检察院门户网站建设方案用织梦做的网站好用吗
目录
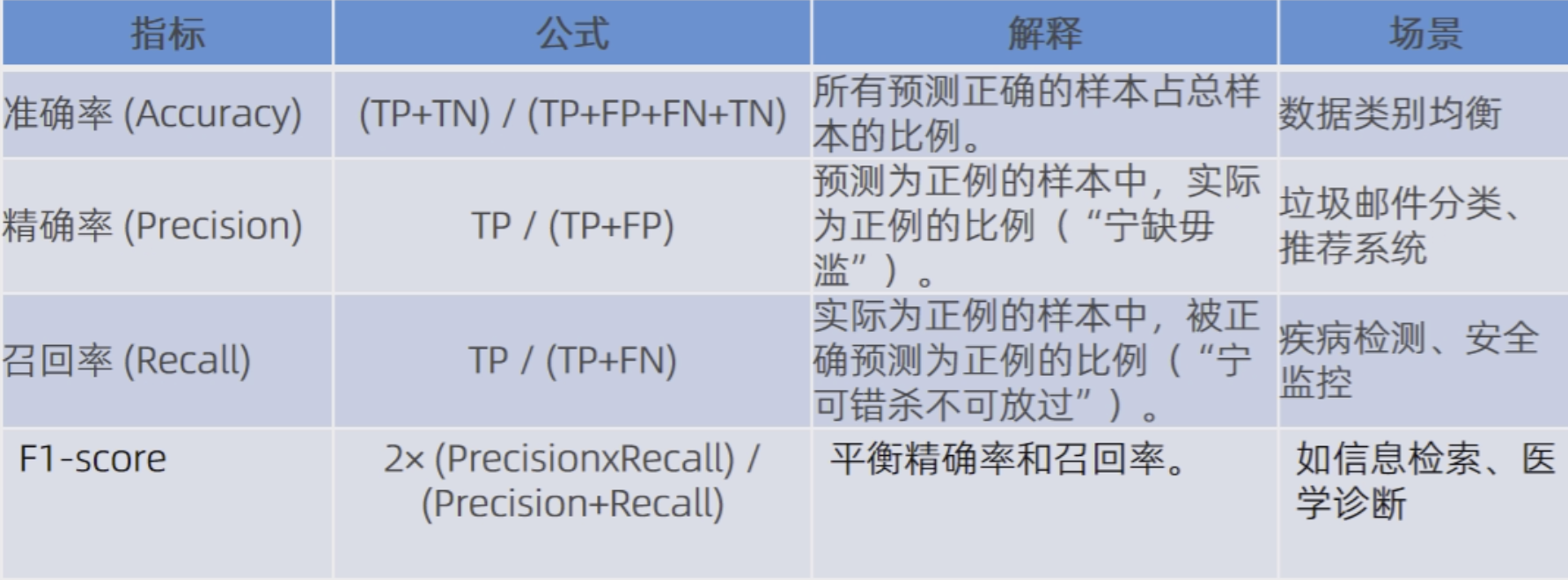
常见指标
其他的评估指标
3.1 BLEU
3.2 ROUGE
3.3 困惑度PPL(perplexity)
常见指标
其他的评估指标
3.1 BLEU
BLEU(Bilingual Evaluation Understudy,双语评估替补)分数是评估一种语言翻译成另一种语言的文本质量的指标。它将“质量”的好坏定义为与人类翻译结果的一致性程度。
BLEU是一种广泛用于评估机器翻译和文本生成任务的自动评价指标,它通过比较生成文本(Candidate)和参考文本(Reference)之间的n-gram重叠程度,量化生成质量。
BLEU算法实际上就是在判断两个句子的相似程度. BLEU 的分数取值范围是 0~1,分数越接近1,说明翻译的质量越高。
BLEU有许多变种,根据n-gram可以划分成多种评价指标,常见的评价指标有BLEU-1、BLEU-2、BLEU-3、BLEU-4四种,其中n-gram指的是连续的单词个数为n,BLEU-1衡量的是单词级别的准确性,更高阶的BLEU可以衡量句子的流畅性.实践中,通常是取N=1~4,然后对进行加权平均。
下面举例说计算过程:
-
基本步骤:
-
分别计算预测文本candidate和目标文本reference的N-gram模型,然后统计其匹配的个数,计算匹配度
-
公式
-
BLEU-N = (Σ Count_match(N-gram)) / (Σ Count(N-gram in candidate))
-
candidate和reference中匹配的 n−gram 的个数 / candidate中 n−gram 的个数.
-
-
-
假设分别给出一个预测文本和目标文本如下:
预测文本: It is a nice day today 目标文本: today is a nice day
-
使用1-gram进行匹配
预测文本: {it, is, a, nice, day, today}
目标文本: {today, is, a, nice, day}
结果:其中{today, is, a, nice, day}匹配,所以匹配度为5/6
-
使用2-gram进行匹配
预测文本: {it is, is a, a nice, nice day, day today}
目标文本: {today is, is a, a nice, nice day}
结果:其中{is a, a nice, nice day}匹配,所以匹配度为3/5
-
使用3-gram进行匹配
预测文本: {it is a, is a nice, a nice day, nice day today}
目标文本: {today is a, is a nice, a nice day}
结果:其中{is a nice, a nice day}匹配,所以匹配度为2/4
-
使用4-gram进行匹配
预测文本: {it is a nice, is a nice day, a nice day today}
目标文本: {today is a nice, is a nice day}
结果:其中{is a nice day}匹配,所以匹配度为1/3
上述例子会出现一种极端情况,请看下面示例:
预测文本: the the the the 目标文本: The cat is standing on the ground 如果按照1-gram的方法进行匹配,则匹配度为1,显然是不合理的,所以计算某个词的出现次数进行改进
-
将计算某个词正确预测次数的方法改为计算某个词在文本中出现的最小次数,如下所示的公式:
-
其中$k$表示在预测文本中出现的第$k$个词语, $c_k$则代表在预测文本中这个词语出现的次数,而$s_k$则代表在目标文本中这个词语出现的次数。
python代码实现:
BLEU计算公式:

BLEU 评分范围
BLEU 分数范围:0 ~ 1(通常用 0 ~ 100 表示)
一般理解:
BLEU 分数 质量 90 - 100 几乎完美 70 - 90 高质量 50 - 70 可接受 30 - 50 勉强可用 0 - 30 低质量
# 第一步安装nltk的包-->pip install nltk
from nltk.translate.bleu_score import sentence_bleudef cumulative_bleu(reference, candidate):# 指标计算:p1^w1*p2^w2 =0.6^0.5*0.25^0.5 = 0.387# math.exp(0.5 * math.log(0.6) + 0.5 * math.log(0.25)) =# math.exp(0.5*math.log(0.15)) = math.exp(math.log(0.15)^0.5) = 0.15^0.5 = 0.387bleu_1_gram = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0))bleu_2_gram = sentence_bleu(reference, candidate, weights=(0.5, 0.5, 0, 0))bleu_3_gram = sentence_bleu(reference, candidate, weights=(0.33, 0.33, 0.33, 0))bleu_4_gram = sentence_bleu(reference, candidate, weights=(0.25, 0.25, 0.25, 0.25))# print('bleu 1-gram: %f' % bleu_1_gram)# print('bleu 2-gram: %f' % bleu_2_gram)# print('bleu 3-gram: %f' % bleu_3_gram)# print('bleu 4-gram: %f' % bleu_4_gram)return bleu_1_gram, bleu_2_gram, bleu_3_gram, bleu_4_gram# 预测文本
candidate_text = ["This", "is", "some", "generated", "text"]# 目标文本列表
reference_texts = [["This", "is", "a", "reference", "text"],["This", "is", "another", "reference", "text"]]# 计算 Bleu 指标
c_bleu = cumulative_bleu(reference_texts, candidate_text)# 打印结果print("The Bleu score is:", c_bleu)
# The Bleu score is: (0.6, 0.387, 1.5949011744633917e-102, 9.283142785759642e-155)3.2 ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)指标是在机器翻译、自动摘要、问答生成等领域常见的评估指标。ROUGE通过将模型生成的摘要或者回答与参考答案(一般是人工生成的)进行比较计算,得到对应的得分,专门用于衡量自动生成文本与人工参考文本之间的相似度。
ROUGE指标与BLEU指标非常类似,均可用来衡量生成结果和标准结果的匹配程度,不同的是ROUGE基于召回率,BLEU更看重准确率。
ROUGE分为四种方法:ROUGE-N, ROUGE-L, ROUGE-W, ROUGE-S.
下面举例说计算过程(这里只介绍ROUGE-N):
-
计算公式:ROUGE-N = (Σ Count_match(N-gram)) / (Σ Count(N-gram in reference))
-
基本步骤:Rouge-N实际上是将模型生成的结果和标准结果按N-gram拆分后,计算召回率
-
假设模型预测文本和一个目标文本如下:
预测文本: It is a nice day today 目标文本: Today is a nice day
-
使用ROUGE-1进行匹配
预测文本: {it, is, a, nice, day, today}
目标文本: {today, is, a, nice, day}
结果::其中{today, is, a, nice, day}匹配,所以匹配度为5/5=1,这说明生成的内容完全覆盖了参考文本中的所有单词,质量较高。
-
通过类似的方法,可以计算出其他ROUGE指标(如ROUGE-2、ROUGE-L、ROUGE-S)的评分,从而综合评估系统生成的文本质量。
python代码实现:
# 第一步:安装rouge-->pip install rouge
from rouge import Rouge# 预测文本
generated_text = "This is some generated text."# 目标文本列表
reference_texts = ["This is a reference text.", "This is another generated reference text."]# 计算 ROUGE 指标
rouge = Rouge()
scores = rouge.get_scores(generated_text, reference_texts[1])# 打印结果
print("ROUGE-1 precision:", scores[0]["rouge-1"]["p"])
print("ROUGE-1 recall:", scores[0]["rouge-1"]["r"])
print("ROUGE-1 F1 score:", scores[0]["rouge-1"]["f"])
# ROUGE-1 precision: 0.8
# ROUGE-1 recall: 0.6666666666666666
# ROUGE-1 F1 score: 0.72727272231404963.3 困惑度PPL(perplexity)
PPL用来度量一个概率分布或概率模型预测样本的好坏程度。PPL表示模型在预测下一个词时的“平均不确定性”,可以理解为模型需要“猜测多少次才能正确预测下一个词”。
PPL基本思想:
-
给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好.
-
基本公式(两种方式):
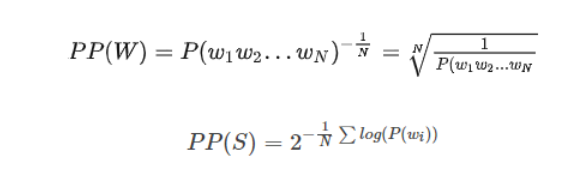
-
由公式可知,句子概率越大,语言模型越好,困惑度越小。
import math# 定义语料库
sentences = [['I', 'have', 'a', 'pen'],['He', 'has', 'a', 'book'],['She', 'has', 'a', 'cat']
]
# 定义语言模型
unigram = {'I': 1 / 12,'have': 1 / 12,'a': 3 / 12,'pen': 1 / 12,'He': 1 / 12,'has': 2 / 12,'book': 1 / 12,'She': 1 / 12,'cat': 1 / 12
}
# 初始化困惑度为0
perplexity = 0
# 循环遍历语料库
for sentence in sentences:# 计算句子的概率, 句子概率等于所有单词的概率相乘sentence_prob = 1# 循环遍历句子中的每个单词for word in sentence:# 计算单词的概率并累乘, 得到句子的概率sentence_prob *= unigram[word]# -1/N * log(P(W1W2...Wn))temp = -math.log(sentence_prob, 2) / len(sentence)# 累加句子的困惑度perplexity += 2 ** temp
# 计算困惑度 2**(-1/N * log(P(W1W2...Wn)))
perplexity = perplexity / len(sentences)
print('困惑度为:', perplexity)
# 困惑度为:8.15