宁波网站建设方案报价2022百度指数排名
前言:
这里面重点通过PyTorch 实现Transformer MoE的模型部分
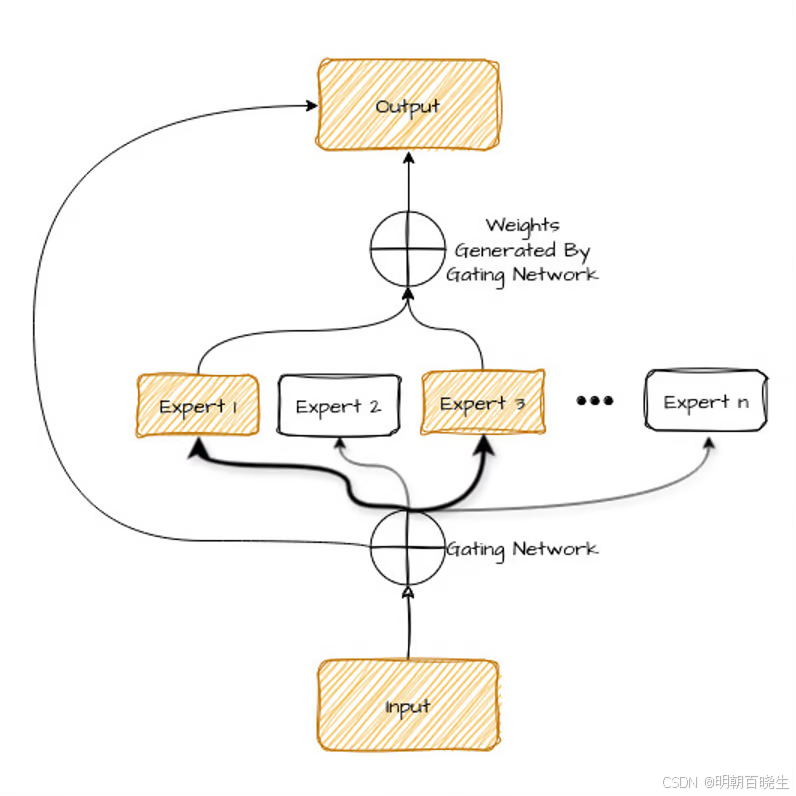
主要有两种架构:
1 一个 Transformer 编码器内部有多个专家。
2 以整体 Transformer 编码器为专家
目录:
1:整个 transformer encoder 作为 expert
2:以整体 Transformer 编码器为expert
一: 一个 Transformer 编码器内部有多个专家。
把 Transformer FFN 换成多个MoE
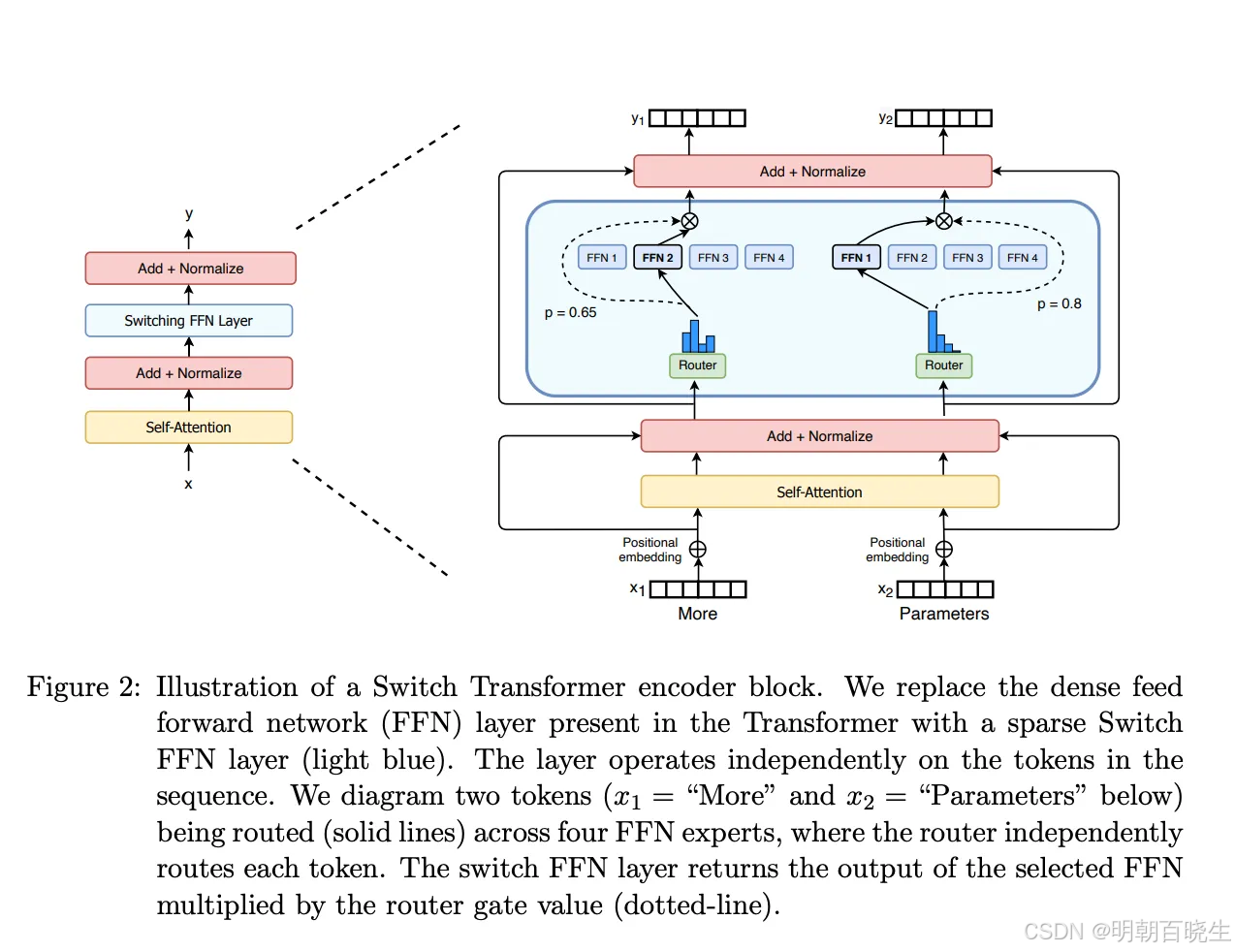
里面的Expert采用了FFN 模型
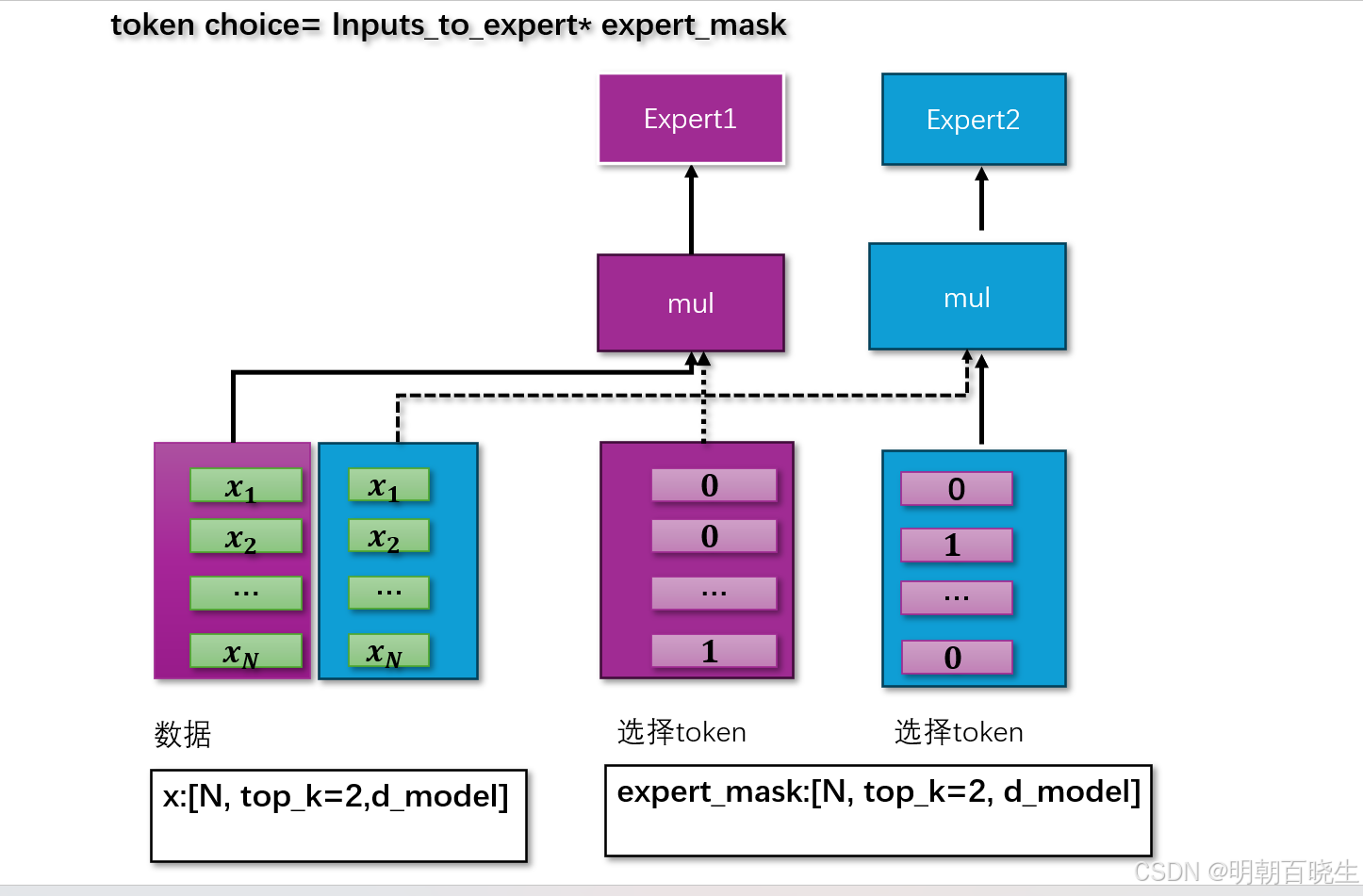
# -*- coding: utf-8 -*-
"""
Created on Mon Mar 24 11:45:03 2025@author: chengxf2
"""import torch
import torch.nn as nn
import torch.nn.functional as Fclass Expert(nn.Module):"""与 Transformer Encoder Layers 中的 FFN 类似的 FFN 专家。""" def __init__(self, d_model=512, hidden_dim=1024):super(Expert, self).__init__()self.input_projection = nn.Linear(d_model, hidden_dim)self.output_projection = nn.Linear(hidden_dim, d_model)self.activation = nn.ReLU()def forward(self, x):x = self.input_projection(x)x = self.activation(x)output = self.output_projection(x)return outputclass Router(nn.Module):"""用于将 token 分发给专家的路由器。""" def __init__(self, d_model, num_experts):super(Router, self).__init__()self.layer = nn.Linear(d_model, num_experts)def forward(self, x):z = self.layer(x)output = F.softmax(z,dim=-1)return outputclass MoE(nn.Module):def __init__(self, d_model, num_experts, hidden_dim, top_k=2):super(MoE, self).__init__()self.experts = nn.ModuleList([Expert(d_model,hidden_dim) for i in range(num_experts)])self.router = Router(d_model, num_experts)self.top_k = top_kdef forward(self, x):# 为路由器展平为 (token_num, d_model)#其中 token_num = batch_size*seq_lenrouting_weights = self.router(x)topk_vals, topk_indices = torch.topk(routing_weights, self.top_k, dim=1)topk_vals_normalized = topk_vals / topk_vals.sum(dim=1, keepdim=True)outputs = torch.zeros_like(x)print("\n topk_vals.shape ",topk_vals.shape)for i , expert in enumerate(self.experts):#expert_mask.shape: [token_num, top_k]expert_mask = (topk_indices==i).float()if expert_mask.any():#token choice#input_to_expert = x.unsqueeze(1).repeat(1,self.top_k,1)*expert_mask#inputs_to_expert = x*expert_mask.unsqueeze(-1)expert_mask = expert_mask.unsqueeze(-1)#print("\n x",x.shape, "\t expert_mask",expert_mask.shape)inputs_to_expert = torch.mul(x.unsqueeze(1), expert_mask)expert_output = expert(inputs_to_expert)#print("\n expert_output: ",expert_output.shape, "\t topk_vals_normalized ", topk_vals_normalized.shape)weighted_expert_outputs = expert_output * topk_vals_normalized.unsqueeze(-1)outputs += weighted_expert_outputs.sum(dim=1)return outputsclass TransformerEncoderLayerWithMoE (nn.Module): def __init__(self, d_model, nhead, num_experts, hidden_dim, dropout, top_k):super (TransformerEncoderLayerWithMoE, self).__init__() self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)self.moe = MoE(d_model, num_experts, hidden_dim,top_k)# 前馈模型的实现self.dropout = nn.Dropout(dropout) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) def forward(self, src=None, src_mask=None, src_key_padding_mask=None):src2 = self.self_attn(src, src, src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[ 0 ] src = src + self.dropout(src2) src = self.norm1(src) #print('\n src ',src.shape)# 利用专家混合batch_size, seq_len, d_model = src.shapesrc = src.view(-1,d_model)src2 = self.moe(src) src = src + self.dropout(src2) src = self.norm2(src) src = src.view(batch_size, seq_len,d_model)return src#Step 3: Initialize the model, the loss and optimizer
num_experts = 8
d_model = 512
nhead = 8
hidden_dim = 1024
dropout = 0.1
num_layers = 3
batch_size = 2
seq_len = 3
d_model = 512
top_k = 2
x = torch.randn(batch_size,seq_len, d_model)input_dim= 512
# Flatten to (batch_size*seq_len, d_model) for the router
model = TransformerEncoderLayerWithMoE(d_model, nhead, num_experts, hidden_dim, dropout, top_k)
output = model(x)
print(output.shape)二 整个 transformer encoder 作为 expert
在这种方法中,我们用多个 Transformer 编码器内部的前馈网络(FFN)作为专家,如下图
Step 1: Build an Expert Network
Step 2: Build the Mixture of Experts
Step 3: Initialize the model, the loss and optimizer
Step 4: Train the model
# -*- coding: utf-8 -*-
"""
Created on Fri Mar 21 15:58:13 2025@author: chengxf2
"""
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Expert(nn.Module):def __init__(self, d_model, nhead, num_layers, input_dim, output_dim):super(Expert, self).__init__()encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead)self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)self.input_projection = nn.Linear(input_dim, d_model)self.output_projection = nn.Linear(d_model, output_dim)def forward(self, x):x = self.input_projection(x)x = self.transformer_encoder(x.unsqueeze(0)).squeeze(0) # Transformer expects (S, N, E), adjusting for N=1output = self.output_projection(x)return outputclass MixtureOfExperts(nn.Module):def __init__(self, num_experts, d_model, nhead, num_layers, input_size, output_size):super(MixtureOfExperts, self).__init__()self.experts = nn.ModuleList([Expert(d_model, nhead, num_layers, input_size, output_size) for _ in range(num_experts)])self.gates = nn.Linear(input_size, num_experts)def forward(self, x):weights = F.softmax(self.gates(x), dim=1)outputs = torch.stack([expert(x) for expert in self.experts], dim=2)return (weights.unsqueeze(2) * outputs).sum(dim=2)class Router(nn.Module):def __init__(self, input_dim=512, num_experts=8):super().__init__()self.layer = nn.Linear(input_dim, num_experts)def forward(self, x):z = self.layer(x)output = F.softmax(z, dim=-1)#print("\n input.shape",x.shape,"\t output", output.shape)return outputclass MoE(nn.Module):def __init__(self, input_dim, output_dim, num_experts, d_model, nhead, num_layers, top_k=2):super().__init__()self.experts = nn.ModuleList([Expert(d_model, nhead, num_layers, input_dim, output_dim) for _ in range(num_experts)])self.router = Router(input_dim, num_experts)self.output_dim = output_dimself.top_k = top_kdef forward(self, x):token_num = x.size(0)#Flatten to (batch_size*seq_len, d_model) for the routerrouting_weights = self.router(x)topk_vals, topk_indices = torch.topk(routing_weights, self.top_k, dim=1)print("\n topk_vals ",topk_vals.shape, "\n topk_indices",topk_indices)topk_vals_normalized = topk_vals / topk_vals.sum(dim=1, keepdim=True)outputs = torch.zeros(token_num, self.output_dim, device=x.device)for i, expert in enumerate(self.experts):#当前的expert: token choicetoken_choice = (topk_indices == i).float()#print("\n token_choice \n",i,token_choice)#print(f"expert{i} \n",expert_mask)if token_choice.any():#[token_num, k]d_model = x.size(1)#[token_num,top_k, d_model]expert_mask = token_choice.unsqueeze(-1)#print(expert_mask.shape)expert_mask= expert_mask.expand(-1, -1, d_model)inputs_to_expert = x.unsqueeze(1).repeat(1, self.top_k, 1) * expert_mask#稀疏inputs_to_expert = inputs_to_expert.view(-1, d_model)expert_outputs = expert(inputs_to_expert).view(token_num, self.top_k, -1)# Weight outputs by normalized routing probability and sum across selected expertsweighted_expert_outputs = expert_outputs * topk_vals_normalized.unsqueeze(-1)outputs += weighted_expert_outputs.sum(dim=1)return outputsdef train():#Step 3: Initialize the model, the loss and optimizernum_experts = 8d_model = 512nhead = 8num_layers = 3batch_size = 2 seq_len = 3d_model = 512top_k = 2x = torch.randn(batch_size,seq_len, d_model)x = x.view(-1,d_model)input_dim= 512# Flatten to (batch_size*seq_len, d_model) for the routermodel = MoE(input_dim, num_experts, num_experts, d_model, nhead, num_layers, top_k)output = model(x)print(output.shape)'''criterion = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# Training loopfor epoch in range(100):for i, data in enumerate(dataloader): # Assume dataloader is defined and provides input and target datainputs, targets = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()print(f"Epoch {epoch + 1}, Loss: {loss.item()}")'''train()
Mixtral of experts | Mistral AI