KMeans算法案例
KMeans算法案例
案例介绍
已知:客户性别、年龄、年收入、消费指数
需求:对客户进行分析,找到业务突破口,寻找黄金客户

数据集共包含顾客的数据, 数据共有 4 个特征, 数据共有 200 条。接下来,使用聚类算法对具有相似特征的的顾客进行聚类,并可视化聚类结果。
案例实现
确定最佳K值
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.metrics import silhouette_score
# 聚类分析用户分群
dataset = pd.read_csv('data/customers.csv')
dataset.info()
print('dataset-->\n', dataset)
X = dataset.iloc[:, [3, 4]]
print('X-->\n', X)
mysse = []
mysscore = []
# 评估聚类个数
for i in range(2, 11):
mykeans = KMeans(n_clusters=i)
mykeans.fit(X)
mysse.append(mykeans.inertia_) # inertia 簇内误差平方和
ret = mykeans.predict(X)
mysscore.append(silhouette_score(X, ret)) # sc系数 聚类需要1个以上的类别
plt.plot(range(2, 11), mysse)
plt.title('the elbow method')
plt.xlabel('number of clusters')
plt.ylabel('mysse')
plt.grid()
plt.show()
plt.title('sh')
plt.plot(range(2, 11), mysscore)
plt.grid(True)
plt.show()通过肘方法、sh系数都可以看出,聚成5类效果最好

顾客聚类
dataset = pd.read_csv('data/customers.csv')
dataset.head()
#全部行,第四第五列 Annual Income (k$) 和 Spending Score (1-100)
X = dataset.iloc[:, [3, 4]].values # 返回的是numpy的ndarray
kmeans = KMeans(n_clusters = 5, init = 'k-means++', random_state = 42) #k=5
y_pred = kmeans.fit_predict(X)解释:
获取质心坐标
# 获取质心点坐标
centroids = kmeans.cluster_centers_
"""
结果是二维数组
[[25.72727273 79.36363636]
[87.75 17.58333333]
[55.0875 49.7125 ]
[86.53846154 82.12820513]
[26.30434783 20.91304348]]
"""获取每簇的点
y_pred == 0
:这是一个布尔索引操作,它会创建一个布尔数组,其中每个元素表示对应的样本是否属于簇0。
例如,如果 y_pred 是 [0, 1, 0, 2, 0],那么 y_pred == 0 的结果将是 [True, False, True, False, True].
X[y_pred == 0, 0]
:这行代码使用布尔索引从数据集 X 中选择所有属于簇0的样本的第一个特征值。
具体来说,它会返回一个一维数组,包含所有被标记为簇0的样本的第一个特征值.
例如,假设
X 是一个二维数组,形状为
(n_samples, n_features),其中 n_samples 是样本数量,n_features 是特征数量。如果
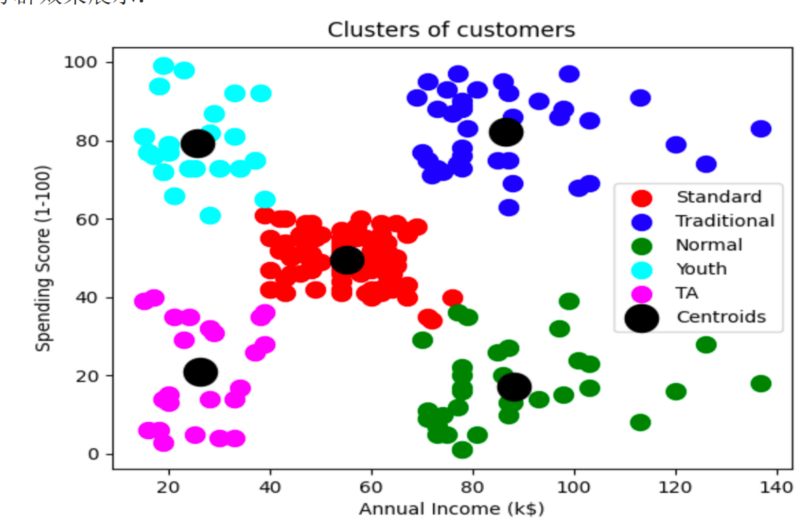
y_pred 是 [0, 1, 0, 2, 0],那么X[y_pred == 0, 0] 将返回一个一维数组,包含X 中索引为0、2和4的样本的第一个特征值.画图展示聚类结果
# 画图展示聚类结果
plt.scatter(X[y_pred == 0, 0], X[y_pred == 0, 1], s = 100, c = 'red', label = 'Standard')
plt.scatter(X[y_pred == 1, 0], X[y_pred == 1, 1], s = 100, c = 'blue', label = 'Traditional')
plt.scatter(X[y_pred == 2, 0], X[y_pred == 2, 1], s = 100, c = 'green', label = 'Normal')
plt.scatter(X[y_pred == 3, 0], X[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Youth')
plt.scatter(X[y_pred == 4, 0], X[y_pred == 4, 1], s = 100, c = 'magenta', label = 'TA')
# kmeans.cluster_centers_:聚类后每类的中心点
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'black', label = 'Centroids')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()从图中可以看出,聚成5类,右上角属于挣的多,消费的也多黄金客户群