关键词是什么百度关键词优化是什么意思
1.字符集介绍
我们从最开始美国人那边开始,首先他们的字符本身就比较简单(字母、数字、其他特殊字符),所以就是使用ASCII字符集进行表示(一个字节表示也就是8位)
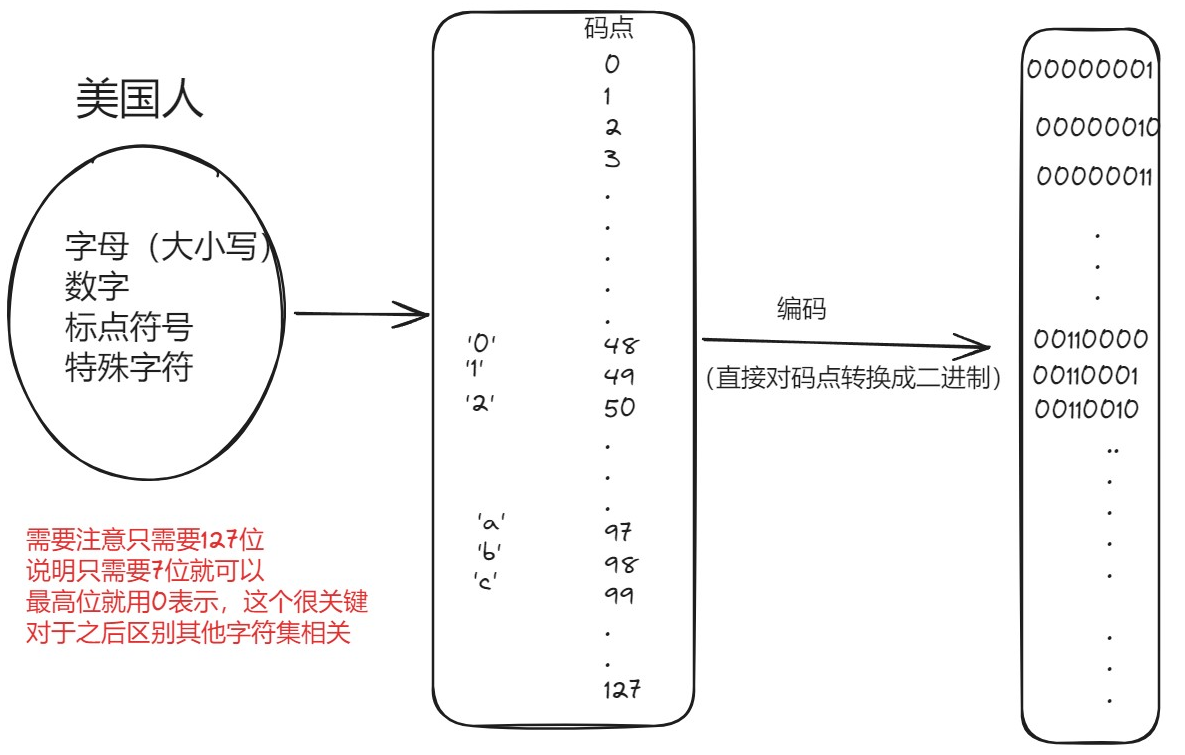
(GBK编码)但是对于中国这种文字较多的来说两万多个字,需要两个字节(16位),同样的道理来说其实15位就已经足够了,因此最高位用1表示,那么如果混合了怎么区别呢?
但是每个国家都有自己的语言怎么办呢,都需要有自己的字符集吗 ,那中国转韩国就会出现乱码的情况!因此国际就出现了万国码Unicode字符集UTF-32编码(用四个字节表示):
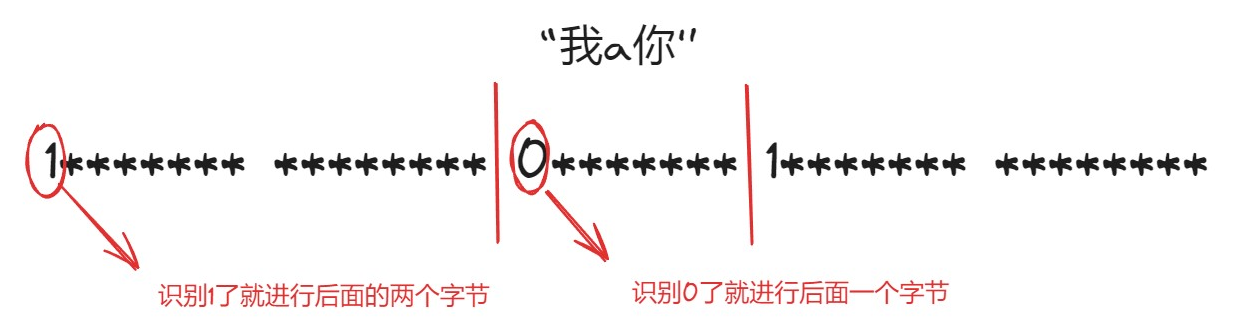
但出现一个问题就是,对于ASCII字符集只需要一个字节那不是前面全补0白白浪费内存资源吗?GDK也是白白浪费资源!因此Unicode字符集的一种编码方案就出现了:UTF-8(采取可变长编码方案)分为了四个长度区:1,2,3,4字节【英文字符、数字只占一个字节,汉字字符占用3个字节】
那么详细介绍一下怎么进行编码的:(按照这个框架进行就可以进行识别)
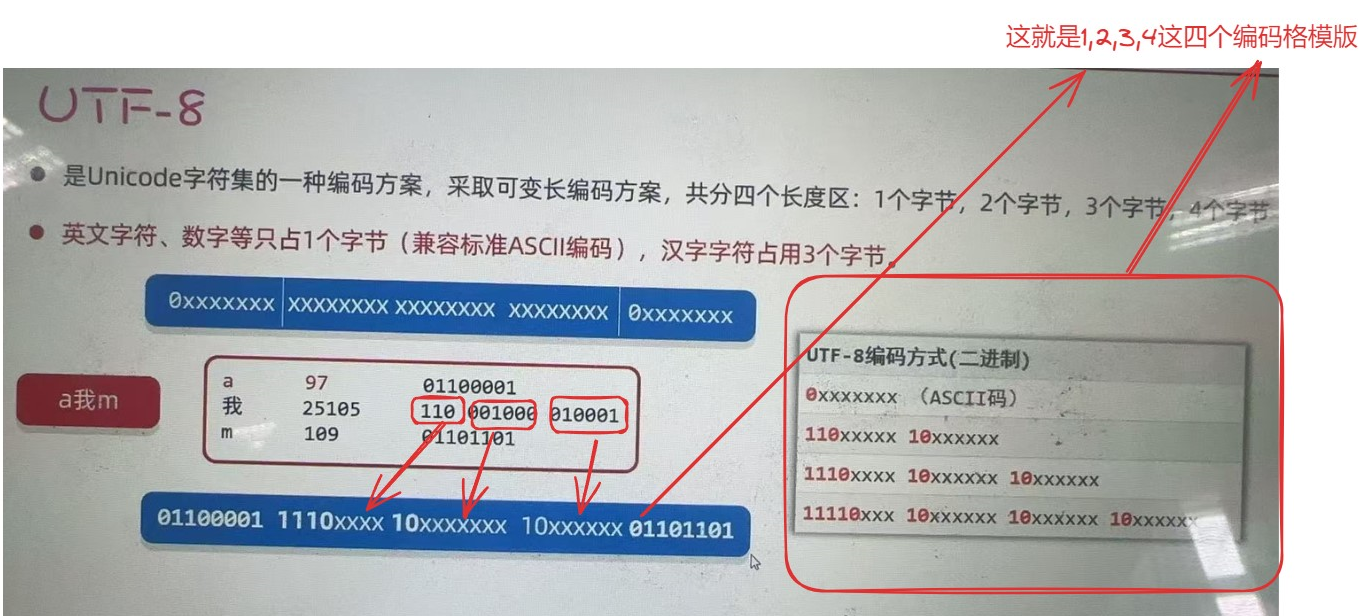
注意!!!
1.根据上面内容可以知道,你用什么进行编码就必须用什么进行解码,不然就会出现乱码
2.英文和数字一般不会出现乱码,因为很多字符集都兼容了ASCII编码(换句话说因为他比较少,一个字节就搞定了,所以不管任何编码都只需要一个字节就可以了)
补充一下:1kb = 1024b,就是1024个字节
2.在Java中字符集编码解码的操作
编码:字符转化成字节
解码:字节转化成字符

程序如下:
package FileDemo;import java.io.UnsupportedEncodingException;
import java.util.Arrays;public class Test04 {public static void main(String[] args) throws UnsupportedEncodingException {//编码String name = "a我b";byte[] bytes = name.getBytes();//默认就是我的平台UTF-8System.out.println(Arrays.toString(bytes));//指定编码byte[] bytes1 = name.getBytes("GBK");System.out.println(Arrays.toString(bytes1));//解码String s = new java.lang.String(bytes);System.out.println(s);//指定解码String s1 = new java.lang.String(bytes1,"GBK");System.out.println(s1);}
}
3.IO流(代表读取数据)
学习IO流就和集合一样,不同常见下使用不用的集合这是很有必要的
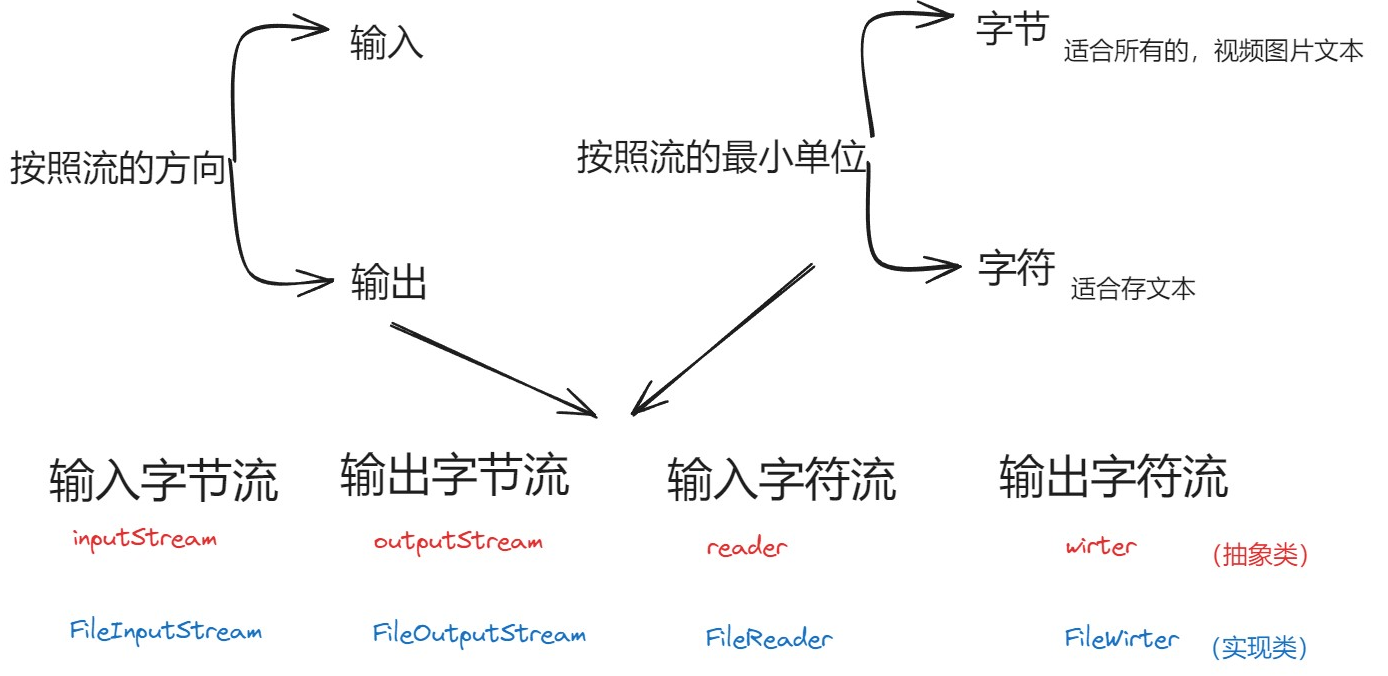
FileInputStream(文件字节输入流):以内存为基准,可以把磁盘文件中的数据以字节的形式读入内存中
还是去找一下构造器和方法
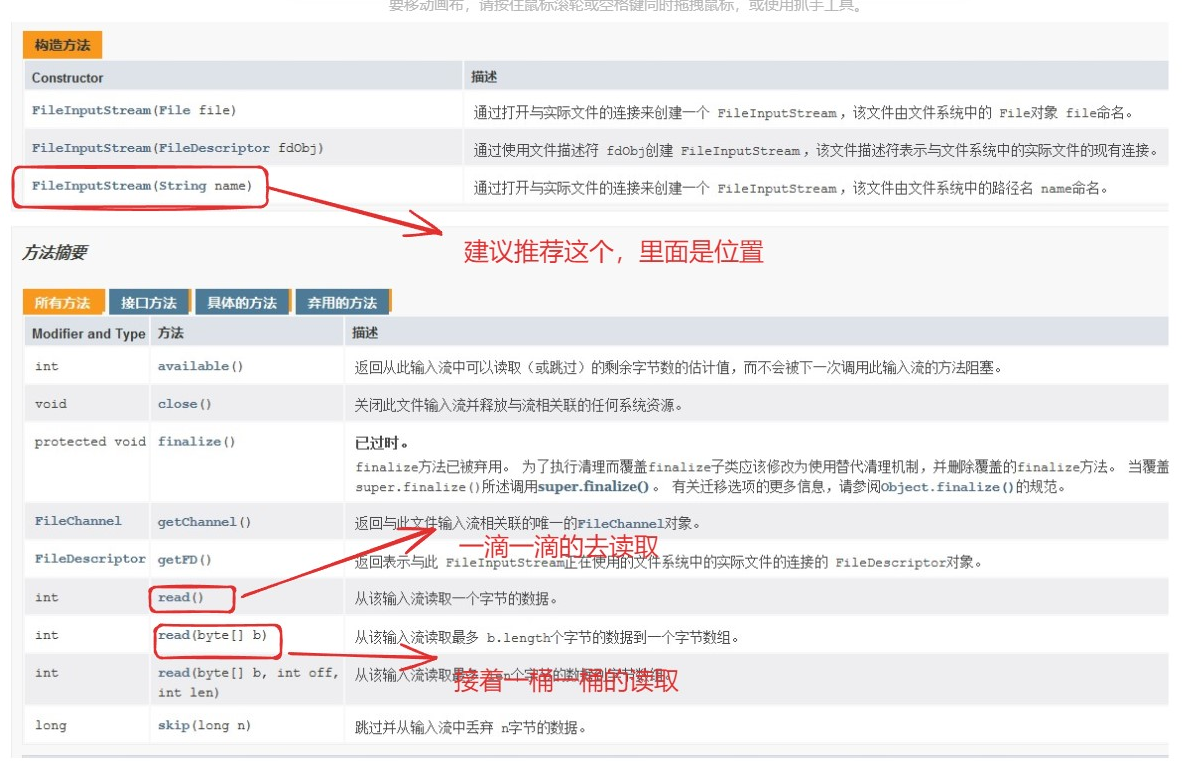
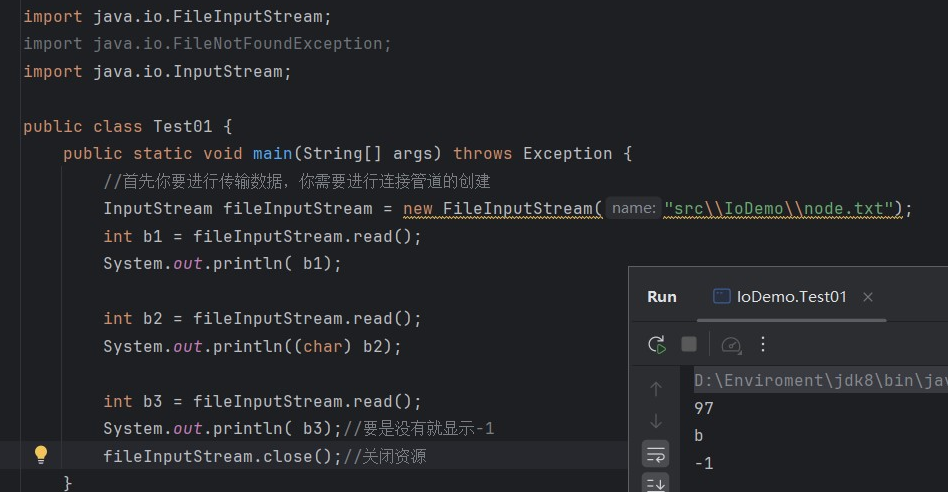
首先我们会想到那就一滴一滴进行流呗:(我们需要知道当没有的读出来就是-1)
因此我们可以对其进行循环,这样就不需要一个一个的取出来
package IoDemo;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;public class Test01 {public static void main(String[] args) throws Exception {//首先你要进行传输数据,你需要进行连接管道的创建InputStream fileInputStream = new FileInputStream("src\\IoDemo\\node.txt");int b;while ((b = fileInputStream.read()) != -1){System.out.print((char) b );}fileInputStream.close();//关闭资源}
}
但是这样有很大的问题:
1.就是性能很差,因为你要去硬盘里面进行读取,相比于内存是比较慢的(进行系统调用)
2.而且有个致命的就是你的汉字怎么办呢,汉字占三个字节,你一个一个读怎么可能呢,
先解决第一个效率的问题:那么我们就想了为什么要一滴一滴进行读取了,我直接一桶一桶的来不就行了、(需要注意读取多少,到处多少)!!!
package IoDemo;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;public class Test01 {public static void main(String[] args) throws Exception {//首先你要进行传输数据,你需要进行连接管道的创建InputStream fileInputStream = new FileInputStream("src\\IoDemo\\node.txt");//设计一个桶装水byte[] buffer = new byte[3];//记录长度int len1 = fileInputStream.read(buffer);//以字符串的形式打印出来String s = new String(buffer,0,len1);//这个可以不用//输出System.out.println(s);System.out.println("当前数目:" + len1);int len2 = fileInputStream.read(buffer);//以字符串的形式打印出来String s1 = new String(buffer,0,len2);//这个需要,因为如果你不这样只有两个就没办法把原来进行覆盖//输出System.out.println(s1);System.out.println("当前数目:" + len2);fileInputStream.close();//关闭资源}
}
还是像上面一样需要进行循环才能处理很多字节:
package IoDemo;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;public class Test01 {public static void main(String[] args) throws Exception {//首先你要进行传输数据,你需要进行连接管道的创建InputStream fileInputStream = new FileInputStream("src\\IoDemo\\node.txt");byte[] buffer = new byte[3];int len;while ((len = fileInputStream.read(buffer)) != -1){String s = new String(buffer, 0, len);System.out.print(s + " ");}fileInputStream.close();//关闭资源}
}
但是这个并没有解决汉字这个问题,因为我们是三个三个取出来,总会有错误的情况(比如abcd我爱你,这就会出现错误)
那么解决方案就是我可以一次性全部读取就好了,在buffer范围里面进行确定【但是这里也有一个麻烦就是你读取的数据太大,可能你的内存就不够了】
package IoDemo;import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;public class Test01 {public static void main(String[] args) throws Exception {//首先你要进行传输数据,你需要进行连接管道的创建InputStream fileInputStream = new FileInputStream("src\\IoDemo\\node.txt");File file = new File("src\\IoDemo\\node.txt");long size = file.length();byte[] buffer = new byte[(int) size];//这里就给我了一些警告,要是真的太大了也没办法进行处理int len = fileInputStream.read(buffer);System.out.println(new String(buffer, 0, len));fileInputStream.close();//关闭资源}
}
上述就是字节输入流,下面我们就需要介绍字节输出流(注意输出的时候如果文件不存在,他会自动帮你创造!)
package IoDemo;import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.OutputStream;public class Test02 {public static void main(String[] args) throws Exception {//创建一个输出流管道
// OutputStream fileOutputStream = new FileOutputStream("src\\IoDemo\\node1.txt");//这个不能追加OutputStream fileOutputStream = new FileOutputStream("src\\IoDemo\\node1.txt",true);//这个不能追加//开始写字节数据出去(一个一个字节)fileOutputStream.write(97);fileOutputStream.write('a');//一次写多个字节(字符串转换字节数组)byte[] bytes = "我爱你中国".getBytes();fileOutputStream.write(bytes);fileOutputStream.write(bytes,0,3);//换行fileOutputStream.write("\r\n".getBytes());//关闭fileOutputStream.close();}
}
下面我将对上面的输入输出字节流进行总结,以一个文件(图片)复制作为案例!
(图片复制其实就是对文件进行读写操作!)
package IoDemo;import java.io.*;public class Test03 {public static void main(String[] args) {System.out.println("--------输入流-------------");//对文件进行读操作//创建一个输入字节流管道InputStream fileInputStream = null;OutputStream fileOutputStream = null;try {//创建一个输入字节流管道fileInputStream = new FileInputStream("src\\IoDemo\\img.png");//然后就是进行读取数据//首先创建字节数组File file = new File("src\\IoDemo\\img.png");long size = file.length();byte[] buffer = new byte[(int) size];//字符串输出int len = fileInputStream.read(buffer);System.out.println(new String(buffer, 0, len));System.out.println("--------输入流-------------");System.out.println("--------输出流-------------");fileOutputStream = new FileOutputStream("src\\IoDemo\\img1.png");fileOutputStream.write(buffer);System.out.println("--------输出流-------------");} catch (Exception e) {throw new RuntimeException(e);}finally {try {fileInputStream.close();} catch (IOException e) {throw new RuntimeException(e);}try {fileOutputStream.close();} catch (IOException e) {throw new RuntimeException(e);}}}
}
但是上述有一个问题需要我们改进一下,就是这个图片格式还算小的,那么如果格式大了,其实这样一下创建一个这样的字节数组是非常占用内存的,因此我们使用循环,一次占用1024个字节,也就是1kb(下面这个代码就是对于复制都是通用的!!!)
package IoDemo;import java.io.*;public class Test4 {public static void main(String[] args) {InputStream fileInputStream = null;OutputStream fileOutputStream = null;try {//创建输入管道fileInputStream = new FileInputStream("src\\IoDemo\\img.png");//创建输出管道fileOutputStream = new FileOutputStream("src\\IoDemo\\img2.png");//首先我们创建一个1kb的字节数组byte[] buffer = new byte[1024];//然后进行循环int len;while ((len = fileInputStream.read(buffer)) != -1){fileOutputStream.write(buffer,0,len);}} catch (Exception e) {throw new RuntimeException(e);}finally {try {fileInputStream.close();} catch (IOException e) {throw new RuntimeException(e);}try {fileOutputStream.close();} catch (IOException e) {throw new RuntimeException(e);}}}
}
(起初我对代码还是有点不太理解,为什么不会出现乱码)
是因为即使中间有乱码的但是在复制成新文件的时候,就继续的进行上一个黏贴,所以字节流适合复制,但不适合读取文件