【极速版 -- 大模型入门到进阶】Transformer: Attention Is All You Need -- 第一弹

第二弹 指路 Transformer: Attention Is All You Need – 第二弹
文章目录
- 🌊 Transformer 模块概述 -- 简化版本
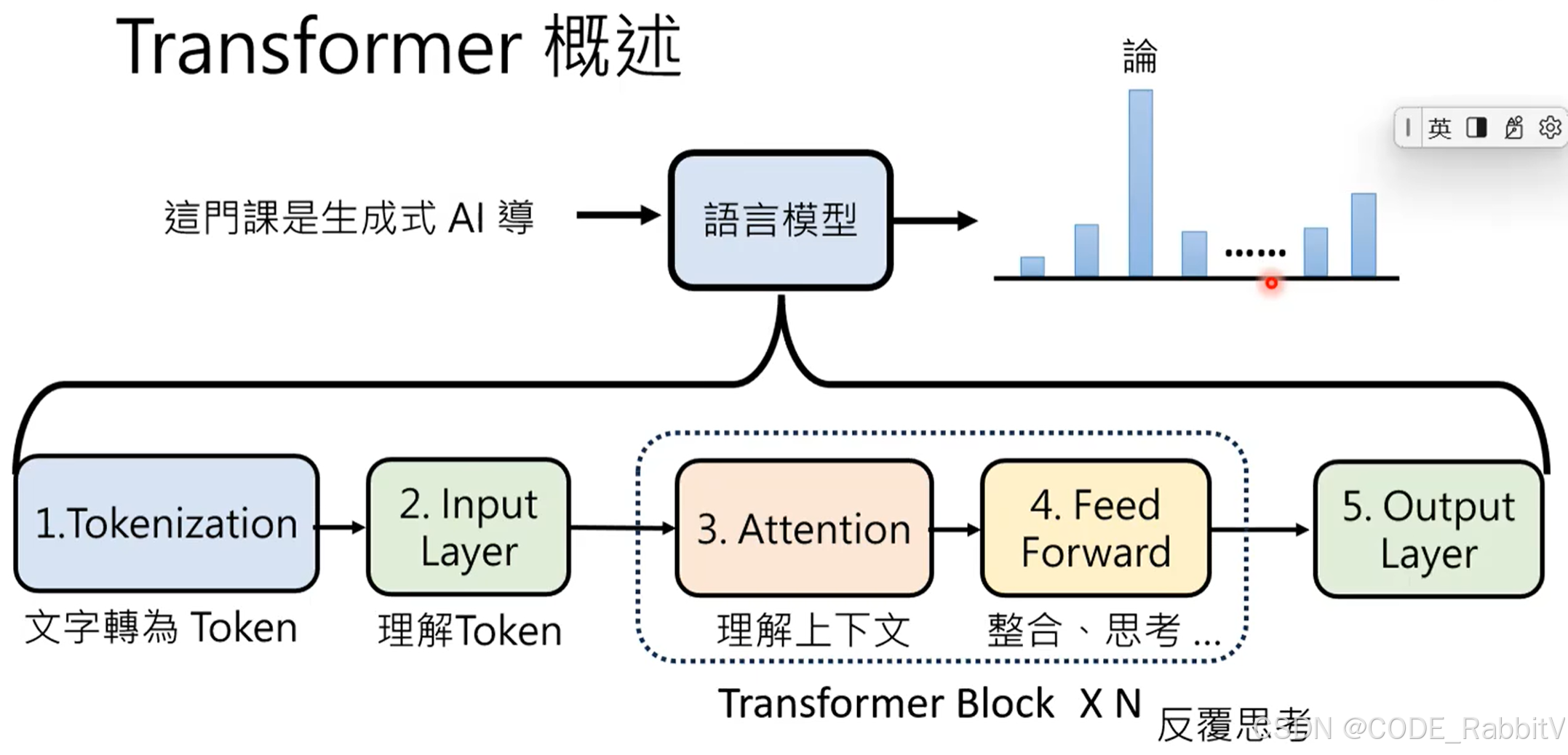
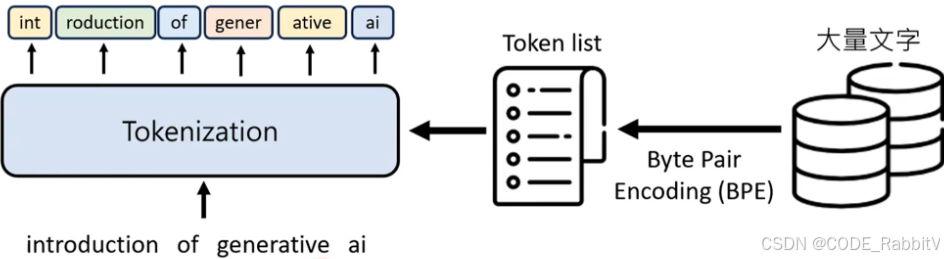
- 【1. Tokenization】把文字变成 Token ❄️
- 【2. Input Layer】理解每个 Token (从语义和位置上) 🔥
- 【3. Attention】考虑 Token 上下文 -- contextuallized token embedding
- 【4. Feed Forward】整合思考
- 【3 & 4 Transformer Block】反复思考
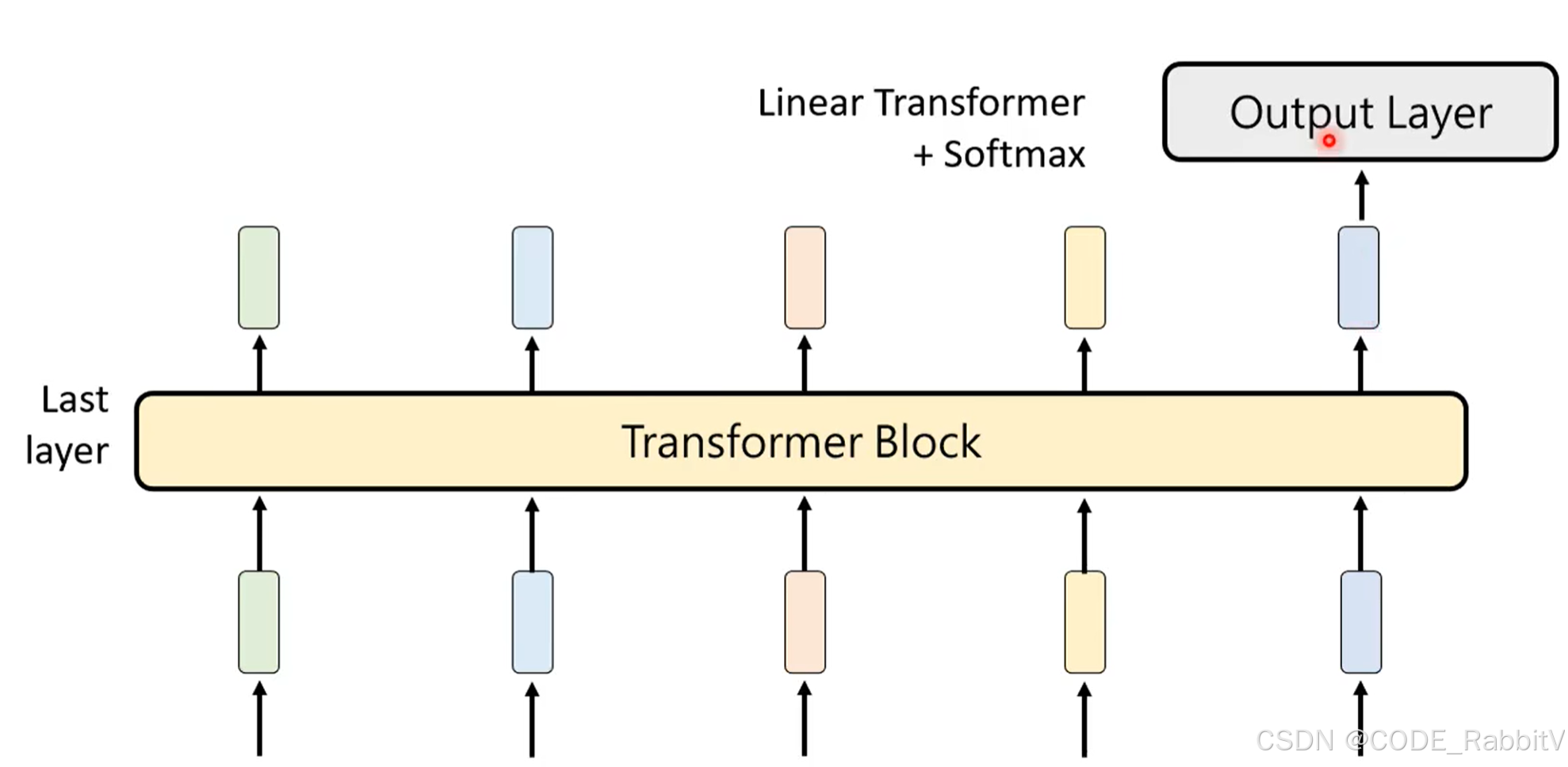
- 【5 Ouput Layer】输出概率
🌊 Transformer 模块概述 – 简化版本
【1. Tokenization】把文字变成 Token ❄️
- https://platform.openai.com/tokenizer
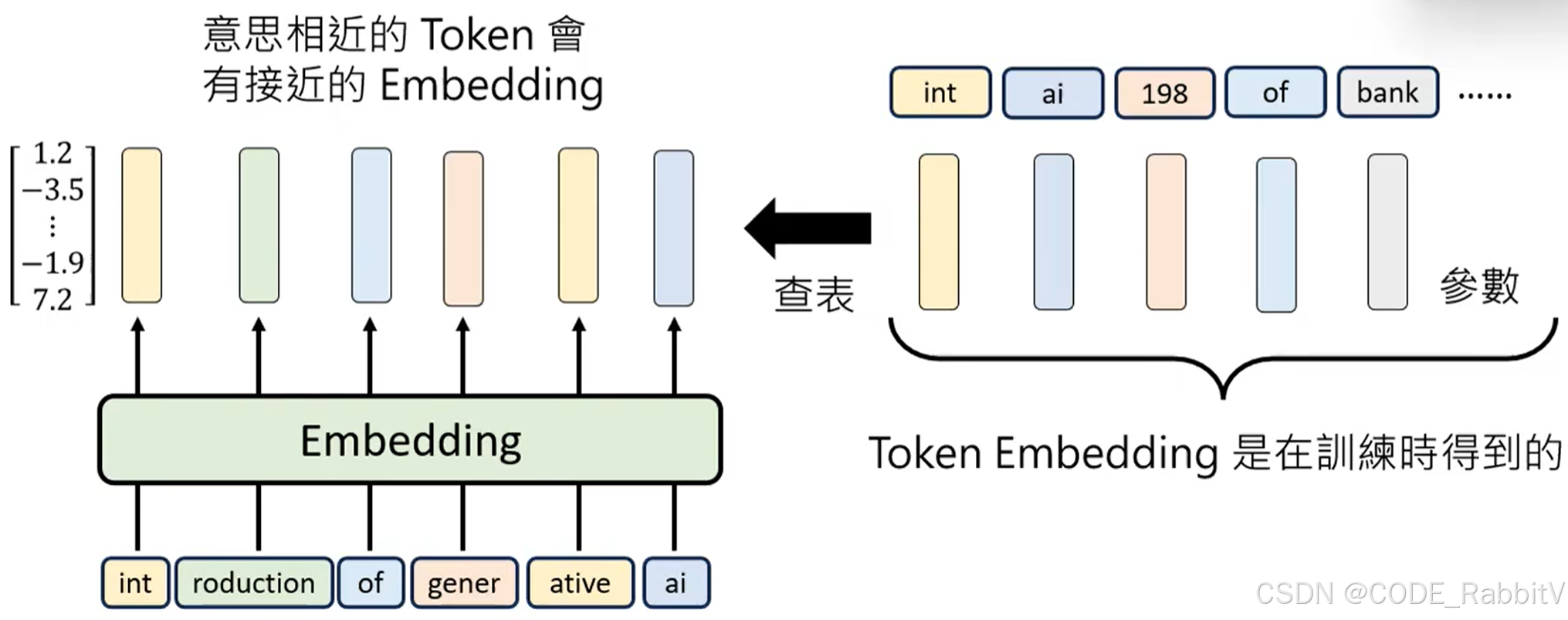
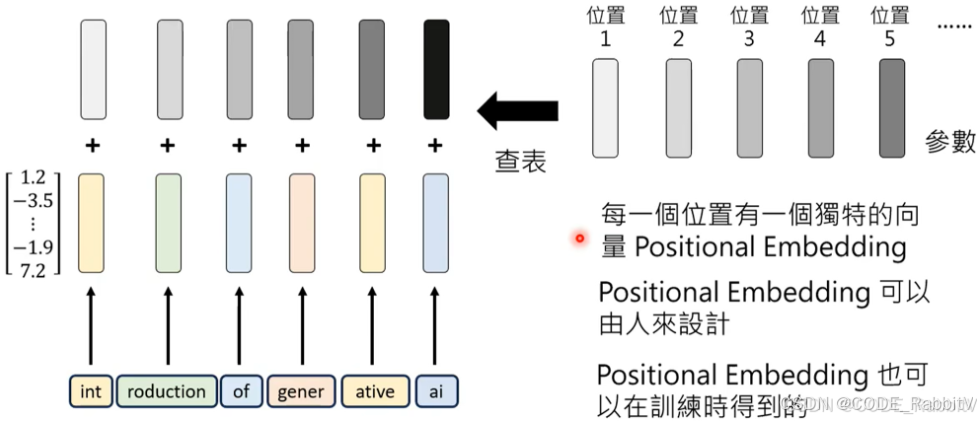
【2. Input Layer】理解每个 Token (从语义和位置上) 🔥
- 意思相近的 Token 会有接近的 Embedding,除了语义,位置上也包含有信息
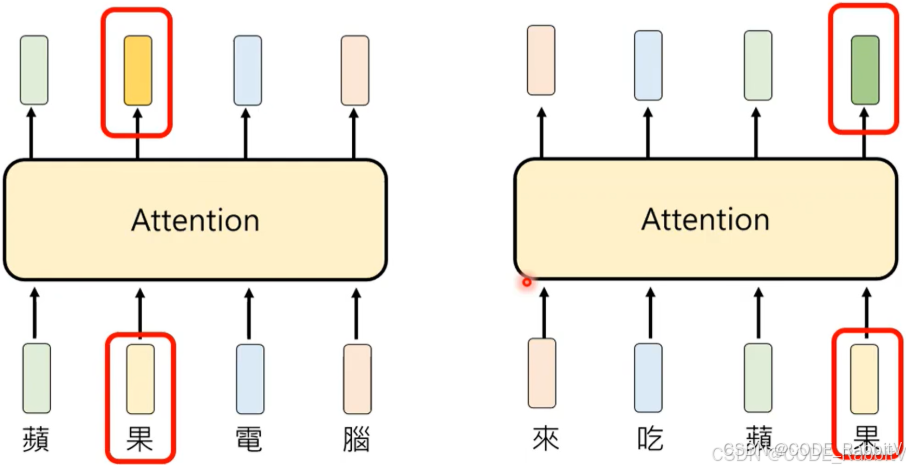
【3. Attention】考虑 Token 上下文 – contextuallized token embedding
- 如下图的例子,同一个 token –
果在不同的上下文中应该具有不同的理解
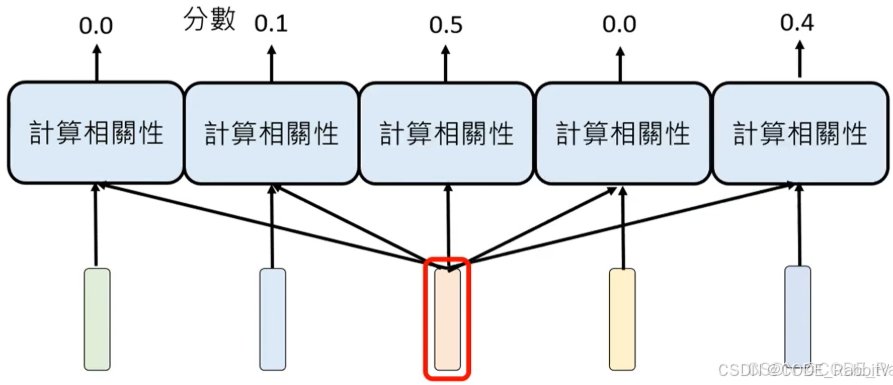
- 步骤一:先找出相关的 token,利用相关性计算程式;可能有不同的相关性存在,所以实际大多使用多个 (16个) 计算相关的程式,也就是常说的 multi-head attention
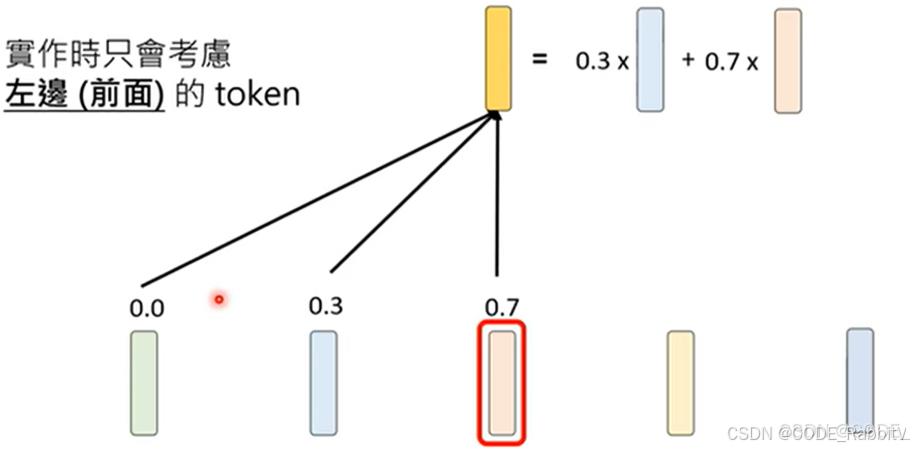
- 步骤二:集合相关的资讯
【4. Feed Forward】整合思考
- 把 multi-head attention 的结果进行汇总,得到一个 embedding 的结果
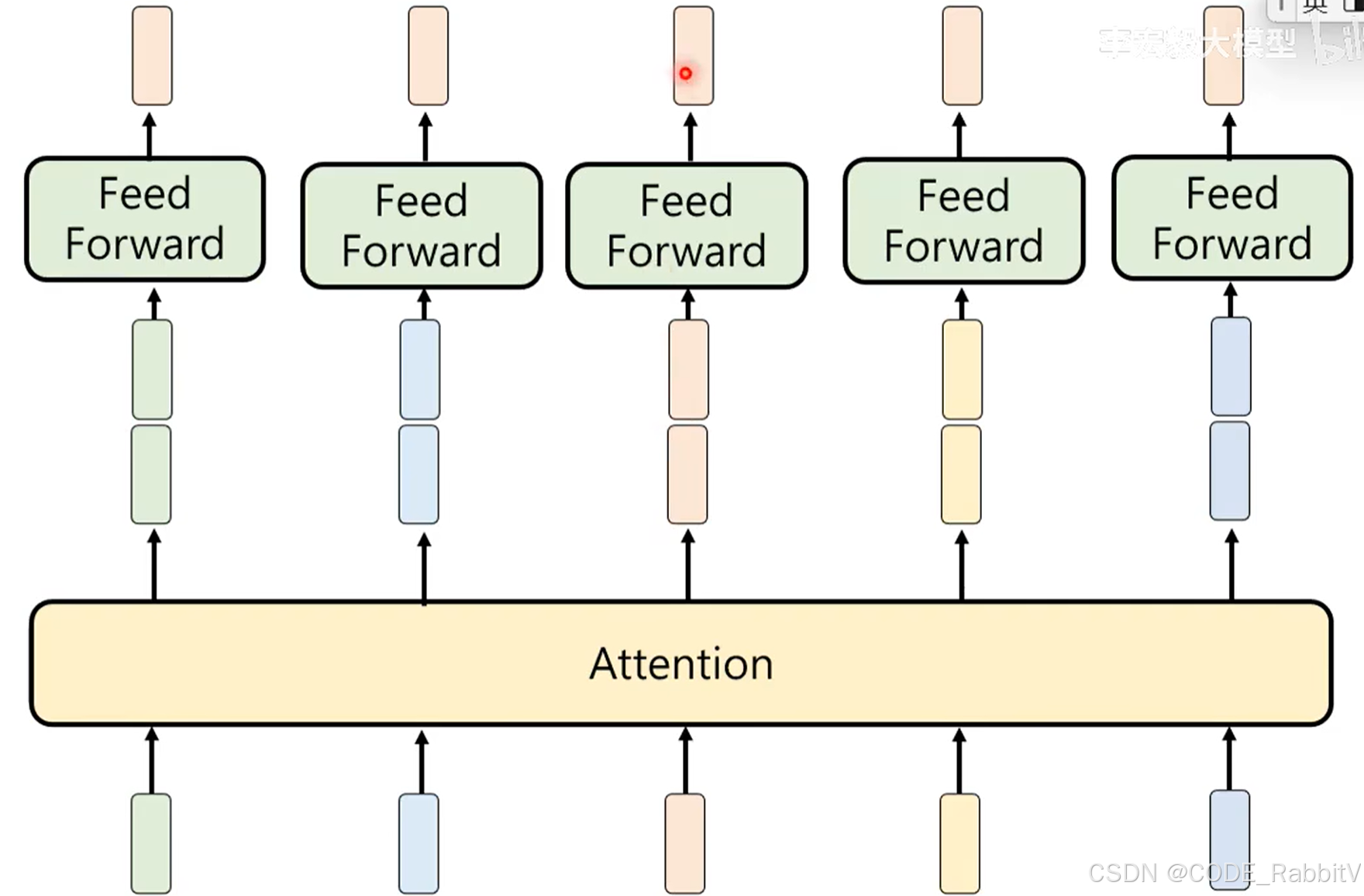
【3 & 4 Transformer Block】反复思考
- Attention + Feed Forward 操作,构成一个 Transformer Block
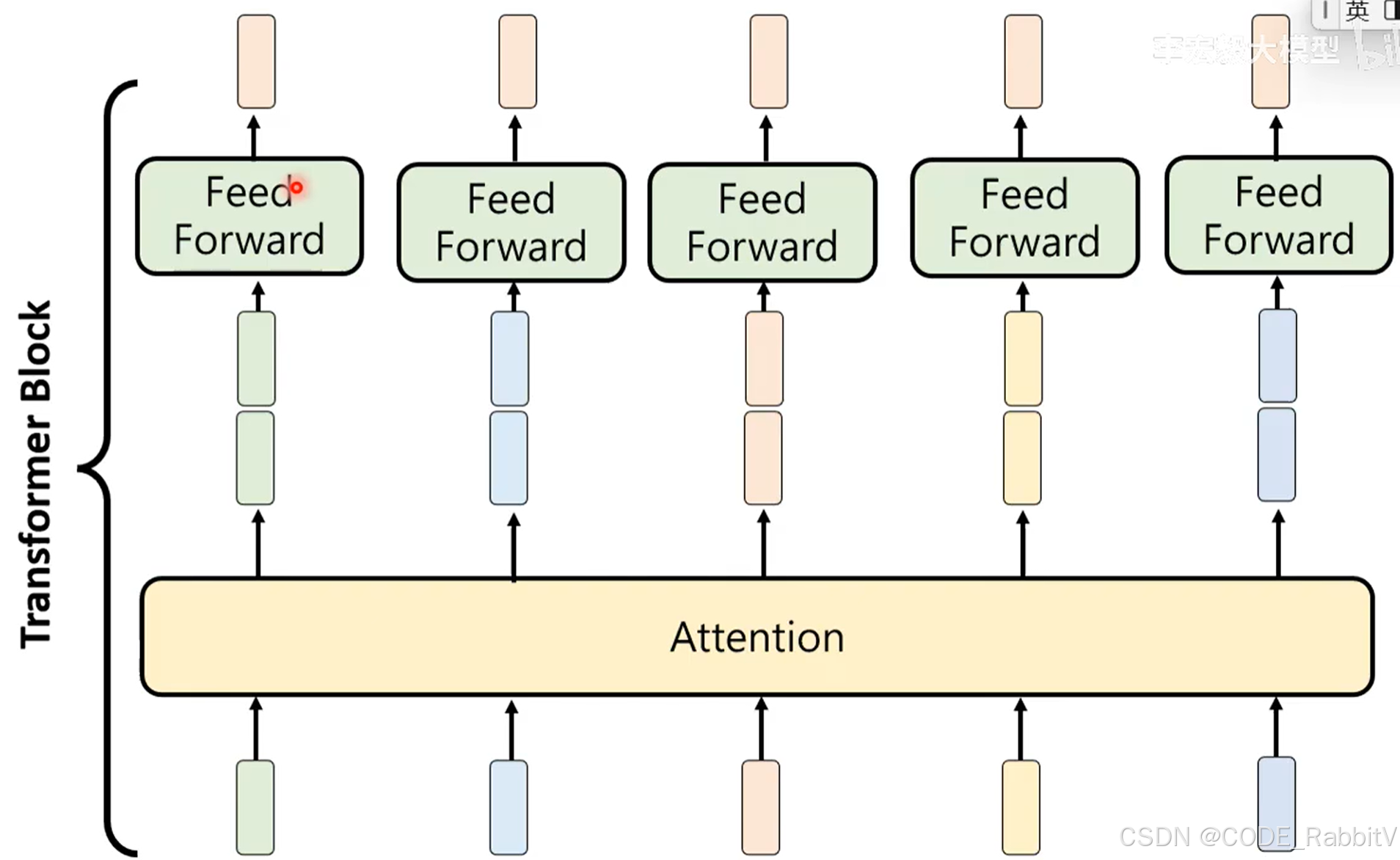
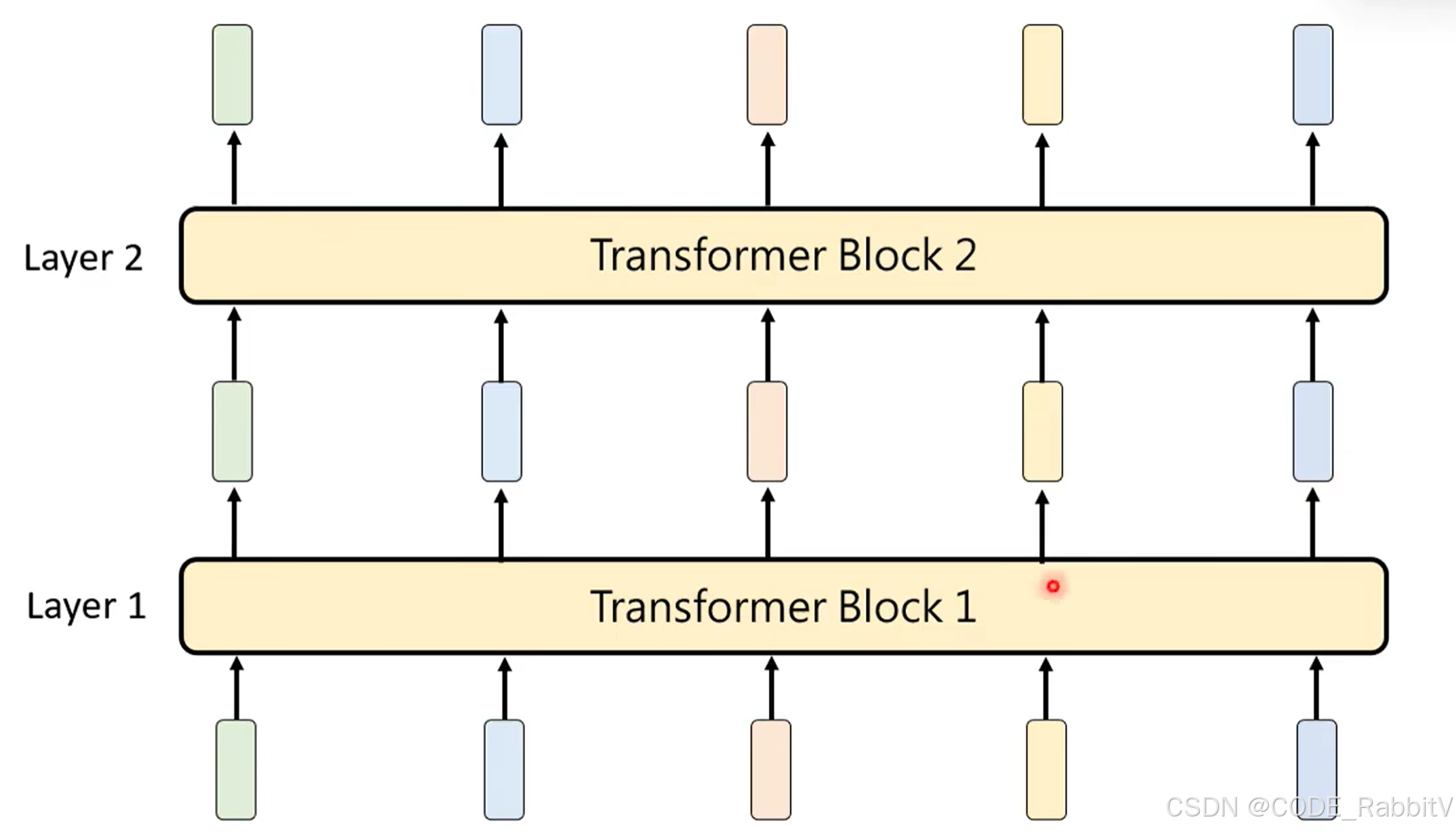
- 构建网络时,会叠加多个 Transformer Block 进行反复思考
【5 Ouput Layer】输出概率