购物网站答辩ppt怎么做网站关键词选择
----->更多内容,请移步“鲁班秘笈”!!<-----
视觉-语言模型(Vision-Language Models,简称VLMs)逐渐成为实现通用人工智能(AGI)的一项关键技术。通过在同一模型中对图像和文本进行对齐,VLM能够在虚拟和现实环境中进行感知、推理与决策。过去几年里,VLM已经在多模态推理、图像编辑、GUI 操作代理、自动驾驶和机器人等多个领域取得显著进展,然而当前的VLM仍然存在明显不足,例如:缺乏三维空间理解能力、难以进行精确计数、缺乏想象力和互动游戏推理等。
这些问题的根本原因在于一方面,视觉-语言数据的数量和质量远不如纯文本数据丰富;另一方面,多模态数据本身就具有异构性,导致训练与推理流程更加复杂,影响模型的效率与效果。
字节跳动近日推出了Seed1.5-VL——一个面向通用视觉-语言理解任务的多模态基础模型。Seed1.5-VL由一个532M参数的视觉编码器和一个拥有20B活跃参数的混合专家(MoE)大语言模型组成。尽管其架构相对紧凑,但它在广泛的公开VLM基准和内部评估测试中表现出色,在60个公开基准中的38个上实现了最先进的性能。此外,在GUI控制和游戏等以代理为中心的任务中,Seed1.5-VL的表现超过了领先的多模态系统,包括OpenAI CUA和Claude 3.7。
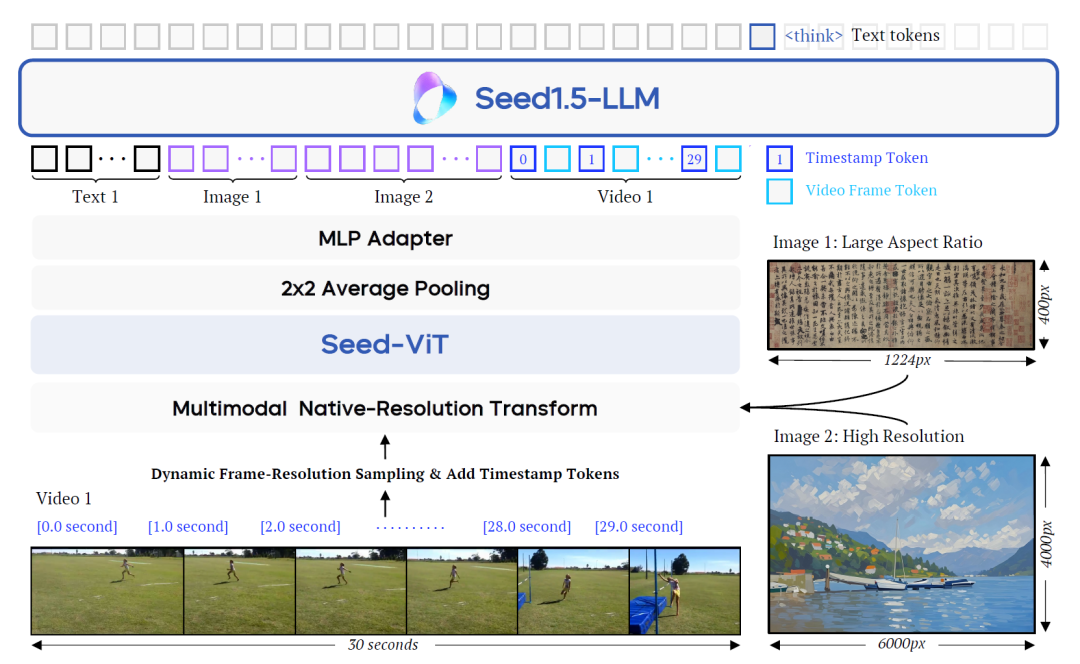
Seed1.5-VL 的架构由三个核心部分构成:Seed-ViT,专为高效图像和视频编码而设计的视觉Transformer。MLP适配器,用于将视觉特征映射为多模态统一表示。大型语言模型(LLM),具备20B活跃参数,用于理解和生成多模态文本。
整体架构如上图所示,模型支持不同尺寸的图片和视频输入,并通过原生分辨率转换模块保留了最大图像细节。视频输入采用动态帧分辨率采样策略,提升时间感知能力和效率。
Seed-ViT支持动态的分辨率,传统VLM多使用固定尺寸的图像输入(如224×224),这会导致高分辨率图片的细节丢失。Seed-ViT通过引入2D RoPE位置编码和动态分辨率支持机制,允许输入任意大小的图像,并保持原始结构信息。这在处理OCR、文档分析等需要细节的任务中表现出显著优势。

每张图像先被切分为不重叠的patch,再通过线性嵌入层映射为向量序列。为避免多张图像在batch中互相干扰,注意力机制使用了mask控制范围。编码后结果再进行2×2平均池化,以减少token数量,以便于降低LLM处理负担。
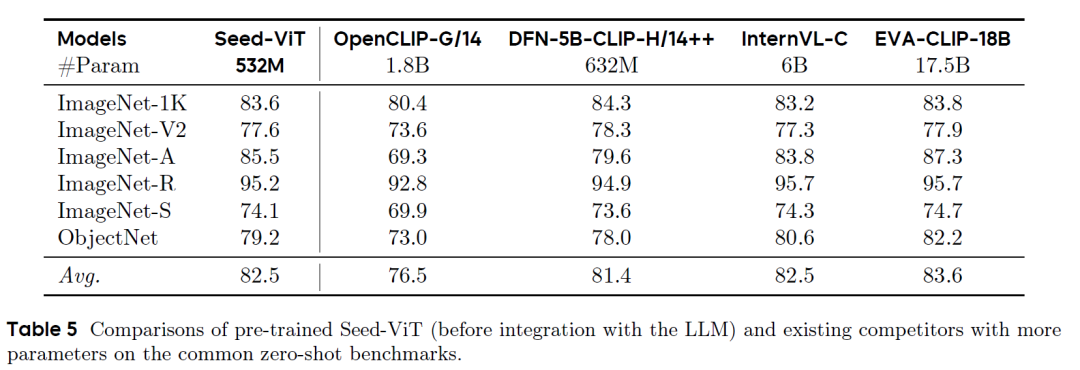
我们在ImageNet-1K、ImageNet-V2、ImageNet-A、ImageNet-R、ImageNet-S和ObjectNet等零样本图像分类基准上评估了Seed-ViT模型。如上表所示,Seed-ViT在这些数据集上取得了82.5%的平均零样本准确率,与InternVL-C-6B相当,而其参数量仅为后者的9%。更令人印象深刻的是,相比参数量30倍于它的EVA-CLIP-18B,Seed-ViT在大多数ImageNet变体上都取得了相当的准确率。此外,与DFN-5BCLIP-H/14++相比,Seed-ViT在包含复杂背景、旋转和视角变化的ObjectNet数据集以及包含自然对抗样本的ImageNet-A数据集上表现更优,这表明Seed-ViT对现实世界的变化具有更强的鲁棒性。
值得一提的是Seed-ViT的预训练方法,整个预训练过程分为三个阶段:
1. Masked Image Modeling (MIM)
该阶段以EVA02-CLIP-E为教师模型,学生模型随机初始化。训练过程中随机遮盖75%图像patch,并使用教师输出作为重建目标,通过余弦相似度损失进行优化。这一阶段显著增强了模型对图像结构和几何的感知能力。
2. 原生分辨率对比学习
将MIM预训练好的视觉编码器与CLIP-E文本编码器配合,进行图文对齐训练。采用SigLIP损失和SuperClass损失共同优化。对比学习强化了模型在图像和文本语义对齐方面的能力。
3. 全模态联合预训练
引入视频、音频、文本等模态,使用MiCo框架构建多模态对齐三元组(视频帧、音频、描述文本)。Seed-ViT学习处理这些不同模态的表示,获得强大的视频和语音理解能力。尽管这阶段只占预训练token总量的4.8%,但显著提升了模型的动态场景处理能力。
在视频处理方面,Seed1.5-VL采用动态帧-分辨率采样策略,根据任务需求调整帧率和分辨率。例如:普通任务:1帧/秒;高时序任务:2帧/秒;计数与运动追踪任务:5帧/秒。
每一帧图像都加上时间戳token,增强模型的时间感知能力。为了控制计算复杂度,模型设定了最大token预算为81920,利用6级分辨率等级动态分配帧的空间精度(如640、512、384等)。如果视频过长,系统会自动启用回退策略,降低帧数以保证覆盖完整视频。
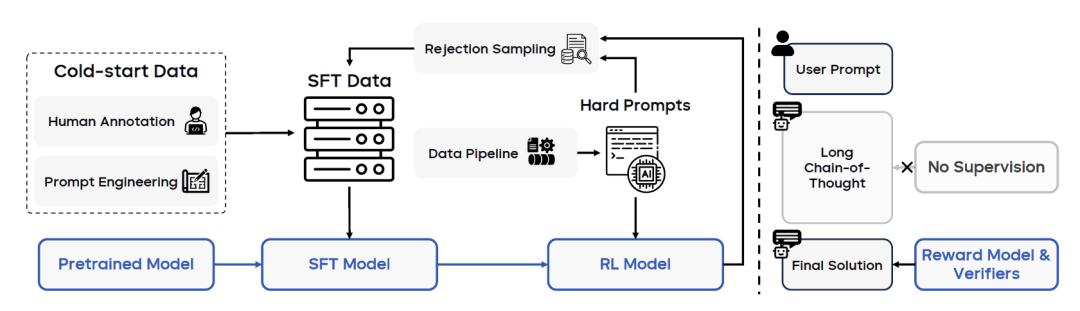
上图为Seed1.5-VL后训练流程概述。Seed1.5-VL的后训练包含结合拒绝采样与在线强化学习的迭代更新机制。通过构建了包含具有难度的提示词收集与筛选的数据管道,用于增强后训练数据集。
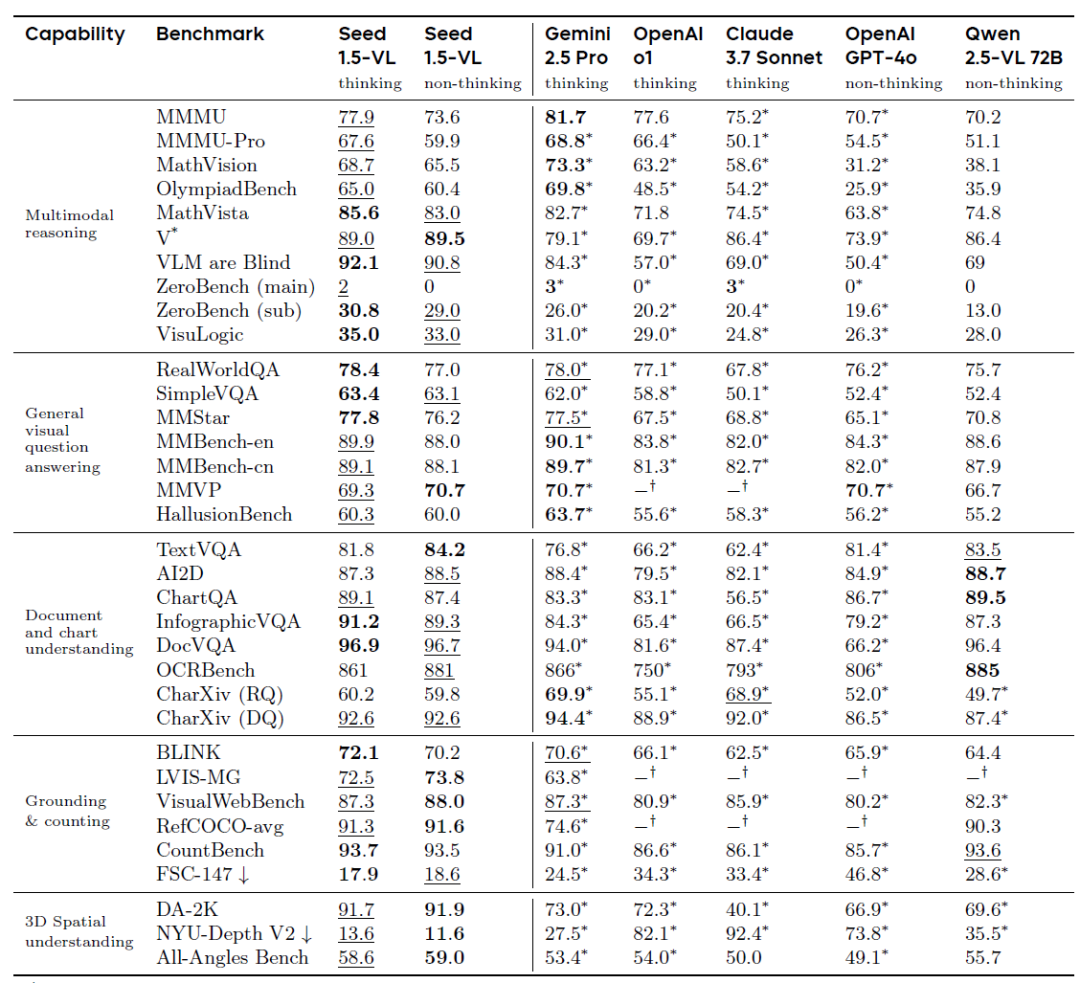
Seed1.5-VL通过高效架构、原生分辨率支持、大规模合成数据及多模态训练流程,构建一个同时具备强大理解能力与推理能力的视觉语言模型。其紧凑设计在保证性能的同时,显著降低了推理成本。除了视觉和视频理解外,它还展示了强大的推理能力,使其在视觉谜题等多模态推理挑战中特别有效。
