨迹重放。在 Isaac Sim 中预先构建机器人的数字孪生,根据真实机器人数据集匹配相同的机器人平台,即,对于 BridgeData V2 使用 WidowX 250 6DOF 机械臂,对于 DROID 和自己建立数据集使用带有 Robotiq 2F-85 夹持器的 Franka Panda 7DoF 机械臂。遵循 Octo 和 OpenVLA 的官方指南,使用每个任务 100 个合成 episodes 作为微调的最佳数据量。使用四个 NVIDIA A6000 GPU,对 Octo 使用批量大小为 256 的完全微调和学习率为 4 × 10−5,对 OpenVLA 使用批量大小为 32 的 LoRA 微调和学习率为 5 × 10−4。