存储效能驱动业务价值:星飞全闪关键业务场景性能实测报告
在数字化转型进程中,企业核心应用的性能——无论是金融交易的响应速度、AI 模型的训练效率,还是实时数据分析的及时性——都直接影响着业务竞争力。为客观评估存储架构对业务场景的支撑能力,我们针对 OLTP 事务处理、AI 向量检索、实时数仓三大关键负载,在同等硬件环境下实测对比 XSKY 星飞全闪存储与业界标杆的 VMware vSAN (ESA 全闪架构)的性能表现。本文聚焦全闪分布式存储架构设计对应用性能的底层影响,从技术架构差异到实测数据,揭示存储软件栈的创新如何释放硬件潜能。
首先,让我们看一下 XSKY 星飞与 VMware vSAN ESA 的架构差异。
vSAN 架构的演进之路
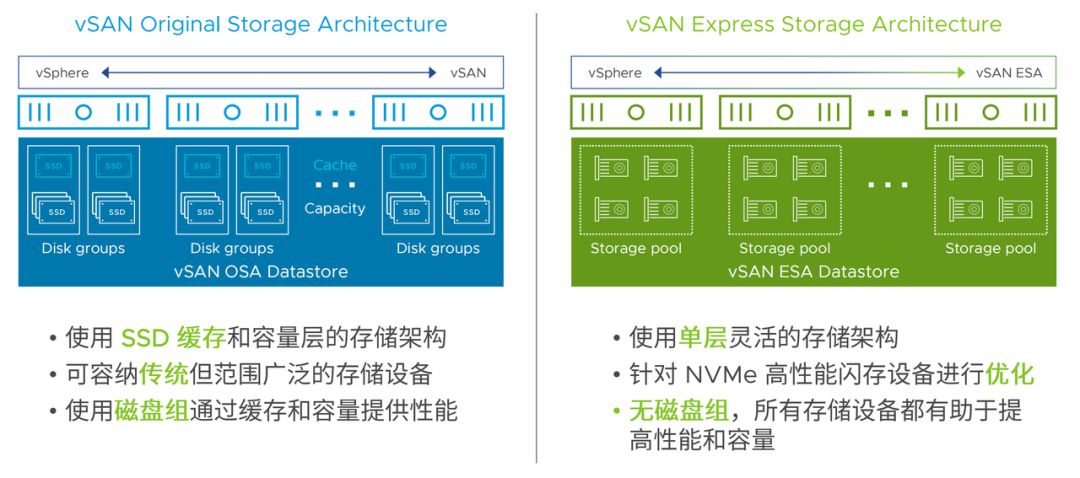
OSA 架构(2014):软件定义存储先驱
2014 年,vSAN OSA 架构以双层存储介质管理模型重新定义虚拟化平台存储范式。它采用 SSD 缓存层 + HDD/SSD 容量层设计,智能缓存算法提升机械硬盘集群随机读性能 3-5 倍,平衡了成本与性能。同时,作为首个嵌入 vSphere 内核的分布式存储,它统一管理存储与计算资源调度,使 I/O 路径缩短 40%,时延降至 2ms 以内。
ESA 架构(2022):全闪时代的飞跃
2022 年 VMware 推出 vSAN ESA 架构,针对全闪存场景深度优化。单层架构设计在 NVMe 的 TLC 存储设备上,简化存储结构,提高数据访问效率。日志结构文件系统(追加写)提升高并发写入性能。融合 RAID 与压缩技术,保障数据安全同时提高磁盘利用率和存储性能。对 RDMA 网络的支持,提升了系统性能和吞吐量。
不过,为兼顾历史兼容性,ESA 软件栈未采用先进的 I/O 路径设计,卷属主控制器为本地节点,存储介质访问模型是 Shared-Nothing,限制了单卷和集群性能。测试显示,ESA 使用 RDMA 对 IOPS 提升不显著。
vSAN ESA 堪称具有里程碑意义的 “改良架构”,巧妙平衡了历史与未来。VMware 在改进过程中展现出大局观与严谨性,虽有局限,但整体性能不俗,其研发精神值得行业尊敬。
星飞全闪架构的技术探索
架构设计理念
XSKY 在 2023 年推出的星飞全闪存储架构,在借鉴 vSAN ESA 架构先进特性的基础上,面向 AI 时代的存储需求进行了深入的演进和创新。
尤为值得关注的是,星飞全闪架构在分布式块存储领域首次实现了 Shared-Everything 架构。这种架构打破了传统分布式存储架构的限制,实现了所有节点之间的资源共享和协同工作。在 Shared-Everything 架构下,存储资源可以在整个集群中进行动态分配和调度,提高了存储资源的利用率和系统的整体性能。同时,这种架构还具备更好的扩展性和容错性,能够满足企业不断增长的存储需求和高可靠性要求。
比 vSAN ESA 更多的改进
因为我们没有历史包袱,所以相比于 vSAN ESA 架构,我们做了更多改进。
全局资源池化:突破 Shared-Nothing 架构的本地性限制
传统的 Shared-Nothing 架构存在着本地性限制,各个节点之间的资源相对独立,难以实现资源的有效共享和协同工作。星飞全闪架构通过全局资源池化技术,突破了这一限制。它将整个集群中的存储资源、计算资源等进行统一管理和调度,形成一个全局的资源池。在这个资源池中,任何节点都可以根据需要访问和使用其他节点的资源,实现了资源的高效共享和优化配置。这种全局资源池化的方式,提高了存储系统的整体性能和灵活性,能够更好地满足企业复杂多变的业务需求。
极简 I/O 路径:端到端 NVMe 和基于 RDMA 的零拷贝传输协议
星飞全闪架构采用了基于 RDMA 的零拷贝传输协议,构建了极简的 I/O 路径。在传统的存储系统中,数据传输往往需要经过多次拷贝和处理,这不仅增加了数据传输的延迟,还消耗了大量的 CPU 资源。而基于 RDMA 的零拷贝传输协议可以实现数据在内存之间的直接传输,无需 CPU 干预,大大降低了数据传输的延迟和 CPU 开销。这种极简的 I/O 路径设计,使得星飞全闪架构在时延方面表现卓越。
分布式卷服务处理:提高单卷性能 20 倍
星飞全闪架构把卷的数据服务处理分布在所有节点上,充分榨干所有存储节点上的网卡、CPU、NVMe 盘的性能。
虚拟化 Vhost 用户态直通存储:解决最后一公里的瓶颈
在虚拟化场景中,采用 Vhost 用户态直通存储技术,可以减少虚拟机 I/O 操作时 KVM 内核态和用户态的切换,降低 CPU 消耗。可以去掉 VMFS 层,把 VMFS 层中的快照克隆功能下放给底层存储实现。由此可以获得更低的时延,更高的 IOPS。
验证架构改进带来的性能提升
接下来,让我们通过一系列的性能测试,来直观地比较这两种优秀的存储架构。也来验证星飞全闪的更多改进带来的收益体现在哪里。测试环境配置
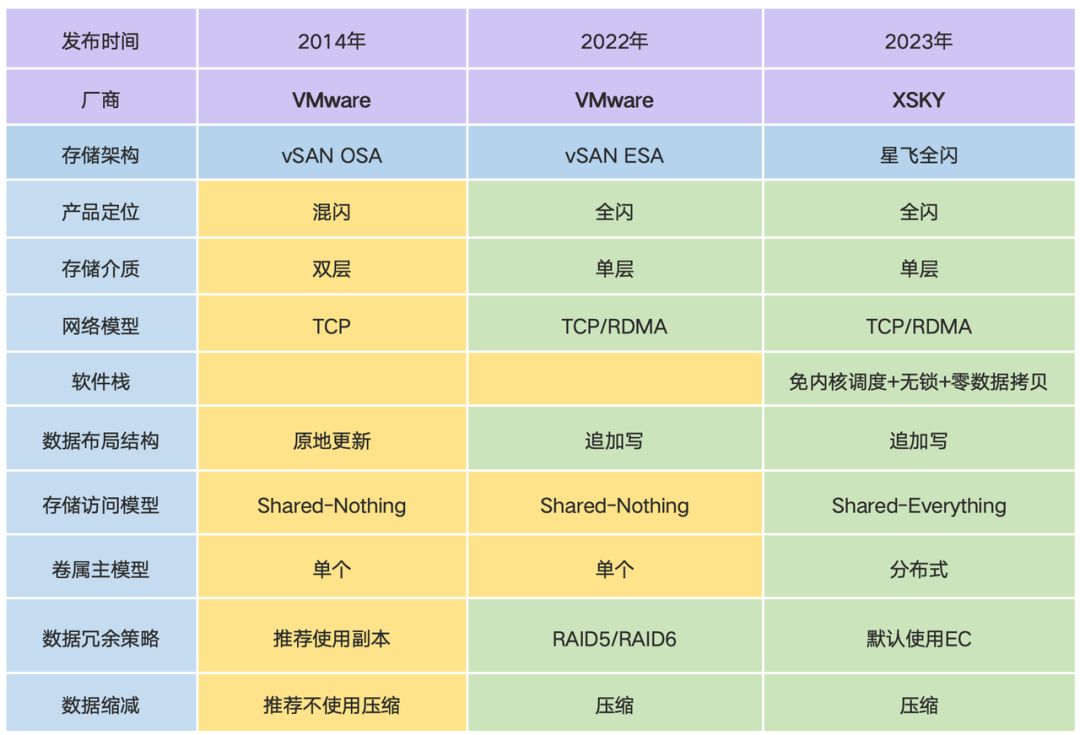
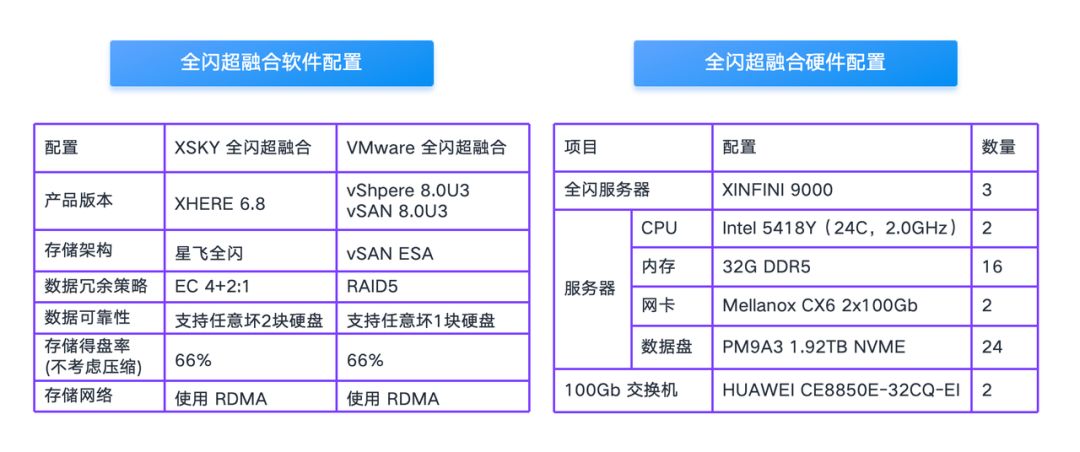
在本次测试中,我们使用相同的硬件设备进行对比测试,其中 XSKY 全闪超融合的存储架构是星飞全闪,VMware 全闪超融合的存储架构是 vSAN ESA。
星飞全闪使用的数据冗余策略是 EC 4+2:1,VMware VSAN ESA 采用的是 RAID5(因为只有 3 台,所以不支持 RAID6)。另外很多读者担心 EC 的性能比较差,无法支持数据库应用,希望这次测试能够解答大家的疑虑。
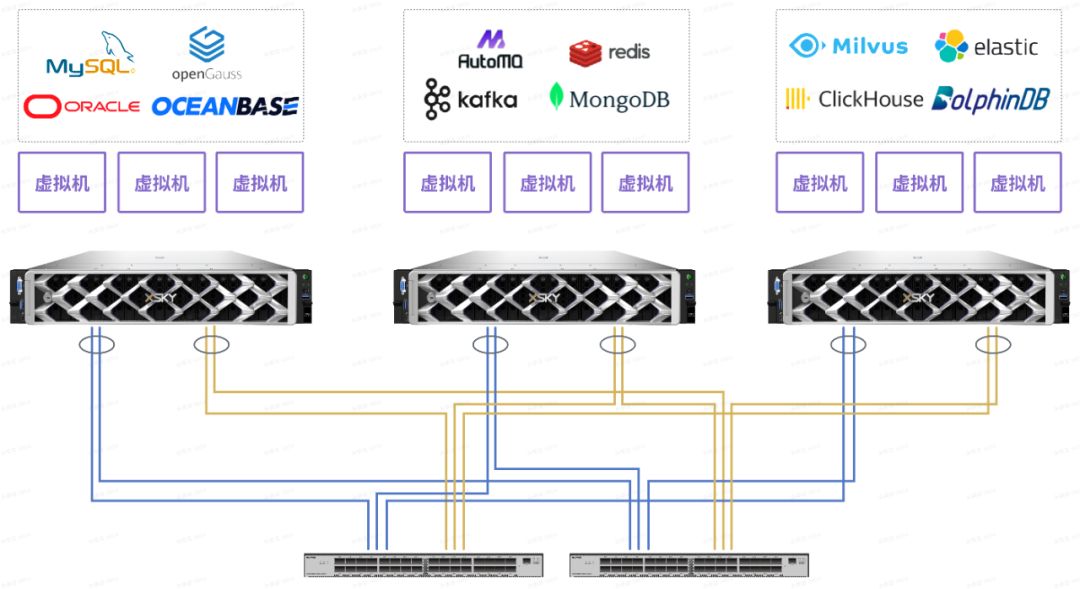
环境网络拓扑如下图所示:
存储基线性能测试
单虚拟机单卷性能对比
创建 1 台 32C32G 的虚拟机,然后挂载 1 个 1TB 的数据卷,使用 fio (3.19 版本) 进行测试。
在小块随机读、随机写、随机读写(读写比 7:3)的性能对比中,我们发现 XSKY 全闪超融合的性能是 VMware 的 15 倍~20 倍,其中 4KB 随机写 IOPS(时延在 0.5ms)是 15 倍, 4KB 随机写 IOPS(时延在 1ms)是 20 倍。
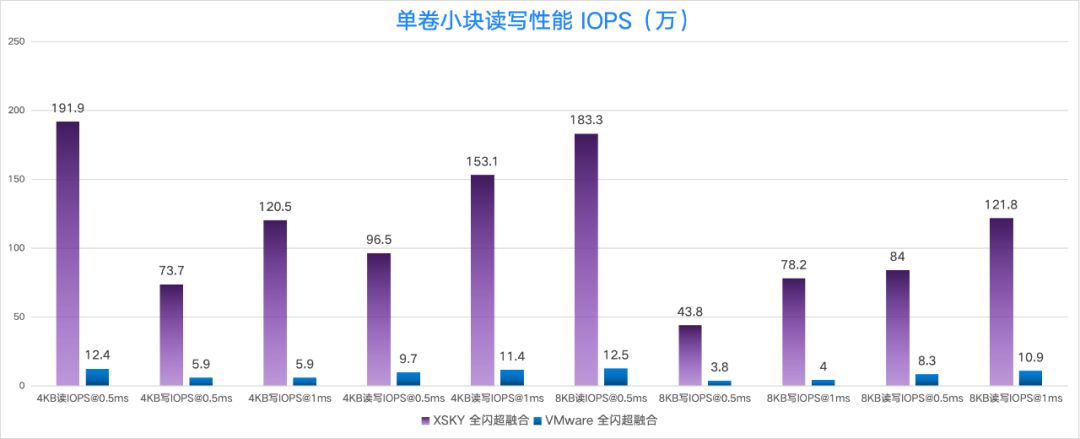
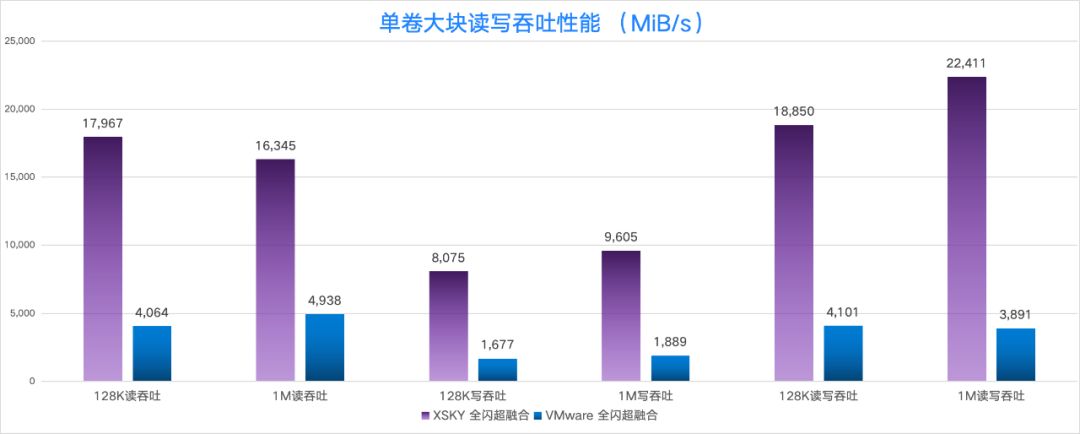
在大块读吞吐、写吞吐、读写吞吐 (读写比 7:3)的性能对比中,XSKY 全闪超融合的 1MB 读写性能是 VMware 的 5.7 倍。
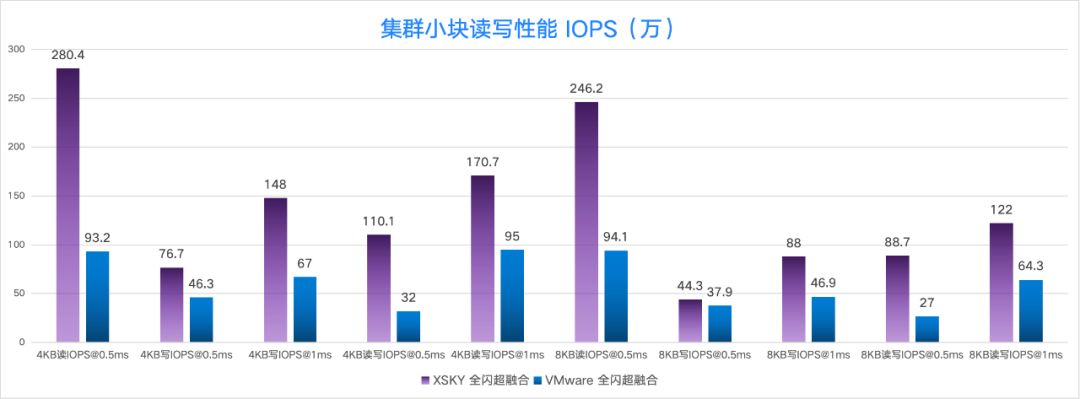
集群性能对比
创建 9 台 16C32G 的虚拟机,每个虚拟机挂载 1 个 256G 的数据卷。测试结果显示 XSKY 全闪超融合在 4KB 随机读、4KB 随机读写(读写比 7:3,且时延在 0.5ms)上的性能都是 VMware 的 3 倍。
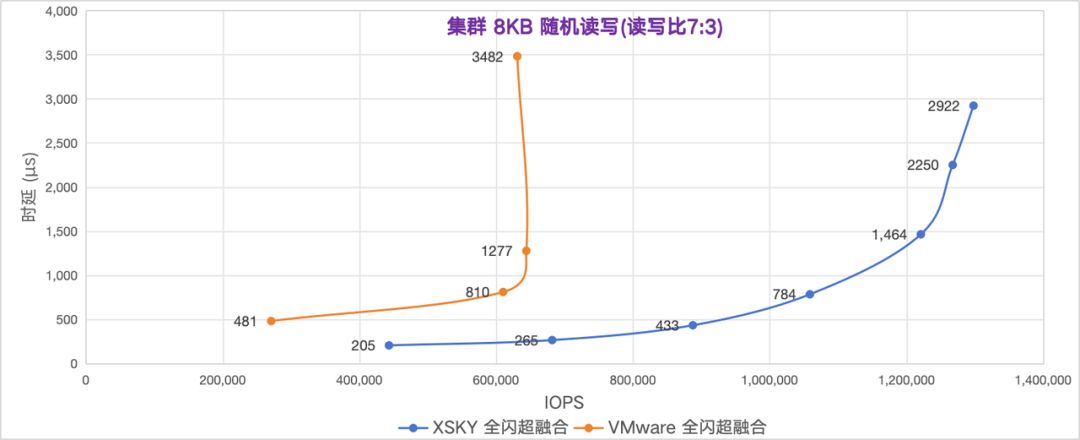
存储性能曲线对比
让我们来对比下 IOPS 和时延的拟合曲线图,能够观察到 XSKY 全闪超融合比 VMware 的时延更低,IOPS 更高 。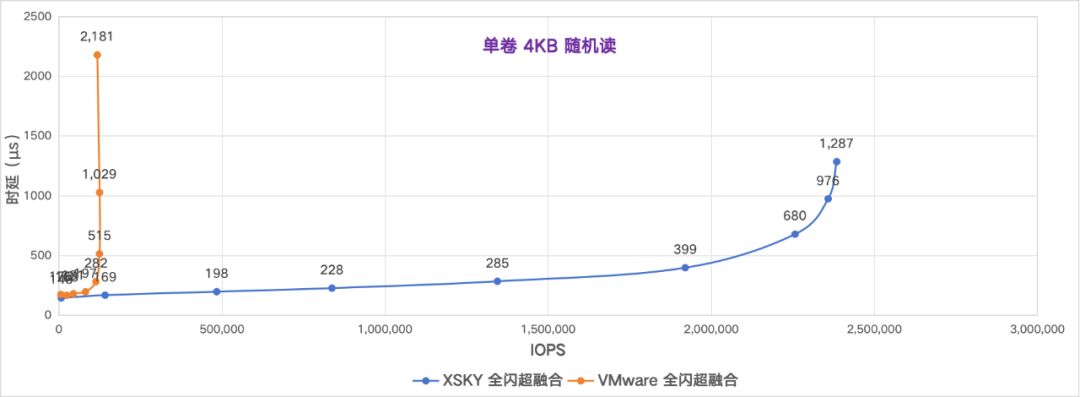
数据库应用测试
我们使用了 12 款数据库和中间件应用做性能对比测试,在这里,我们举例三款典型数据库来展示 XSKY 全闪超融合和 VMware 全闪超融合跑真实应用的性能。
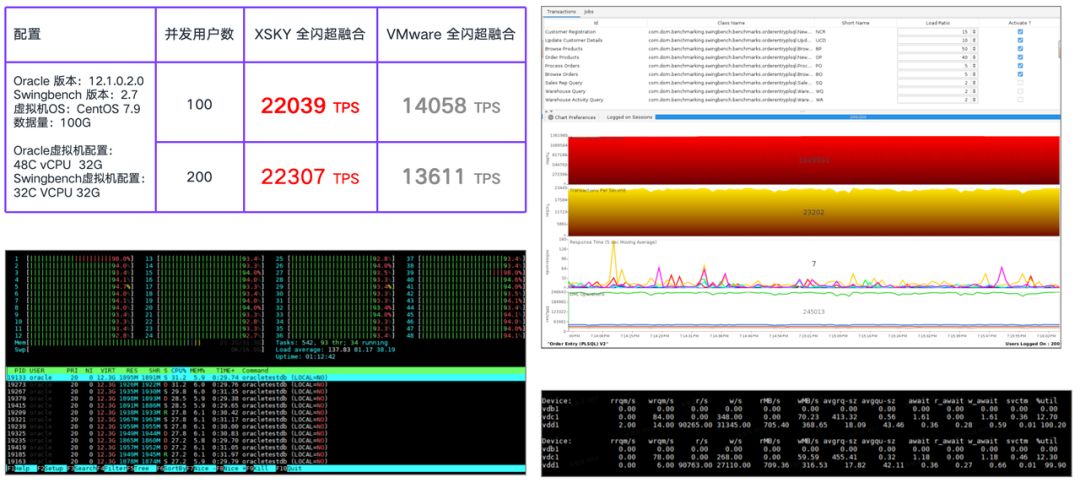
OLTP 数据库 Oracle 12C 单实例 Swingbench 压力测试
在测试中,XSKY 全闪超融合的性能可以达到 22307 TPS,是 VMware 全闪超融合的 1.63 倍。从测试截图可以看到,Oracle 虚拟机的 CPU 已经跑满,Oracle 实例的数据卷的 8KB 随机读达到 9 万 IOPS,读时延是 0.28ms,数据卷的 8KB 随机写达到 3.1 万 IOPS,写时延是 0.59ms。
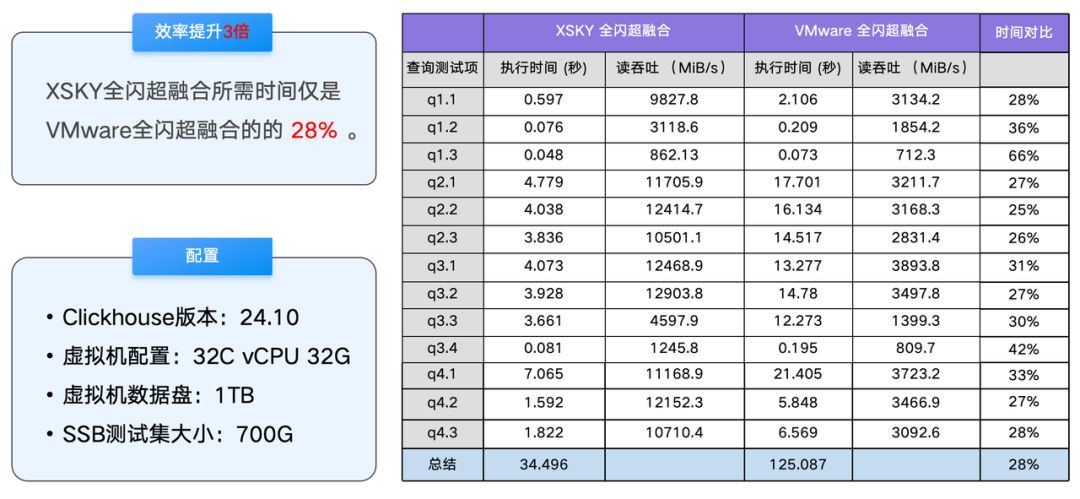
OLAP 数仓 Clickhouse 单实例 SSB 数据集测试
在测试中,可以观察到 XSKY 全闪超融合可以给 Clickhouse 单实例提供 12903MiB/s 的读吞吐能力,这使得 XSKY 全闪超融合仅需 34.496 秒即可跑完 SSB 数据集查询测试,而 VMware 全闪超融合则需要 125.087 秒。使用 XSKY 全闪超融合在 OLAP 场景中效率是 VMware 全闪超融合的 3 倍。
RAG 向量数据库 Milvus 搜索性能测试
在 RAG 向量数据库的搜索性能测试中,XSKY 全闪超融合的 QPS 可以达到 2557,是 VMware 全闪超融合的 3.3 倍。在测试过程中,我们发现 RAG 向量数据库对于底层数据卷的存储 I/O 负载是高并发 4KB 随机读。XSKY 全闪超融合单卷 IOPS 上限是 191 万,实际测试中发挥了 25 万 IOPS,然后遇到了 Milvus 虚拟机的 CPU 瓶颈。
假如增加 Milvus 虚拟机的 vCPU,则基于 XSKY 全闪超融合的向量搜索 QPS 还能继续提升。假如使用 VMware 全闪超融合则无法提升,因为 VMware 的单卷 IOPS 上限是 12 万。
这说明了在 AI 时代的新型数据库应用对于单卷性能的要求极高。

总结
以上测试结果表明,VMware 的 vSAN ESA 是一款优秀的全闪存储架构,为企业的存储需求提供了可靠的解决方案,但是因为要兼顾历史,所以只能做有限的设计。
XSKY 因为没有历史包袱,所以星飞全闪架构相比于 vSAN ESA 做了更多性能改进,因此在存储时延、IOPS 和读写吞吐等方面表现更为出色,能够更好的满足对性能敏感的 OLTP 数据库、OLAP 数仓、AI RAG 向量数据库、Kafka 消息中间件等应用的需求。对于 VMware 的老用户和运维人员来说,星飞全闪存储架构无疑提供了一个更具竞争力的选择。
