网站备案 谁接入谁负责网站只做五周
目录
关于RNN
关于batch normalize和layer normalize
关于整体结构
具体结构
先解释一下注意力:
再说一下多头
最后说Feed Forward
重新看结构图
解释一下Feed Forward的作用
关于transformer整体的理解
关于position encoding
关于RNN
RNN的整体结构是:encoder+decoder+softmax。
举例说明RNN的工作流程:假设我们有一个长为T的token,最终要输出的长为K的token。encoder直接生成T个向量ht。在预测第k个位置的词时,网络将k-1步decoder的输出sk和全部的ht计算出来一组权重向量,用这组权重对T个向量进行加权平均ck。这个ck和上一时刻decoder的输出sk-1或上一时刻输出词对应的embedding yk-1组合作为第k个时刻decoder的输入。
不同的RNN网络(比如LSTM,GRU)会修改encoder和decoder的具体实现,或处理权重不一样,或拼接方法不一样等等,但整体框架不变。
为了下面对transformer说明方便起见,在一般使用注意力机制中也有key(K),query(Q)、value(V)的概念。key就是encoder输出的hi,query则是decoder输出的st,value则也是encoder输出的hi。(transformer中也是key和query先算权重,然后和value做合并)
关于batch normalize和layer normalize
在文章中我们可以看到,transformer做的是层归一化而不是batch的归一化,这里总结一下二者的区别:那么比如说对一个32*6*2*2的输出来说,32是 Batch size,6是通道数,2*2是每个通道的小维度,那么 Batch Normalization是对32*2*2整体做归一化,layer normalize是对6*2*2这个小块做归一化。
这两个操作的目的从网络上来说是为了避免每一层训练是的分布偏移(这样归一化之后都是标准正态的分布)减少梯度爆炸,避免过拟合等等实验出来的结果,从数学上讲的话是为了降低loss函数的Lipschitz梯度大小(减少震荡)
transformer使用层归一化的原因是:
主要原因是每次token的长度不一样,batch归一化需要每一个batch的所有内容长度(或大小)是固定的,那么这时候就需要填充或者对token进行削减,影响网络效果。layer则没有这个问题,毕竟他舍弃了batch。比如batch归一化的话,三个token组成一个batch,这三个长度为2 5 4,这么2和4就需要填充成5的。
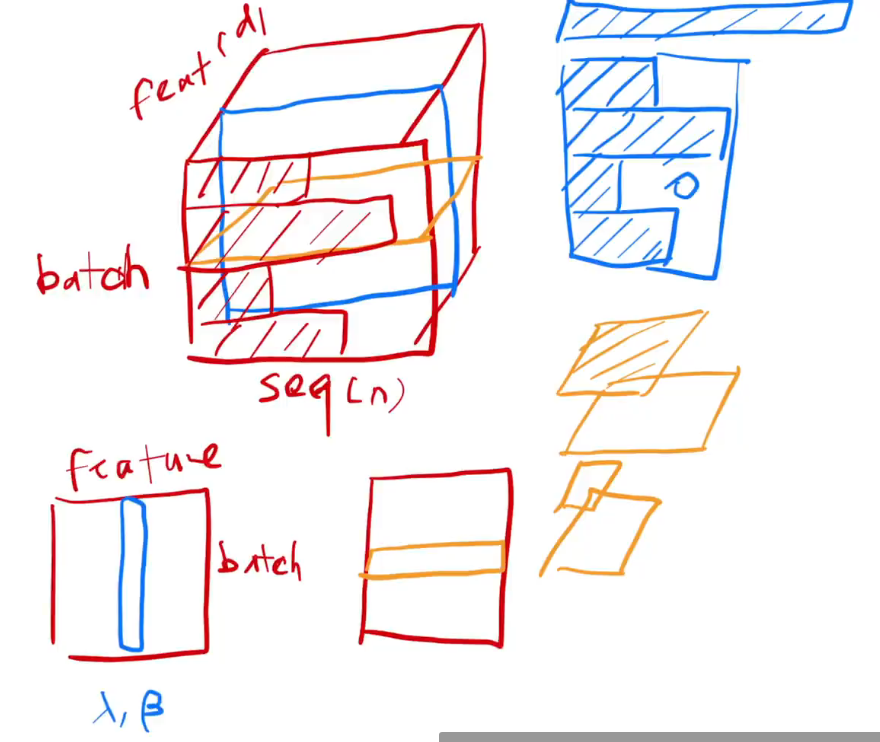
在李沐老师的视频中有一个形象的图我们看上半部分,他这里没有考虑通道的问题,那么batch归一化的话就需要对整个红色的立方体做归一化,但由于seq长度不一样,那么有的seq可能就需要零填充来是的他填满一整个立方体,但是layer normalize的话就只是对这个立方体的每个平着的切面,也就是途中黄色的部分做归一化,那么这个时候不同seq长度不一样也无所谓了,毕竟他们之间相互不再影响
关于整体结构
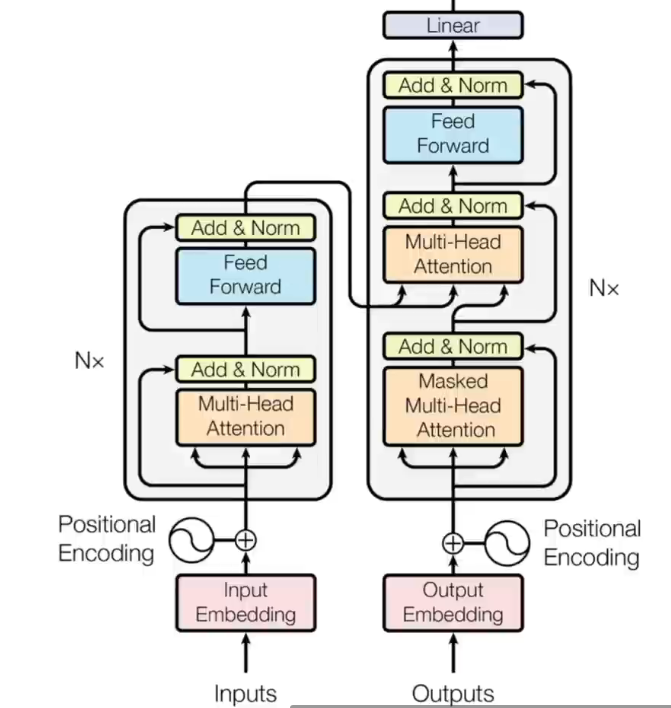
整体结构其实蛮好理解,这里解释几点:
- 左边是encoder,右边的decoder,encoder的输入就是网络的输入,decoder的输入则是上一时刻整个网络的输出。因为他是一个时序的循环网络,就是说他上一时刻的输出是会被当做下一时刻的输入的。
- 我们在网络训练的时候会给出网络的输入输出进行训练,使用的时候却只有输入。为了保持一致,在decoder中可以看到加了一个musk,这个musk掩盖掉的就是当前时刻及之后的输出,保证网络的训练和预测一致
- add指的就是一个残差连接,说白了就是当前小块的输出=x+f(x)然后再归一化,而不是直接f(x)归一化
具体结构
attention:我们可以看到网络的整体结构是由很多的注意力块构成的,下面就解释一下他提出的这个注意力块:多头注意力
先解释一下注意力:
说白了就是对value、也就是encoder结果的一个加权,做这个加权就认为是做了注意力。这篇文章对注意力的实现是:
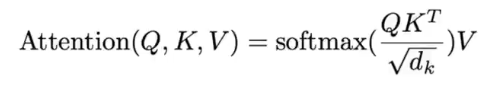
通过这个公式我们可以看到,他其实也是Q和K做一个点乘的操作,然后softmax得到权重,这个权重对V做加权。这里写成矩阵的形式其实是为了做并行计算,对网络整体的操作没有任何影响。我们还需要解释一个为什么要除一个根号dk。这么做其实是为了避免在encoder输出的向量比较长的时候,可能会出现有的点的乘积特别大导致梯度小网络误认为已经收敛。他是把这个dk理解成方差了,所以除的是方差的根号值。
对矩阵做softmax就是对每一行softmax
这里的QKV说的是注意力块的输入,每个注意力块的QVK并不相同
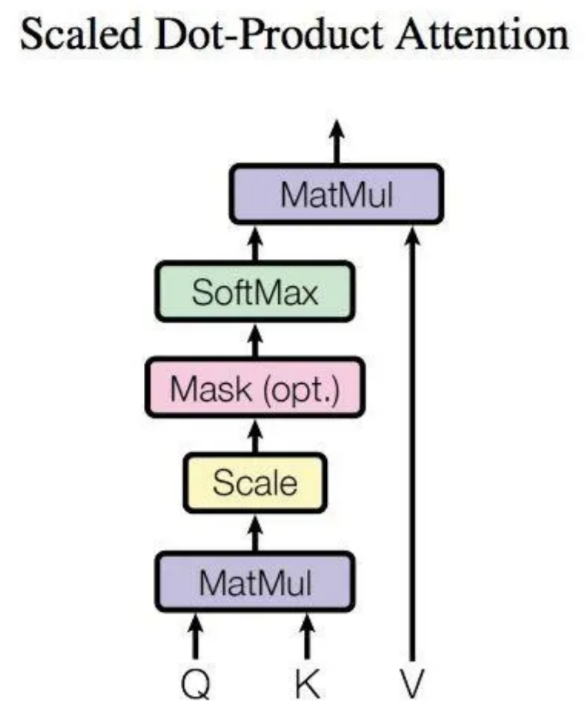
画成图的话就是这个样子。
再解释一下mask。
就像为我们上面说的,注意力机制在第t个时间步,decoder只应该看到t之前的query,也就是decoder的输出。但是我们上面的计算明显是计算了全部的query,那么怎么做呢,其实很简单:目标是把理应看不到的query对应计算得到权重值变为0,操作是在计算QK后,把结果中对应位置全部变为一个非常小的负数,比如1e-11,这样softmax之后就接近0了。
这里说的是训练时的操作。每个epoch训练的时候不止会给encoder的输入和decoder的输出,还会给矩阵Q,并且这个矩阵Q是理论讲上一帧的输出(为了模仿预测时的行为)。给这个矩阵Q的方式就是musk。transformer中这里依然是一个自注意的块(即QKV相等)那么对于Q来说,坐标i不应该看到i之前的内容,QK相乘(其实是QQ相乘)的结果是第i个位置对第j个位置的权重。那么第i个位置理论来讲只能看到<=i的词,因此musk掉上三角的部分
再说一下多头
我们可以看到他的注意力块写的是multi-head attention,刚刚其实只解释了attention,没有解释multi-head。
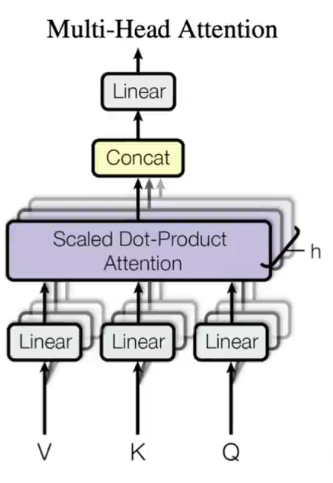
我们可以看到他其实将QKV三个矩阵通过一个线性层降维成h个KQV,然后做上面提到的注意力计算,计算结果再拼接起来,最终再一个线性层做输出。这么做流程很好理解,但思路其实很高明。他这么做是为了让网络可以多学习到一些模式,有点类似于CNN中输出多个通道的感觉。因为我们看到在attention块其实没什么好学的,就是一个固定的计算方法,这未免有些浪费了,所以加了一个线性层,也就是大家说的所谓的W来让网络可以多学一点模式出来。
最后说Feed Forward
他是在对注意力头的输出加两个全连接层,第一层先升维到2048,第二层再降维回512,这样最终才能做残差连接(所谓残差连接就是输出再加一个x)不同的点在于他这里是Point-Wise的,其实是说把输入的每一个向量作为一个点(比如输入n个长512的向量,那么就是n个点)。这每个向量做MLP的输入而不是n*512总体作为MLP的输入。并且每一个向量是共用的同一个Feed Forward块,这个很好理解,毕竟不可能输入token长度不一样就构造不同个数的MLP
重新看结构图
刚刚我们解释了每个注意力的模块是怎么用的,但是其实我们可以看到我们只是简单的将输入描述为了QKV,这三个东西分别是什么其实并没有说,下面就说一下:
图中我们可以看到是由三个注意力块的,QKV在不同的块中其实并不一样,我们依次来说
- 第一个模块:我们可以从图中看出他是一个箭头分出来了三个箭头,这其实表示:encoder中的注意力块的QKV实际上都是由输入K复制来的,也就是说,K=Q=V,实际上是个自注意的机制,如果不考虑多头的话,每个向量对自己的注意力肯定是最高的(矩阵相等算出来的肯定是自己的权重高),考虑多头的话可能有些不一样
- 第二个模块:这个模块可以看到他也是一个自注意,和上一个模块其实是一样的,不过是加了一个musk的步骤,这个musk就是上面说到的
- 第三个模块:这个模块就不再是自注意了。我们可以看到他其实是使用encoder的输出作为KEY和VALUE(当然这里她俩其实是一样的,都是encoder输出的n个hi向量拼成的矩阵)。KEY和QUERY算权重,权重给VALUE算最终输出结果。
解释一下Feed Forward的作用
我个人认为Feed Forward才是真正起作用的模块,前面的attention块其实只做一个历史信息汇聚的任务,也就是对输入的增强,那么增强之后怎么映射到我想要的结果,其实起作用的就是这个Feed Forward块。并且由于每个向量的信息都已经汇聚完成,因此可以直接对每个向量单独做MLP
关于transformer整体的理解
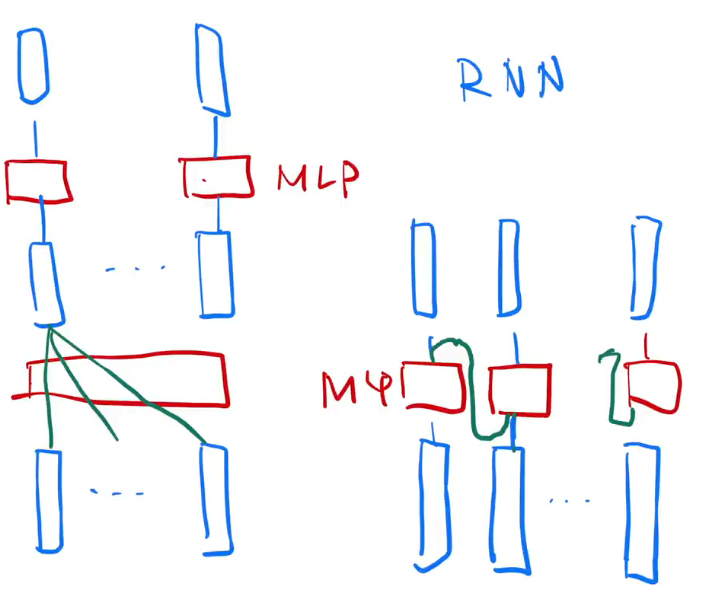
李沐老师在他的视频中画了一个图来比较transformer和传统RNN的区别,RNN是每次将上一次的输出拿来做这一次的输入,但transformer块实际上是一次得到的全部的结果。
关于position encoding
这样其实会带来一个问题:虽然这样的注意力块确实整合了之前的内容信息,但丢失了顺序的信息。换句话说就是,改变输入顺序,并不影响输出结果,毕竟attention块只做加权。这显然有问题,所以要在encoding的时候处理一下,给网络加上顺序的信息(其实就是embedding的结果加一个表征顺序的向量),这点在整体的结构图上也可以看到(有一个类似阴阳鱼的东西,做的就是这个工作)