算命先生的网站怎么做wordpress 分类目录自定义
这篇论文提出了一种用于多视角多类别异常检测 (MVMCAD) 的模型,旨在解决现有模型在多视角场景下建模不同视角之间关系和互补信息不足的问题。该模型通过整合来自多个视角的信息来准确识别异常。
论文地址: Learning Multi-view Multi-class Anomaly Detection
该项目代码暂未开源
主要亮点
- 针对现有方法在多视角多类别异常检测中性能不佳的问题,该论文提出了一个名为MVMCAD的编码器-解码器框架。
- MVMCAD通过引入半冻结编码器处理跨视图数据不一致性,设计异常放大模块增强异常区域信号,并利用跨特征损失融合多层语义信息。
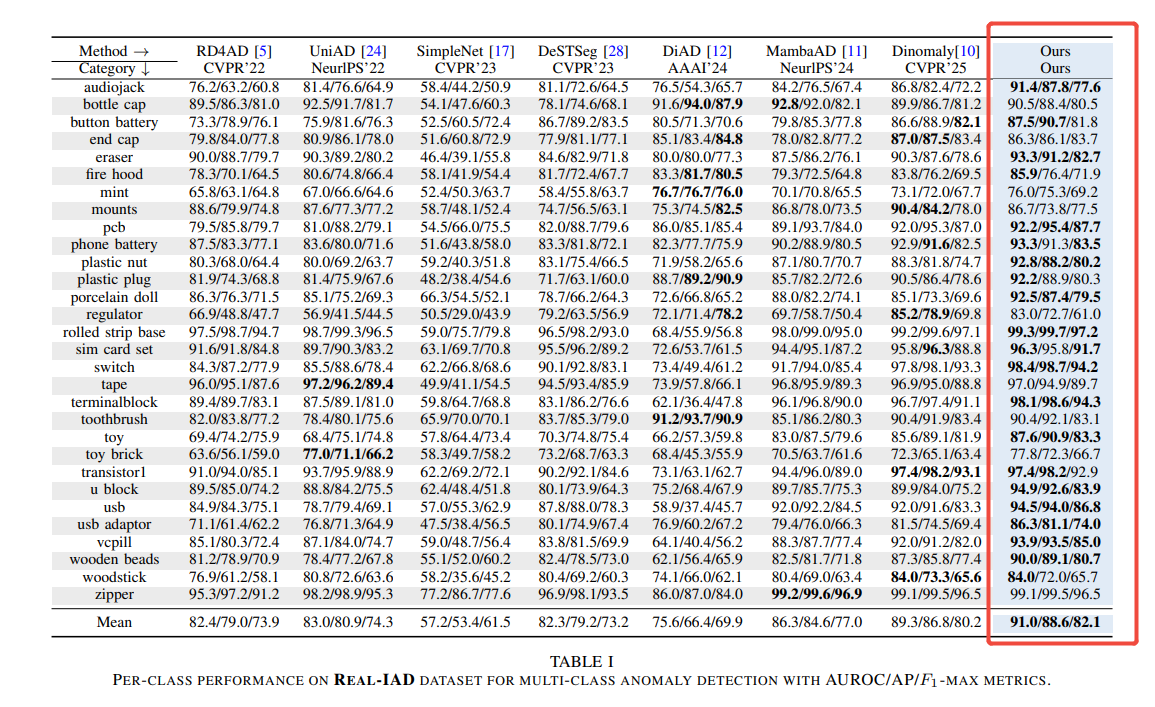
- 在Real-IAD数据集上的实验结果表明,所提出的MVMCAD模型在图像级别检测和像素级别定位任务上均取得了显著优于现有最先进方法的性能。
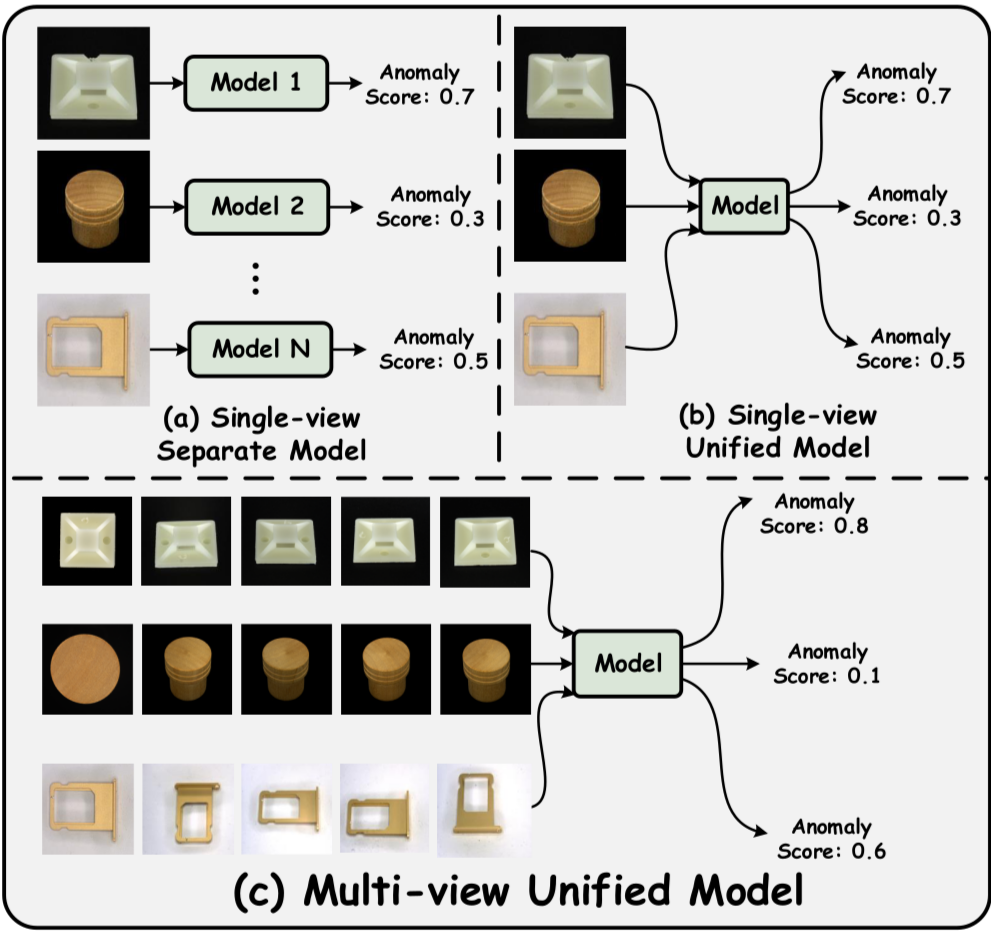
该论文提出了一种名为 MVMCAD(Multi-View Multi-Class Anomaly Detection)的模型,旨在解决现有 MCAD 模型在处理多视角数据时性能不佳的问题。现有 MCAD 方法通常难以有效建模不同视角之间的关系和互补信息,这导致它们在多视角场景下表现受限。MVMCAD 模型通过整合来自多个视角的信息,以准确识别异常。
!](https://i-blog.csdnimg.cn/direct/c492f16f795f477e8bb6a3a3f46b3be5.png)
该方法建立在一个 encoder-decoder 框架之上。核心方法包含三个关键组件:
Semi-Frozen Encoder (SFE)
为了应对视角数据的不一致性,SFE 结合了一个可训练的 pre-encoder prior enhancement mechanism 和一个 Frozen Backbone。该机制位于 Frozen Backbone 之前,允许模型在保持其原有视觉表示能力的同时,对多视角图像数据分布进行高效且稳定的适应。
给定输入图像 x 0 ∈ R B × C × H × W x_0 \in \mathbb{R}^{B \times C \times H \times W} x0∈RB×C×H×W。
首先通过 pre-encoder 机制微调部分层以增强对多视角图像的适应性。
对输入图像进行加权归一化:
X ~ c , h , w = BN ( X ) = γ c ⋅ X c , h , w − μ c σ c ( 1 ) \tilde{X}_{c,h,w} = \text{BN}(X) = \gamma_c \cdot \frac{X_{c,h,w} - \mu_c}{\sigma_c} \quad (1) X~c,h,w=BN(X)=γc⋅σcXc,h,w−μc(1)
其中 μ c \mu_c μc 和 σ c \sigma_c σc 是输入的均值和方差, γ c \gamma_c γc 是归一化缩放因子。
定义权重 α c \alpha_c αc:
α c = ∣ γ c ∣ ∑ k = 1 C ∣ γ k ∣ ( 2 ) \alpha_c = \frac{|\gamma_c|}{\sum_{k=1}^C |\gamma_k|} \quad (2) αc=∑k=1C∣γk∣∣γc∣(2)
加权结果:
X c h c , h , w = σ ( α c ) ⋅ X ~ c , h , w ⋅ X c , h , w ( 3 ) X_{chc,h,w} = \sigma(\alpha_c) \cdot \tilde{X}_{c,h,w} \cdot X_{c,h,w} \quad (3) Xchc,h,w=σ(αc)⋅X~c,h,w⋅Xc,h,w(3)
其中 σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是 sigmoid 激活函数。
计算特征图 X c h c , h , w X_{chc,h,w} Xchc,h,w 沿通道维度的均值以校准不同视角输入特征的变化并提高特征一致性:
β h , w = M h , w ∑ h ′ = 1 H ∑ w ′ = 1 W M h ′ , w ′ ( 4 ) \beta_{h,w} = \frac{M_{h,w}}{\sum_{h'=1}^H \sum_{w'=1}^W M_{h',w'}} \quad (4) βh,w=∑h′=1H∑w′=1WMh′,w′Mh,w(4)
其中 M h , w = 1 C ∑ c = 1 C X c h c , h , w M_{h,w} = \frac{1}{C} \sum_{c=1}^C X_{chc,h,w} Mh,w=C1∑c=1CXchc,h,w。
Prior 机制的最终输出:
X p r i o r c , h , w = σ ( β h , w ) ⋅ X c h c , h , w ⋅ X c h c , h , w ( 5 ) X_{priorc,h,w} = \sigma(\beta_{h,w}) \cdot X_{chc,h,w} \cdot X_{chc,h,w} \quad (5) Xpriorc,h,w=σ(βh,w)⋅Xchc,h,w⋅Xchc,h,w(5)
然后,处理后的特征被 Patch 化并送入 Frozen Encoder ε \varepsilon ε(使用 DINOv2-R 预训练的 ViT-Base/14):
f i = ε ( Patch ( X p r i o r c , h , w ) ) ( 6 ) f_i = \varepsilon(\text{Patch}(X_{priorc,h,w})) \quad (6) fi=ε(Patch(Xpriorc,h,w))(6)
其中 f i ∈ R B × N × D f_i \in \mathbb{R}^{B \times N \times D} fi∈RB×N×D。
Anomaly Amplification Module (AAM)
为了更好地强调异常区域的表示,AAM 模块捕捉全局 token 间的上下文关系,并通过计算归一化相似度并反向加权特征响应来抑制与正常区域高度相似的 token。它不仅有助于模型聚合图像不同部分的关联信息,还能在抑制主导性正常模式的同时放大语义上偏差或稀有的 token(通常对应异常)。
给定 f i ∈ R B × N × D f_i \in \mathbb{R}^{B \times N \times D} fi∈RB×N×D。
计算 Query, Key, Value 矩阵:
Q = f i W Q , K = f i W K , V = f i W V ( 7 ) Q = f_i W_Q, K = f_i W_K, V = f_i W_V \quad (7) Q=fiWQ,K=fiWK,V=fiWV(7)
其中 W Q , W K , W V ∈ R D × d k W_Q, W_K, W_V \in \mathbb{R}^{D \times d_k} WQ,WK,WV∈RD×dk 是线性映射权重, d k d_k dk 是 attention head 的维度。
计算 Value 的加权和:
F = W F ( Softmax ( Q K ⊤ d k ) V ) ( 8 ) F = W_F(\text{Softmax}(\frac{QK^\top}{\sqrt{d_k}}) V) \quad (8) F=WF(Softmax(dkQK⊤)V)(8)
其中 W F W_F WF 是线性映射权重。
沿 token 维度归一化特征 F F F:
F ^ = Normalize ( F , dim = N ) ( 9 ) \hat{F} = \text{Normalize}(F, \text{dim} = N) \quad (9) F^=Normalize(F,dim=N)(9)
计算 token 相似度得分:
Sim = ∑ j = 1 N ∥ F ^ j ∥ 2 ⋅ γ ( 10 ) \text{Sim} = \sum_{j=1}^N \| \hat{F}_j \|^2 \cdot \gamma \quad (10) Sim=j=1∑N∥F^j∥2⋅γ(10)
其中 γ ∈ R h × 1 \gamma \in \mathbb{R}^{h \times 1} γ∈Rh×1 是可学习的温度参数, h h h 是 attention head 的数量。
定义 Soft Attention 分布:
Π = Softmax ( Sim ) ∈ R B × h × N ( 11 ) \Pi = \text{Softmax}(\text{Sim}) \in \mathbb{R}^{B \times h \times N} \quad (11) Π=Softmax(Sim)∈RB×h×N(11)
计算基于抑制的 attention factor:
Att = 1 1 + ( Π ⊤ ⋅ F 2 ) ( 12 ) \text{Att} = \frac{1}{1 + (\Pi^\top \cdot F^2)} \quad (12) Att=1+(Π⊤⋅F2)1(12)
AAM 的最终输出 f m f_m fm:
f m = W o u t ( − ( F ⋅ Π ) ⋅ Att ) ( 13 ) f_m = W_{out}(-(F \cdot \Pi) \cdot \text{Att}) \quad (13) fm=Wout(−(F⋅Π)⋅Att)(13)
其中 W o u t W_{out} Wout 是线性映射权重, f m ∈ R B × N × D f_m \in \mathbb{R}^{B \times N \times D} fm∈RB×N×D。
Cross-Feature Loss (CFL)
为了捕捉在不同语义层次上表现的异常(一些表现为低级纹理偏差,另一些表现为高级结构不一致),CFL 被设计用于对齐浅层 encoder 特征与深层 decoder 特征,反之亦然。这使得 decoder 能够在浅层定位异常并在深层增强它们,从而提高模型准确和鲁棒的异常检测能力。
从 SFE 获得特征 { f e 1 , f e 2 } \{f_{e1}, f_{e2}\} {fe1,fe2},从 AAM 获得特征 f m = { f 1 , f 2 } f_m = \{f_1, f_2\} fm={f1,f2}。
损失对齐 f e 1 f_{e1} fe1 与 f 2 f_2 f2,以及 f e 2 f_{e2} fe2 与 f 1 f_1 f1。
定义相似度为 1 − cos ( z 1 , z 2 ) 1 - \text{cos}(z_1, z_2) 1−cos(z1,z2),其中 cos \text{cos} cos 是余弦相似度。
Score = 1 − cos ( z 1 , z 2 ) ( 14 ) \text{Score} = 1 - \text{cos}(z_1, z_2) \quad (14) Score=1−cos(z1,z2)(14)
选取相似度得分最高的前 10% 的索引集合 I I I:
I = { i ∣ Score i ≥ h } ( 15 ) I = \{i \mid \text{Score}_i \ge h\} \quad (15) I={i∣Scorei≥h}(15)
其中 h h h 是恰好排名在前 10% 的相似度得分。
Cross-Feature Loss 计算如下:
L c r o s s = 1 2 [ 1 ∣ I ∣ ∑ i ∈ I Score ( f e 1 , f 2 ) i + 1 ∣ I ∣ ∑ i ∈ I Score ( f e 2 , f 1 ) i ] ( 16 ) L_{cross} = \frac{1}{2} \left[ \frac{1}{|I|} \sum_{i \in I} \text{Score}(f_{e1}, f_2)_i + \frac{1}{|I|} \sum_{i \in I} \text{Score}(f_{e2}, f_1)_i \right] \quad (16) Lcross=21[∣I∣1i∈I∑Score(fe1,f2)i+∣I∣1i∈I∑Score(fe2,f1)i](16)
在训练阶段,decoder 学习重建从 encoder 提取的中间特征 f m f_m fm,通过最小化 CFL 来对齐深浅层表示。在推理阶段,decoder 能很好地重建正常区域但无法重建异常区域,从而暴露偏差。像素级别的重建误差用于生成异常热图并计算最终的异常得分 S S S。
实验结果
在 Real-IAD 数据集上进行的大量实验验证了该方法的有效性。在 image-level 异常检测方面,MVMCAD 取得了 91.0/88.6/82.1 的 AUROC/AP/F1-max 分数,超过了现有最佳方法 Dinomaly。在 pixel-level 异常定位方面,该方法取得了 99.1/43.9/48.2/95.2 的 AUROC/AP/F1-max/AUPRO 分数,同样优于现有 SOTA 方法。消融实验表明,SFE、AAM 和 CFL 各自对性能提升有贡献,三者结合 achieves best overall performance。可视化结果显示模型能够精确本地化不同类型对象的异常。该方法在单独类别训练设置下也表现出色,并在 pixel-level 异常定位方面显著优于 UniAD 和 MVAD。
论文最后指出,未来的工作将集中于提高基于 Transformer 的 encoder-decoder 框架的训练和推理效率,并开发自适应的异常放大策略,以平衡像素级精度和整体性能,解决 AAM 可能导致的像素级 AP 和 F1-max 略微下降的问题。
论文贡献总结
- 提出了一个编码器-解码器框架,用于训练统一模型以解决多视角异常检测问题。
- 提出了半冻结编码器、异常放大模块和跨特征损失,以实现稳定的跨视角表示学习,增强异常区域的显著性,并对齐特征层次结构之间的语义差异,从而改进多视角异常检测。
- 在 Real-IAD 数据集上的大量实验表明,所提出的方法优于SOTA。指标表明,该方法在图像级别检测和像素级别定位的异常识别任务中均表现良好。
