网站首页文件名通常是青岛网站建设公司电话
文章目录
- 线程同步
- 实现线程同步的方式
- 1.原子类型
- 2.互斥量
- 3.锁
- ①死锁
- ②读写锁
- 读写锁操作函数
- 4.条件变量(新特性)
- 生产者消费者模型(条件变量版本)
- 5.信号量(非C++11特性)
- 生产者消费者模型(信号量版本)
线程同步
- 线程的最大优势,就是可以通过 全局变量 来共享信息(即通信),但是代价是:必须要保证多个线程不能 同时修改 同一个变量。当多个线程都操作 同一个全局变量或共享数据 时,可能引发 线程安全问题(又叫线程同步问题)
- 临界区 就是操作共享变量的代码片段。我们必须要保证 临界区是原子的,也就是要么不执行,要么一次性执行完,不能被其他线程中断。所以说,线程同步即:当一个线程正在 操作共享变量时,其他线程 只能等待,不能操作这个变量,直到该线程操作完成。
- 线程同步虽然会对效率造成一定影响,但它是必须要有的;由于只有 临界区 要且必须要 线程同步,其他代码都不需要,所以多线程还是可以实现高并发的
实现线程同步的方式
1.原子类型
- 声明一个类型为T 的原子类型变量t:
atmoic<T> t; // 声明一个类型为T的原子类型变量t
-
特点:
-
如果是对原子类型的变量进行修改,就不需要加锁了。线程会自动地互斥访问原子类型
-
原子类型是不允许拷贝和赋值的,因为atmoic模板类中的拷贝构造、移动构造、赋值运算符重载都被删除掉了
-
#include <atomic>
int main()
{atomic<int> a1(0);//atomic<int> a2(a1); // 编译失败atomic<int> a2(0);//a2 = a1; // 编译失败return 0;
}
-
实例:
该例中,使用原子变量后 就不再需要加锁了

2.互斥量
原子类型可以保证一个变量的安全性,但是对于一段代码的安全性,我们只能通过 互斥量和锁 来实现
-
普通互斥量(std:: mutex)

-
注意,线程函数调用 lock() 时,可能会发生以下三种情况:
- 如果该互斥量当前没有被锁住,则调用线程将该互斥量锁住,直到调用 unlock之前,该线程一直拥有该锁
- 如果当前互斥量被其他线程锁住,则当前的调用线程被阻塞住
- 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)
-
线程函数调用 try_lock() 时,可能会发生以下三种情况:
- 如果当前互斥量没有被其他线程占有,则该线程锁住互斥量,直到该线程调用 unlock释放互斥量
- 如果当前互斥量被其他线程锁住,则当前调用线程返回 false,而并不会被阻塞掉
- 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)
-
-
递归互斥量(std:: recursive_mutex)
-
递归互斥锁 允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权。释放互斥量时需要调用相同次数的 unlock()。除此之外,std::recursive_mutex 的特性和 std::mutex 大致相同
-
这对于递归函数 可能需要在同一线程中多次获取锁的情况很有用:
-
#include <iostream>#include <mutex>#include <thread>std::recursive_mutex myRecursiveMutex;void recursiveAccess(int depth) {std::unique_lock<std::recursive_mutex> lock(myRecursiveMutex);if (depth > 0) {recursiveAccess(depth - 1);}// 访问共享资源的代码std::cout << "Accessing shared resource at depth " << depth << "...\n";}int main() {std::thread t1(recursiveAccess, 3);t1.join();return 0;}```- **定时互斥量(std::timed_mutex)**- 比 std::mutex 多了两个成员函数,try_lock_for(),try_lock_until() :- try_lock_for():函数参数表示一个时间范围,在这一段时间范围之内线程如果没有获得锁 则保持阻塞;如果在此期间其他线程释放了锁,则该线程可获得该互斥锁;如果超时(指定时间范围内没有获得锁),则函数调用返回false。```c++timed_mutex myMutex;chrono::milliseconds timeout(100); //100毫秒if (myMutex.try_lock_for(timeout)){//在100毫秒内获取了锁//业务代码myMutex.unlock(); //释放锁}else{//在100毫秒内没有获取锁//业务代码}
-
try_lock_until():函数参数表示一个时刻,在这一时刻之前线程如果没有获得锁则保持阻塞;如果在此时刻前其他线程释放了锁,则该线程可获得该互斥锁;如果超过指定时刻没有获得锁,则函数调用返回false。
-
定时递归互斥量(std::recursive_timed_mutex)
允许同一线程多次获取锁,并提供了超时功能。与std::timed_mutex一样,std::recursive_timed_mutex也提供了try_lock_for()和try_lock_until()方法
3.锁
这里主要介绍两种RAII方式的锁封装(std::lock_guard 和 std::unique_lock),可以动态的释放锁资源,防止线程由于编码失误导致一直持有锁。
-
std::lock_gurad 是 C++11 中定义的模板类,取代了mutex的lock和unlock函数。定义如下:

- lock_guard类模板通过RAII来封装。在需要加锁的地方,只需要用互斥量实例化一个lock_guard对象,此时类内调用构造函数成功上锁;出作用域前,lock_guard对象要被销毁,调用析构函数自动解锁,可以有效避免死锁问题。
- lock_guard对象之间是不能拷贝和赋值的
- lock_guard的缺陷:太单一,用户没有办法对该锁进行控制,因此C++11又提供了unique_lock。
-
独占锁(unique_lock)
-
与lock_guard不同的是,unique_lock更加的灵活(但效率上差一点,内存占用多一点),提供了更多的成员函数:
- 上锁/解锁操作:lock、try_lock、try_lock_for、try_lock_until和unlock
-
//1.立即上锁std::mutex mtx;std::unique_lock<std::mutex> lck(mtx);//2.延迟上锁std::unique_lock<std::mutex> lck(mtx, std::defer_lock); //只是创建对象,不上锁lck.lock(); // 此时才上锁if(lck.try_lock()){// 已获得锁}lck.unlock();
- 修改操作:移动赋值、交换即swap(与另一个unique_lock对象互换所管理的互斥量所有权)、释放即release(返回它所管理的互斥量对象的指针,并释放所有权)
std::unique_lock<std::mutex> ul1(mtx);std::unique_lock<std::mutex> ul2 = std::move(ul1); // 把ul1的锁转移到ul2上,即现在是ul2对mtx上锁if (!ul1.owns_lock()) // 现在 ul1 应该不再持有锁了{assert(true);}
- 获取属性:owns_lock(返回当前对象是否上了锁)、operator bool()(与owns_lock()的功能相同)、mutex(返回当前unique_lock所管理的互斥量的指针)
if(lck.owns_lock()){// 此时拥有锁}auto* m = lck.mutex();
①死锁
- 死锁就是 多个进程因为争夺共享资源,导致它们之间互相等待。若无外力干预,这些进程都无法继续执行
- 死锁的几种场景:
- 忘记释放锁(自己不能再用了,其他线程也不能用)
- 重复加同一个锁 (往往是在被锁定的代码区内调用函数,而那个函数内部也有同一个锁,这种错误就比较隐蔽了)
- 多线程多锁,抢占锁资源(线程之间互相需要对方的锁,但是都给不了)
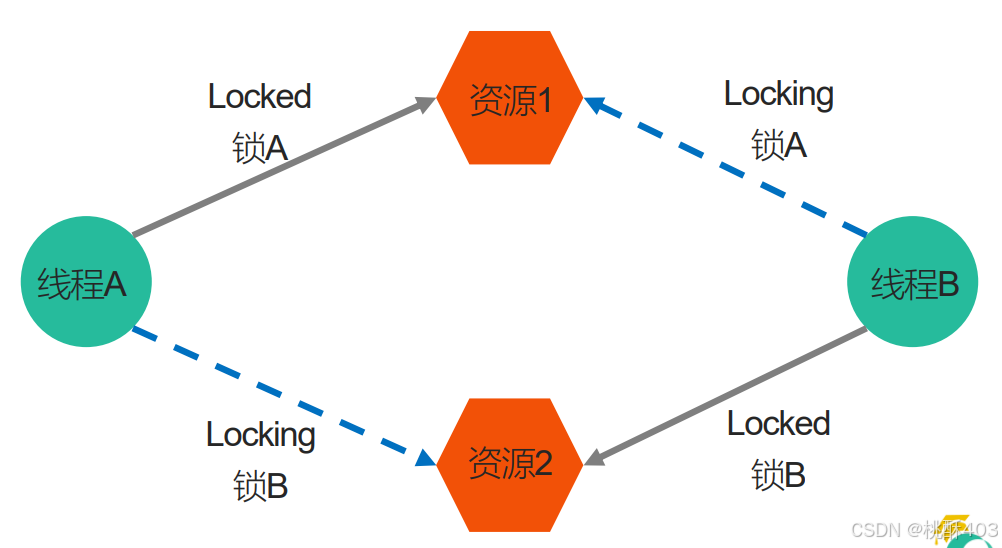
第三个场景的实例:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>// 创建2个互斥量
pthread_mutex_t mutex1, mutex2;void * workA(void * arg) {pthread_mutex_lock(&mutex1);sleep(1);pthread_mutex_lock(&mutex2);printf("workA....\n");pthread_mutex_unlock(&mutex2);pthread_mutex_unlock(&mutex1);return NULL;
}void * workB(void * arg) {pthread_mutex_lock(&mutex2);sleep(1);pthread_mutex_lock(&mutex1);printf("workB....\n");pthread_mutex_unlock(&mutex1);pthread_mutex_unlock(&mutex2);return NULL;
}int main() {// 初始化互斥量pthread_mutex_init(&mutex1, NULL);pthread_mutex_init(&mutex2, NULL);// 创建2个子线程pthread_t tid1, tid2;pthread_create(&tid1, NULL, workA, NULL);pthread_create(&tid2, NULL, workB, NULL);// 回收子线程资源pthread_join(tid1, NULL);pthread_join(tid2, NULL);// 释放互斥量资源pthread_mutex_destroy(&mutex1);pthread_mutex_destroy(&mutex2);return 0;
}
②读写锁
-
多个线程同时写共享数据,会出问题;但它们同时读一个共享数据却不会发生问题
-
在 读远大于写的场景中,可以使用 读写锁,使得 多个线程可以同时读 一份共享数据,但是只有一个线程可以写(修改)共享数据
-
特点:
- 如果 有线程在读共享数据,可允许其他线程读,但不能让其他线程写(读的时候不能写)
- 如果 有线程在写共享数据,那么其他线程既不能读,也不能写(写的时候也不能读)
- 获得 写锁的线程 先进入临界区(A、C读锁,B写锁,则先让B修改共享数据,然后再让A、C读)
-
相较于 互斥量,读写锁 本质是提高了 读的并发性
读写锁操作函数
读写锁的类型 pthread_rwlock_t//只有一个变量int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr);//初始化int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);//释放变量资源int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);//读锁int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);//写锁int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);//解锁,共用一个
实例:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>// 创建一个共享数据
int num = 1;
// pthread_mutex_t mutex;
pthread_rwlock_t rwlock;//读写锁变量void * writeNum(void * arg) {while(1) {pthread_rwlock_wrlock(&rwlock);//写锁num++;printf("++write, tid : %ld, num : %d\n", pthread_self(), num);pthread_rwlock_unlock(&rwlock);//解锁usleep(100);}return NULL;
}void * readNum(void * arg) {while(1) {pthread_rwlock_rdlock(&rwlock);//读锁printf("===read, tid : %ld, num : %d\n", pthread_self(), num);pthread_rwlock_unlock(&rwlock);//解锁usleep(100);}return NULL;
}int main() {pthread_rwlock_init(&rwlock, NULL);//在main中先初始化// 创建3个写线程,5个读线程pthread_t wtids[3], rtids[5];for(int i = 0; i < 3; i++) {pthread_create(&wtids[i], NULL, writeNum, NULL);}for(int i = 0; i < 5; i++) {pthread_create(&rtids[i], NULL, readNum, NULL);}// 设置线程分离for(int i = 0; i < 3; i++) {pthread_detach(wtids[i]);}for(int i = 0; i < 5; i++) {pthread_detach(rtids[i]);}while(1)//因为要等子线程运行完了之后,才能去销毁互斥量,所以要么是 join,要么是 detach+while(1)//这样才能保证,在销毁前子线程已运行完{sleep(1);}pthread_rwlock_destroy(&rwlock);pthread_exit(NULL);return 0;
}
4.条件变量(新特性)
1.条件变量(condition_variable)总是和 锁、互斥量 结合在一起,通常情况下这个互斥量是 std::mutex,并且 **锁 只能是 std::unique_lock< std::mutex > **。通过这样,可以控制线程的阻塞,同时在满足一定条件后被唤醒。
2.定义:
condition_variable cv;
3.成员函数:

-
等待条件成立: wait,wait_for 和 wait_unitl
-
wait :使当前线程阻塞,直到另一个线程调用 notify_one 或 notify_all。
- 参数(1个或2个):它需要两个参数:一个是 锁 unique_lock< mutex >,它应该在调用 wait 之前由调用线程锁定,并且在 wait 等待期间由 wait 自动解锁;另一个是函数或可调用对象(通常是一个lambda表达式或函数指针),用于检查条件是否满足(这个可以不写)
-
void wait(std::unique_lock<std::mutex>& lock);// 若发生虚假唤醒,wait 之后的代码将会被执行template<class Predicate>void wait(std::unique_lock<std::mutex>& lock, Predicate pred);/** 相当于while (!pred()) {通过检查 pred 返回值,可以避免虚假唤醒wait(lock);}**/
-
特点:wait 会无限期地等待,直到条件满足。它会在每次从 wait 返回时重新获取互斥锁。
-
wait_for :导致当前的线程阻塞直到条件变量被通知,或者超时返回。
- 参数(2个或3个):与 wait 类似,它需要一个 unique_lock< std::mutex > 和 一个函数或可调用对象来检查条件(这个可以不写)。此外,它还需要一个表示等待时间的 (std::chrono::)duration 类型的参数。
template<class Rep, class Period>std::cv_status wait_for(std::unique_lock<std::mutex>& lock,const std::chrono::duration<Rep, Period>& rel_time);// 被其他线程唤醒或发生虚假唤醒,未超时,返回 std::cv_status::no_timeout,// 超时则返回 std::cv_status::timeouttemplate<class Rep, class Period, class Predicate>bool wait_for(std::unique_lock<std::mutex>& lock,const std::chrono::duration<Rep, Period>& rel_time,Predicate pred);// 相当于// wait_until(lock, std::chrono::steady_clock::now() + rel_time, std::move(pred));
-
特点:wait_for 提供了等待时间的上限。如果在指定的时间内条件没有变为真,则 wait_for 会返回,即使 notify_one 或 notify_all 还没有被调用。
-
wait_until:使当前线程阻塞 直到指定的时间点 或 直到另一个线程调用 notify_one 或 notify_all
- 参数:与 wait 和 wait_for 类似,它需要一个 std::unique_lock< std::mutex > 和 一个函数或可调用对象来检查条件(可以不写)。此外,它还需要一个表示未来某个时间点的 (std::chrono::)time_point 类型的参数。
template<class Clock, class Duration>std::cv_status wait_until(std::unique_lock<std::mutex>& lock,const std::chrono::time_point<Clock, Duration>& timeout_time);// 被其他线程唤醒或发生虚假唤醒,未超时,返回 std::cv_status::no_timeout// 超时则返回 std::cv_status::timeouttemplate<class Clock, class Duration, class Pred>bool wait_until(std::unique_lock<std::mutex>& lock,const std::chrono::time_point<Clock, Duration>& timeout_time, Pred pred);/** 相当于while (!pred()) {通过检查 pred 返回值,可以避免虚假唤醒if (wait_until(lock, timeout_time) == std::cv_status::timeout) {return pred();}}return true;**/
-
特点:wait_until 允许指定一个绝对的时间点作为等待的结束条件。如果在指定的时间点之前条件没有变为真,则 wait_until 会返回,即使 notify_one 或 notify_all 还没有被调用。
-
以上3个类型的 wait 函数都会在阻塞时 自动释放锁,即 调用 unique_lock 的成员函数 unlock(),来让其他线程获得锁(这就是条件变量只能和 unique_lock 一起使用的原因),否则线程在阻塞时也将一直占有锁。
-
wait 类型函数返回(即解阻塞)时要不是因为被唤醒,要不是因为超时。但是在实际中发现,因为操作系统的原因,wait 类型在不满足条件时,它也会返回,这就导致了虚假唤醒,因此我们一般都是使用带有函数指针或lamba表达式参数的 wait 函数。
-
给出信号: notify_one 和 notify_all 函数
-
notify_one(无参):唤醒 等待的线程之一
-
notify_all(无参):唤醒任何等待的线程

-
生产者消费者模型(条件变量版本)
-
模型中的对象:生产者(可不止一个)、消费者(可不止一个)、容器
-
特点:
- 如果 生产者生产的东西装满了容器,此时生产者需要等待(阻塞),并 唤醒消费者让其消费
- 如果 消费者 把容器中的东西全都消费完了,此时消费者需要等待(阻塞),并 唤醒生产者让其生产
- 生产者线程 和 消费者线程 之间需要做到 线程同步
-
条件变量版本:
#include <stdio.h>#include <pthread.h>#include <stdlib.h>#include <unistd.h>#include <mutex>#include <thread>#include <condition_variable>// 创建一个互斥量mutex mtx;// 创建条件变量condition_variable cv;//共享资源就是这个链表struct Node{int num;Node *next;};// 头结点Node * head = NULL;void * producer(void * arg) {// 不断的创建新的节点,添加到链表中while(1) {unique_lock<mutex> ul(&mtx);Node * newNode = new Node;newNode->next = head;head = newNode;newNode->num = rand() % 1000;printf("add node, num : %d, tid : %ld\n", newNode->num, pthread_self());// 只要生产了一个,就通知消费者消费cv.notify_one();ul.unlock();usleep(100);}return NULL;}void * customer(void * arg) {while(1) {unique_lock<mutex> ul(mtx);// 保存头结点的指针Node * tmp = head;// 判断是否有数据if(head != NULL) {// 有数据head = head->next;//把数据打印出来printf("del node, num : %d, tid : %ld\n", tmp->num, pthread_self());delete(tmp);ul.unlock();usleep(100);} else {// 没有数据,需要等待// 当这个函数调用阻塞的时候,会对互斥锁进行解锁,当不阻塞的,继续向下执行,会重新加锁。cv.wait(ul);ul.unlock();//须释放,因为下一层循环还要再获取锁}}return NULL;}int main() {// 创建5个生产者线程,和5个消费者线程thread ptids[5], ctids[5];for(int i = 0; i < 5; i++) {ptid[i]=thread(producer);ctid[i]=thread(custmer);}for(int i = 0; i < 5; i++) {ptids[i].detach();ctids[i].detach();}while(1) {sleep(10);}pthread_exit(NULL);return 0;}
5.信号量(非C++11特性)
- 信号量也用于 控制线程的阻塞;但与条件变量不同的是,信号的wait 并不会立即阻塞线程,而是当信号量的value值为0,才会去阻塞,直到 value值 > 0 时才解除阻塞
- 调用 wait,会使 value - 1,并判断是否满足阻塞的条件;调用 post,会使 value + 1
- 控制多个线程的阻塞,只需要一个条件变量;而控制两个线程的阻塞和唤醒,就需要2个信号量,依次类推
- wait 一般用于控制自身线程 某个操作的重复次数;而 post 一般用于让其他线程进行某个操作
信号量操作函数:
信号量的类型 sem_tint sem_init(sem_t *sem, int pshared, unsigned int value);- 初始化信号量- 参数:- sem : 信号量变量的地址- pshared : 有两个值,0 表示 用在线程间 ,非0 表示 用在进程间- value : 信号量中的值int sem_destroy(sem_t *sem);- 释放信号量资源int sem_wait(sem_t *sem);- 调用一次对信号量的值-1,如果减1之前值为0,就阻塞,直到value值>0(先判断后减1)int sem_trywait(sem_t *sem);- sem_trywait()为sem_wait()的非阻塞版,只-1,不进行阻塞int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);- 阻塞特定时间int sem_post(sem_t *sem);- 调用一次对信号量的值+1int sem_getvalue(sem_t *sem, int *sval);
生产者消费者模型(信号量版本)
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
#include <semaphore.h>// 创建一个互斥量
pthread_mutex_t mutex;
// 创建两个信号量,两个线程需要两个信号量
sem_t psem;
sem_t csem;struct Node{int num;struct Node *next;
};// 头结点
struct Node * head = NULL;void * producer(void * arg) {// 不断的创建新的节点,添加到链表中while(1) {sem_wait(&psem);//让生产者信号量-1pthread_mutex_lock(&mutex);struct Node * newNode = (struct Node *)malloc(sizeof(struct Node));newNode->next = head;head = newNode;newNode->num = rand() % 1000;printf("add node, num : %d, tid : %ld\n", newNode->num, pthread_self());pthread_mutex_unlock(&mutex);sem_post(&csem);//让消费者信号量+1}return NULL;
}void * customer(void * arg) {while(1) {sem_wait(&csem);//让消费者信号量-1pthread_mutex_lock(&mutex);// 保存头结点的指针struct Node * tmp = head;head = head->next;printf("del node, num : %d, tid : %ld\n", tmp->num, pthread_self());free(tmp);pthread_mutex_unlock(&mutex);sem_post(&psem);//让生产者信号量+1}return NULL;
}int main() {pthread_mutex_init(&mutex, NULL);sem_init(&psem, 0, 8);sem_init(&csem, 0, 0);// 创建5个生产者线程,和5个消费者线程pthread_t ptids[5], ctids[5];for(int i = 0; i < 5; i++) {pthread_create(&ptids[i], NULL, producer, NULL);pthread_create(&ctids[i], NULL, customer, NULL);}for(int i = 0; i < 5; i++) {pthread_detach(ptids[i]);pthread_detach(ctids[i]);}while(1) {sleep(10);}pthread_mutex_destroy(&mutex);pthread_exit(NULL);return 0;
}