自己做的网站怎么才能在百度上查找站长统计幸福宝网站统计
前情回顾
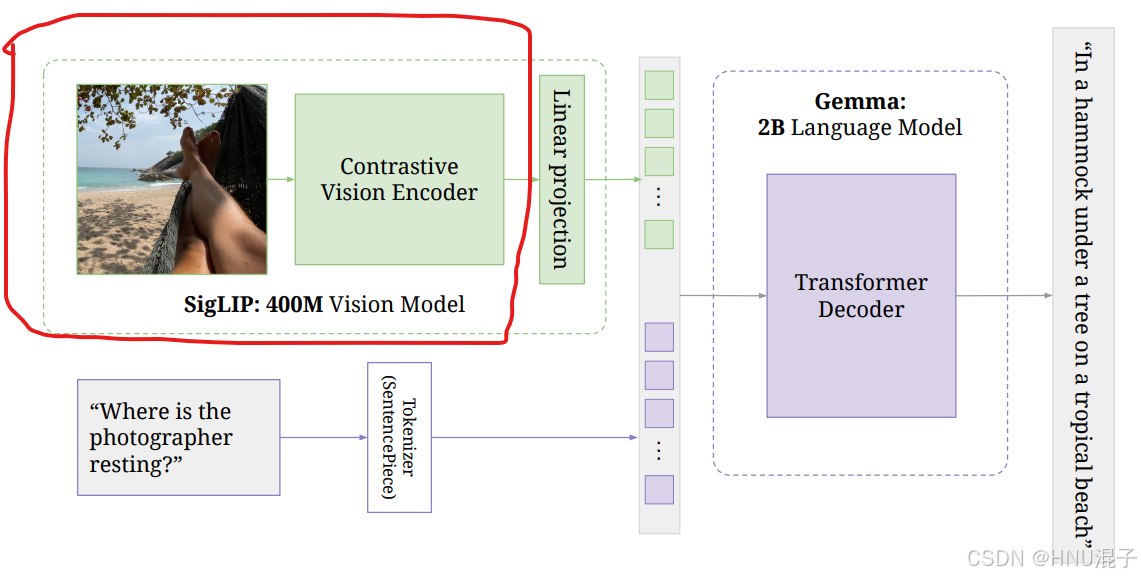
我们目前实现了视觉模型的编码器部分,然而,我们所做的是把一张图片编码嵌入成了许多个上下文相关的嵌入向量,然而我们期望的是一张图片用一个向量来表示,从而与文字的向量做点积形成相似度(参考手搓多模态-01 对比学习的优化)。所以我们需要加一个Linear Projection来将多个嵌入向量投影成一个嵌入向量,但这些可以之后再做,在数据准备阶段我们还有一些数据预处理的工作没有做,本文将着重描述如何进行数据预处理。
数据预处理
我们新建了一个文件,名叫paligemma_processer.py.

首先我们创建了一个类,名叫processer,在processer中我们将实现数据预处理的功能。
所做的预处理主要包括
- 图像的放缩和标准化
- 对输入的图像-文本对解析形成token向量
- 为图像的token创建占位符,这表示在Gemma模型的输入中,有一部分输入向量是来自视觉编码器,那这部分向量暂时就用一个临时的image_token来表示,方便后面替换
- 对于图像的输入,我们需要将输入转换为形如[Batch_size,Channels,Height,Width]的输入,并转换为torch.tensor类型方便pytorch处理。
这部分的代码主要如下:
class PaligemmaProcessor: IMAGE_TOKEN = "<image>"def __init__(
self,
tokenizer,
num_image_tokens,
image_size ):super().__init__()
self.image_seq_lenth = num_image_tokens
self.image_size = image_size token_to_add = {"addtional_special_tokens": [self.IMAGE_TOKEN]} ##标识图像占位符
tokenizer.add_special_tokens(token_to_add)
EXTRA_TOKENS = [f"<loc:{i:04d}>" for i in range(1024)] ##用于目标检测
EXTRA_TOKENS += [f"<seg:<{i:04d}>" for i in range(1024)] ##用于语义分割 tokenizer.add_tokens(EXTRA_TOKENS)
self.image_token_id = tokenizer.convert_tokens_to_ids(self.IMAGE_TOKEN) ##图像占位符的id tokenizer.add_bos_token = False ##去掉默认的bos和eos
tokenizer.add_eos_token = False self.tokenizer = tokenizerdef __call__(
self,
text: List[str],
images: List[Image.Image],
padding: str = "longest",
truncation: bool = True):assert len(text) == 1 and len(images) == 1, "Only support one text and one image for now." pixel_values = process_images(
images,
size=(self.image_size, self.image_size),
resample= Image.Resampling.BICUBIC,
rescale_factor=1.0 / 255.0,
image_mean = IMAGENET_STANDARD_MEAN,
image_std = IMAGENET_STANDARD_STD) pixel_values = np.stack(pixel_values,axis=0)
pixel_values = torch.tensor(pixel_values) ##转换为torch.tensor##通过add_image_token_to_prompt函数,将图像占位符添加到文本中,形成一个输入prompt
input_string = [
add_image_token_to_prompt(
prefix_prompt = prompt,
bos_token = self.tokenizer.bos_token,
image_seq_len = self.image_seq_lenth,
image_token = self.IMAGE_TOKEN)for prompt in text]## 将string类型的prompt转换为嵌入向量,其实这里是根据string中的词元划分成一个token_id的向量## 比如输入的string是"<image><image><bos>hello,world<sep>" 然后tokenizer将其分割成[<image>,<image>,<bos>,hell,oworld,<sep>],这里假设hell和oworld都是token,并查找每个token的id,可能得到[0,0,1,11,15,2]作为嵌入向量
inputs = self.tokenizer(
input_string,
padding=padding,
truncation=truncation,
return_tensors="pt")## 返回待编码的图像以及嵌入好的文本向量
return_data = {"pixel_values": pixel_values, **inputs}return return_data
首先我们为tokenizer 添加了一些额外的特殊token,比如用于目标检测的特殊位置token,以及语义分割用的特殊token,但是我们暂时不会用到它们。
图像处理
在数据预处理部分,我们首先通过一个预处理函数来处理图像,这里面就包括了图像的缩放,归一化和标准化。
pixel_values = process_images(
images,
size=(self.image_size, self.image_size),
resample= Image.Resampling.BICUBIC,
rescale_factor=1.0 / 255.0,
image_mean = IMAGENET_STANDARD_MEAN,
image_std = IMAGENET_STANDARD_STD)
该函数的实现如下:
def process_images(
images: List[Image.Image],
size: Tuple[int, int] = None,
resample: Image.Resampling = None,
rescale_factor: float = None,
image_mean: Optional[Union[float,List[float]]] = None,
image_std: Optional[Union[float,List[float]]] = None
) -> List[np.ndarray]:
height, width = size
images = [
resize(image =image, size = (height,width), resample=resample) if image.size != size else image for image in images]
images = [np.array(image) for image in images]
images = [
rescale(image = image, factor = rescale_factor) for image in images] ## 归一化缩放
images = [
normalize(image = image, mean = image_mean, std = image_std) for image in images] ## 标准化## image : [Height,Width,Channel] --> [Channel,Height,Width]
images = [image.transpose(2,0,1) for image in images]return images
首先我们需要对图像进行缩放,那么这里会涉及到一个重采样函数,表示你用什么方法对图像进行缩放采样,不同的方法采样出来的效果也不一样,这里我们用Image.Resampling.BICUBIC方法,关于这个方法的详细信息请参考其他博客。
缩放操作是在将0-255的像素值缩放到0-1,防止之后模型嵌入时的数值不稳定。
随后的标准化其实就像Batch Normalization和Layer Normalization一样,对图像的像素分布标准化为正态分布,所以需要大量图像的RGB通道各自的均值和方差,故使用image_net的统计结果。
然后把图像三个维度的顺序改变一下。
其中resize,rescale,normalize函数依次如下:
IMAGENET_STANDARD_MEAN = [0.485, 0.456, 0.406]
IMAGENET_STANDARD_STD = [0.229, 0.224, 0.225]def resize(
image: Image.Image,
size: Tuple[int, int],
resample: Image.Resampling = None,
reducing_gap: Optional[int] = None
):
height,width = size
image.resize(size=(width,height),resample=resample,reducing_gap=reducing_gap)return imagedef rescale(
image: np.ndarray,
factor: float,
dtype: np.dtype = np.float32
):
image = image * factor
image = image.astype(dtype)return imagedef normalize(
image: np.ndarray,
mean: Optional[Union[float,List[float]]] = None,
std: Optional[Union[float,List[float]]] = None
) -> np.ndarray:if mean is None:
mean = IMAGENET_STANDARD_MEANif std is None:
std = IMAGENET_STANDARD_STD
mean = np.array(mean)
std = np.array(std)
image = (image - mean) / stdreturn image
然后我们还需要将输出的图像信息转换为torch.tensor,这里的转换代码如下:
pixel_values = np.stack(pixel_values,axis=0)
pixel_values = torch.tensor(pixel_values) ##转换为torch.tensor
首先用stack方法把一个numpy tensor list转换为一个大tensor,然后再把numpy的tensor转换为torch的tensor.
token 处理
token的处理主要在这一部分
##通过add_image_token_to_prompt函数,将图像占位符添加到文本中,形成一个输入prompt
input_string = [add_image_token_to_prompt(
prefix_prompt = prompt,
bos_token = self.tokenizer.bos_token,
image_seq_len = self.image_seq_lenth,
image_token = self.IMAGE_TOKEN)for prompt in text]## 将string类型的prompt转换为嵌入向量,其实这里是根据string中的词元划分成一个token_id的向量## 比如输入的string是"<image><image><bos>hello,world<sep>" 然后tokenizer将其分割成[<image>,<image>,<bos>,hell,oworld,<sep>],这里假设hell和oworld都是token,并查找每个token的id,可能得到[0,0,1,11,15,2]作为嵌入向量
inputs = self.tokenizer(
input_string,
padding=padding,
truncation=truncation,
return_tensors="pt")## 返回待编码的图像以及嵌入好的文本向量
return_data = {"pixel_values": pixel_values, **inputs}
首先我们会构造输入的string文本,这个构造主要依照论文的内容:
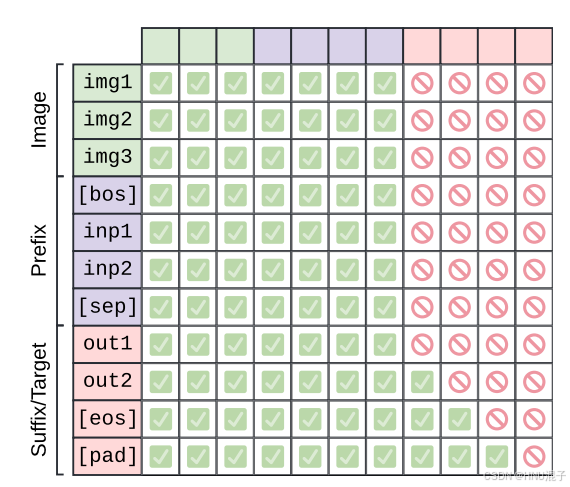
论文构造的输入首先是image token占位符,然后是一个bos表示文本信息的开始,然后是text input,然后是[sep],而论文用'\n'表示[sep]:

于是我们的add_image_token_to_prompt如下所示
def add_image_token_to_prompt(
prefix_prompt: str,
bos_token: str,
image_seq_len: int,
image_token: str
):##论文使用换行符当做[sep]token,但是可能会出现\n与前面的token重叠导致语义信息丢失。 return f"{image_token * image_seq_len}{bos_token}{prefix_prompt}\n"
但这里可能会出现一个问题,即论文使用换行符当做[sep]token,但是可能会出现\n与前面的token重叠导致语义信息丢失。但这里我们暂时不管这个问题。
随后tokenizer的调用实际上会把输入的string根据词汇表拆分成一个个token对应的id,而我们预选添加了image_token的占位符,也就是说我们构建的string_input可能类似于"<image><image><bos>hello,world<sep>",而tokenizer会根据词汇表划分这些token为一个list[<image>,<image>,<bos>,"hell,","oworld",<sep>],然后再通过查表的方式将这些token转换为数值id,比如查到我们加入的<image>对应的id是0,<bos>是1, <sep>是2,"hell,"是11,"oworld"是15,(注意,这里假设词汇表的"hell,"是一个token,"oworld"也是一个token)那么输出可能形如[0,0,1,11,15,2]。
## 将string类型的prompt转换为嵌入向量,其实这里是根据string中的词元划分成一个token_id的向量
## 比如输入的string是"<image><image><bos>hello,world<sep>" 然后tokenizer将其分割成[<image>,<image>,<bos>,hell,oworld,<sep>],这里假设hell和oworld都是token,并查找每个token的id,可能得到[0,0,1,11,15,2]作为嵌入向量
inputs = self.tokenizer(
input_string,
padding=padding,
truncation=truncation,
return_tensors="pt"
)
## 返回待编码的图像以及嵌入好的文本向量
return_data = {"pixel_values": pixel_values, **inputs}
return return_data