给公司做网站百度指数有哪些功能
一、引言:购物篮里的秘密
想象一下,你是一家超市的数据分析师,看着每天成千上万的购物小票,你是否好奇:顾客们买面包的时候,是不是也经常顺手带上牛奶?买啤酒的人,会不会也喜欢买尿布(经典的“啤酒与尿布”故事!)?
这些隐藏在购物篮里的“秘密”,就是关联规则。找出这些规则,超市就能更好地进行商品摆放、捆绑促销、精准推荐,最终提升销售额。而我们今天要聊的主角——FP-Growth算法,就是挖掘这些秘密的强大工具之一,而且它以高效著称!
在这篇文章里,我会用最通俗易懂的语言,带你一步步揭开FP-Growth的神秘面纱,让你不仅理解它的原理,还能动手用Python代码实践。准备好了吗?让我们开始这场数据挖掘之旅吧!
二、关联规则挖掘:我们在找什么?
简单来说,关联规则挖掘就是想找到数据集中项与项之间有趣的关联性。形式通常是 “如果 A 出现,那么 B 很可能也出现”,记作 A -> B。
-
项集 (Itemset): 一组一起出现的商品,比如 {牛奶, 面包}。
-
支持度 (Support): 一个项集在所有交易中出现的频率。比如 {牛奶, 面包} 在100个购物单里出现了10次,支持度就是 10/100 = 10%。我们通常会设定一个最小支持度 (Minimum Support) 阈值,只关心那些足够“频繁”的项集。
-
置信度 (Confidence): 买了A的顾客中,有多少比例也买了B。计算公式是 Support(A ∪ B) / Support(A)。比如,买了牛奶的人中有80%也买了面包,那么规则 {牛奶} -> {面包} 的置信度就是80%。我们也会设定最小置信度 (Minimum Confidence) 阈值。
我们的目标就是:找到那些同时满足最小支持度和最小置信度阈值的关联规则。
三、 老大哥Apriori的“烦恼”
在FP-Growth出现之前,Apriori算法是关联规则挖掘领域的“老大哥”。它的核心思想是“频繁项集的所有子集也必须是频繁的”。
Apriori的步骤大致是:
-
扫描数据库,找到所有频繁的单个商品(1项集)。
-
基于频繁1项集,生成候选的2项集。
-
扫描数据库,计算候选2项集的支持度,筛选出频繁2项集。
-
基于频繁2项集,生成候选的3项集...
-
重复这个过程,直到找不到更长的频繁项集。
详见当机器学习遇见购物车:手把手教你玩转Apriori关联分析
Apriori的痛点是什么?
-
多次扫描数据库: 生成k项集就需要扫描一次数据库,如果最长的频繁项集是10项集,那可能要扫描10次!数据量大时,这非常耗时。
-
产生大量候选集: 尤其是当商品种类很多时,生成的候选集数量可能爆炸式增长,计算和筛选这些候选集也需要大量时间和内存。
就像大海捞针,Apriori一遍又一遍地撒网(扫描数据库),捞起来一堆可能是针也可能是石头的“候选者”(候选集),再慢慢筛选。效率自然不会太高。
四、 FP-Growth闪亮登场:新思路解决老问题
FP-Growth(Frequent Pattern Growth)算法则另辟蹊径。它巧妙地避免了Apriori的两个主要痛点:
-
它只需要扫描数据库两次! (是的,你没看错,两次!)
-
它不产生候选集!
它是怎么做到的呢?FP-Growth的核心思想是:
-
压缩数据: 将整个交易数据库的信息压缩到一个叫做FP树 (FP-Tree) 的特殊树形结构中。这棵树保留了项集之间的关联信息。
-
分而治之: 基于FP树,递归地挖掘频繁项集。
想象一下,你不是一遍遍翻阅原始账本(数据库),而是先精心整理出一本“索引摘要”(FP树),然后在这本摘要上高效地查找信息。这就是FP-Growth的魅力所在!
五、核心利器:FP树 (FP-Tree) 是什么?
FP树是一种紧凑的数据结构,它存储了数据库中频繁项集的所有必要信息。它有以下特点:
-
树形结构: 有一个根节点(通常标为null),其余节点代表一个商品(项)。
-
路径代表交易: 从根节点到某个节点的路径,代表了一个交易(或交易的一部分)。
-
节点计数: 每个节点包含一个计数器,记录该节点代表的商品在经过该路径的交易中出现了多少次。
-
父子关系: 体现了商品在交易中的先后顺序(按频率排序后的顺序)。
-
项头表 (Header Table): 一个列表,包含了所有频繁的单个商品(按频率降序排列)。每个商品指向它在FP树中第一次出现的位置。
-
节点链接 (Node Links): FP树中相同商品名的节点会被链接起来(像串珠子一样),方便快速找到某个商品的所有出现位置。这个链接就从项头表开始。
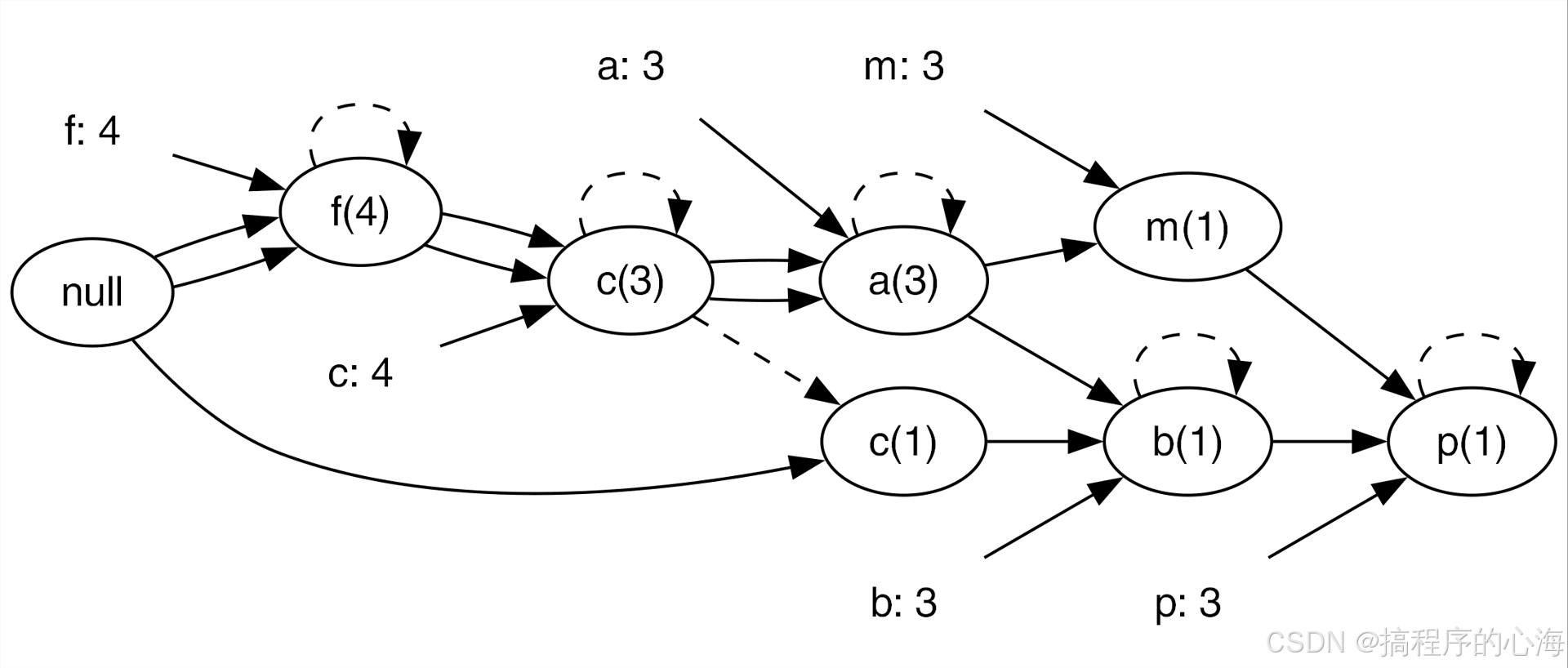
这个结构看起来有点复杂?别担心,我们马上通过一个手把手的例子来构建它!
六、手把手实战:构建FP树
- 数据预处理:统计商品支持度并排序
- 逐笔插入事务构建 FP-Tree
- 完善节点链(横向用虚线连接相同商品节点)
构建一颗FP树很简单,看下面动图演示

得到结果如下
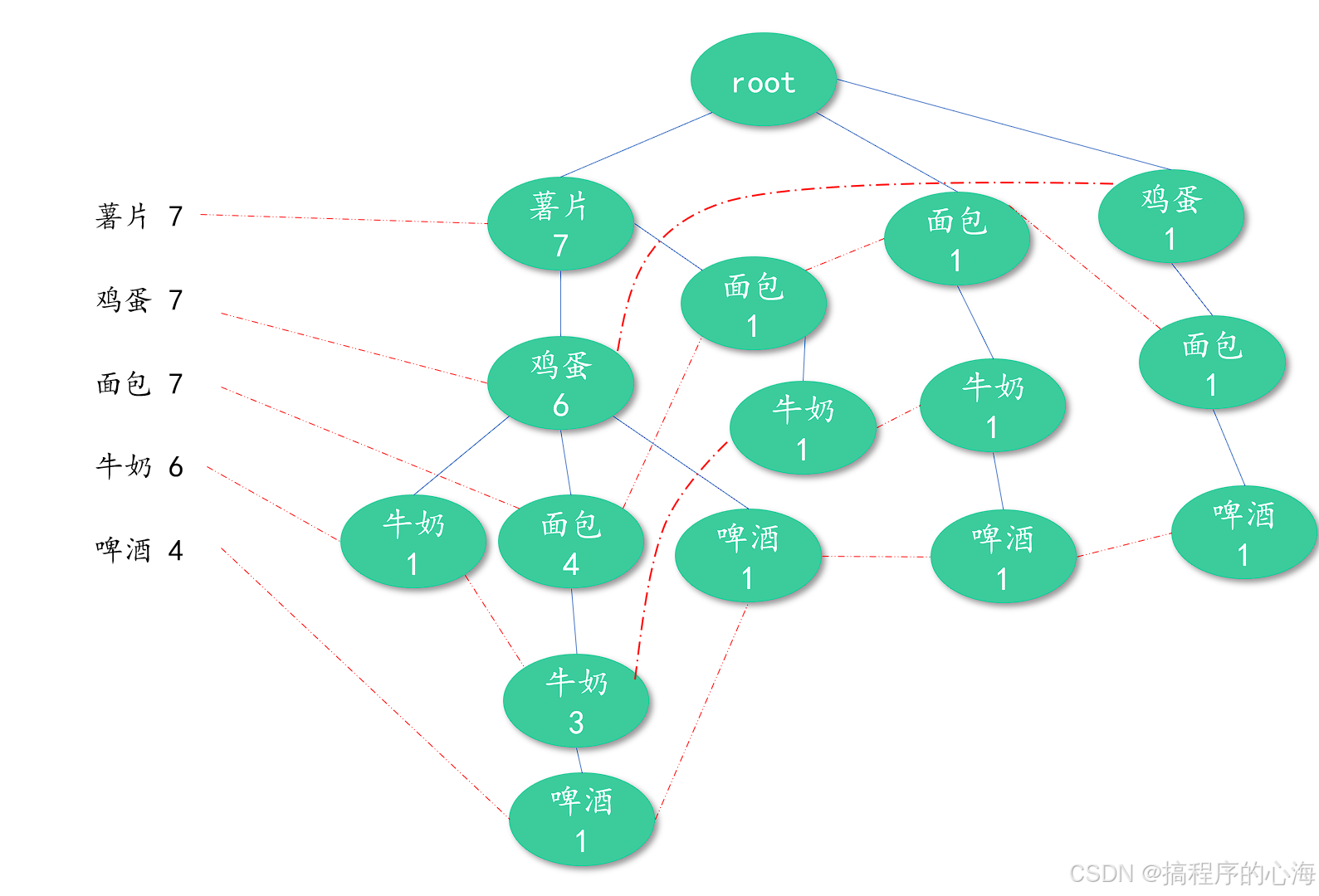
怎么样,这幅图应该是比较清晰的展示了我们的构建过程了,
我们在回头来看下面这张图,现在应该更加清晰的理解,为什么这张图是这样画的
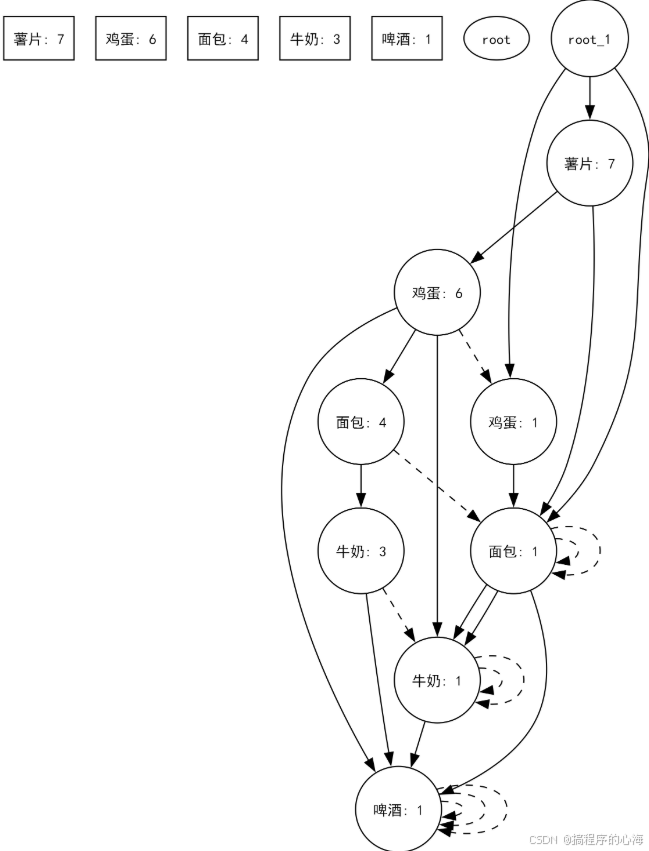
七、Python 代码实现与案例演示
下面的代码将实现一个简单的 FP-Growth 算法,包括 FP-Tree 的构建和频繁项集的挖掘。为了便于理解,代码中添加了详细注释。
import collections# 定义 FP-Tree 节点类
class FPTreeNode:def __init__(self, item, count, parent):self.item = item # 节点所代表的项self.count = count # 节点计数self.parent = parent # 父节点self.children = {} # 子节点字典:{项: 节点}self.node_link = None # 指向相同项的下一个节点def increment(self, count):self.count += count# 构建 FP-Tree
def build_fp_tree(transactions, min_support):# 第一步:统计各项频数freq = {}for trans in transactions:for item in trans:freq[item] = freq.get(item, 0) + 1# 过滤低频项freq = {item: count for item, count in freq.items() if count >= min_support}if len(freq) == 0:return None, None# 头指针表:存放每个项对应的第一个 FP-Tree 节点header_table = {item: [count, None] for item, count in freq.items()}# 创建根节点root = FPTreeNode(None, 1, None)# 按事务插入 FP-Treefor trans in transactions:# 筛选和排序local_items = {}for item in trans:if item in freq:local_items[item] = freq[item]if len(local_items) > 0:# 按频数降序排序(频数相同按字母排序)ordered_items = [item for item, _ in sorted(local_items.items(), key=lambda x: (-x[1], x[0]))]update_tree(ordered_items, root, header_table, 1)return root, header_tabledef update_tree(items, node, header_table, count):if len(items) == 0:returnfirst_item = items[0]# 如果子节点中已经有该项,则更新计数if first_item in node.children:node.children[first_item].increment(count)else:# 创建新的子节点new_node = FPTreeNode(first_item, count, node)node.children[first_item] = new_node# 更新头指针表:链接相同项的节点if header_table[first_item][1] is None:header_table[first_item][1] = new_nodeelse:update_header(header_table[first_item][1], new_node)# 递归处理剩余的项update_tree(items[1:], node.children[first_item], header_table, count)def update_header(node, target):# 链表最后一个节点插入新的节点while node.node_link is not None:node = node.node_linknode.node_link = target# 挖掘 FP-Tree 的频繁项集
def mine_tree(header_table, min_support, prefix, freq_item_list):# 按出现频数升序排序(从低频到高频)sorted_items = [item for item, _ in sorted(header_table.items(), key=lambda x: x[1][0])]for base_item in sorted_items:new_freq_set = prefix.copy()new_freq_set.add(base_item)freq_item_list.append((new_freq_set, header_table[base_item][0]))# 构造条件模式基conditional_patterns = {}node = header_table[base_item][1]while node is not None:path = []ascend_tree(node, path)if len(path) > 1:conditional_patterns[frozenset(path[1:])] = node.countnode = node.node_link# 构建条件 FP-Treeconditional_tree, conditional_header = build_fp_tree_from_conditional(conditional_patterns, min_support)if conditional_header is not None:mine_tree(conditional_header, min_support, new_freq_set, freq_item_list)def ascend_tree(node, path):if node.parent is not None:path.append(node.item)ascend_tree(node.parent, path)def build_fp_tree_from_conditional(conditional_patterns, min_support):# 将条件模式基转换为事务列表transactions = []for pattern, count in conditional_patterns.items():transaction = list(pattern)for _ in range(count):transactions.append(transaction)return build_fp_tree(transactions, min_support)# 测试案例
if __name__ == "__main__":# 示例数据集:每个事务为一个项的列表dataset = [['薯片', '鸡蛋', '面包', '牛奶'],['薯片', '鸡蛋', '啤酒'],['面包', '牛奶', '啤酒'],['薯片', '鸡蛋', '面包', '牛奶', '啤酒'],['薯片', '鸡蛋', '面包'],['鸡蛋', '面包', '啤酒'],['薯片', '面包', '牛奶'],['薯片', '鸡蛋', '面包', '牛奶'],['薯片', '鸡蛋', '牛奶']]min_support = 3 # 最小支持度阈值# 构建 FP-Treetree, header_table = build_fp_tree(dataset, min_support)if tree is None:print("没有满足最小支持度的频繁项。")else:# 挖掘频繁项集freq_item_list = []mine_tree(header_table, min_support, set(), freq_item_list)print("挖掘出的频繁项集及其支持度:")for itemset, support in freq_item_list:print(f"{set(itemset)}: {support}")
代码讲解
-
FP-Tree 节点类
FPTreeNode
每个节点保存当前项、计数、父节点、子节点以及指向下一个相同项节点的链接(用于头指针表)。 -
build_fp_tree函数-
首次扫描数据集统计各项频数,并过滤低频项。
-
根据频数对事务中的项进行排序,调用
update_tree插入树中。
-
-
update_tree函数
递归插入排序后的项,若节点存在则计数加1,否则创建新节点并更新头指针表。 -
频繁项集挖掘
mine_tree
根据头指针表,从每个频繁项出发构造条件模式基,并递归挖掘条件 FP-Tree。 -
测试案例
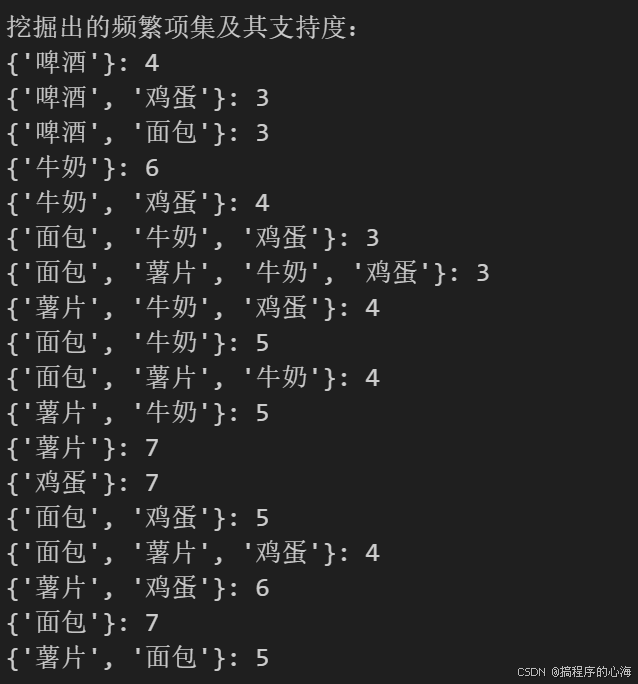
用一个简单的购物篮数据集进行测试,设置最小支持度为 3,最终输出满足条件的频繁项集及其支持度。
挖掘频繁项集
在构建好 FP-Tree 之后,算法对每个频繁项依次进行挖掘,主要步骤包括:
-
条件模式基构造:
对于一个频繁项,从头指针表中找到所有出现该项的节点,然后沿着路径向上遍历(不包括根节点),形成“条件模式基”。每条路径的计数即为该节点的计数。例如,“啤酒”出现在事务 2、3、4、6,因此其条件模式基就是每个含有“啤酒”节点对应的前缀路径。 -
递归构建条件 FP-Tree:
用条件模式基构建新的 FP-Tree,继续递归挖掘频繁项集。最终组合前缀和条件 FP-Tree中挖掘出的项集,就形成了最终的频繁项集及其支持度。
最终我们得到结果如下(代码输出结果)
总结
本文详细介绍了 FP-Growth 算法的原理、FP-Tree 的构建过程以及如何通过 Python 实现该算法。通过手把手的代码讲解与图文展示,相信大家对频繁项集挖掘有了更直观的认识和理解。在实际应用中,FP-Growth 算法因其高效性被广泛应用于大规模数据挖掘中。
如果你对算法原理或代码实现有任何疑问,欢迎在评论区留言交流!
如果这篇文章对你有所启发,期待你的点赞关注!