建设工程指数网站成华区统一建设办公室网站
第一章:人工智能之不同数据类型及其特点梳理
第二章:自然语言处理(NLP):文本向量化从文字到数字的原理
第三章:循环神经网络RNN:理解 RNN的工作机制与应用场景(附代码)
第四章:循环神经网络RNN、LSTM以及GRU 对比(附代码)
第五章:理解Seq2Seq的工作机制与应用场景中英互译(附代码)
第六章:深度学习架构Seq2Seq-添加并理解注意力机制(一)
第七章:深度学习架构Seq2Seq-添加并理解注意力机制(二)
第八章:深度学习模型Transformer初步认识整体架构
一、Transformer 是什么?
Transformer 是 Google 在 2017 年提出的 基于自注意力机制(Self-Attention) 的深度学习模型,彻底摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),成为自然语言处理(NLP)领域的革命性架构。其核心思想是通过 全局依赖建模 和 并行计算 高效处理序列数据,广泛应用于机器翻译、文本生成、语音识别等任务。
典型应用
- BERT、GPT 等预训练模型均基于 Transformer。
- ChatGPT、DALL·E 等生成式 AI 的核心架构。
二、产生的背景
2.1. 传统模型的局限性
- RNN(LSTM/GRU):
- 序列依赖:必须逐时间步计算,无法并行训练。
- 长距离依赖:梯度消失/爆炸问题严重,难以捕捉远距离词的关系。
- CNN:
- 局部感受野:依赖卷积核大小,难以建模全局依赖。
- 位置敏感性:需堆叠多层才能扩大感受野,效率低。
2.2. 注意力机制的启发
- 2014 年,注意力机制首次在 Seq2Seq 模型中被提出,解决了编码器信息压缩的瓶颈。
- 但基于 RNN 的注意力模型依然无法完全并行,且长序列处理能力有限。
2.3. 硬件算力提升
- GPU/TPU 的普及使得大规模并行计算成为可能,推动了 Transformer 的可行性。
三、发展历史
| 时间 | 里程碑 |
|---|---|
| 2017 | Transformer 诞生:论文《Attention Is All You Need》提出纯注意力架构。 |
| 2018 | BERT:基于 Transformer 的双向预训练模型,刷新多项 NLP 任务记录。 |
| 2018 | GPT:基于 Transformer 的单向生成式预训练模型,开启大模型时代。 |
| 2020 | Vision Transformer (ViT):将 Transformer 应用于计算机视觉领域。 |
| 2022 | ChatGPT:基于 Transformer 的对话模型,引发生成式 AI 的爆发。 |
四、Transformer 的优缺点
优点
| 特性 | 说明 |
|---|---|
| 并行计算 | 所有位置同时计算,训练速度远超 RNN/CNN。 |
| 长距离依赖建模 | 自注意力直接捕捉任意位置的关系,避免梯度消失。 |
| 可扩展性 | 通过堆叠多层和多头注意力,轻松扩展模型容量。 |
| 多模态支持 | 统一处理文本、图像、语音等不同模态数据(如 ViT、Whisper)。 |
缺点
| 局限性 | 说明 |
|---|---|
| 计算复杂度高 | 自注意力复杂度为 O ( N 2 ) O(N^2) O(N2),长序列(如文档)计算成本剧增。 |
| 显存占用大 | 存储注意力矩阵需大量显存,限制输入长度。 |
| 数据需求高 | 依赖海量训练数据,小数据场景易过拟合。 |
五、Transformer 整体架构
Transformer 由 编码器(Encoder) 和 解码器(Decoder) 堆叠组成,
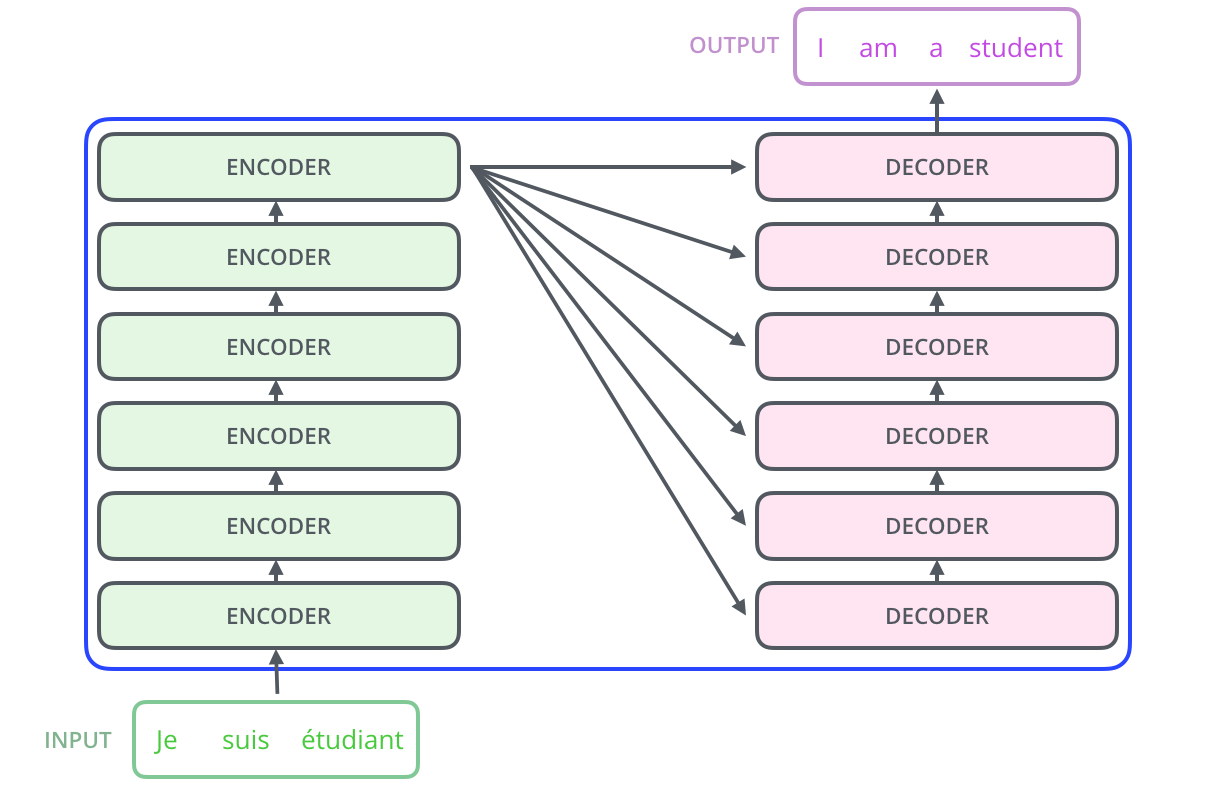
而每一个编码器或者解码器内部,又由不同的组件构成。
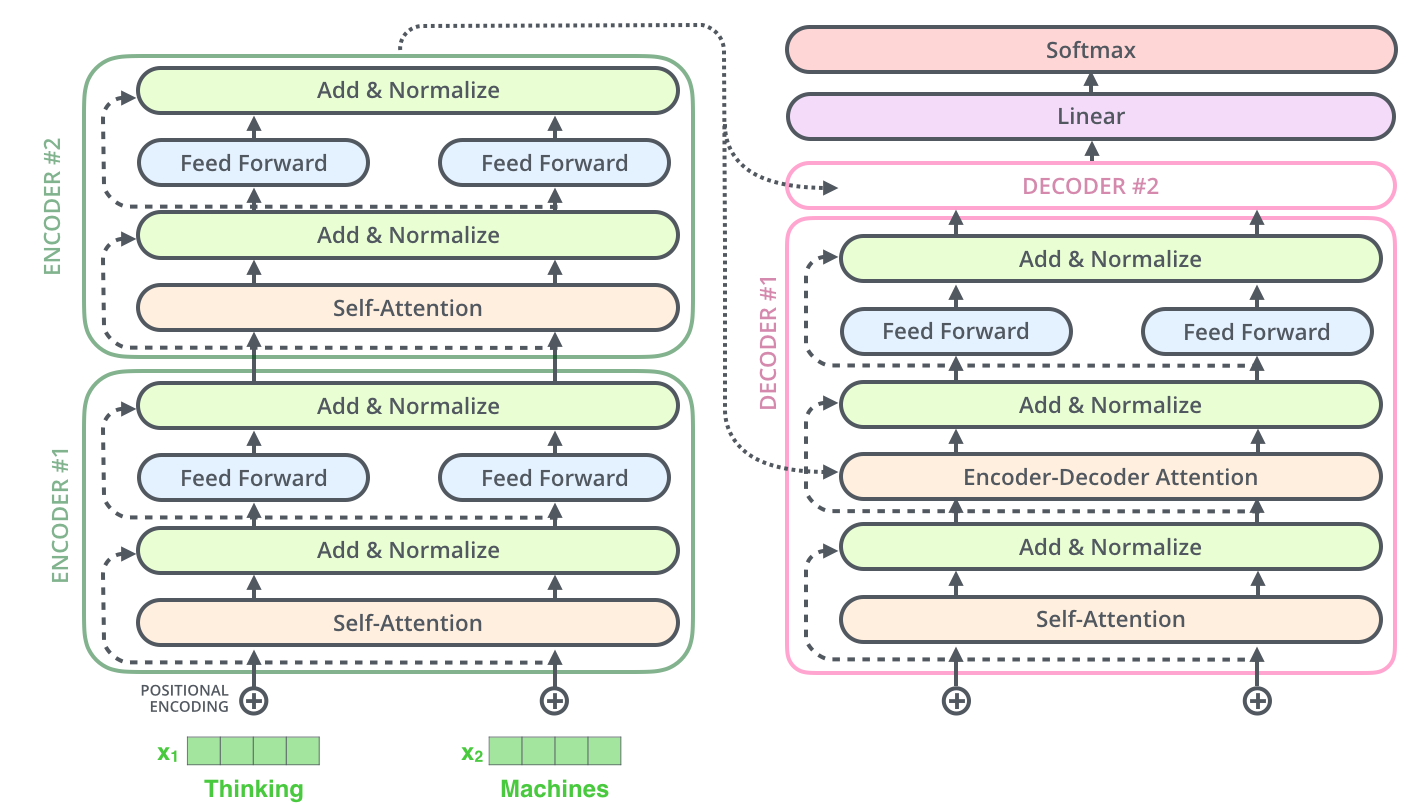
编码器(Encoder)
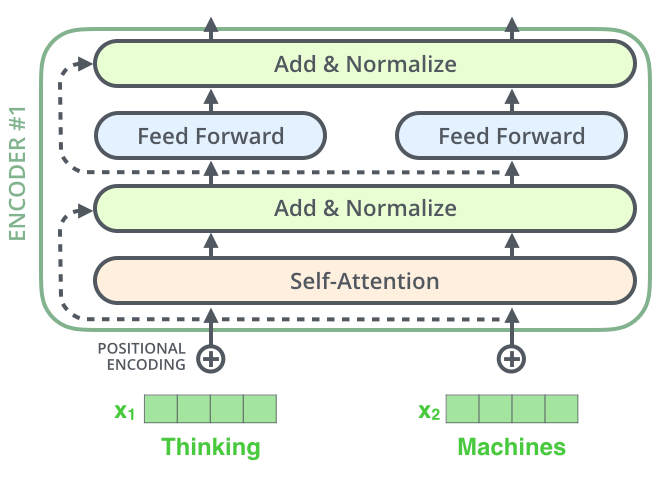
- 编码器(Encoder)包含 N 个相同层,每层由以下组件构成:
- 多头自注意力(Multi-Head Self-Attention)
- 前馈网络(Feed-Forward Network)
- 残差连接(Residual Connection) 和 层归一化(LayerNorm)
解码器(Decoder)
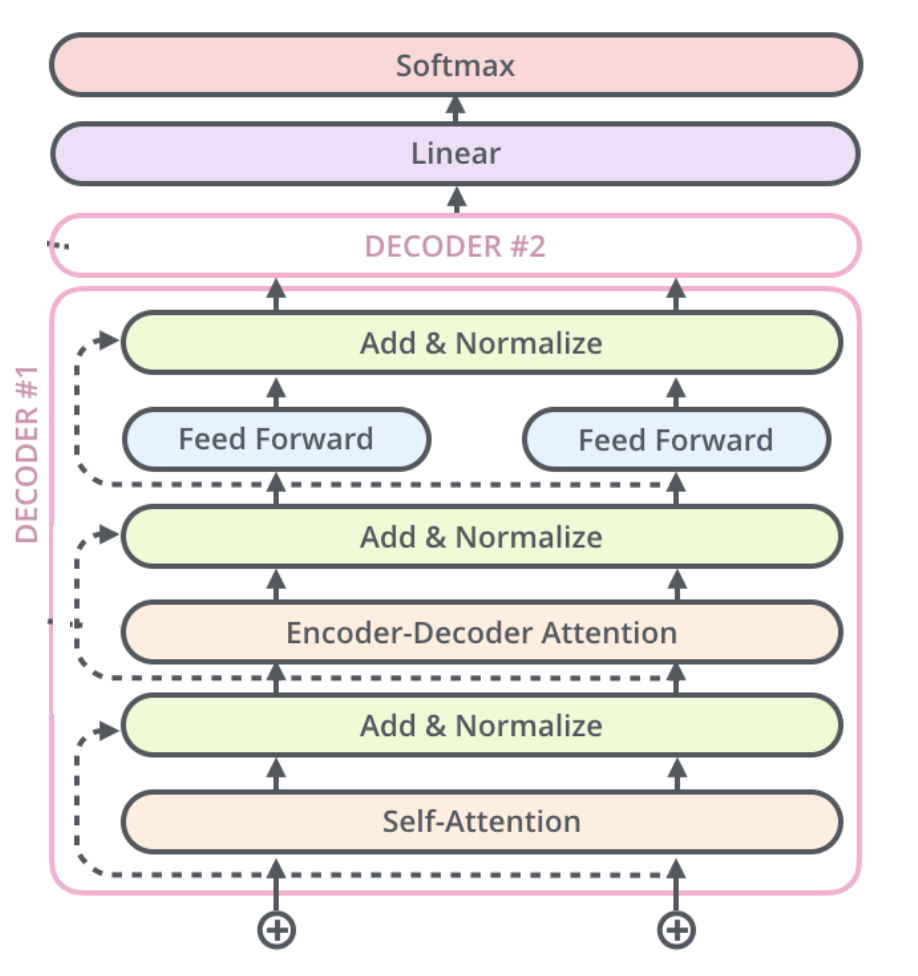
- 解码器(Decoder)包含 N 个相同层,每层在编码器基础上增加:
- 掩码多头自注意力(Masked Multi-Head Self-Attention)
- 编码器-解码器注意力(Encoder-Decoder Attention)
六、核心组件
6.1. 自注意力机制(Self-Attention)
目标:为序列中每个位置生成加权表示,反映全局依赖关系。
计算步骤:
- 生成 Q、K、V 矩阵:
Q = X W Q , K = X W K , V = X W V Q = XW^Q, \quad K = XW^K, \quad V = XW^V Q=XWQ,K=XWK,V=XWV - 计算注意力分数:
Attention ( Q , K , V ) = Softmax ( Q K ⊤ d k ) V \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V Attention(Q,K,V)=Softmax(dkQK⊤)V- 缩放点积:除以 d k \sqrt{d_k} dk 防止梯度爆炸。
- Softmax:归一化为概率分布。
6.2. 多头注意力(Multi-Head Attention)
- 并行计算:将 Q、K、V 拆分为多个子空间(头),分别计算注意力后拼接:
MultiHead ( Q , K , V ) = Concat ( head 1 , … , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO- 优势:捕捉不同子空间的语义特征(如语法、语义)。
6.3. 位置编码(Positional Encoding)
- 目标:为输入序列注入位置信息(替代 RNN 的时序性)。
- 公式(正弦/余弦函数):
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d ) , P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d}}\right), \quad PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d}}\right) PE(pos,2i)=sin(100002i/dpos),PE(pos,2i+1)=cos(100002i/dpos) - 效果:使模型能区分不同位置的词(如“猫追狗” vs “狗追猫”)。
6.4. 前馈网络(Feed-Forward Network)
- 结构:两层全连接层 + 激活函数(如 ReLU):
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2 - 作用:增强模型非线性表达能力。
6.5. 残差连接与层归一化
- 残差连接:缓解梯度消失,公式为 x + Sublayer ( x ) x + \text{Sublayer}(x) x+Sublayer(x)。
- 层归一化:加速训练,稳定梯度。
6.6. 编码器-解码器注意力
- 解码器在生成每个词时,通过 编码器-解码器注意力层 关注编码器的输出:
- Q 来自解码器的上一状态。
- K、V 来自编码器的输出。
- 作用:动态对齐输入与输出序列(如机器翻译中的词对齐)。
七、总结
Transformer 通过 自注意力机制 和 并行计算架构,解决了传统模型的序列处理瓶颈,成为 AI 领域的基石技术。尽管存在计算资源消耗大的问题,但其在长距离依赖建模、多模态支持等方面的优势,使其在 NLP、CV、语音等领域持续引领技术突破。
下一章详细介绍Transformer的几个核心组件,自注意力推导示例、什么是多头注意力、为什么要添加位置编码等