c++的封装
封装的核心思想:
例如我们现在要封装一个 管道类Fifo
Fifo类本身不能实现IPC通信,Fifo类依赖内部存放的真正的管道去实现IPC通信
Fifo类的作用为,将真正的管道整理、封装妥当,使得通过Fifo类操作管道变得简单易懂
1 c语言中和c++中struct的区别
1.1 名字不一样
c语言中的struct我们叫结构体或者构造体
c++ 中的struct 我们 称为类
1.2 存放的数据不一样
c语言的struct结构体里面:
只能存放栈空间变量
c++的struct类里面
可以存放栈空间变量
可以存放静态存储区变量
可以存放函数的声明及定义
1.3 访问权限区别
c语言的struct里面,是没有访问权限这个概念的
c++的struct(其实是类)里面,存在访问权限的概念
访问权限总共有3种:
public、protected、private
public:公开访问
protected:受保护访问
private:私有访问
什么叫公开访问:允许类的外部访问
允许在类的外部,访问类中的成员变量 (成员属性)
struct Data d;
d.a; 这个就属于外部访问
什么叫私有访问:只允许在类的内部进行访问
class Data{
private:
int a;
public:
void func(){
a = 0; //由于在类的作用域内部访问,所以是内部访问
}
}
什么叫受保护访问:目前来说,受保护访问和私有一样,只允许内部访问
未来还有一个知识点:private成员连内部访问都做不到了,protected成员依旧只允许内部访问
2 c++中的类
不仅仅有struct,union也是类
c++中还有一个类,叫做 class
class 和 struct 有什么区别呢
class 和 struct 唯一的区别在于
struct中的所有数据,默认public
class 中的所有数据,默认private
根据c++委员会的规范要求,无论是 class 还是 struct
成员属性(变量) 要求是私有的
成员方法(函数) 要求是公开的
3 构造函数
我们总是希望,创建一个类的对象的时候(结构体类型的变量),能够在创建的同时,完成初始化工作,而不是额外再去调用初始化函数
构造函数,就能实现创建对象的同时,完成初始化
什么是构造函数:
创建一个对象的时候,自动调用的一个函数,就是构造函数
3.1 构造函数的特点
1:在创建对象的时候,自动调用对象的构造函数
2:构造函数没有返回值类型,注意不是指返回值类型为void,就是没有返回值类型,很特殊
3:构造函数的函数名,必须和类名一模一样
4:当一个类里面,不存在任何一个构造函数的时候,编译器会自动补全一个没有参数,只申请栈空间,其他什么都不做的构造函数
5:当我们手写任意版本的构造函数之后,编译器将不再补全任何构造函数
3.2 构造函数的调用形式:以 class Stu 类为例
1
Stu zs / Stu zs(参数)
调用无参构造函数 / 调用带参数的构造函数
2
Stu zs = Stu() / Stu zs = Stu(参数)
3
Stu zs = 参数
这种只允许调用一个参数版本的构造函数
4
Stu zs = {参数}
3.3 构造函数的隐式调用(3,4都是隐式调用)
第3,4种构造函数的调用形式为隐式调用
什么叫隐式调用:看不出来这里调用了一个构造函数
体现在:
class Stu{
private:
int score;
public:
// 编译器自动补全 Stu(){}
Stu(int _score){
score = _score;
}
Stu(){}
};
void func(Stu zs){
cout << 14 << endl;
};
void func(int a){
cout << 19 << endl;
}
int main(int argc,const char** argv){
Stu zs;
func(100);// 我的本意是通过构造函数第3种形式,即 Stu zs = 100这种形式,调用 19行的函数
}
类似第24行代码,我们看不出本意是调用构造函数,只会觉得是传了100
或者本意是调用构造函数,但是编译器给我们当100传进去,我们又没发现导致逻辑错误
这种很隐蔽的效果,我们称为 "隐式调用"
有一个关键字:explicit
将这个关键字写在构造函数的前面的话,会静止构造函数被隐式调用
3.4 构造函数到底做了什么
工作函数其实分2部分
1:编译器自动执行的部分,在:
构造函数的 () 后面,{} 前面
2:用户部分
Stu()
这部分为编译器自动执行的部分,用来创建并初始化成员属性的地方
{
这部分为用户部分
}
所以问题就变成了:编译器自动执行部分,到底执行了什么操作
声明并初始化类当中的所有栈空间成员属性
我们把构造函数中,编译器自动执行的,用来创建并初始化成员属性的地方,称为列表初始化
列表初始化部分的改造方式
Stu()
// 列表初始化部分,写法如下
: 成员属性名1(初始值/参数),成员属性名2(初始值/参数),...,成员属性名n(初始值/参数)
// 注意,列表初始化格式为 x(y),x永远为成员属性,y就近原则
{
}
3.5 类当中的引用
类里面如果存在引用成员属性,记得一定一定一定
要在构造函数的列表初始化部分,初始化该引用,否则编译报错
4 接口
接口:一个类专门提供给外部,用来访问该类私有成员的函数,就叫接口
换种说:专门提供给外部,访问私有成员服务的函数
接口一般就分为2种:
set接口:修改私有成员
get接口:获取、访问私有成员
5 this 指针
当对象调用成员函数的时候,会默认的在最左侧,将对象自己的地址传入
class Stu{
int score;
public:
void setScore(int _score){score = _score;}
上面这个函数,编译器编译过后会变成:
void setScore(Stu* this,int score){this->score = score}
}
Stu zs;
所以 this 指针其实就是指向了调用成员函数的对象地址的一个指针
注意:this 指针是一个指针常量,指向不能变
“常量指针”: 本质是一个指针,什么样的指针?指向常量的指针,所以指针指向的地址上的数据不能变
“指针常量”: 本质是一个常量,什么样的常量?指针类型的常量,所以该指针的指向不能变
如果想要让this指针,称为一个 const XXX*,即常量指针的,const 关键字应该加在 () const{} 之间
int getScore()const{return score;}
这个位置的从const 就是用来修饰this指针的,即
编译器会将这个代码翻译成:
int getScore(const Stu* this){return this->score;}
6 get 接口中的指针问题
当类成员属性存在指针的时候、
针对该指针属性的 getter 接口:返回值必须是 const 指针,常量指针类型
如果没有返回常量指针的话,就会将私有成员的地址暴露给外部,使得外部可以绕开setter接口直接修改私有成员,这是一个非法行为
7 析构函数
当一个对象生命周期结束的时候,会自动调用该对象的析构函数
所以我们可以在析构函数里面去写那些需要善后的工作
7.1 析构函数的特点
1:当一个对象生命周期结束的时候,自动调用该对象的析构函数
2:析构函数也没有返回值类型
3:析构函数函数名也和类名一样,但是要在函数名前面加上 ~ 以表示功能和构造函数相反
4:如果我们不手写析构函数的话,编译器会自动补全一个什么都不干的析构函数
一般情况下,如果对象内部没有需要手动释放,手动关闭的数据的话,直接使用编译器自动补全的析构函数就可以了
8 拷贝构造函数
属于一种特殊的构造函数
构造函数千千万,参数随便传
但是,其中有一种参数形式,我们称之为拷贝构造函数
5:析构函数允许手动调用
但是,即使手动调用了析构函数,自动调用的那一次不会省略
手动调用析构函数的意义在于:程序如果接收到信号,意外结束的话,是不会调用析构函数
8.1 拷贝构造函数的调用时机
构造函数的目的是构建(创建)一个新的对象
拷贝的含义在于:创建出来的对象要初始化,出数值选择拷贝的对象
class Stu{
string name
};
Stu zs ; // 创建zs对象,并且没有做初始化
Stu ls = "李四" // 创建ls对象,并且将 ls.name 初始化成 "李四"
Stu ww = zs // 创建 ww 对象, 并且将 ww 中的所有属性,初始化成 zs
这个就是拷贝构造函数,拷贝了zs的所有数据,去构建新对象ww
1: 使用一个已经存在的对象,去构建一个新的对象的时候,调用拷贝构造函数
2:函数的参数是一个普通对象(非对象引用)的时候,调用拷贝构造函数
3:当函数返回值是一个对象的时候,调用拷贝构造函数
8.2 一个重要的结论及要求
从我们学了拷贝构造之后
要求大家:所有对象的函数传参、
尽可能的都是 const 类& 版本,否则容易出各种各样的编译问题
有些时候,可能参数会在函数内部发生改变,这个时候就不要传const 了
8.3 拷贝构造函数的特点
1:由于拷贝构造函数是一种特殊的构造函数,所以调用过构造函数之后,就不可能再调用拷贝构造函数了。反之同理
2:当我们写了任意构造函数,但是没写拷贝构造函数的时候,编译器依旧会为我们自动补全一个 = 赋值的拷贝构造函数
class Stu{
string name;
int age;
int score;
用编译器默认补全的拷贝构造函数
}
Stu zs("张三,",20,100);
Stu ls = zs;
编译自动补全的拷贝构造函数做了如下操作:
ls.name = zs.name
ls.age = zs.age;
ls.score = zs.score
既然编译器补全的拷贝构造函数,已经实现了拷贝功能,我们还有什么理由要去手写拷贝构造呢?
因为:
当类里面存在指针的时候
默认的拷贝构造函数做了一个指针之间的 = 赋值操作
这就导致,2个不同对象的指针,指向同一片内存空间
修改任意一个对象的指针指向的地址上的值,另一个对象会被同步修改
这种行为,我们成为 "浅拷贝"
浅拷贝:
在拷贝的时候,仅仅拷贝了指针的指向,并没有拷贝地址上的数据
深拷贝:
在拷贝的时候,拷贝的是地址上的数据,并且将拷贝的数据,存放到一个独立的内存里面去
所以,深拷贝要做以下2件事情
1:申请独立的内存
2:将被拷贝的对象中指针指向的地址上数据,拷贝当自己的地址上面去
所以:手写拷贝构造理由
防止发生浅拷贝
8.4 拷贝构造的优化问题
在当前版本的g++编译器里面,会针对拷贝构造函数和析构函数做出优化
使得 一个局部变量的生命周期变长
从而优化掉不需要调用的拷贝构造函数和析构函数,提高代码的运行效率
9 c++中的static
9.1 回顾一下 c 语言中的static
1:延长生命周期
静态局部变量
2:限制作用域
静态全局变量
上面2种情况,其实都是根据静态存储区的特点衍生出来的
静态存储区的特点:
相同作用域中的同名变量,第一次声明的时候正常声明,之后的所有声明,都会引用第一次声明的变量
9.2 C++中的static
其实c++ 中的static和 c语言中的 static遵循的特性一模一样
相同作用域中的同名变量,第一次声明的时候正常声明,之后的所有声明,都会引用第一次声明的变量
只不过,c++中static 用的地方和c语言的不一样,所以产生了不同的效果
c++中的static 用在2个地方
9.2.1 类当中的成员变量
可以从很多角度来看待这问题
1:该类的所有对象,共享静态成员变量
2:我们可以把静态成员成员变量,看成类的属性,而不是对象的属性
如果一个属性属于类的话,那么他的访问方式会多一个
class Bank{
static int rate
};
Back 工商银行;
cout << "工商银行的利率 = " << 工商银行.rate << endl;
cout << "工商银行的利率 = " << Back::rate << endl; 这种形式是新增的形式,仅限于访问类的成员属性,即静态成员属性
由于构造函数只会创建类对象里面的栈空间数据,并不会创建静态数据
所以我们需要手动去创建一个静态数据
创建方法如21行所示
第一步,在main函数前面 先写: int rate = 0 ;
表明这个变量将被创建在静态存储区
第二步,在rate前面写上 Bank:: ,表明 rate 隶属于 Bank作用域而不是全局
9.2.2 类当中的成员函数
当static修饰类当中的成员函数的时候,会发生什么呢
1:同样的,可以通过类直接调用
2:静态成员函数里面,无法访问普通成员变量,只能访问静态成员变量
因为静态成员函数中,没有this指针
10 static具体应用:单例模式
什么是单例模式:无论如何创建一个类的对象,对象数量永远 == 1,永远是同一个对象
单例模式非常适合用来写弹窗
10.1 构造函数私有化
保证构造函数不能被随意调用
10.2 如何调用私有化的构造函数:写一个公开接口
构造函数一旦私有化之后,唯一对象也无法构建了
所以我们需要写一个公开的接口,去调用私有的构造函数
10.3 公开接口写判断,是否能够调用唯一一次构造函数
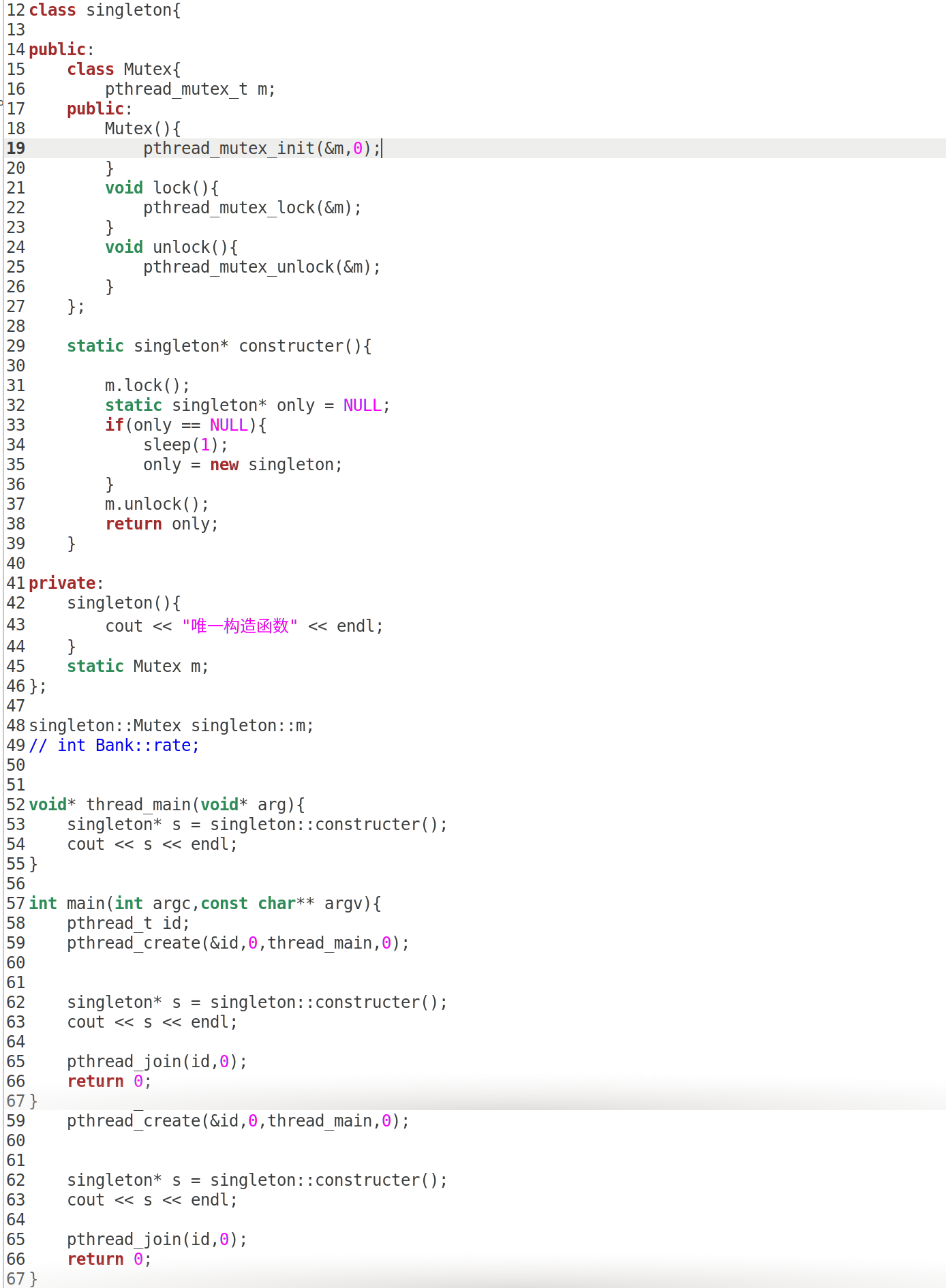
10.4 多线程下的单例模式
我们刚才写的单例模式,在多线程下是不安全的,不单例的
1 懒汉模式上互斥锁:所以我们要在单例模式的类里面上锁,上锁方式如下图
2 使用饿汉单例模式
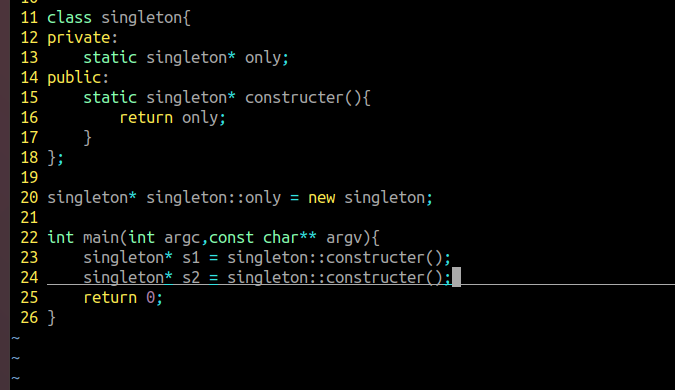
3 懒汉和饿汉的优缺点、
懒汉:
优点:节省空间
灵活性高
缺点:多线程不安全
饿汉:
优点:多线程绝对安全
缺点:浪费空间
灵活性差
11 c++ 中的堆空间
我们从单例模式中发现,malloc函数并不会调用类的构造函数
所以,在c++中,如果我们想要在堆空间上创建一个对象的话,不能使用 malloc函数
如果想要在堆空间中构建对象的话,使用运算符 :new
class Stu{
}
Stu* zs = new Stu
new的几种使用方式
使用new创建堆空间对象
1:Stu* zs = new Stu
调用 Stu 无参构造函数
2:Stu* zs = new Stu(参数)
调用 Stu 带参构造函数
3:Stu* arr = new Stu[10]
在堆空间上创建了一个拥有10个Stu对象的数组arr
所以会调用10次构造函数
注意:创建堆空间数组的时候,只能调用无参构造,无法调用带参数版本的
new 不仅仅能够在堆空间上创建对象,还可以在堆空间上创建普通 变量
int* a = new int
在堆空间上创建一个int变量,但是没有初始化
int* a = new int(19)
在堆空间上创建一个int变量,并且初始化为19
int* arr = new int[10]
在堆空间上创建了一个拥有10个int的数组,并自动初始化为0
new 和 malloc的区别
1 malloc只会申请堆空间
new 不仅仅申请堆空间,如果申请的类的堆空间的话,还会调用该类的构造函数
2 malloc 申请的堆空间不会初始化(calloc才会,但是不能指定初始值)
new申请的堆空间允许指定初始值
3 malloc是函数
new是运算符
4 malloc 是字节流申请,即malloc想申请几个字节,就能申请几个字节
new 是模块化申请堆空间,申请堆空间大小取决于数据类型的大小
释放堆空间对象:delete
1: Stu* zs = new Stu
delete zs;
释放zs指向的堆空间,并且调用 zs的析构函数
2: Stu* arr = new Stu[10]
delete arr
delete arr+1
delete arr+2
.....
delete arr+9
或者 delete[] arr
释放 arr 指向的堆空间数组,并且调用10次Stu析构函数
