wordpress 单页面 主题优化推广
Librosa是什么?
Librosa 是一个基于 Python 的开源音频分析库,专注于音乐和语音信号的处理与特征提取。它广泛应用于音频分析、音乐信息检索(MIR)、语音识别、声纹识别等领域,提供了丰富的算法和工具,简化了音频信号处理流程。

一、核心功能
1、音频加载与处理
- 支持多种音频格式(WAV、MP3、OGG等),自动解析音频文件为 NumPy 数组。
- 提供重采样、时域/频域转换、分帧、加窗等基础操作。
2、特征提取
- 时域特征:短时能量、过零率、自相关函数。
- 频域特征:梅尔频率倒谱系数(MFCC)、色度图、频谱质心、频谱带宽。
- 时频域特征:短时傅里叶变换(STFT)、常数Q变换(CQT)、梅尔频谱。
- 高级特征:节奏分析(节拍检测)、音高估计、和弦识别。
3、音乐分析
- 和弦识别、调性检测、音高跟踪、音乐相似度计算。
4、可视化工具
- 绘制波形、频谱图、语谱图、梅尔频谱等。
二、应用场景
-
语音处理
- 语音识别(ASR)中的特征提取(如MFCC)。
- 声纹识别(说话人验证)。
- 语音情感分析。
-
音乐分析
- 音乐推荐系统、自动标注、版权检测。
- 节拍跟踪、和弦识别。
-
音频效果处理
- 音高修正、变速不变调(如基于相位声码器的处理)。
三、特点
-
易用性
- 提供简洁的 API,快速实现复杂音频分析流程。
- 示例丰富,文档完善。
-
算法全面
- 集成音频处理领域经典算法(如 MFCC、动态时间规整 DTW)。
- 支持深度学习集成(与 TensorFlow/PyTorch 兼容)。
-
社区支持
- 活跃的开源社区,持续更新新功能和优化。
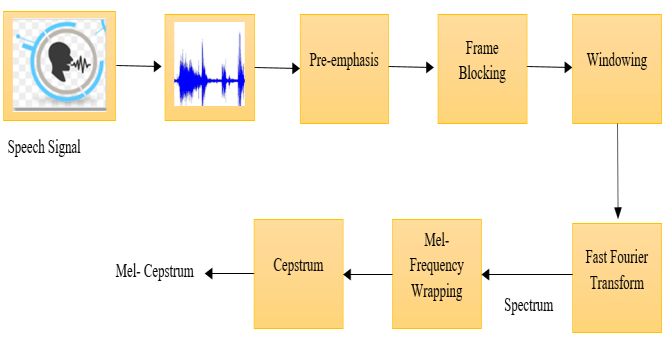
四、简单示例:提取音频 MFCC 特征
import librosa
import librosa.display
import matplotlib.pyplot as plt# 加载音频文件
y, sr = librosa.load("audio.wav", sr=None) # sr=None 保留原始采样率# 提取 MFCC 特征
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)# 可视化
plt.figure(figsize=(10, 4))
librosa.display.specshow(mfccs, x_axis='time', sr=sr)
plt.colorbar()
plt.title('MFCC')
plt.tight_layout()
plt.show()五、多人声纹对比
- 使用 librosa 库提取音频的 MFCC 特征(梅尔频率倒谱系数),这是声纹识别中常用的特征
- 计算多个音频文件之间的余弦相似度,生成相似度矩阵
- 以表格形式输出相似度数值
- 绘制相似度热图,直观展示各个声纹之间的相似程度
import os
import numpy as np
import librosa
import librosa.display
from sklearn.metrics.pairwise import cosine_similarity
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示异常:ml-citation{ref="4,6" data="citationList"}def extract_features(file_path, mfcc_count=20):"""提取音频文件的MFCC特征"""try:# 加载音频文件y, sr = librosa.load(file_path, sr=None)# 提取MFCC特征mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=mfcc_count)# 计算MFCC的均值作为特征向量feature_vector = np.mean(mfccs, axis=1)return feature_vectorexcept Exception as e:print(f"Error processing {file_path}: {e}")return Nonedef compare_voiceprints(file_paths):"""比较多个声纹文件并返回相似度矩阵"""features_list = []valid_files = []# 提取所有文件的特征for file_path in file_paths:features = extract_features(file_path)if features is not None:features_list.append(features)valid_files.append(file_path)if len(features_list) < 2:print("至少需要两个有效的音频文件进行比较")return None, None# 转换为numpy数组features_matrix = np.array(features_list)# 计算余弦相似度矩阵similarity_matrix = cosine_similarity(features_matrix)return valid_files, similarity_matrixdef plot_similarity_matrix(files, similarity_matrix):"""绘制相似度矩阵热图"""plt.figure(figsize=(10, 8))plt.imshow(similarity_matrix, cmap='hot', interpolation='nearest')plt.colorbar()# 设置坐标轴标签file_names = [os.path.basename(file) for file in files]plt.xticks(range(len(file_names)), file_names, rotation=45)plt.yticks(range(len(file_names)), file_names)# 添加相似度数值for i in range(len(file_names)):for j in range(len(file_names)):plt.text(j, i, f'{similarity_matrix[i, j]:.2f}',ha='center', va='center', color='black')plt.title('声纹相似度矩阵')plt.tight_layout()plt.savefig('voiceprint_similarity.png')plt.show()def main():"""主函数:比较多个声纹文件并显示结果"""# 示例:指定要比较的音频文件路径audio_files = ["E:\\Projects\\pyprojects\\files\\voice1.wav","E:\\Projects\\pyprojects\\files\\voice2.wav","E:\\Projects\\pyprojects\\files\\voice3.wav"]# 检查文件是否存在valid_files = []for file in audio_files:if os.path.exists(file):valid_files.append(file)else:print(f"文件不存在: {file}")if len(valid_files) < 2:print("没有足够的有效文件进行比较")return# 比较声纹files, similarity_matrix = compare_voiceprints(valid_files)if similarity_matrix is not None:# 打印相似度矩阵print("相似度矩阵:")file_names = [os.path.basename(file) for file in files]print("\t" + "\t".join(file_names))for i, row in enumerate(similarity_matrix):print(f"{file_names[i]}\t" + "\t".join([f"{val:.4f}" for val in row]))# 绘制相似度热图plot_similarity_matrix(files, similarity_matrix)if __name__ == "__main__":main()运行结果:
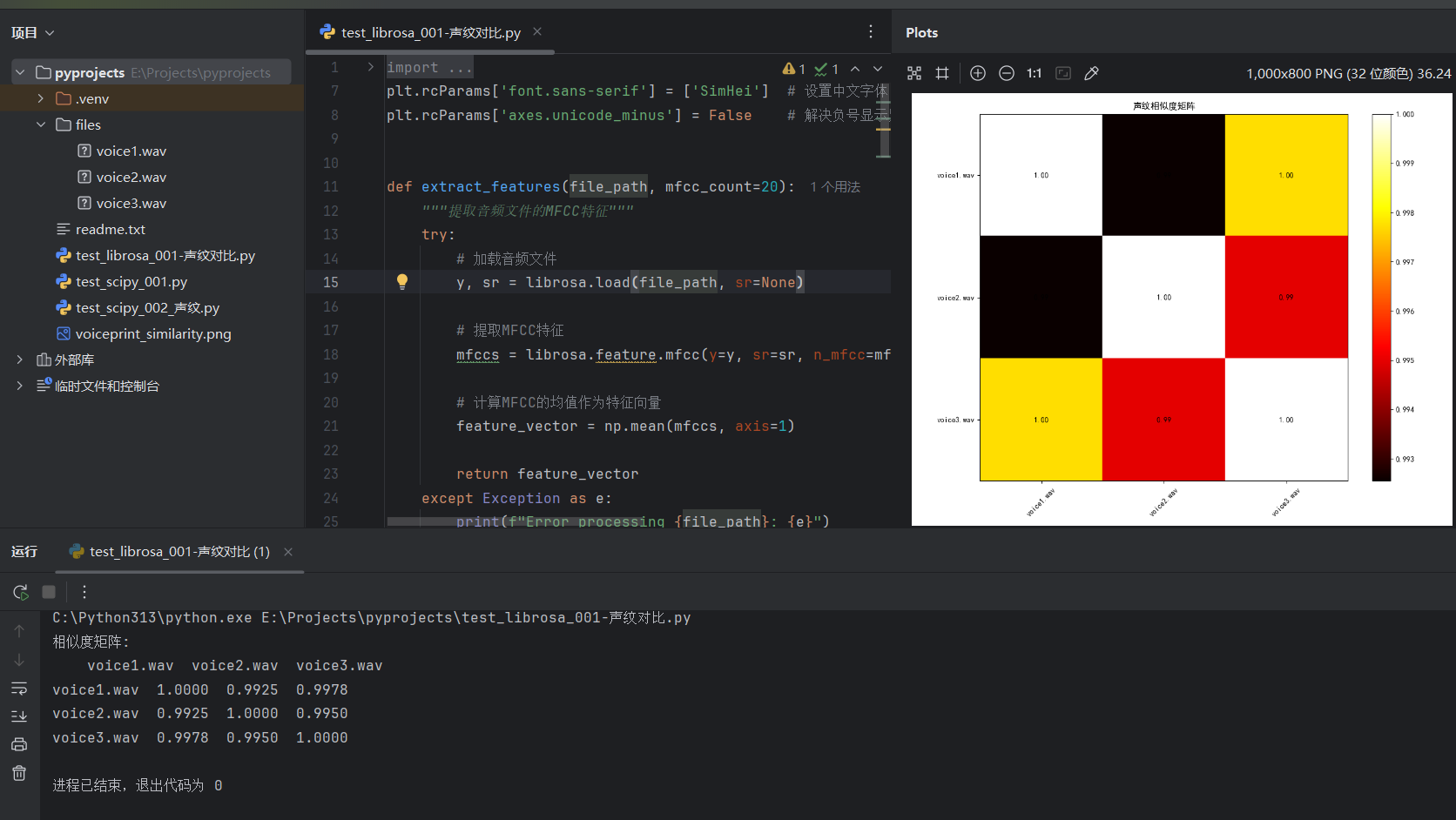
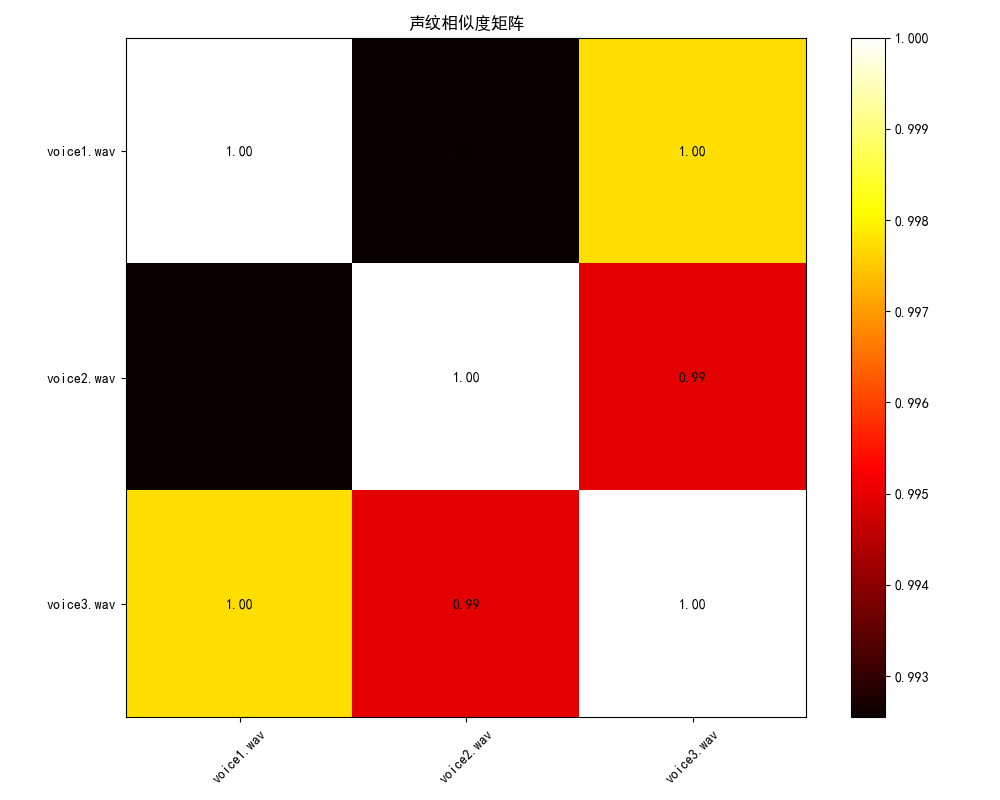
六、与其他工具对比
| 工具 | 定位 | 特点 |
|---|---|---|
| Librosa | 音频分析与特征提取、语音处理(如语音识别) | 专注于音乐/语音信号处理,算法丰富、提供底层特征(MFCC、STFT),适合科研 |
| TensorFlow | 端到端深度学习模型 | 适合构建语音识别、合成等完整系统 |
| pydub | 音频文件操作(剪切、合并) | 简单易用,但功能较单一 |
七、适用人群
- 研究人员:需要快速实现音频特征提取和分析。
- 开发者:构建语音助手、音乐推荐系统等应用。
- 学生/教育者:学习音频信号处理的基础理论与实践。
八、总结
Librosa 是音频处理领域的“瑞士军刀”,尤其适合需要提取音频特征(如 MFCC、频谱图)的场景。对于复杂任务(如端到端语音识别),可结合深度学习框架(如 PyTorch)使用。其丰富的算法库和易用性使其成为音频分析的首选工具之一。