网站建设 风险防控电商创客网站建设方案
本章将介绍神经网络的学习中的一些重要观点,主题涉及寻找最优权重 参数的最优化方法、权重参数的初始值、超参数的设定方法等。
此外,为了 应对过拟合,本章还将介绍权值衰减、 Dropout 等正则化方法,并进行实现。
最后将对近年来众多研究中使用的 Batch Normalization 方法进行简单的介绍。
使用本章介绍的方法,可以高效地进行神经网络(深度学习)的学习,提高 识别精度。
6.1 参数的更新
神经网络的学习的目的是找到使损失函数的值尽可能小的参数。这是寻 找最优参数的问题,解决这个问题的过程称为 最优化(optimization)。遗憾的是, 神经网络的最优化问题非常难。这是因为参数空间非常复杂,无法轻易找到 最优解(无法使用那种通过解数学式一下子就求得最小值的方法)。而且,在 深度神经网络中,参数的数量非常庞大,导致最优化问题更加复杂。
在前几章中,为了找到最优参数,我们将参数的梯度(导数)作为了线索。 使用参数的梯度,沿梯度方向更新参数,并重复这个步骤多次,从而逐渐靠 近最优参数,这个过程称为 随机梯度下降法(stochastic gradient descent), 简称SGD 。 SGD是一个简单的方法,不过比起胡乱地搜索参数空间,也算是“聪明”的方法。但是,根据不同的问题,也存在比 SGD更加聪明的方法。本节我们将指出 SGD 的缺点,并介绍 SGD 以外的其他最优化方法。
6.1.1 探险家的故事
有一个性情古怪的探险家。他在广袤的干旱地带旅行,坚持寻找幽 深的山谷。他的目标是要到达最深的谷底(他称之为“至深之地”)。这 也是他旅行的目的。并且,他给自己制定了两个严格的“规定”:一个 是不看地图;另一个是把眼睛蒙上。因此,他并不知道最深的谷底在这 个广袤的大地的何处,而且什么也看不见。在这么严苛的条件下,这位 探险家如何前往“至深之地”呢?他要如何迈步,才能迅速找到“至深 之地”呢?
寻找最优参数时,我们所处的状况和这位探险家一样,是一个漆黑的世界。我们必须在没有地图、不能睁眼的情况下,在广袤、复杂的地形中寻找 “至深之地”。大家可以想象这是一个多么难的问题。
在这么困难的状况下,地面的坡度显得尤为重要。探险家虽然看不到周 围的情况,但是能够知道当前所在位置的坡度(通过脚底感受地面的倾斜状况)。 于是,朝着当前所在位置的坡度最大的方向前进,就是 SGD的策略。勇敢 的探险家心里可能想着只要重复这一策略,总有一天可以到达“至深之地”。
6.1.2 SGD
让大家感受了最优化问题的难度之后,我们再来复习一下 SGD。用数学式可以将 SGD 写成如下的式( 6 . 1 )。

这里把需要更新的权重参数记为W,把损失函数关于W的梯度记为 。
η表示学习率,实际上会取0.01或0.001这些事先决定好的值。式子中的←表示用右边的值更新左边的值。如式(6.1)所示,SGD是朝着梯度方向只前进一定距离的简单方法。现在,我们将SGD实现为一个Python类(为方便 后面使用,我们将其实现为一个名为SGD的类)。
class SGD:"""随机梯度下降法(Stochastic Gradient Descent)"""def __init__(self, lr=0.01):self.lr = lrdef update(self, params, grads):for key in params.keys():params[key] -= self.lr * grads[key] 这里,进行初始化时的参数 lr表示learning rate(学习率) 。这个学习率 会保存为实例变量。此外,代码段中还定义了 update(params, grads)方法 , 这个方法在 SGD 中会被反复调用。参数 params 和 grads(与之前的神经网络 的实现一样)是字典型变量,按 params['W1'] 、 grads['W1']的形式,分别保 存了权重参数和它们的梯度。
使用这个 SGD类,可以按如下方式进行神经网络的参数的更新(下面的代码是不能实际运行的伪代码)。

这里首次出现的变量名 optimizer表示“优化器”的意思 ,这里 由 SGD 承担这个角色。参数的更新由 optimizer负责完成。我们在这里需要 做的只是将参数和梯度的信息传给 optimizer。 像这样,通过单独实现进行最优化的类,功能的模块化变得更简单。
比如,后面我们马上会实现另一个最优化方法 Momentum,它同样会实现 成拥有 update(params, grads)这个共同方法的形式。这样一来,只需要将 optimizer = SGD() 这一语句换成 optimizer = Momentum() ,就可以从 SGD 切 换为 Momentum 。
很多深度学习框架都实现了各种最优化方法,并且提供了可以简单切换这些方法的构造。比如 Lasagne深度学习框架,在updates.py 这个文件中以函数的形式集中实现了最优化方法。用户可以从中选 择自己想用的最优化方法。
6.1.3 SGD的缺点
虽然 SGD简单,并且容易实现,但是在解决某些问题时可能 没有效率 。 这里,在指出 SGD的缺点之际,我们来思考一下求下面这个函数的最小值 的问题。
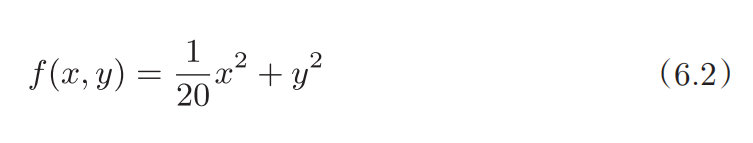
如图 6-1 所示,式( 6 . 2 )表示的函数是向 x轴方向延伸的“碗”状函数。 实际上,式( 6 . 2 )的等高线呈向 x 轴方向延伸的椭圆状。
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D# 生成数据
x = np.linspace(-50, 50, 200) # 扩大范围以更好展示形状
y = np.linspace(-50, 50, 200)
X, Y = np.meshgrid(x, y)
Z = (1/20) * X**2 + Y**2# 创建三维曲面图
fig = plt.figure(figsize=(14, 6))# 三维曲面子图
ax1 = fig.add_subplot(121, projection='3d')
surf = ax1.plot_surface(X, Y, Z, cmap='viridis', alpha=0.8, rstride=1, cstride=1)
ax1.set_xlabel('X')
ax1.set_ylabel('Y')
ax1.set_zlabel('Z')
ax1.set_title('3D Surface Plot')
ax1.view_init(elev=30, azim=45) # 调整视角# 添加颜色条
fig.colorbar(surf, ax=ax1, shrink=0.5, aspect=10)# 二维等高线子图
ax2 = fig.add_subplot(122)
contour = ax2.contour(X, Y, Z, levels=20, cmap='viridis')
ax2.clabel(contour, inline=True, fontsize=8) # 添加等高线标签
ax2.set_xlabel('X')
ax2.set_ylabel('Y')
ax2.set_title('Contour Plot')
fig.colorbar(contour, ax=ax2, shrink=0.5, aspect=10)plt.tight_layout()
plt.show()
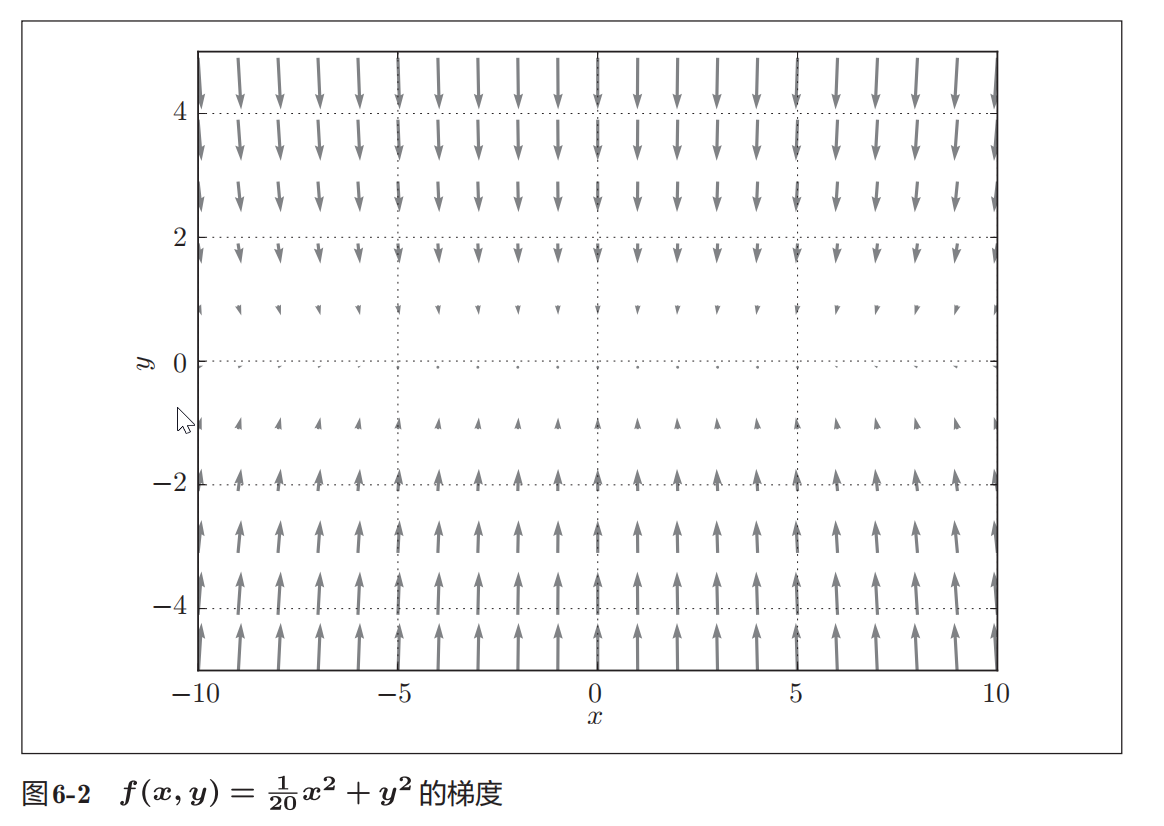
现在看一下式( 6 . 2)表示的函数的梯度。如果用图表示梯度的话,则如 图 6-2 所示。这个梯度的特征是, y 轴方向上大, x轴方向上小。换句话说, 就是 y 轴方向的坡度大,而 x轴方向的坡度小。这里需要注意的是,虽然式 ( 6 . 2 )的最小值在 ( x, y ) = (0 , 0) 处,但是图 6-2中的梯度在很多地方并没有指 向 (0 , 0) 。
import numpy as np
import matplotlib.pyplot as plt# 生成数据
x = np.linspace(-10, 10, 20) # 缩小范围以便清晰显示梯度
y = np.linspace(-10, 10, 20)
X, Y = np.meshgrid(x, y)# 计算函数值和梯度
Z = (1/20) * X**2 + Y**2
grad_x = X / 10 # ∂f/∂x = x/10
grad_y = 2 * Y # ∂f/∂y = 2y# 创建图形
plt.figure(figsize=(10, 6))# 绘制梯度场(箭头图)
plt.quiver(X, Y, grad_x, grad_y,scale=20, # 控制箭头长度scale_units='width',color='r', # 箭头颜色edgecolor='k', # 箭头边缘颜色linewidth=0.5)# 叠加等高线
contour = plt.contour(X, Y, Z, levels=10, colors='b', linestyles='dashed')
plt.clabel(contour, inline=True, fontsize=8) # 添加等高线标签# 图形设置
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Gradient Field of f(x,y) = (1/20)x² + y²')
plt.grid(True, linestyle='--', alpha=0.7)
plt.axis('equal') # 保持坐标轴比例一致plt.show()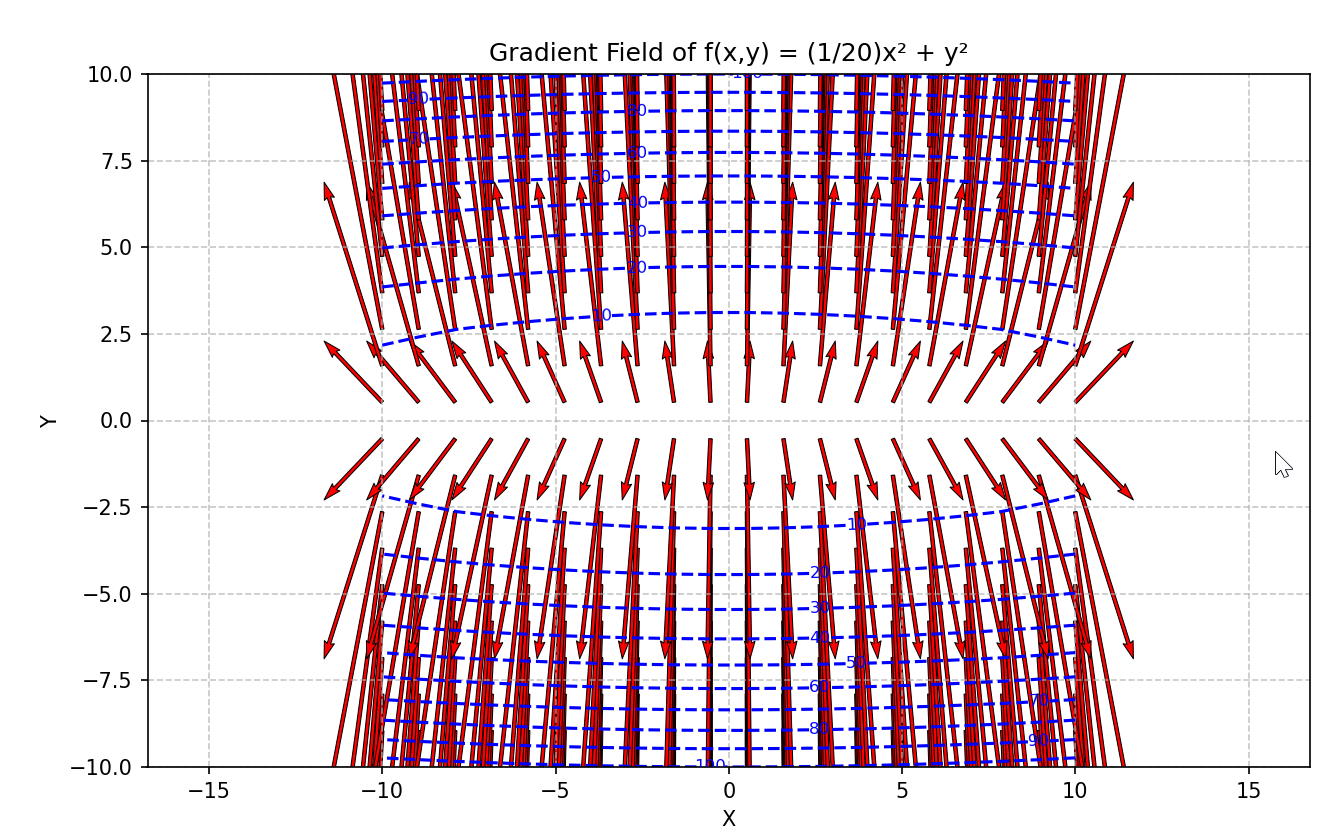
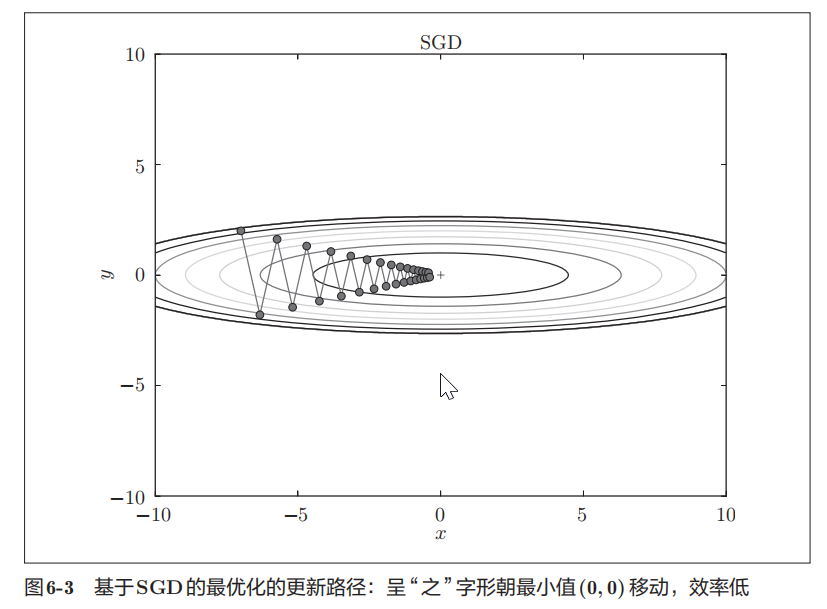
我们来尝试对图 6-1 这种形状的函数应用 SGD 。从 (x, y) = (−7.0, 2.0)处 (初始值)开始搜索,结果如图 6-3 所示。
在图 6-3 中, SGD呈“之”字形移动。这是一个相当低效的路径。也就是说, SGD 的缺点是,如果函数的形状非均向( anisotropic),比如呈延伸状,搜索 的路径就会非常低效。因此,我们需要比单纯朝梯度方向前进的 SGD更聪 明的方法。 SGD 低效的根本原因是,梯度的方向并没有指向最小值的方向。
# 导入数值计算库
import numpy as np
# 导入绘图库
import matplotlib.pyplot as plt
# 导入3D绘图工具包
from mpl_toolkits.mplot3d import Axes3D# 定义目标函数 Z = (1/20)X² + Y²
def f(x, y):return (x**2)/20 + y**2# 定义目标函数的梯度(导数)
def grad_f(x, y):# X方向的梯度分量:∂Z/∂X = X/10grad_x = x / 10# Y方向的梯度分量:∂Z/∂Y = 2Ygrad_y = 2 * yreturn np.array([grad_x, grad_y]) # 返回梯度向量# 初始化随机梯度下降参数
start_x, start_y = -7.0, 2.0 # 起始点坐标
learning_rate = 0.1 # 学习率(步长)
iterations = 100 # 最大迭代次数# 初始化存储路径的列表
x_vals, y_vals = [start_x], [start_y]
current_x, current_y = start_x, start_y # 当前位置初始化为起点# 执行随机梯度下降算法
for _ in range(iterations):grad = grad_f(current_x, current_y) # 计算当前点的梯度# 更新参数:向梯度反方向移动(学习率 × 梯度)current_x -= learning_rate * grad[0]current_y -= learning_rate * grad[1]# 记录新的位置到路径列表x_vals.append(current_x)y_vals.append(current_y)# 创建画布和子图布局
fig = plt.figure(figsize=(12, 5))# ==== 三维曲面图 ====
# 创建第一个子图(3D投影)
ax1 = fig.add_subplot(121, projection='3d')
# 生成网格数据用于绘制曲面
X = np.linspace(-8, 8, 100) # X轴范围-8到8,生成100个点
Y = np.linspace(-8, 8, 100) # Y轴范围同上
# 生成二维网格坐标矩阵
X, Y = np.meshgrid(X, Y)
# 计算对应的Z值
Z = (X**2)/20 + Y**2
# 绘制3D曲面,使用渐变色填充
ax1.plot_surface(X, Y, Z, cmap='viridis', alpha=0.7)
# 绘制优化路径:红色折线带圆点
ax1.plot(x_vals, y_vals,f(np.array(x_vals), np.array(y_vals)), # Z轴坐标根据函数计算color='red', marker='o', markersize=3, linewidth=1)
# 设置坐标轴标签
ax1.set_xlabel('X'), ax1.set_ylabel('Y'), ax1.set_zlabel('Z')
# 设置标题和标题位置
ax1.set_title('SGD Path on 3D Surface', y=0.9)# ==== 二维等高线图 ====
# 创建第二个子图(普通二维坐标)
ax2 = fig.add_subplot(122)
# 生成等高线数据:20条对数间隔的等高线
contour = ax2.contour(X, Y, Z,levels=np.logspace(-2, 3, 20), # 等高线层级范围cmap='viridis') # 颜色映射
# 添加等高线数值标签
ax2.clabel(contour, inline=True, fontsize=8)
# 绘制优化路径:红色带圆点折线
ax2.plot(x_vals, y_vals, 'r-o', label='SGD Path')
# 标记起点(蓝色实心圆)
ax2.scatter(start_x, start_y,color='blue', s=50,label='Start')
# 标记最小值点(绿色实心圆)
ax2.scatter(0, 0,color='green', s=50,label='Minimum')
# 设置坐标轴标签
ax2.set_xlabel('X'), ax2.set_ylabel('Y')
# 设置标题和网格
ax2.set_title('SGD Path on Contour Plot')
ax2.legend() # 显示图例
ax2.grid(True) # 显示网格线# 调整子图间距并显示图形
plt.tight_layout()
plt.show()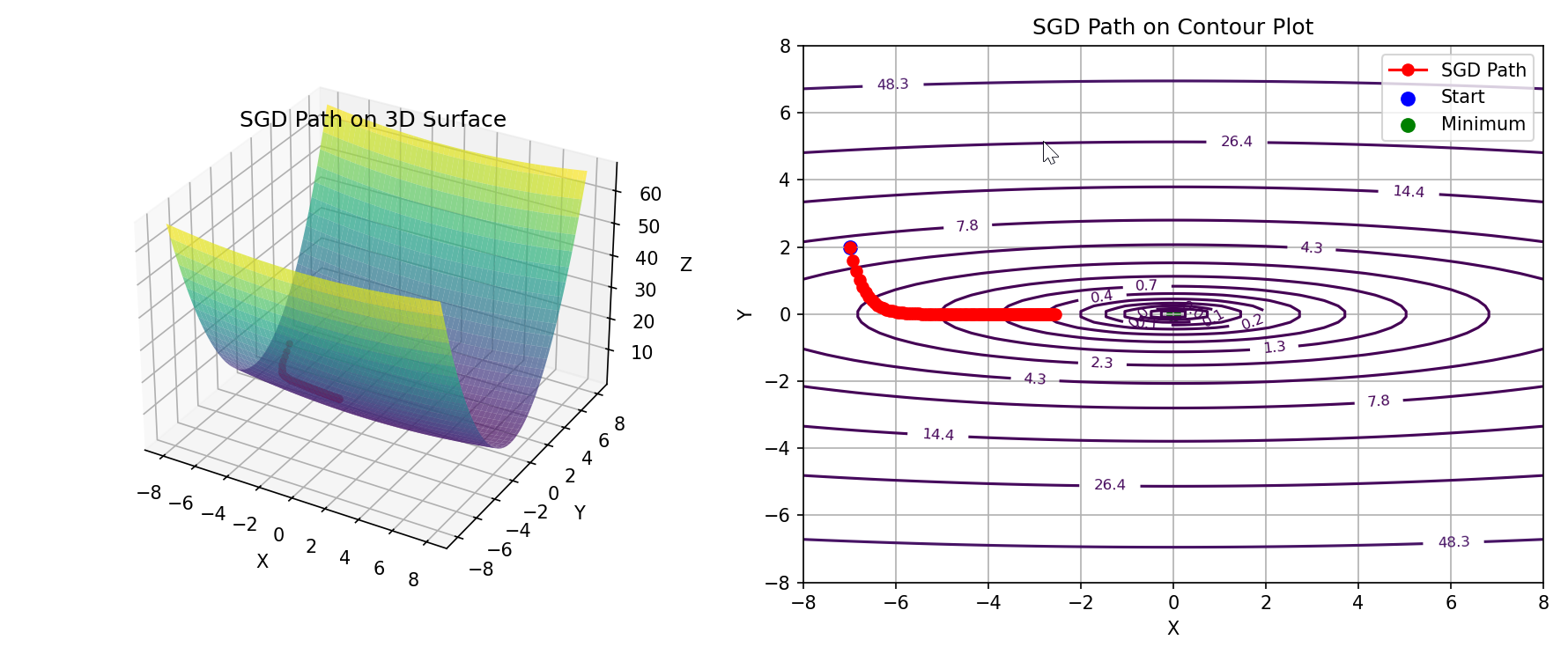
6.1.4 Momentum
Momentum是“动量”的意思,和物理有关。用数学式表示Momentum方法,如下所示。
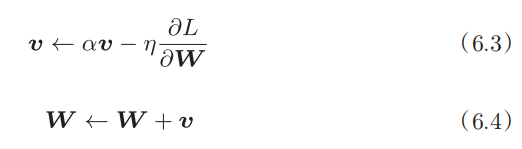
和前面的SGD一样,W表示要更新的权重参数, ∂L/∂W表示损失函数关于W的梯度,η表示学习率。这里新出现了一个变量v,对应物理上的速度。
式(6.3)表示了物体在梯度方向上受力,在这个力的作用下,物体的速度增加这一物理法则。如图6-4所示,Momentum方法给人的感觉就像是小球在地面上滚动。

实例变量v会保存物体的速度。初始化时,v中什么都不保存,但当第一次调用update()时,v会以字典型变量的形式保存与参数结构相同的数据。剩余的代码部分就是将式(6.3)、式(6.4)写出来,很简单。 现在尝试使用Momentum解决式(6.2)的最优化问题,如图6-5所示。
图6-5中,更新路径就像小球在碗中滚动一样。和SGD相比,我们发现“ 之”字形的“程度”减轻了。这是因为虽然x轴方向上受到的力非常小,但是一直在同一方向上受力,所以朝同一个方向会有一定的加速。反过来,虽然y轴方向上受到的力很大,但是因为交互地受到正方向和反方向的力,它们会互相抵消,所以y轴方向上的速度不稳定。因此,和SGD时的情形相比,可以更快地朝x轴方向靠近,减弱“之”字形的变动程度。
6.1.5 AdaGrad
在神经网络的学习中,学习率(数学式中记为η)的值很重要。学习率过小,会导致学习花费过多时间;反过来,学习率过大,则会导致学习发散而不能正确进行。
在关于学习率的有效技巧中,有一种被称为 学习率衰减(learning rate decay)的方法,即随着学习的进行,使学习率逐渐减小。实际上,一开始“多”学,然后逐渐“少”学的方法,在神经网络的学习中经常被使用。
逐渐减小学习率的想法,相当于将“全体”参数的学习率值一起降低。而AdaGrad 进一步发展了这个想法,针对“一个一个”的参数,赋予其“定制”的值。
AdaGrad会为参数的每个元素适当地调整学习率,与此同时进行学习(AdaGrad的Ada来自英文单词Adaptive,即“适当的”的意思)。下面,让我们用数学式表示AdaGrad的更新方法。
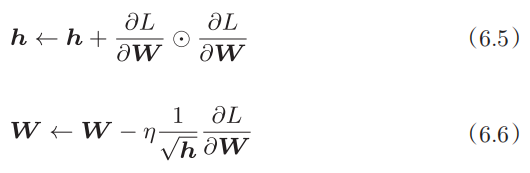
和前面的SGD一样,W表示要更新的权重参数,∂L/∂W 表示损失函数关于W的梯度,η表示学习率。这里新出现了 变量h,如式(6.5)所示,它保存了以前的所有梯度值的平方和(式(6.5)中的⨀表示对应矩阵元素的乘法)。然后,在更新参数时,通过乘以1/  ,就可以调整学习的尺度。这意味着,参数的元素中变动较大(被大幅更新)的元素的学习率将变小。也就是说,可以按参数的元素进行学习率衰减,使变动大的参数的学习率逐渐减小。
,就可以调整学习的尺度。这意味着,参数的元素中变动较大(被大幅更新)的元素的学习率将变小。也就是说,可以按参数的元素进行学习率衰减,使变动大的参数的学习率逐渐减小。
AdaGrad会记录过去所有梯度的平方和。因此,学习越深入,更新的幅度就越小。实际上,如果无止境地学习,更新量就会变为 0,完全不再更新。为了改善这个问题,可以使用 RMSProp方法。RMSProp方法并不是将过去所有的梯度一视同仁地相加,而是逐渐地遗忘过去的梯度,在做加法运算时将新梯度的信息更多地反映出来。这种操作从专业上讲,称为“ 指数移动平均”,呈指数函数式地减小过去的梯度的尺度。
现在来实现 AdaGrad。AdaGrad 的 实 现 过 程 如 下 所 示(源 代 码 在common/optimizer.py中)。

这里需要注意的是,最后一行加上了微小值 1e-7。这是为了防止当 self.h[key] 中有 0 时,将 0用作除数的情况。在很多深度学习的框架中,这 个微小值也可以设定为参数,但这里我们用的是 1e-7 这个固定值。
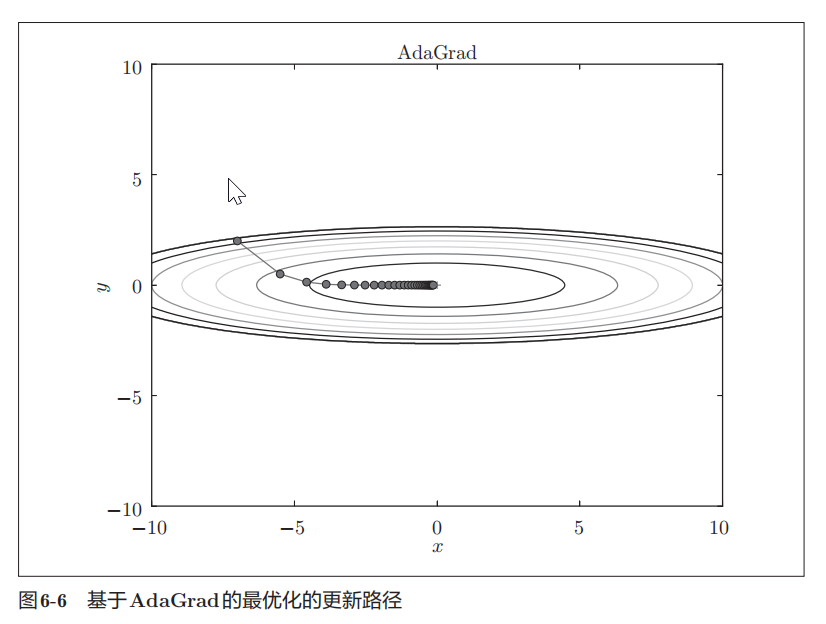
现在,让我们试着使用 AdaGrad 解决式( 6 . 2 )的最优化问题,结果如图6-6 所示。
6.1.6 Adam
Momentum参照小球在碗中滚动的物理规则进行移动,AdaGrad为参数的每个元素适当地调整更新步伐。如果将这两个方法融合在一起会怎么样呢?这就是Adam方法的基本思路 。
Adam是2015年提出的新方法。它的理论有些复杂,直观地讲,就是融合了Momentum和AdaGrad的方法。通过组合前面两个方法的优点,有望实现参数空间的高效搜索。
此外,进行超参数的“ 偏置校正”也是Adam的特征。这里不再进行过多的说明,详细内容请参考原作者的论文[8]。关于Python的实现,common/optimizer.py中将其实现为了Adam类,有兴趣的读者可以参考。现在,我们试着使用Adam解决式(6.2)的最优化问题,结果如图6-7所示。
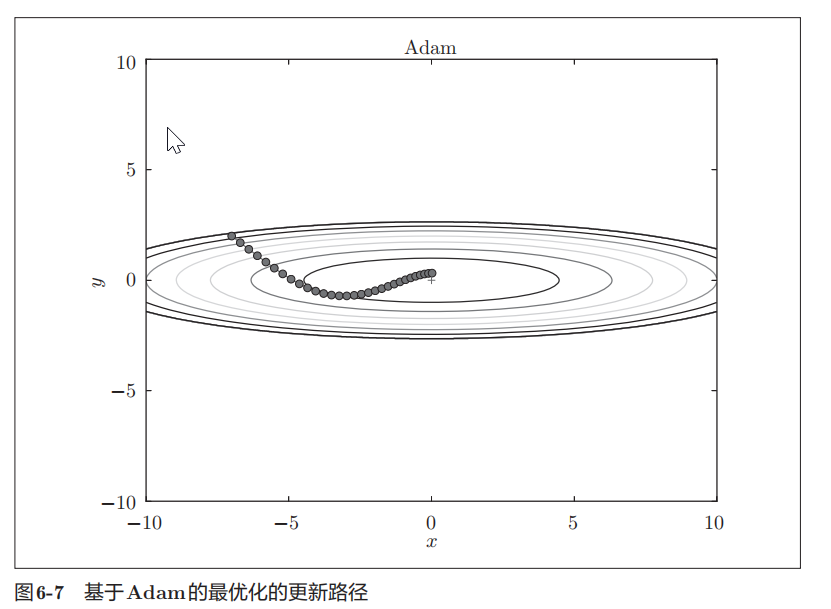
在图6-7中,基于Adam的更新过程就像小球在碗中滚动一样。虽然Momentun也有类似的移动,但是相比之下,Adam的小球左右摇晃的程度有所减轻。这得益于学习的更新程度被适当地调整了。
Adam会设置 3个超参数。一个是学习率(论文中以α出现),另外两个是一次momentum系数β1和二次momentum系数β2。根据论文,标准的设定值是β1为 0.9,β2 为 0.999。设置了这些值后,大多数情况下都能顺利运行。
6.1.7 使用哪种更新方法呢
到目前为止,我们已经学习了 4种更新参数的方法。这里我们来比较一 下这 4 种方法(源代码在 ch06/optimizer_compare_naive.py 中)。
如图 6-8所示,根据使用的方法不同,参数更新的路径也不同。只看这 个图的话, AdaGrad似乎是最好的,不过也要注意,结果会根据要解决的问 题而变。并且,很显然,超参数(学习率等)的设定值不同,结果也会发生变化。
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
from common.optimizer import *def f(x, y):return x**2 / 20.0 + y**2def df(x, y):return x / 10.0, 2.0*yinit_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=0.95)
optimizers["Momentum"] = Momentum(lr=0.1)
optimizers["AdaGrad"] = AdaGrad(lr=1.5)
optimizers["Adam"] = Adam(lr=0.3)idx = 1for key in optimizers:optimizer = optimizers[key]x_history = []y_history = []params['x'], params['y'] = init_pos[0], init_pos[1]for i in range(30):x_history.append(params['x'])y_history.append(params['y'])grads['x'], grads['y'] = df(params['x'], params['y'])optimizer.update(params, grads)x = np.arange(-10, 10, 0.01)y = np.arange(-5, 5, 0.01)X, Y = np.meshgrid(x, y) Z = f(X, Y)# for simple contour line mask = Z > 7Z[mask] = 0# plot plt.subplot(2, 2, idx)idx += 1plt.plot(x_history, y_history, 'o-', color="red")plt.contour(X, Y, Z)plt.ylim(-10, 10)plt.xlim(-10, 10)plt.plot(0, 0, '+')#colorbar()#spring()plt.title(key)plt.xlabel("x")plt.ylabel("y")plt.show()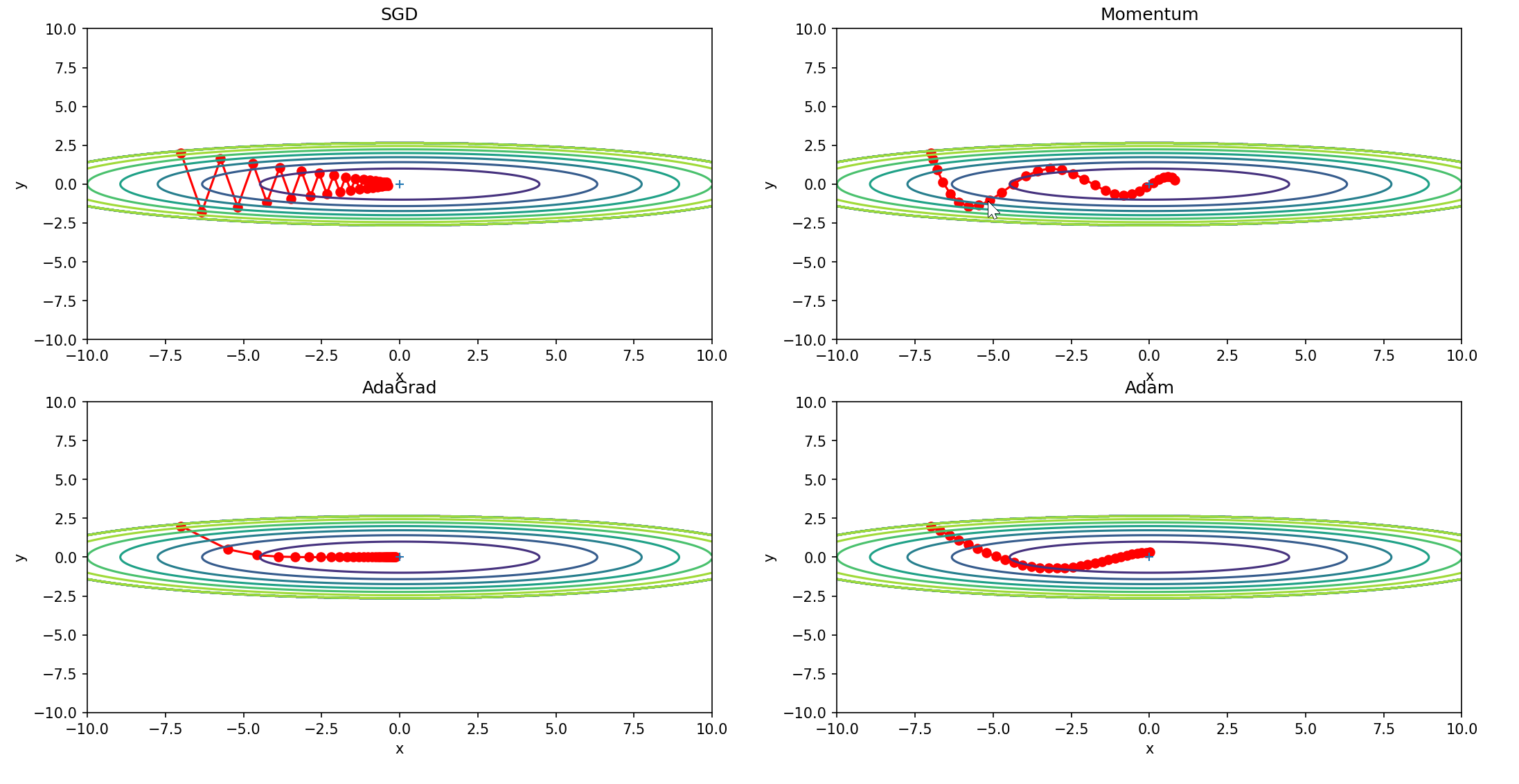
上面我们介绍了 SGD 、 Momentum 、 AdaGrad 、 Adam 这4种方法,那 么用哪种方法好呢?非常遗憾,(目前)并不存在能在所有问题中都表现良好 的方法。这 4种方法各有各的特点,都有各自擅长解决的问题和不擅长解决 的问题。
很多研究中至今仍在使用 SGD 。 Momentum 和 AdaGrad也是值得一试 的方法。最近,很多研究人员和技术人员都喜欢用 Adam。本书将主要使用 SGD 或者 Adam ,读者可以根据自己的喜好多多尝试。
6.1.8 基于MNIST数据集的更新方法的比较
我 们 以 手 写 数 字 识 别 为 例,比 较 前 面 介 绍 的 SGD 、 Momentum、 AdaGrad 、 Adam 这 4种方法,并确认不同的方法在学习进展上有多大程度 的差异。先来看一下结果,如图 6-9 所示(源代码在ch06/optimizer_compare_ mnist.py 中)。
# coding: utf-8
import os
import sys
sys.path.append(os.pardir) # 将父目录加入系统路径,用于导入自定义模块# 导入必要的第三方库
import matplotlib.pyplot as plt # 绘图库
import numpy as np # 数值计算库# 从自定义模块导入所需功能
from dataset.mnist import load_mnist # MNIST数据集加载函数(当前未使用)
from common.util import smooth_curve # 平滑曲线的工具函数
from common.multi_layer_net import MultiLayerNet # 多层神经网络类
from common.optimizer import * # 所有优化器类(SGD/Momentum/AdaGrad/Adam)# ======================
# 主程序开始
# ======================# 0: 加载MNIST数据集(改用TensorFlow Keras版本)
# 使用TensorFlow内置的MNIST数据集(无需手动下载)
(x_train, t_train), (x_test, t_test) = mnist.load_data()# 数据预处理
# 将图像数据展平为向量(28x28 -> 784),并归一化到[0,1]范围
x_train = x_train.reshape(-1, 784).astype(np.float32)/255.0
x_test = x_test.reshape(-1, 784).astype(np.float32)/255.0# 将标签转换为one-hot编码格式
t_train = np.eye(10)[t_train] # 创建10个类别的one-hot矩阵
t_test = np.eye(10)[t_test]# 数据集基本信息
train_size = x_train.shape[0] # 训练样本总数(60000)
batch_size = 128 # 每次训练使用的样本数
max_iterations = 2000 # 最大训练轮次# ======================
# 1. 实验配置初始化
# ======================# 初始化优化器字典(包含四种优化算法)
optimizers = {'SGD': SGD(), # 随机梯度下降法'Momentum': Momentum(),# 带动量的梯度下降'AdaGrad': AdaGrad(), # 自适应梯度算法'Adam': Adam() # 自适应矩估计算法
}# 初始化网络模型和损失记录器
networks = {} # 存储不同优化器对应的网络实例
train_loss = {} # 存储各优化器的训练损失历史for key in optimizers.keys():# 创建具有4层隐藏层(每层100节点)的全连接网络networks[key] = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100],output_size=10)# 为每个优化器创建独立的损失记录列表train_loss[key] = []# ======================
# 2. 训练过程
# ======================for i in range(max_iterations):# 随机采样一个mini-batchbatch_mask = np.random.choice(train_size, batch_size)x_batch = x_train[batch_mask] # 选取输入样本t_batch = t_train[batch_mask] # 选取对应标签# 对每个优化器进行独立训练for key in optimizers.keys():# 计算梯度(通过反向传播)grads = networks[key].gradient(x_batch, t_batch)# 更新网络参数optimizers[key].update(networks[key].params, grads)# 计算并记录当前批次的损失值loss = networks[key].loss(x_batch, t_batch)train_loss[key].append(loss)# 每100次迭代打印当前损失状态if i % 100 == 0:print("===========" + "iteration:" + str(i) + "===========")for key in optimizers.keys():# 获取当前优化器的最新损失值loss = networks[key].loss(x_batch, t_batch)print(f"{key}: {loss:.4f}") # 格式化输出损失值(保留4位小数)# ======================
# 3. 结果可视化
# ======================# 定义不同优化器的标记样式
markers = {"SGD": "o", # 圆圈标记"Momentum": "x", # 叉号标记"AdaGrad": "s", # 方块标记"Adam": "D" # 菱形标记
}# 生成x轴坐标数据
x = np.arange(max_iterations)# 绘制各优化器的损失曲线
for key in optimizers.keys():# 对原始损失值进行平滑处理smoothed_loss = smooth_curve(train_loss[key])# 绘制曲线并设置标记样式plt.plot(x, smoothed_loss, marker=markers[key], # 设置标记形状markevery=100, # 每隔100点显示标记label=key # 图例标签)# 设置图表属性
plt.xlabel("iterations") # x轴标题
plt.ylabel("loss") # y轴标题
plt.ylim(0, 1) # 设置y轴范围
plt.legend() # 显示图例
plt.title("Optimizer Comparison") # 图表标题
plt.show() # 显示图表===========iteration:1800===========
SGD:0.17020471001448634
Momentum:0.041975077112411635
AdaGrad:0.015143706148737824
Adam:0.011175943051347607
===========iteration:1900===========
SGD:0.2062572590920101
Momentum:0.05884984330174722
AdaGrad:0.03464677927561151
Adam:0.08108088815820025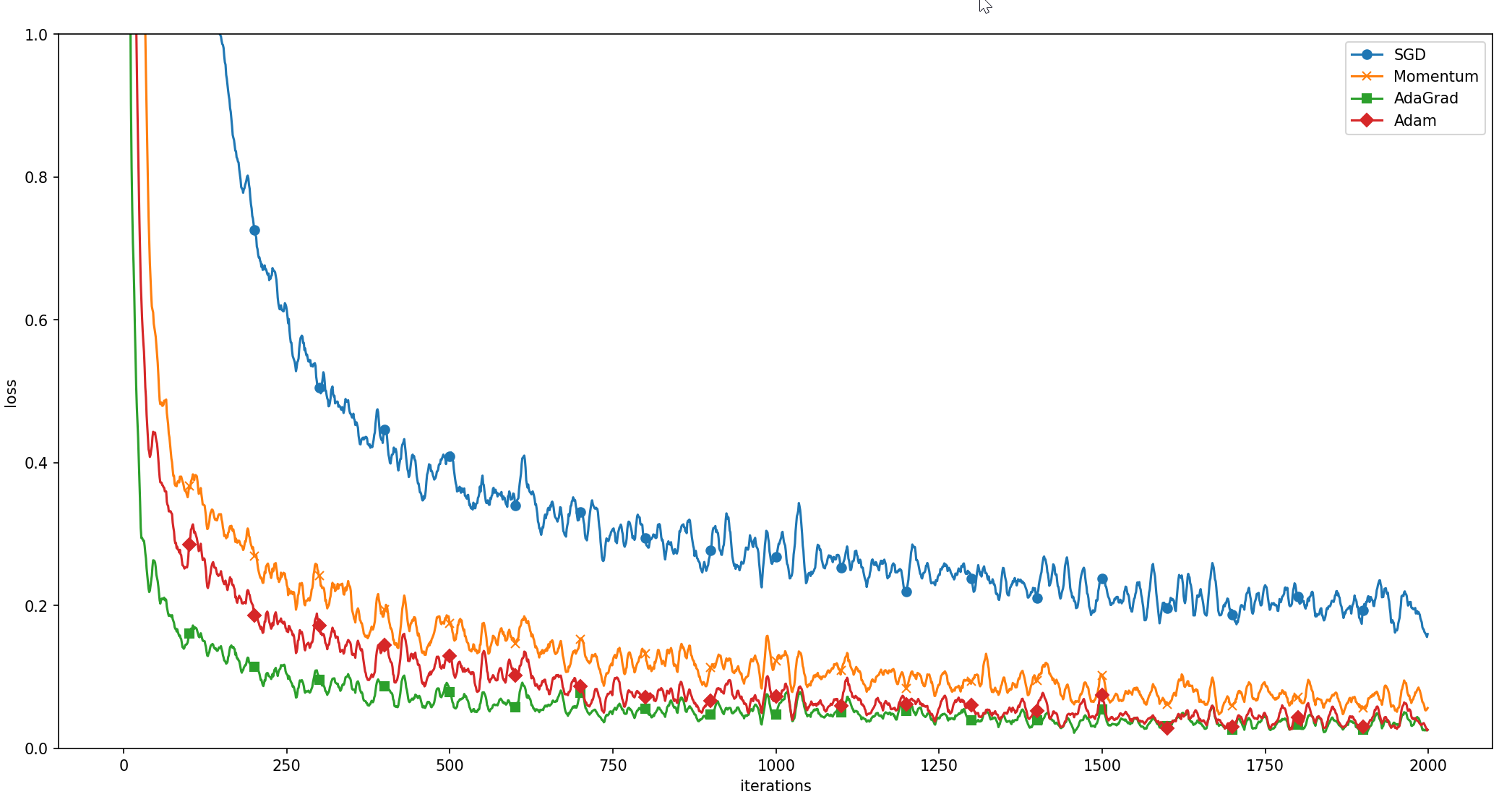
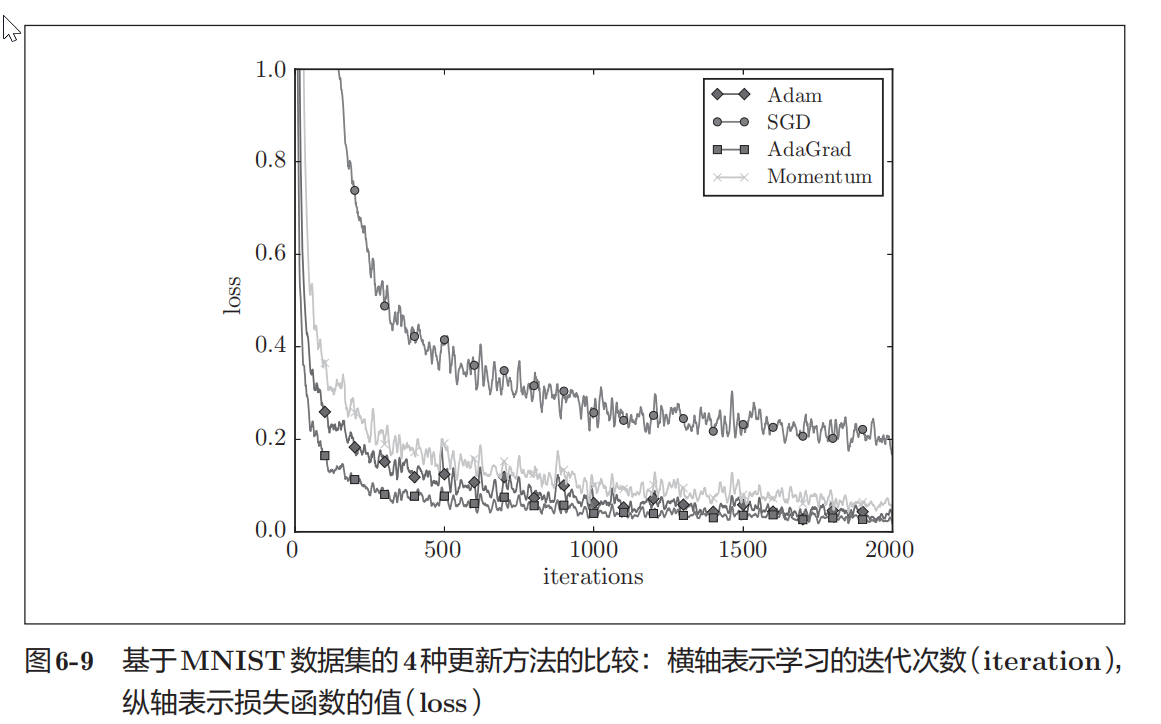
这个实验以一个 5 层神经网络为对象,其中每层有 100个神经元。激活 函数使用的是 ReLU 。
从图 6-9 的结果中可知,与 SGD 相比,其他 3种方法学习得更快,而且 速度基本相同,仔细看的话,AdaGrad的学习进行得稍微快一点。这个实验 需要注意的地方是,实验结果会随学习率等超参数、神经网络的结构(几层 深等)的不同而发生变化。不过,一般而言,与 SGD 相比,其他 3种方法可以学习得更快,有时最终的识别精度也更高。
6.2 权重的初始值
在神经网络的学习中,权重的初始值特别重要。实际上,设定什么样的 权重初始值,经常关系到神经网络的学习能否成功。本节将介绍权重初始值 的推荐值,并通过实验确认神经网络的学习是否会快速进行。
6.2.1 可以将权重初始值设为0吗
后面我们会介绍抑制过拟合、提高泛化能力的技巧—— 权值衰减(weight decay) 。简单地说, 权值衰减就是一种以减小权重参数的值为目的进行学习 的方法 。通过减小权重参数的值来抑制过拟合的发生。
如果想减小权重的值,一开始就将初始值设为较小的值才是正途。实际上, 在这之前的权重初始值都是像 0.01 * np.random.randn(10, 100)这样,使用 由高斯分布生成的值乘以 0 . 01 后得到的值(标准差为 0 . 01 的高斯分布)。
如果我们把权重初始值全部设为 0以减小权重的值,会怎么样呢?从结 论来说, 将权重初始值设为0不是一个好主意 。事实上,将权重初始值设为 0 的话,将无法正确进行学习。
为什么不能将权重初始值设为0呢?
严格地说,为什么不能将权重初始值设成一样的值呢?这是因为在误差反向传播法中,所有的权重值都会进行 相同的更新。比如,在 2 层神经网络中,假设第 1 层和第 2 层的权重为 0。这 样一来,正向传播时,因为输入层的权重为 0 ,所以第 2层的神经元全部会 被传递相同的值。第 2层的神经元中全部输入相同的值,这意味着反向传播 时第 2层的权重全部都会进行相同的更新(回忆一下“乘法节点的反向传播” 的内容)。因此,权重被更新为相同的值,并拥有了对称的值(重复的值)。 这使得神经网络拥有许多不同的权重的意义丧失了。为了防止“权重均一化” (严格地讲,是为了瓦解权重的对称结构), 必须随机生成初始值 。
6.2.2 隐藏层的激活值的分布
观察隐藏层的激活值 A (激活函数的输出数据)的分布,可以获得很多启 发。这里,我们来做一个简单的实验,观察权重初始值是如何影响隐藏层的 激活值的分布的。这里要做的实验是, 向一个5层神经网络(激活函数使用 sigmoid函数)传入随机生成的输入数据 ,用直方图绘制各层激活值的数据分 布。这个实验参考了斯坦福大学的课程 CS231n [5] 。
进行实验的源代码在 ch06/weight_init_activation_histogram.py中,下 面展示部分代码。
# coding: utf-8
import numpy as np
import matplotlib.pyplot as pltdef sigmoid(x):return 1 / (1 + np.exp(-x))def ReLU(x):return np.maximum(0, x)def tanh(x):return np.tanh(x)input_data = np.random.randn(1000, 100) # 1000个数据
node_num = 100 # 各隐藏层的节点(神经元)数
hidden_layer_size = 5 # 隐藏层有5层
activations = {} # 激活值的结果保存在这里x = input_datafor i in range(hidden_layer_size):if i != 0:x = activations[i-1]# 改变初始值进行实验!w = np.random.randn(node_num, node_num) * 1# w = np.random.randn(node_num, node_num) * 0.01# w = np.random.randn(node_num, node_num) * np.sqrt(1.0 / node_num)# w = np.random.randn(node_num, node_num) * np.sqrt(2.0 / node_num)a = np.dot(x, w)# 将激活函数的种类也改变,来进行实验!z = sigmoid(a)# z = ReLU(a)# z = tanh(a)activations[i] = z# 绘制直方图
for i, a in activations.items():plt.subplot(1, len(activations), i+1)plt.title(str(i+1) + "-layer")if i != 0: plt.yticks([], [])# plt.xlim(0.1, 1)# plt.ylim(0, 7000)plt.hist(a.flatten(), 30, range=(0,1))
plt.show()
这里假设神经网络有 5 层,每层有 100个神经元。然后,用高斯分布随 机生成 1000 个数据作为输入数据,并把它们传给 5层神经网络。激活函数使 用 sigmoid 函数,各层的激活值的结果保存在 activations变量中。这个代码 段中需要注意的是权重的尺度。虽然这次我们使用的是标准差为1的高斯分 布,但实验的目的是通过改变这个尺度(标准差),观察激活值的分布如何变 化。现在,我们将保存在 activations 中的各层数据画成直方图。
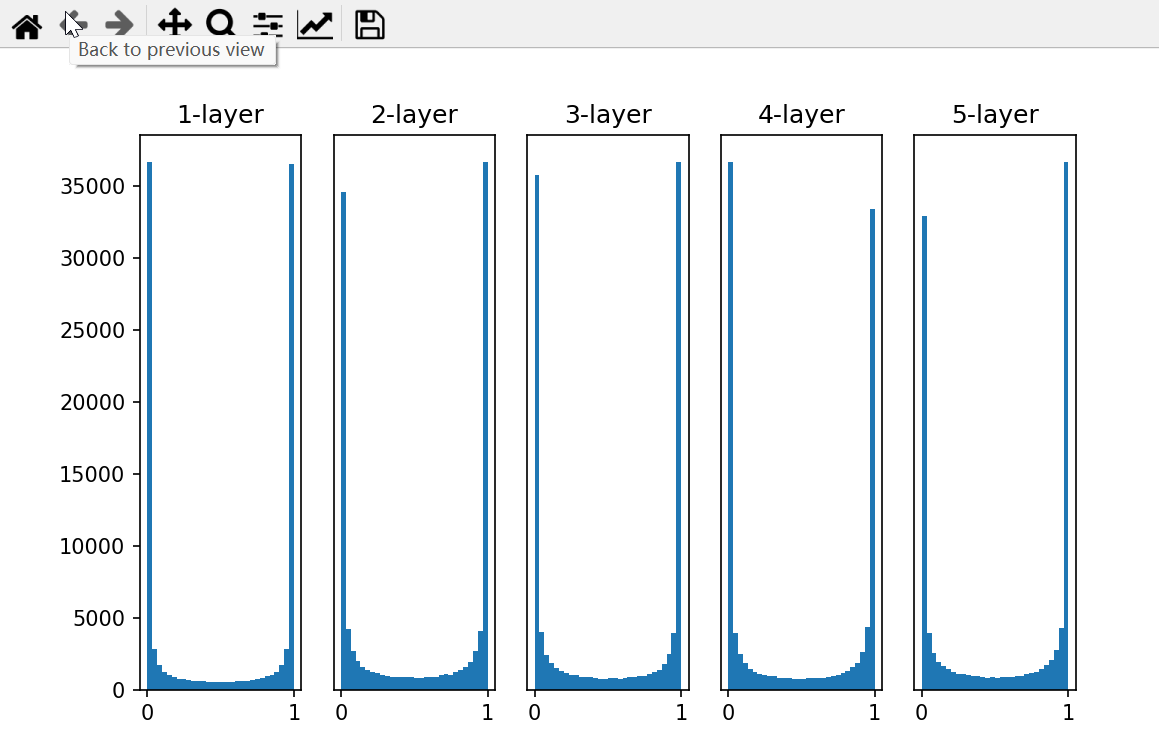
从图 6-10 可知,各层的激活值呈偏向 0 和 1 的分布。这里使用的sigmoid 函数是 S 型函数,随着输出不断地靠近 0 (或者靠近 1),它的导数的值逐渐接 近 0 。因此,偏向 0 和 1的数据分布会造成反向传播中梯度的值不断变小,最 后消失。这个问题称为 梯度消失 ( gradient vanishing)。层次加深的深度学习 中,梯度消失的问题可能会更加严重。
下面,将权重的标准差设为 0 . 01,进行相同的实验。实验的代码只需要 把设定权重初始值的地方换成下面的代码即可。
# w = np.random.randn(node_num, node_num) * 1
w = np.random.randn(node_num, node_num) * 0.01 来看一下结果。使用标准差为 0 . 01的高斯分布时,各层的激活值的分布如图 6-11 所示。
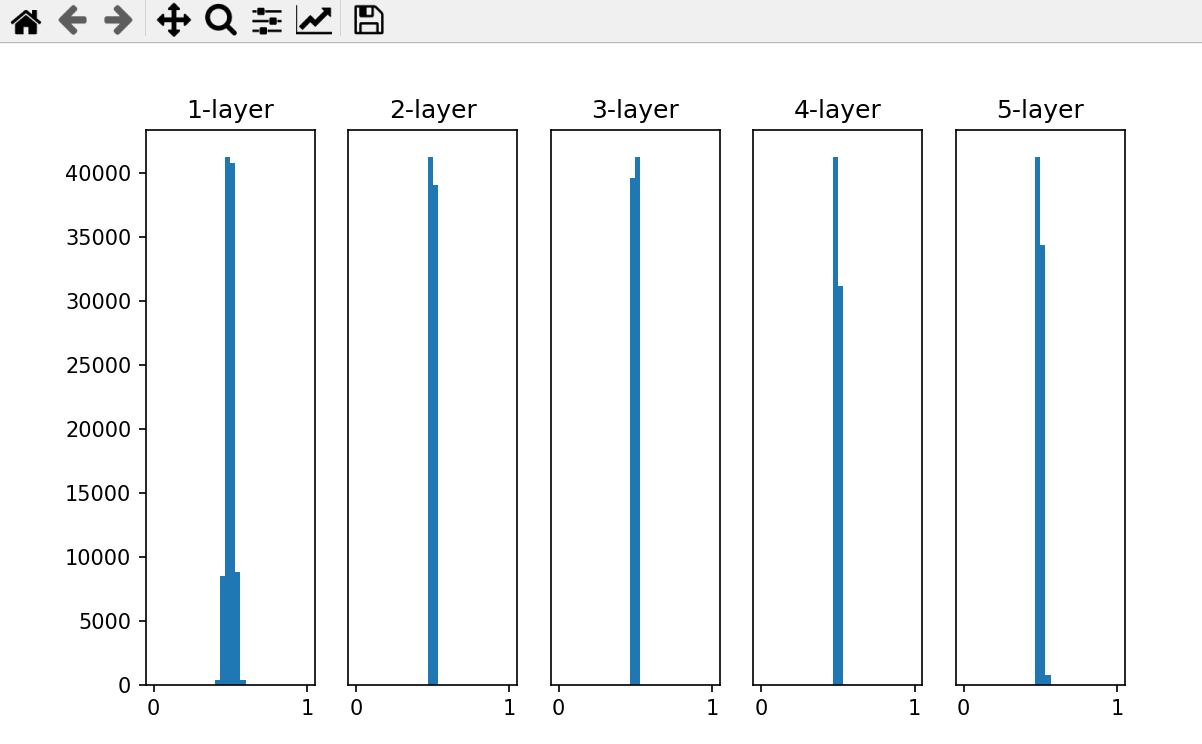
这次呈 集中在0.5附近 的分布。因为不像刚才的例子那样偏向 0和1,所 以不会发生梯度消失的问题。但是, 激活值的分布有所偏向,说明在表现力上会有很大问题 。
为什么这么说呢?
因为如果有多个神经元都输出几乎相同 的值,那它们就没有存在的意义了 。比如,如果 100个神经元都输出几乎相 同的值,那么也可以由 1个神经元来表达基本相同的事情。因此,激活值在 分布上有所偏向会出现“ 表现力受限 ”的问题。
各层的激活值的分布都要求有适当的广度。为什么呢?因为通过在各层间传递多样性的数据,神经网络可以进行高效的学习。反过来,如果传递的是有所偏向的数据,就会出现梯度消失或者“表现力受限”的问题,导致学习可能无法顺利进行。
接着,我们尝试使用 Xavier Glorot 等人的论文 [9]中推荐的 权重初始值(俗称“Xavier初始值 ”)。
现在, 在一般的深度学习框架中,Xavier初始值已被作为标准使用 。比如, Caffe 框架中,通过在设定权重初始值时赋予 xavier参数, 就可以使用 Xavier 初始值。
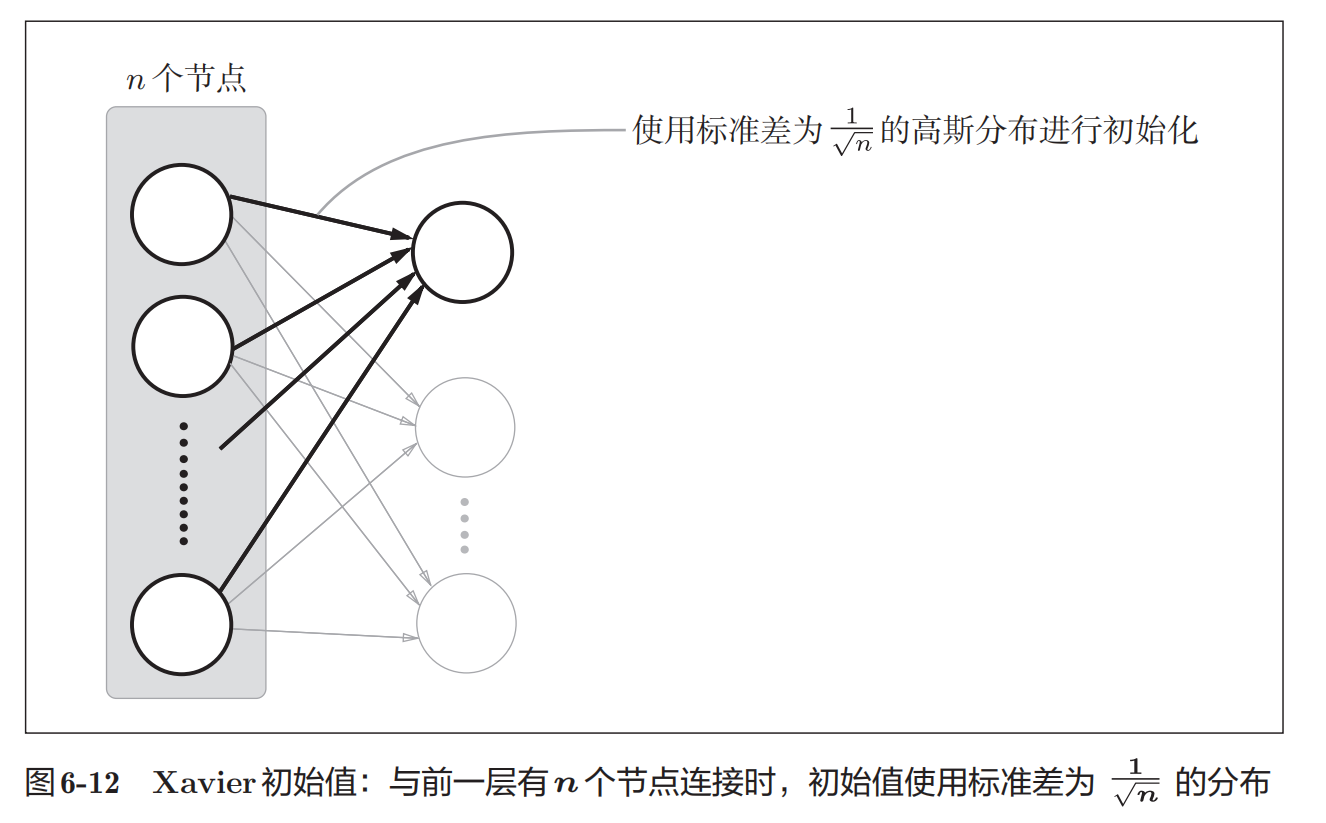
Xavier的论文中,为了使各层的激活值呈现出具有相同广度的分布,推 导了合适的权重尺度。推导的结论是,如果前一层的节点数为 n ,则初始 值使用标准差为 的分布 (图 6-12 )。
的分布 (图 6-12 )。