添加网站到百度WordPress的数据库建表
目录
一、代码下载
二、数据准备
三、训练
四、测试
一、代码下载地址:open-mmlab/mmrotate: OpenMMLab Rotated Object Detection Toolbox and Benchmark
预训练模型下载:

二、数据准备
(1)一般是使用rolabelimg来标注,使用rolabelimg标注生成的是xml文件,但训练的时候使用的是txt文件。xml转txt代码如下:
import os
import xml.etree.ElementTree as ET
import math
import cv2 as cv
import numpy as npdef voc_to_dota(xml_dir, xml_name, img_dir, savedImg_dir):txt_name = xml_name[:-4] + '.txt' # txt文件名字:去掉xml 加上.txttxt_path = xml_dir + '/txt_label' # txt文件目录:在xml目录下创建的txtl_label文件夹if not os.path.exists(txt_path):os.makedirs(txt_path)txt_file = os.path.join(txt_path, txt_name) # txt完整的含名文件路径img_name = xml_name[:-4] + '.jpg' # 图像名字img_path = os.path.join(img_dir, img_name) # 图像完整路径# img = cv.imread(img_path) # 读取图像img = cv.imdecode(np.fromfile(img_path, dtype=np.uint8), 1)xml_file = os.path.join(xml_dir, xml_name)tree = ET.parse(os.path.join(xml_file)) # 解析xml文件 然后转换为DOTA格式文件root = tree.getroot()with open(txt_file, "w+", encoding='UTF-8') as out_file:# out_file.write('imagesource:null' + '\n' + 'gsd:null' + '\n')for obj in root.findall('object'):name = obj.find('name').textdifficult = obj.find('difficult').text# print(name, difficult)robndbox = obj.find('robndbox')cx = float(robndbox.find('cx').text)cy = float(robndbox.find('cy').text)w = float(robndbox.find('w').text)h = float(robndbox.find('h').text)angle = float(robndbox.find('angle').text)# print(cx, cy, w, h, angle)p0x, p0y = rotatePoint(cx, cy, cx - w / 2, cy - h / 2, -angle)p1x, p1y = rotatePoint(cx, cy, cx + w / 2, cy - h / 2, -angle)p2x, p2y = rotatePoint(cx, cy, cx + w / 2, cy + h / 2, -angle)p3x, p3y = rotatePoint(cx, cy, cx - w / 2, cy + h / 2, -angle)# 找最左上角的点dict = {p0y: p0x, p1y: p1x, p2y: p2x, p3y: p3x}list = find_topLeftPopint(dict)# print((list))if list[0] == p0x:list_xy = [p0x, p0y, p1x, p1y, p2x, p2y, p3x, p3y]elif list[0] == p1x:list_xy = [p1x, p1y, p2x, p2y, p3x, p3y, p0x, p0y]elif list[0] == p2x:list_xy = [p2x, p2y, p3x, p3y, p0x, p0y, p1x, p1y]else:list_xy = [p3x, p3y, p0x, p0y, p1x, p1y, p2x, p2y]# 在原图上画矩形 看是否转换正确cv.line(img, (int(list_xy[0]), int(list_xy[1])), (int(list_xy[2]), int(list_xy[3])), color=(255, 0, 0),thickness=3)cv.line(img, (int(list_xy[2]), int(list_xy[3])), (int(list_xy[4]), int(list_xy[5])), color=(0, 255, 0),thickness=3)cv.line(img, (int(list_xy[4]), int(list_xy[5])), (int(list_xy[6]), int(list_xy[7])), color=(0, 0, 255),thickness=2)cv.line(img, (int(list_xy[6]), int(list_xy[7])), (int(list_xy[0]), int(list_xy[1])), color=(255, 255, 0),thickness=2)data = str(list_xy[0]) + " " + str(list_xy[1]) + " " + str(list_xy[2]) + " " + str(list_xy[3]) + " " + \str(list_xy[4]) + " " + str(list_xy[5]) + " " + str(list_xy[6]) + " " + str(list_xy[7]) + " "data = data + name + " " + difficult + "\n"out_file.write(data)if not os.path.exists(savedImg_dir):os.makedirs(savedImg_dir)out_img = os.path.join(savedImg_dir, xml_name[:-4] + '.jpg')# cv.imwrite(out_img, img)cv.imencode(".png", img)[1].tofile(out_img)def find_topLeftPopint(dict):dict_keys = sorted(dict.keys()) # y值temp = [dict[dict_keys[0]], dict[dict_keys[1]]]minx = min(temp)if minx == temp[0]:miny = dict_keys[0]else:miny = dict_keys[1]return [minx, miny]# 转换成四点坐标
def rotatePoint(xc, yc, xp, yp, theta):xoff = xp - xcyoff = yp - yccosTheta = math.cos(theta)sinTheta = math.sin(theta)pResx = cosTheta * xoff + sinTheta * yoffpResy = - sinTheta * xoff + cosTheta * yoff# pRes = (xc + pResx, yc + pResy)# 保留一位小数点return float(format(xc + pResx, '.1f')), float(format(yc + pResy, '.1f'))# return xc + pResx, yc + pResyimport argparsedef parse_args():parser = argparse.ArgumentParser(description='数据格式转换')parser.add_argument('--xml-dir', default=r'C:\Users\Admin\Desktop\tmp_test\xml', help='original xml file dictionary')parser.add_argument('--img-dir', default=r'C:\Users\Admin\Desktop\tmp_test\img', help='original image dictionary')parser.add_argument('--outputImg-dir', default=r'C:\Users\Admin\Desktop\tmp_test\train_txt',help='saved image dictionary after dealing ')args = parser.parse_args()return argsif __name__ == '__main__':args = parse_args()xml_path = args.xml_dirxmlFile_list = os.listdir(xml_path)print(xmlFile_list)for i in range(0, len(xmlFile_list)):if ('.xml' in xmlFile_list[i]) or ('.XML' in xmlFile_list[i]):voc_to_dota(xml_path, xmlFile_list[i], args.img_dir, args.outputImg_dir)print('----------------------------------------{}{}----------------------------------------'.format(xmlFile_list[i], ' has Done!'))else:print(xmlFile_list[i] + ' is not xml file')(2)训练数据格式分布如下:images文件夹里是图片,labels文件夹里是对应的txt文件。txt前8个数字就是绘制的旋转框的四个点坐标, 然后是类别名称,最后一个是检测困难程度,0表示不困难

三、训练
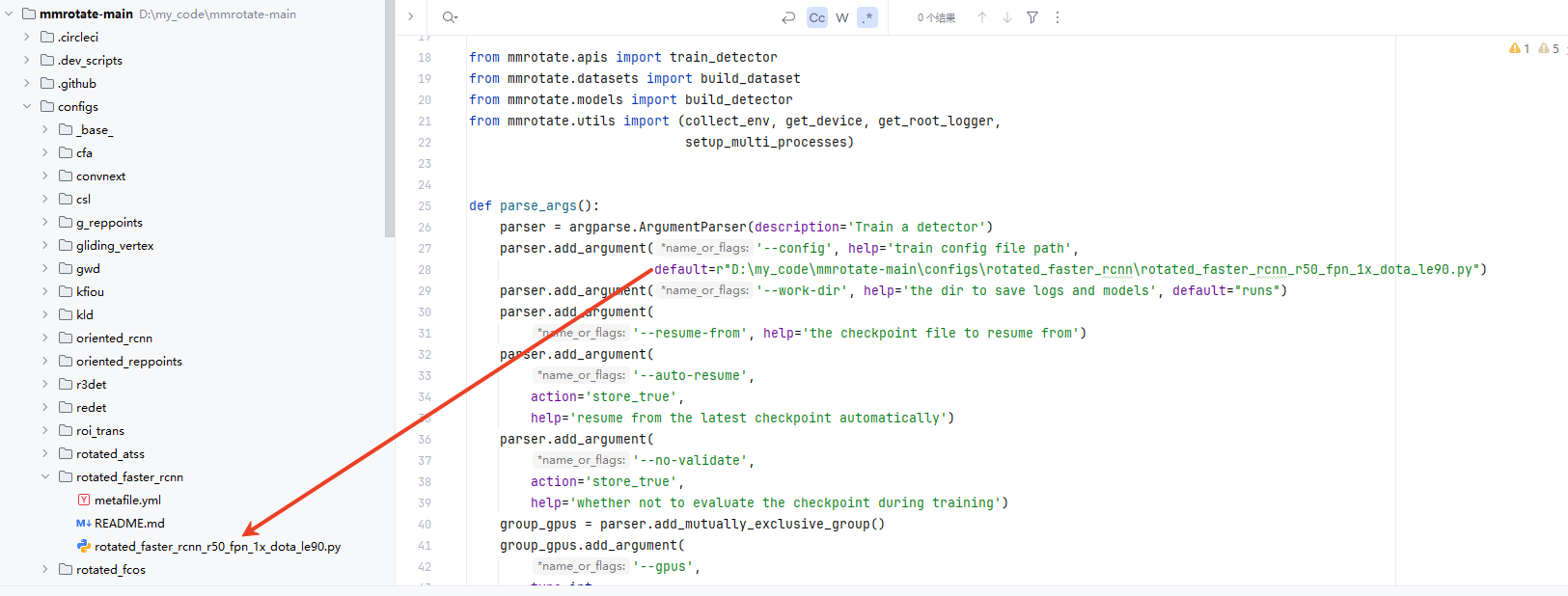
(1)参数配置:主要配置–config和–work-dir两个。其中–config为训练配置文件,–work-dir为模型和日志保存文件夹。config表示旋转使用哪种模型算法进行训练,这里使用的是rotated_faster_rcnn_r50_fpn_1x_dota_le90.py,可以根据自己的要求进行选择使用
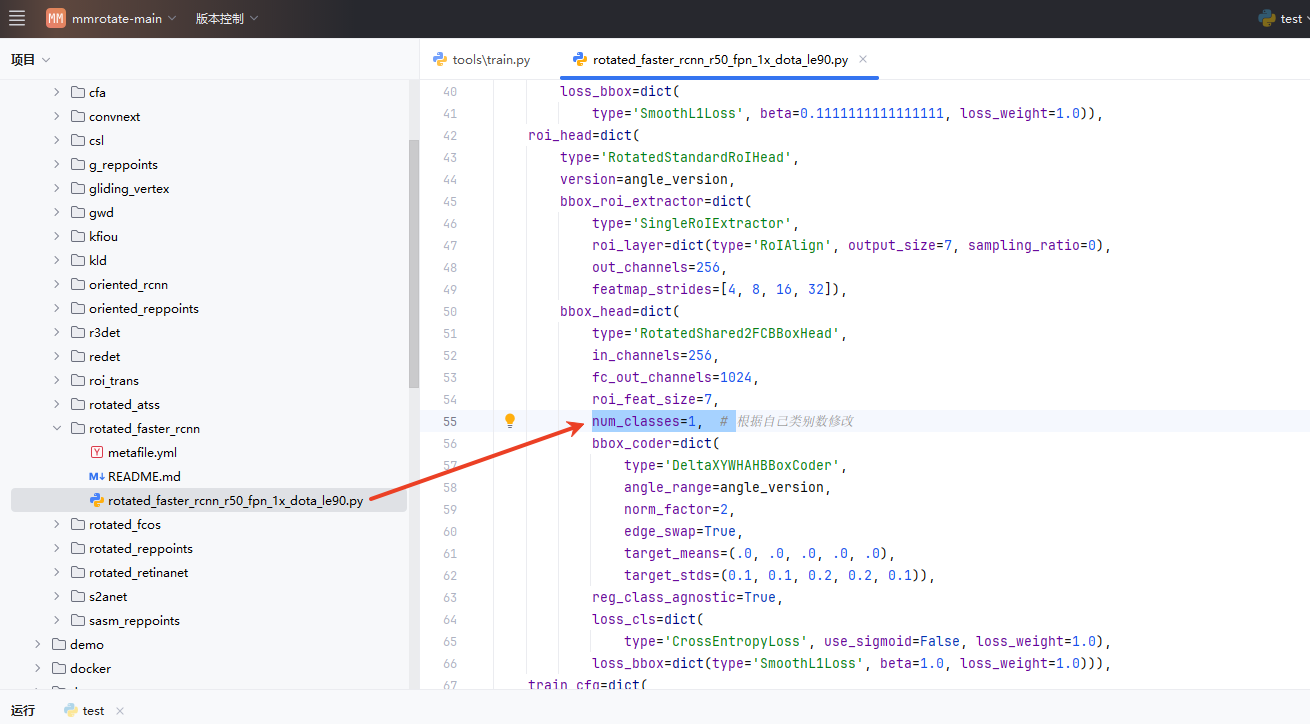
(2)类别数设置: 根据自己训练的类别数修改
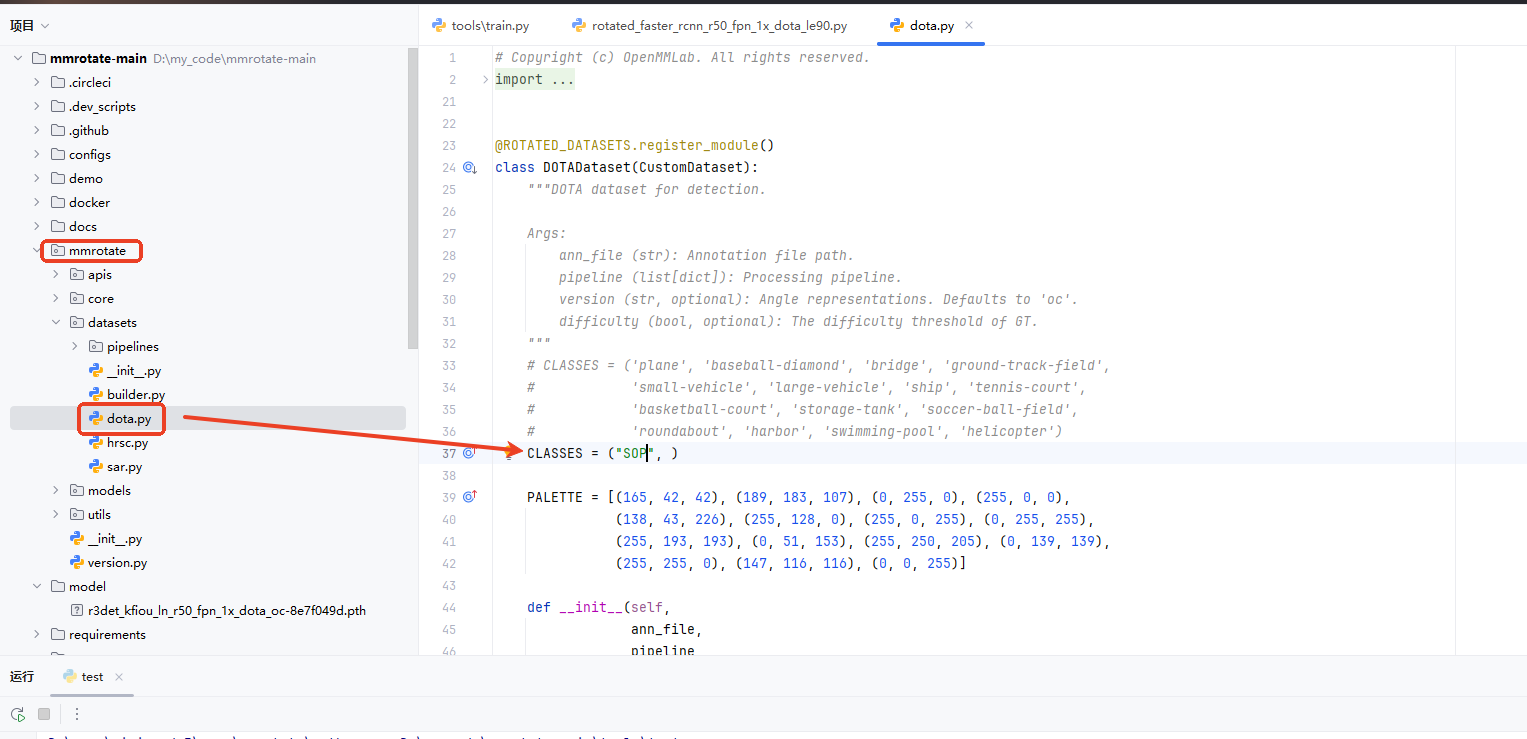
(3)类别名称修改,如果只有一个类别后面需要加上,确保这是一个tuple
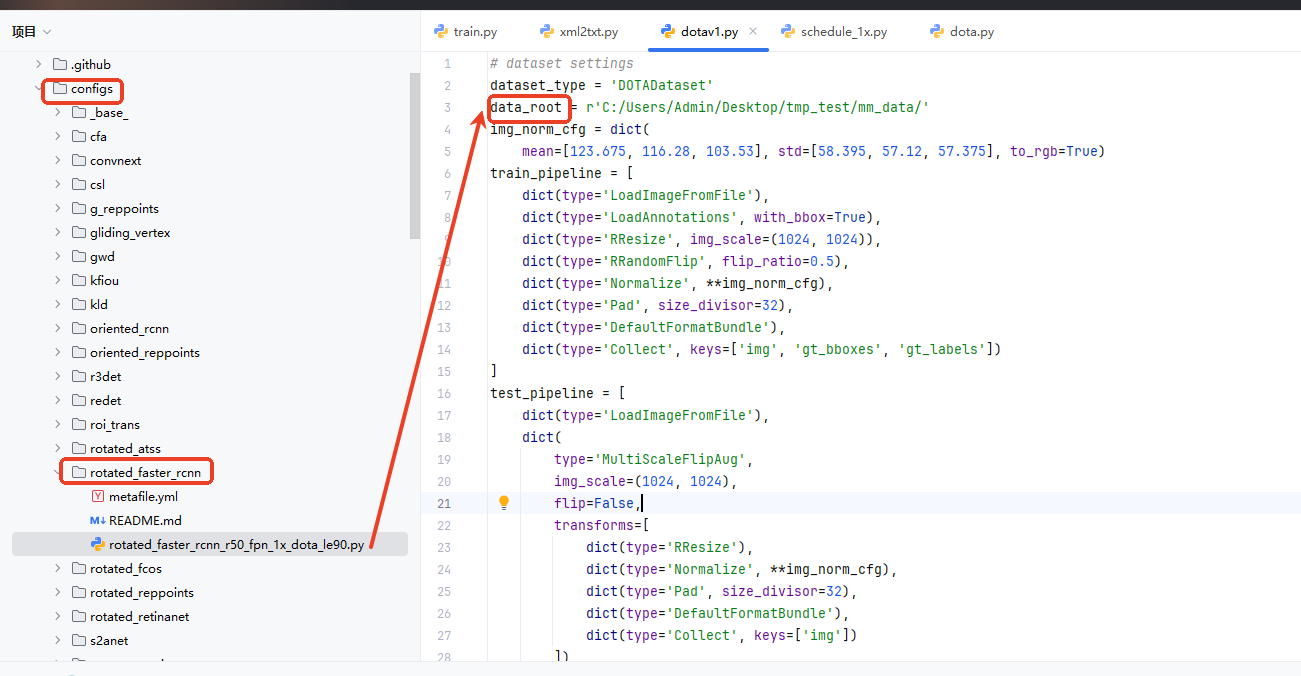
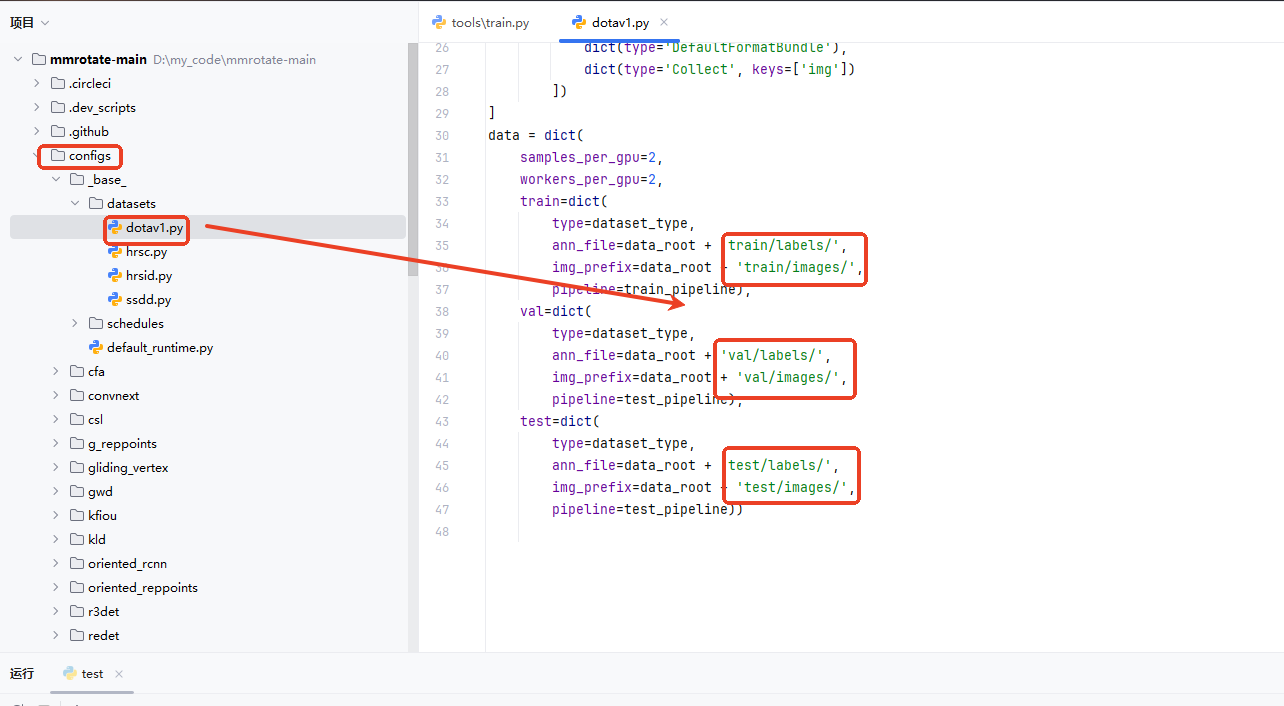
(4)训练数据集路径设置:
 (5)训练epoch设置
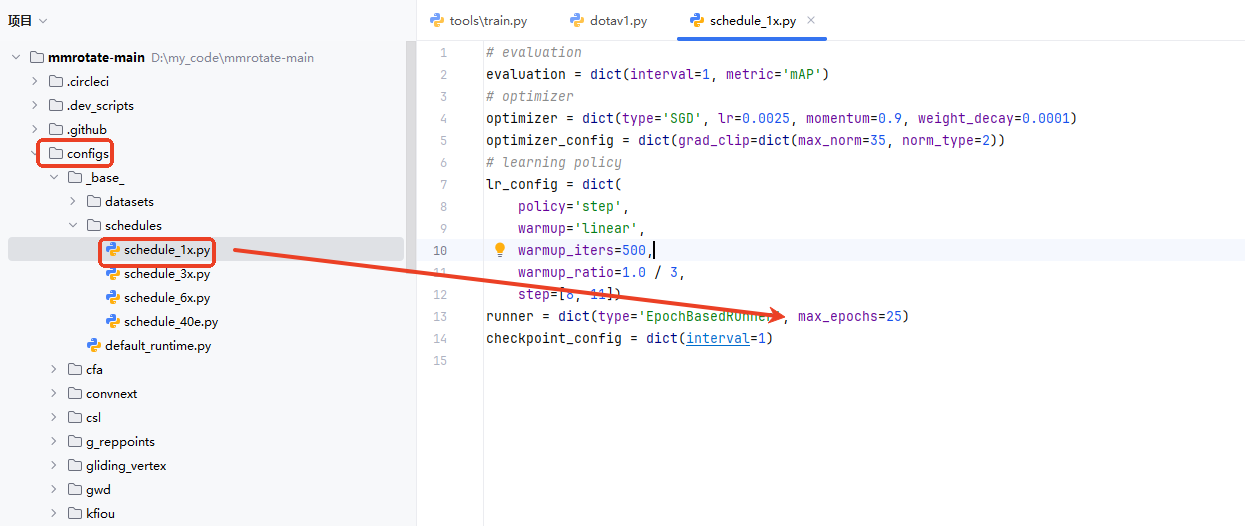
(5)训练epoch设置
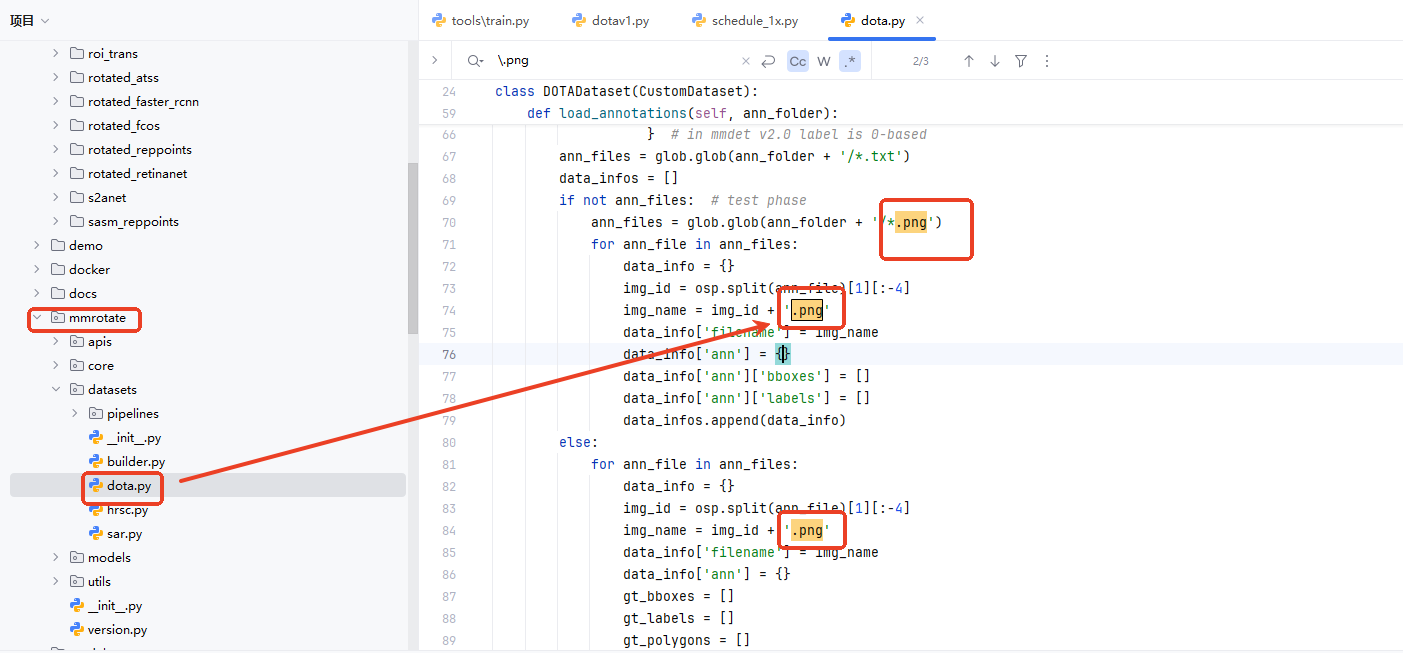
(6)训练图片格式修改,默认的代码只支持png格式的图片,在此处进行修改
(7)预训练模型设置:
(7)配置完之后就可以运行tool/train.py文件了