神农架网站制作低价建设手机网站
本文主要记录CLIP模型的原理,安装,基本使用。
1.CLIP模型原理
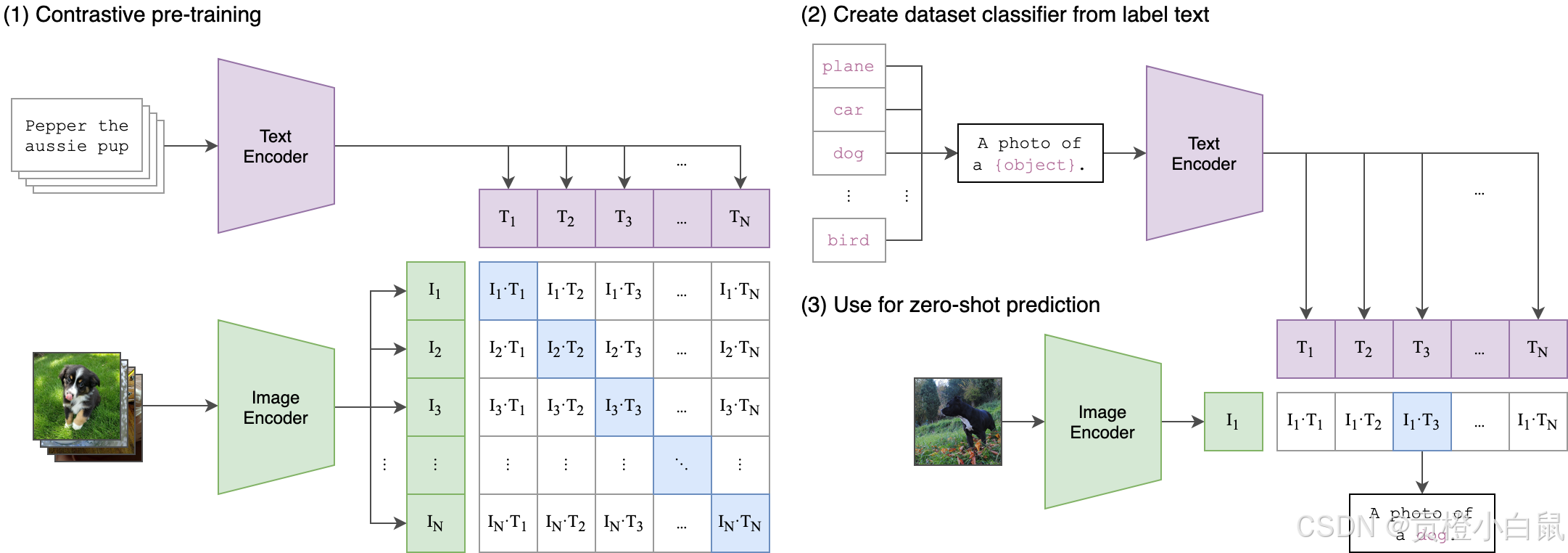
CLIP模型是文本图像匹配模型。使用4亿个图文对进行对比训练。
首先,每个batch的图文对分别进行图像编码和文本编码。
图像编码使用ViT,输出[batch_size,picture_feature]
文本编码使用Transformer,输出[batch_size,text_feature]
对比训练:在batch中计算所有图像与文本的余弦相似度,每个图文对的相似度最高,处在对角线上,其余相似度低。这样就可以进行训练得到CLIP模型。
2.CLIP安装
参考:安装文本-图像对比学习模型CLIP的方法
3.基本使用
3.1 单张图片分类
输入一张图片,设置几个类别,输出softmax概率分布。
def classify_image_with_clip():'''使用CLIP模型推理图像的文本描述可以调整的部分:1.选择文本描述,这里为"a diagram", "a dog", "a cat"2.加载CLIP模型,这里为ViT-B/323.选择输入图像,这里为CLIP.png'''device = "cuda" if torch.cuda.is_available() else "cpu" #选择GPU或CPUmodel, preprocess = clip.load("ViT-B/32", device=device) #加载视觉模型ViT-B/32image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device) #对输入图像进行预处理,增加一个batch维度并转移到GPU或CPUtext = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device) #选择文本描述,并转移到GPU或CPUwith torch.no_grad(): #关闭梯度计算logits_per_image, logits_per_text = model(image, text) #计算余弦相似度probs = logits_per_image.softmax(dim=-1).cpu().numpy() #softmax归一化后取出概率值print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]] #打印概率值3.2使用CLIP推理CIFAR100图像的类别
选择CIFAR100的任一张图,输出类别。
def classify_image_with_clip_cifar100():'''使用CLIP模型推理CIFAR100图像的文本描述可以调整的部分:1.选择某一张CIFAR100图像,这里为第3637张图像2.加载CLIP模型,这里为ViT-B/323.扩展CIFAR100的文本描述,这里为"a photo of a {class}"'''device = "cuda" if torch.cuda.is_available() else "cpu" #选择GPU或CPUmodel, preprocess = clip.load('ViT-B/32', device) #加载视觉模型ViT-B/32cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False) #下载CIFAR100数据集,该数据集包含100个类别的图像image, class_id = cifar100[3637] #选择第3637张图像及其类别image_input = preprocess(image).unsqueeze(0).to(device) #对输入图像进行预处理,增加一个batch维度并转移到GPU或CPUtext_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device) #扩展cifar100的文本描述with torch.no_grad(): #关闭梯度计算image_features = model.encode_image(image_input) #计算图像特征text_features = model.encode_text(text_inputs) #计算文本特征image_features /= image_features.norm(dim=-1, keepdim=True) #归一化图像特征text_features /= text_features.norm(dim=-1, keepdim=True) #归一化文本特征similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) #计算余弦相似度values, indices = similarity[0].topk(5) #取出前5个最相似的文本描述#打印预测结果print("\nTop predictions:\n")for value, index in zip(values, indices):print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")3.3使用CLIP训练Logistic回归模型,分类CIFAR100
使用CLIP训练CIFAR100分类器
def train_classifier_with_clip_cifar100():'''使用CLIP模型训练CIFAR100图像分类器可以调整的部分:1.选择训练集和测试集的比例,这里为8:22.选择逻辑回归分类器,这里为LogisticRegression3.设置分类器超参数,这里为C=0.316, max_iter=10004.加载模型,这里为ViT-B/32'''device = "cuda" if torch.cuda.is_available() else "cpu" #选择GPU或CPUmodel, preprocess = clip.load('ViT-B/32', device) #加载视觉模型ViT-B/32root = os.path.expanduser("~/.cache") #下载CIFAR100数据集的路径train = CIFAR100(root, download=True, train=True, transform=preprocess) #下载训练集test = CIFAR100(root, download=True, train=False, transform=preprocess) #下载测试集def get_features(dataset):'''使用batch计算数据集的特征例:dataset有10000张图像1.划分为100个batch2.每个batch计算100张图像的特征3.将本batch的特征和标签添加合并到一个数组4.将100个batch的特征合并后返回'''all_features = [] #特征列表all_labels = [] #标签列表with torch.no_grad(): #关闭梯度计算for images, labels in tqdm(DataLoader(dataset, batch_size=100)): #加载数据集,batchsize设置为100,并显示进度条features = model.encode_image(images.to(device)) #计算图像特征all_features.append(features) #将特征添加到列表all_labels.append(labels) #将标签添加到列表return torch.cat(all_features).cpu().numpy(), torch.cat(all_labels).cpu().numpy() #将特征和标签合并成一个数组并转移到CPUtrain_features, train_labels = get_features(train) #计算训练集的特征test_features, test_labels = get_features(test) #计算测试集的特征classifier = LogisticRegression(random_state=0, C=0.316, max_iter=1000, verbose=1) #设置逻辑回归分类器# 使用训练集训练分类器# 输入train_features:[num_samples, feature_dim], train_labels:[num_samples]# y = sigmoid(train_features * x + b) [num_samples, num_classes]# 使用y和train_labels计算损失函数# 优化器更新参数classifier.fit(train_features, train_labels) #使用训练集训练分类器predictions = classifier.predict(test_features) #使用测试集预测标签accuracy = np.mean((test_labels == predictions).astype(float)) * 100. #计算准确率print(f"Accuracy = {accuracy:.3f}") #打印准确率