中国纪检监察报是日报吗广州推广seo
在上一篇文章中,我们探讨了可解释性AI与特征可视化技术。本文将深入多模态学习领域,重点介绍OpenAI提出的CLIP(Contrastive Language-Image Pretraining)模型,该模型通过对比学习实现了图像与文本的联合理解。
一、多模态学习基础
1. 核心概念
-
模态对齐:建立不同模态(如图像/文本)间的语义关联
-
跨模态检索:实现图文双向搜索
-
联合表征:学习统一的特征空间
2. 技术对比
| 方法 | 代表模型 | 特点 | 典型应用 |
|---|---|---|---|
| 双塔结构 | CLIP | 对比学习预训练 | 零样本分类 |
| 融合编码器 | ViLBERT | 跨模态注意力机制 | 视觉问答 |
| 生成式架构 | DALL·E | 文本到图像生成 | 创意内容生成 |
| 统一Transformer | Flamingo | 处理交错图文序列 | 多模态对话 |
二、CLIP模型原理
1. 对比学习目标
CLIP通过优化图像-文本对的相似度矩阵:
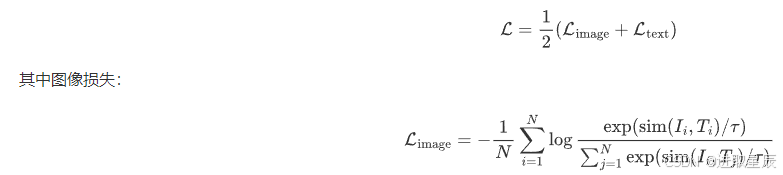
2. 模型架构
import torch
from torch import nn
from typing import Tuple, Optional
import torch.nn.functional as Fclass CLIP(nn.Module):def __init__(self,image_encoder: nn.Module,text_encoder: nn.Module,embed_dim: int = 512,init_logit_scale: float = 2.6592,projection_dropout: float = 0.1):"""CLIP模型实现参数:image_encoder: 图像编码器 (需有output_dim属性)text_encoder: 文本编码器 (需有output_dim属性)embed_dim: 联合嵌入空间的维度init_logit_scale: 初始温度参数projection_dropout: 投影层的dropout率"""super().__init__()self.image_encoder = image_encoderself.text_encoder = text_encoder# 图像/文本投影层self.image_proj = nn.Sequential(nn.Linear(image_encoder.output_dim, embed_dim),nn.Dropout(projection_dropout))self.text_proj = nn.Sequential(nn.Linear(text_encoder.output_dim, embed_dim),nn.Dropout(projection_dropout))# 可学习的温度参数 (logit scale)self.logit_scale = nn.Parameter(torch.tensor([init_logit_scale]))# 初始化self._init_weights()def _init_weights(self):"""初始化投影层权重"""for proj in [self.image_proj, self.text_proj]:if isinstance(proj[0], nn.Linear):nn.init.normal_(proj[0].weight, std=0.02)if proj[0].bias is not None:nn.init.zeros_(proj[0].bias)def encode_image(self, image: torch.Tensor) -> torch.Tensor:"""提取归一化的图像特征"""image_features = self.image_proj(self.image_encoder(image))return image_features / image_features.norm(dim=1, keepdim=True)def encode_text(self, text: torch.Tensor) -> torch.Tensor:"""提取归一化的文本特征"""text_features = self.text_proj(self.text_encoder(text))return text_features / text_features.norm(dim=1, keepdim=True)def forward(self,image: torch.Tensor,text: torch.Tensor,return_features: bool = False) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]:"""前向传播参数:image: 输入图像张量 [batch, channels, H, W]text: 输入文本张量 [batch, seq_len]return_features: 是否返回原始特征返回:logits: 图像-文本相似度矩阵 [batch, batch](可选) image_features: 图像特征 [batch, embed_dim](可选) text_features: 文本特征 [batch, embed_dim]"""# 提取特征image_features = self.encode_image(image)text_features = self.encode_text(text)# 计算相似度logit_scale = self.logit_scale.exp().clamp(max=100) # 防止数值溢出logits = logit_scale * image_features @ text_features.t()if return_features:return logits, image_features, text_featuresreturn logitsdef compute_loss(self,image_features: torch.Tensor,text_features: torch.Tensor) -> torch.Tensor:"""计算对称对比损失参数:image_features: 归一化的图像特征 [batch, embed_dim]text_features: 归一化的文本特征 [batch, embed_dim]返回:损失值 (标量张量)"""logit_scale = self.logit_scale.exp().clamp(max=100)# 计算相似度矩阵logits_per_image = logit_scale * image_features @ text_features.t()logits_per_text = logits_per_image.t()# 创建标签 (对角线为匹配对)batch_size = image_features.shape[0]labels = torch.arange(batch_size, device=image_features.device)# 对称损失loss_image = F.cross_entropy(logits_per_image, labels)loss_text = F.cross_entropy(logits_per_text, labels)return (loss_image + loss_text) / 2# 示例用法
if __name__ == "__main__":# 模拟编码器 (实际应使用ViT/Transformer等)class MockEncoder(nn.Module):def __init__(self, output_dim=768):super().__init__()self.output_dim = output_dimself.proj = nn.Linear(1000, output_dim)def forward(self, x):return self.proj(torch.randn(x.shape[0], 1000).to(x.device))# 初始化CLIPimage_encoder = MockEncoder()text_encoder = MockEncoder()clip_model = CLIP(image_encoder, text_encoder)# 模拟输入batch_size = 4fake_images = torch.randn(batch_size, 3, 224, 224)fake_texts = torch.randint(0, 10000, (batch_size, 77))# 前向传播logits, img_feats, txt_feats = clip_model(fake_images, fake_texts, return_features=True)print(f"相似度矩阵形状: {logits.shape}")print(f"图像特征形状: {img_feats.shape}")print(f"文本特征形状: {txt_feats.shape}")# 计算损失loss = clip_model.compute_loss(img_feats, txt_feats)print(f"对比损失值: {loss.item():.4f}")输出为:
相似度矩阵形状: torch.Size([4, 4])
图像特征形状: torch.Size([4, 512])
文本特征形状: torch.Size([4, 512])
对比损失值: 1.6367三、CLIP实战应用
1. 使用官方预训练模型
import clip
import torch
from PIL import Image# 加载模型与预处理
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)# 图像-文本匹配
image = preprocess(Image.open("cat.jpeg")).unsqueeze(0).to(device)
text = clip.tokenize(["a cat", "a dog", "a bird"]).to(device)with torch.no_grad():logits_per_image, _ = model(image, text)probs = logits_per_image.softmax(dim=-1).cpu().numpy()print("预测概率:", probs) #预测概率: [[0.9785 0.01087 0.010704]]2. 零样本图像分类
import torch
import clip
from PIL import Image
import matplotlib.pyplot as plt
from typing import List, Optional, Tupleclass ZeroShotCLIPClassifier:def __init__(self, model_name: str = "ViT-B/32", device: Optional[str] = None):"""初始化CLIP零样本分类器参数:model_name: CLIP模型名称 (e.g. "ViT-B/32", "RN50")device: 指定设备 (None则自动选择)"""self.device = device or ("cuda" if torch.cuda.is_available() else "cpu")self.model, self.preprocess = clip.load(model_name, device=self.device)self.model.eval()def predict(self,image_path: str,class_descriptions: List[str],temperature: float = 100.0,show_visualization: bool = True) -> Tuple[str, torch.Tensor]:"""执行零样本分类参数:image_path: 图像文件路径class_descriptions: 类别描述列表temperature: 温度参数控制置信度分布show_visualization: 是否显示分类结果可视化返回:tuple: (预测类别, 各类别概率)"""try:# 1. 图像预处理image = self._load_and_preprocess(image_path)# 2. 文本tokenizetext_inputs = self._prepare_text(class_descriptions)# 3. 特征提取with torch.no_grad():image_features = self.model.encode_image(image)text_features = self.model.encode_text(text_inputs)# 4. 计算相似度logits = (temperature * image_features @ text_features.T)probs = logits.softmax(dim=-1).squeeze()# 5. 结果处理pred_idx = probs.argmax().item()pred_class = class_descriptions[pred_idx]if show_visualization:self._visualize_results(image_path, class_descriptions, probs.cpu())return pred_class, probsexcept Exception as e:raise RuntimeError(f"分类失败: {str(e)}") from edef _load_and_preprocess(self, image_path: str) -> torch.Tensor:"""加载并预处理图像"""try:image = Image.open(image_path)return self.preprocess(image).unsqueeze(0).to(self.device)except FileNotFoundError:raise ValueError(f"图像文件不存在: {image_path}")except Exception as e:raise RuntimeError(f"图像加载失败: {str(e)}")def _prepare_text(self, descriptions: List[str]) -> torch.Tensor:"""准备文本输入"""if not descriptions:raise ValueError("类别描述列表不能为空")return torch.cat([clip.tokenize(desc) for desc in descriptions]).to(self.device)def _visualize_results(self,image_path: str,classes: List[str],probs: torch.Tensor) -> None:"""可视化分类结果"""plt.figure(figsize=(12, 6))# 显示图像plt.subplot(1, 2, 1)image = Image.open(image_path)plt.imshow(image)plt.axis('off')plt.title('Input Image')# 显示分类概率plt.subplot(1, 2, 2)colors = plt.cm.viridis(probs.numpy() / probs.max())bars = plt.barh(classes, probs.numpy(), color=colors)plt.xlabel('Probability')plt.title('Classification Probabilities')plt.gca().invert_yaxis() # 最高概率显示在最上方# 添加概率值标签for bar in bars:width = bar.get_width()plt.text(width + 0.01, bar.get_y() + bar.get_height()/2,f'{width:.2f}',va='center')plt.tight_layout()plt.show()# 使用示例
if __name__ == "__main__":# 初始化分类器classifier = ZeroShotCLIPClassifier(model_name="ViT-B/32")# 定义类别描述 (可自由扩展)animal_classes = ["a photo of a cat","a photo of a dog", "a photo of a bird","a photo of a horse","a photo of a fish"]# 执行分类image_path = "cat.jpeg" # 替换为你的图像路径pred_class, probs = classifier.predict(image_path=image_path,class_descriptions=animal_classes,temperature=100.0,show_visualization=True)print(f"\n预测结果: {pred_class}")print("各类别概率:")for cls, prob in zip(animal_classes, probs):print(f"- {cls}: {prob.item():.4f}")输出为:
预测结果: a photo of a cat
各类别概率:
- a photo of a cat: 1.0000
- a photo of a dog: 0.0000
- a photo of a bird: 0.0000
- a photo of a horse: 0.0000
- a photo of a fish: 0.00003. 特征空间可视化
import torch
import umap
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from typing import List, Optional, Tuple
from matplotlib.offsetbox import OffsetImage, AnnotationBbox
from sklearn.preprocessing import StandardScalerclass MultimodalVisualizer:def __init__(self, model, preprocess,device: str = "cuda" if torch.cuda.is_available() else "cpu",n_neighbors: int = 15,min_dist: float = 0.1,metric: str = 'cosine',random_state: int = 42):"""参数:model: 已加载的CLIP模型preprocess: CLIP预处理函数device: 指定计算设备n_neighbors: UMAP邻居数min_dist: UMAP点间最小距离metric: 距离度量方式random_state: 随机种子"""self.model = modelself.preprocess = preprocessself.device = deviceself.model.to(self.device) # 确保模型在正确设备上self.reducer = umap.UMAP(n_neighbors=n_neighbors,min_dist=min_dist,metric=metric,random_state=random_state)self.scaler = StandardScaler()def visualize_embeddings(self, image_paths: List[str], texts: List[str], **kwargs):"""可视化入口方法"""# 提取特征image_embeddings, text_embeddings = self._extract_features(image_paths, texts)# 合并特征并标准化all_embeddings = torch.cat([image_embeddings, text_embeddings]).cpu().numpy()scaled_embeddings = self.scaler.fit_transform(all_embeddings)# 降维可视化return self._plot_embeddings(scaled_embeddings, len(image_paths),image_paths,texts,**kwargs)def _extract_features(self, image_paths, texts):"""特征提取方法"""# 图像特征image_features = []for path in image_paths:try:image = Image.open(path)image_input = self.preprocess(image).unsqueeze(0).to(self.device)with torch.no_grad():features = self.model.encode_image(image_input)image_features.append(features)except Exception as e:print(f"跳过图像 {path}: {str(e)}")continue# 文本特征text_inputs = torch.cat([clip.tokenize(txt) for txt in texts]).to(self.device) # 显式指定设备with torch.no_grad():text_features = self.model.encode_text(text_inputs)return torch.cat(image_features), text_featuresdef _plot_embeddings(self, embeddings, n_images, image_paths, texts, **kwargs):"""可视化绘图方法"""# 参数设置figsize = kwargs.get('figsize', (15, 10))point_size = kwargs.get('point_size', 50)sample_images = kwargs.get('sample_images', 5)# 创建图表fig, ax = plt.subplots(figsize=figsize)# 绘制图像点img_scatter = ax.scatter(embeddings[:n_images, 0], embeddings[:n_images, 1],c='blue', label='Images', s=point_size, alpha=0.5)# 绘制文本点txt_scatter = ax.scatter(embeddings[n_images:, 0], embeddings[n_images:, 1],c='red', label='Texts', s=point_size, alpha=0.7)# 添加交互元素self._add_interactive_elements(ax, embeddings, n_images, image_paths, texts, sample_images)# 美化图表ax.set_title('CLIP Multimodal Embedding Space', pad=20)ax.legend()plt.tight_layout()return figdef _add_interactive_elements(self, ax, embeddings, n_images, image_paths, texts, sample_images):"""添加交互元素"""# 添加文本标签for i in range(n_images, len(embeddings)):ax.annotate(texts[i-n_images][:15] + "..." if len(texts[i-n_images]) > 15 else texts[i-n_images],(embeddings[i, 0], embeddings[i, 1]),fontsize=8, alpha=0.8)# 添加缩略图step = max(1, n_images // sample_images)for i in range(0, n_images, step):try:img = Image.open(image_paths[i])img.thumbnail((100, 100))im = OffsetImage(img, zoom=0.5)ab = AnnotationBbox(im, (embeddings[i, 0], embeddings[i, 1]),frameon=False, pad=0)ax.add_artist(ab)except Exception as e:print(f"无法加载缩略图 {image_paths[i]}: {str(e)}")# 使用示例
if __name__ == "__main__":import clip# 初始化CLIP模型device = "cuda" if torch.cuda.is_available() else "cpu"model, preprocess = clip.load("ViT-B/32", device=device)# 准备数据image_paths = ["cat.jpeg","dog.jpg","bird.jpeg","car.jpg","building.jpg"]texts = ["a photo of a cat","a picture of a dog","a bird flying in the sky","a red car on the road","a modern office building"]# 创建可视化visualizer = MultimodalVisualizer(model, preprocess, device=device)fig = visualizer.visualize_embeddings(image_paths=image_paths,texts=texts,sample_images=2,point_size=80)plt.savefig("multimodal-embedding-space.png")plt.show()输出为:
四、自定义CLIP训练
1. 数据准备
import torch
from torch.utils.data import Dataset
from PIL import Image
import clip
from typing import List, Callable, Optional
import numpy as np
import osclass ImageTextDataset(Dataset):def __init__(self,image_paths: List[str],texts: List[str],transform: Optional[Callable] = None,preload_images: bool = False,max_text_length: int = 77,tokenizer: Callable = clip.tokenize,retry_on_error: int = 3):"""多模态图像-文本数据集参数:image_paths: 图像路径列表texts: 对应文本描述列表transform: 图像预处理函数preload_images: 是否预加载图像到内存max_text_length: 文本最大token长度tokenizer: 文本tokenizer函数retry_on_error: 错误重试次数"""assert len(image_paths) == len(texts), "图像和文本数量必须相同"self.image_paths = image_pathsself.texts = textsself.transform = transformself.tokenizer = tokenizerself.max_text_length = max_text_lengthself.retry_on_error = retry_on_error# 预加载选项self.preloaded = Noneif preload_images:self._preload_images()def _preload_images(self):"""将图像预加载到内存"""self.preloaded = []for path in self.image_paths:for _ in range(self.retry_on_error + 1):try:img = Image.open(path).convert('RGB')self.preloaded.append(img)breakexcept Exception as e:if _ == self.retry_on_error:print(f"无法加载图像 {path}: {str(e)}")self.preloaded.append(None)def __len__(self) -> int:return len(self.image_paths)def __getitem__(self, idx: int) -> tuple:"""返回:tuple: (图像张量, 文本token)如果加载失败且未预加载,返回 (None, None)"""# 文本处理text = self.texts[idx]text_tokens = self.tokenizer(text, truncate=True)[0] # 自动截断# 图像处理for attempt in range(self.retry_on_error + 1):try:if self.preloaded is not None:img = self.preloaded[idx]if img is None: # 预加载时已失败return None, Noneelse:img = Image.open(self.image_paths[idx]).convert('RGB')if self.transform:img = self.transform(img)return img, text_tokensexcept Exception as e:if attempt == self.retry_on_error:print(f"加载失败 {self.image_paths[idx]}: {str(e)}")if self.preloaded is not None:self.preloaded[idx] = None # 标记为失败return None, Nonedef get_valid_samples(self) -> 'ImageTextDataset':"""获取有效样本的子数据集"""valid_indices = []for i in range(len(self)):img_path = self.image_paths[i]if self.preloaded and self.preloaded[i] is None:continueif not os.path.exists(img_path):continuevalid_indices.append(i)return ImageTextDataset(image_paths=[self.image_paths[i] for i in valid_indices],texts=[self.texts[i] for i in valid_indices],transform=self.transform,preload_images=False, # 不再重复预加载max_text_length=self.max_text_length,tokenizer=self.tokenizer)# 使用示例
if __name__ == "__main__":import clipfrom torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize# 1. 初始化CLIP预处理device = "cuda" if torch.cuda.is_available() else "cpu"_, preprocess = clip.load("ViT-B/32", device=device)# 2. 自定义预处理管道custom_transform = Compose([Resize(256),CenterCrop(224),lambda x: x.convert("RGB"), # 确保RGB格式ToTensor(),Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))])# 3. 创建数据集dataset = ImageTextDataset(image_paths=["cat.jpeg", "dog.jpg", "nonexistent.jpg"],texts=["a cute cat", "a happy dog", "missing image"],transform=custom_transform,preload_images=True,retry_on_error=2)# 4. 过滤无效样本valid_dataset = dataset.get_valid_samples()print(f"原始样本数: {len(dataset)} | 有效样本数: {len(valid_dataset)}")# 5. 数据加载示例from torch.utils.data import DataLoaderdef collate_fn(batch):# 过滤掉无效样本 (None, None)batch = [item for item in batch if item[0] is not None]if len(batch) == 0:return Noneimages, texts = zip(*batch)return torch.stack(images), torch.stack(texts)dataloader = DataLoader(valid_dataset,batch_size=2,shuffle=True,collate_fn=collate_fn,num_workers=4,pin_memory=True)# 6. 测试迭代for batch_idx, (images, texts) in enumerate(dataloader):print(f"Batch {batch_idx}:")print(f"- 图像形状: {images.shape}")print(f"- 文本形状: {texts.shape}")if batch_idx >= 1: # 只展示前两个batchbreak输出为:
无法加载图像 nonexistent.jpg: [Errno 2] No such file or directory: '/workspace/nonexistent.jpg'
原始样本数: 3 | 有效样本数: 2
Batch 0:
- 图像形状: torch.Size([2, 3, 224, 224])
- 文本形状: torch.Size([2, 77])2. 训练循环
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import AdamW
from torch.optim.lr_scheduler import CosineAnnealingLR
from tqdm import tqdm
import logging
from datetime import datetime
from torch.utils.data import DataLoader
from torchvision import transformsdef setup_logger():"""设置基础日志配置"""logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s',handlers=[# 将日志输出到文件(文件名包含当前时间)logging.FileHandler(f'clip_training_{datetime.now().strftime("%Y%m%d_%H%M%S")}.log'),# 同时输出到控制台logging.StreamHandler()])def train_clip(model, train_loader, val_loader=None, epochs=5, device='cuda', save_path='best_clip_model.pth'):"""使用对比学习训练CLIP模型参数:model: 要训练的CLIP模型(应返回图像和文本的嵌入向量)train_loader: 训练数据的DataLoaderval_loader: 可选,验证数据的DataLoaderepochs: 训练轮数device: 训练设备 ('cuda' 或 'cpu')save_path: 最佳模型保存路径"""setup_logger()logger = logging.getLogger(__name__)# 将模型移动到指定设备model = model.to(device)# 设置优化器和学习率调度器optimizer = AdamW(model.parameters(), lr=5e-5, weight_decay=0.01) # 使用权重衰减防止过拟合scheduler = CosineAnnealingLR(optimizer, T_max=epochs * len(train_loader)) # 余弦退火学习率# 跟踪最佳验证损失best_loss = float('inf')for epoch in range(epochs):model.train() # 设置为训练模式total_loss = 0.0# 使用进度条显示训练过程progress_bar = tqdm(train_loader, desc=f'Epoch {epoch + 1}/{epochs}', leave=False)for batch_idx, (images, texts) in enumerate(progress_bar):# 将数据移动到设备images, texts = images.to(device), texts.to(device)# 前向传播:获取图像和文本特征image_features, text_features = model(images, texts)# 特征归一化(重要步骤)image_features = F.normalize(image_features, dim=-1)text_features = F.normalize(text_features, dim=-1)# 计算相似度矩阵(使用可学习的温度参数logit_scale)logit_scale = model.logit_scale.exp()logits_per_image = logit_scale * image_features @ text_features.t() # 图像-文本相似度logits_per_text = logits_per_image.t() # 文本-图像相似度# 计算对比损失labels = torch.arange(len(images), device=device) # 创建对角线标签loss = (F.cross_entropy(logits_per_image, labels) +F.cross_entropy(logits_per_text, labels)) / 2 # 对称损失# 反向传播optimizer.zero_grad() # 清空梯度loss.backward() # 计算梯度# 梯度裁剪(防止梯度爆炸)torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)optimizer.step() # 更新参数scheduler.step() # 更新学习率total_loss += loss.item()progress_bar.set_postfix({'loss': loss.item()}) # 在进度条显示当前损失# 计算平均训练损失avg_train_loss = total_loss / len(train_loader)logger.info(f"Epoch {epoch + 1}/{epochs} - 训练损失: {avg_train_loss:.4f}")# 验证阶段if val_loader is not None:val_loss = evaluate(model, val_loader, device)logger.info(f"Epoch {epoch + 1}/{epochs} - 验证损失: {val_loss:.4f}")# 保存最佳模型if val_loss < best_loss:best_loss = val_losstorch.save(model.state_dict(), save_path)logger.info(f"保存新的最佳模型,验证损失: {val_loss:.4f}")return modeldef evaluate(model, data_loader, device='cuda'):"""在验证数据上评估模型"""model.eval() # 设置为评估模式total_loss = 0.0with torch.no_grad(): # 禁用梯度计算for images, texts in data_loader:images, texts = images.to(device), texts.to(device)# 获取特征并归一化image_features, text_features = model(images, texts)image_features = F.normalize(image_features, dim=-1)text_features = F.normalize(text_features, dim=-1)# 计算相似度矩阵logit_scale = model.logit_scale.exp()logits_per_image = logit_scale * image_features @ text_features.t()logits_per_text = logits_per_image.t()# 计算对比损失labels = torch.arange(len(images), device=device)loss = (F.cross_entropy(logits_per_image, labels) +F.cross_entropy(logits_per_text, labels)) / 2total_loss += loss.item()# 返回平均验证损失return total_loss / len(data_loader)# 1. 定义一个简单的CLIP模型结构(示例)
class SimpleCLIP(nn.Module):def __init__(self, image_embed_dim=512, text_embed_dim=512):super().__init__()# 图像编码器(使用简化的CNN)self.image_encoder = nn.Sequential(nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1),nn.ReLU(),nn.AdaptiveAvgPool2d(1),nn.Flatten(),nn.Linear(64, image_embed_dim))# 文本编码器(使用简化的LSTM)self.text_encoder = nn.LSTM(input_size=300, # 假设词向量维度为300hidden_size=text_embed_dim,num_layers=2,batch_first=True)# 可学习的温度参数(logit_scale)self.logit_scale = nn.Parameter(torch.ones([]) * 0.07)def forward(self, images, texts):# 图像特征提取image_features = self.image_encoder(images)# 文本特征提取(假设texts是预处理的词向量序列)_, (hidden, _) = self.text_encoder(texts)text_features = hidden[-1] # 取最后一层的隐藏状态return image_features, text_features# 2. 准备模拟数据集(实际使用时替换为真实数据集)
class DummyDataset(torch.utils.data.Dataset):def __init__(self, size=1000):self.size = size# 模拟图像数据(3通道,224x224)self.images = torch.randn(size, 3, 224, 224)# 模拟文本数据(假设已经转换为词向量序列,长度20,维度300)self.texts = torch.randn(size, 20, 300)def __len__(self):return self.sizedef __getitem__(self, idx):return self.images[idx], self.texts[idx]# 3. 数据预处理和加载
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])# 创建数据集和数据加载器
train_dataset = DummyDataset(size=1000)
val_dataset = DummyDataset(size=200)train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)# 4. 初始化模型并训练
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = SimpleCLIP().to(device)# 调用训练函数
trained_model = train_clip(model=model,train_loader=train_loader,val_loader=val_loader,epochs=5,device=device,save_path='best_clip_model.pth'
)# 5. 使用训练好的模型(示例)
def encode_image(model, image):"""编码单张图像"""model.eval()with torch.no_grad():image = image.unsqueeze(0).to(device) # 添加batch维度features = model.image_encoder(image)return F.normalize(features, dim=-1)def encode_text(model, text):"""编码单个文本"""model.eval()with torch.no_grad():text = text.unsqueeze(0).to(device) # 添加batch维度_, (hidden, _) = model.text_encoder(text)features = hidden[-1]return F.normalize(features, dim=-1)# 示例使用
test_image = torch.randn(3, 224, 224) # 模拟测试图像
test_text = torch.randn(20, 300) # 模拟测试文本image_feature = encode_image(trained_model, test_image)
text_feature = encode_text(trained_model, test_text)# 计算相似度
similarity = (image_feature @ text_feature.T) * trained_model.logit_scale.exp()
print(f"图像-文本相似度: {similarity.item():.4f}")输出为:
2025-04-02 02:24:47,144 - INFO - Epoch 1/5 - 训练损失: 3.4226
2025-04-02 02:24:47,216 - INFO - Epoch 1/5 - 验证损失: 3.2677
2025-04-02 02:24:47,238 - INFO - 保存新的最佳模型,验证损失: 3.2677
2025-04-02 02:24:47,935 - INFO - Epoch 2/5 - 训练损失: 3.4223
2025-04-02 02:24:48,016 - INFO - Epoch 2/5 - 验证损失: 3.2677
2025-04-02 02:24:48,065 - INFO - 保存新的最佳模型,验证损失: 3.2677
2025-04-02 02:24:48,772 - INFO - Epoch 3/5 - 训练损失: 3.4221
2025-04-02 02:24:48,845 - INFO - Epoch 3/5 - 验证损失: 3.2677
2025-04-02 02:24:48,899 - INFO - 保存新的最佳模型,验证损失: 3.2677
2025-04-02 02:24:49,583 - INFO - Epoch 4/5 - 训练损失: 3.4220
2025-04-02 02:24:49,653 - INFO - Epoch 4/5 - 验证损失: 3.2677
2025-04-02 02:24:49,706 - INFO - 保存新的最佳模型,验证损失: 3.2677
2025-04-02 02:24:50,380 - INFO - Epoch 5/5 - 训练损失: 3.4219
2025-04-02 02:24:50,450 - INFO - Epoch 5/5 - 验证损失: 3.2677
2025-04-02 02:24:50,496 - INFO - 保存新的最佳模型,验证损失: 3.2677
图像-文本相似度: -0.0156五、高级应用拓展
1. 跨模态检索增强
import torch
import clip
from PIL import Image
import os
import matplotlib.pyplot as plt
import numpy as npdef retrieve_images(query_text, image_db, model, preprocess, device, top_k=5, display=True):"""基于CLIP模型的文本到图像检索函数参数:query_text: str, 查询文本image_db: list, 图像路径列表model: CLIP模型preprocess: 图像预处理函数device: 计算设备top_k: int, 返回最相似的top_k个图像display: bool, 是否显示结果返回:list: 包含(image_path, similarity_score)元组的列表,按相似度降序排列"""# 编码查询文本text_input = clip.tokenize([query_text]).to(device)with torch.no_grad():text_features = model.encode_text(text_input)similarities = []# 计算每张图像与文本的相似度for img_path in image_db:try:image = preprocess(Image.open(img_path)).unsqueeze(0).to(device)with torch.no_grad():image_features = model.encode_image(image)# 计算余弦相似度sim = torch.cosine_similarity(text_features, image_features)similarities.append((img_path, sim.item()))except Exception as e:print(f"Error processing {img_path}: {str(e)}")continue# 按相似度降序排序sorted_results = sorted(similarities, key=lambda x: -x[1])[:top_k]if display:# 显示检索结果plt.figure(figsize=(15, 5))plt.suptitle(f'Query: "{query_text}"', fontsize=16)for i, (img_path, sim_score) in enumerate(sorted_results):img = Image.open(img_path)plt.subplot(1, top_k, i+1)plt.imshow(img)plt.title(f"Score: {sim_score:.3f}")plt.axis('off')plt.tight_layout()plt.show()return sorted_results# 示例使用
if __name__ == "__main__":# 设置设备device = "cuda" if torch.cuda.is_available() else "cpu"# 加载CLIP模型model, preprocess = clip.load("ViT-B/32", device=device)# 准备图像数据库image_folder = "sample_images" # 替换为你的图像文件夹路径image_db = [os.path.join(image_folder, f) for f in os.listdir(image_folder) if f.lower().endswith(('.png', '.jpg', '.jpeg'))]# 执行查询query = "a happy dog playing in the park"results = retrieve_images(query, image_db, model, preprocess, device, top_k=3)# 打印结果print("\nTop results:")for i, (img_path, score) in enumerate(results):print(f"{i+1}. {img_path} - Similarity: {score:.4f}")输出为:
Top results:
1. sample_images/dog.jpg - Similarity: 0.2151
2. sample_images/bird.jpeg - Similarity: 0.15322. 提示工程优化
import torch
import clip
from PIL import Image
import os
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import PCA# 设备设置
device = "cuda" if torch.cuda.is_available() else "cpu"def load_clip_model(model_name="ViT-B/32"):"""加载CLIP模型和预处理函数"""model, preprocess = clip.load(model_name, device=device)print(f"Loaded CLIP {model_name} on {device}")return model, preprocessdef optimize_prompt(class_name, templates, model, visualize=False):"""通过多提示模板优化文本特征表示参数:class_name: 目标类别名称(如"cat")templates: 提示模板列表model: CLIP模型visualize: 是否可视化特征空间返回:torch.Tensor: 优化后的文本特征向量 [embed_dim]"""# 生成多提示文本并编码text_inputs = torch.cat([clip.tokenize(t.format(class_name)) for t in templates]).to(device)with torch.no_grad():text_features = model.encode_text(text_inputs)text_features = text_features / text_features.norm(dim=-1, keepdim=True)# 计算平均特征mean_features = text_features.mean(dim=0, keepdim=True)mean_features = mean_features / mean_features.norm(dim=-1, keepdim=True)if visualize:visualize_features(text_features.cpu().numpy(), templates, class_name)return mean_features.squeeze(0)def visualize_features(features, templates, class_name):"""可视化提示模板生成的特征空间"""pca = PCA(n_components=2)reduced = pca.fit_transform(features)plt.figure(figsize=(10, 8))plt.scatter(reduced[:, 0], reduced[:, 1], c='blue', s=100)# 标注每个点对应的模板for i, (x, y) in enumerate(reduced):short_template = templates[i].replace("{}", "").strip() or "plain"plt.annotate(short_template, (x, y), textcoords="offset points", xytext=(0,10), ha='center')# 绘制平均特征点mean_point = reduced.mean(axis=0)plt.scatter(mean_point[0], mean_point[1], c='red', s=200, marker='*')plt.annotate("Optimized", mean_point, textcoords="offset points", xytext=(0,15), ha='center', color='red')plt.title(f'Prompt Feature Space for "{class_name}"\n(PCA Projection)')plt.xlabel("Principal Component 1")plt.ylabel("Principal Component 2")plt.grid(True)plt.show()def calculate_similarity(image_feature, text_feature):"""安全计算余弦相似度(0-100)参数:image_feature: 图像特征 [1, embed_dim]text_feature: 文本特征 [embed_dim] 或 [1, embed_dim]"""if text_feature.dim() == 1:text_feature = text_feature.unsqueeze(0)return (100.0 * (image_feature @ text_feature.mT)).item()def evaluate_prompt(model, preprocess, class_name, prompt_type="optimized"):"""评估提示效果参数:prompt_type: "optimized" 或 "single""""# 准备测试图像image_path = f"{class_name}.jpg" # 假设存在类名对应的图像try:image = preprocess(Image.open(image_path)).unsqueeze(0).to(device)except:print(f"Test image {image_path} not found, using random image")image = torch.randn(1, 3, 224, 224).to(device)with torch.no_grad():image_feature = model.encode_image(image)image_feature = image_feature / image_feature.norm(dim=-1, keepdim=True)if prompt_type == "optimized":templates = ["a photo of a {}","a bad photo of a {}","a cropped photo of the {}","a good photo of the {}","a low resolution photo of a {}","a high resolution photo of a {}","a close-up photo of a {}","a black and white photo of the {}"]text_feature = optimize_prompt(class_name, templates, model, visualize=True)else:text_input = clip.tokenize([f"a photo of a {class_name}"]).to(device)text_feature = model.encode_text(text_input)text_feature = text_feature / text_feature.norm(dim=-1, keepdim=True)text_feature = text_feature.squeeze(0)similarity = calculate_similarity(image_feature, text_feature)print(f"{prompt_type.capitalize()} prompt similarity: {similarity:.2f}")return similarityif __name__ == "__main__":# 1. 加载模型model, preprocess = load_clip_model()# 2. 定义测试类别class_name = "dog" # 替换为您想测试的类别# 3. 评估单提示和优化提示print("\n=== Prompt Engineering Evaluation ===")single_score = evaluate_prompt(model, preprocess, class_name, "single")optimized_score = evaluate_prompt(model, preprocess, class_name, "optimized")# 4. 显示改进效果improvement = optimized_score - single_scoreprint(f"\nImprovement from prompt engineering: {improvement:.2f} points")print(f"Relative improvement: {improvement/single_score*100:.1f}%")输出为:
Loaded CLIP ViT-B/32 on cuda=== Prompt Engineering Evaluation ===
Single prompt similarity: 24.89
Optimized prompt similarity: 25.83Improvement from prompt engineering: 0.94 points
Relative improvement: 3.8%六、总结与展望
本文深入探讨了:
-
CLIP架构原理:对比学习目标与双塔设计
-
零样本能力:无需微调的新类别识别
-
跨模态应用:图文检索与特征空间对齐
-
自定义训练:实现领域自适应
在下一篇文章《联邦学习与隐私保护》中,我们将探索如何在分布式环境下实现安全的多模态学习。
关键工具推荐:
pip install clip-anytorch umap-learn应用建议:
-
产品推荐系统使用CLIP实现跨模态搜索
-
内容审核结合提示工程增强分类效果
-
机器人导航通过图文对齐理解环境