做印刷的网站做哪个网站好
在大模型推理能力不断取得突破的今天,强化学习成为提升模型能力的关键手段。然而,现有zero-RL方法存在局限。论文提出的LUFFY框架,创新性地融合离线策略推理轨迹,在多个数学基准测试中表现卓越,为训练通用推理模型开辟新路径,快来一探究竟!
论文标题
LUFFY: Learning to Reason under Off-Policy Guidance
来源
arXiv:2504.14945v2 [cs.LG] 22 Apr 2025
https://arxiv.org/abs/2504.14945
代码
https://github.com/ElliottYan/LUFFY
文章核心
研究背景
大推理模型(LRMs)借助强化学习(RL)取得显著进展,能实现复杂推理和自我反思等行为,但现有零RL方法存在局限性。
研究问题
-
zero-RL方法本质上是“在线策略(on-policy)”,学习局限于模型自身输出,难以突破初始能力边界,无法获取新的认知能力。
-
简单的模仿学习虽引入外部指导,但容易导致模型陷入表面和僵化的推理模式,阻碍进一步学习,泛化能力受限。
-
离线策略学习在zero-RL中尚未得到充分探索,如何有效结合离线策略知识与在线策略学习,而非单纯模仿学习,是亟待解决的问题。
主要贡献
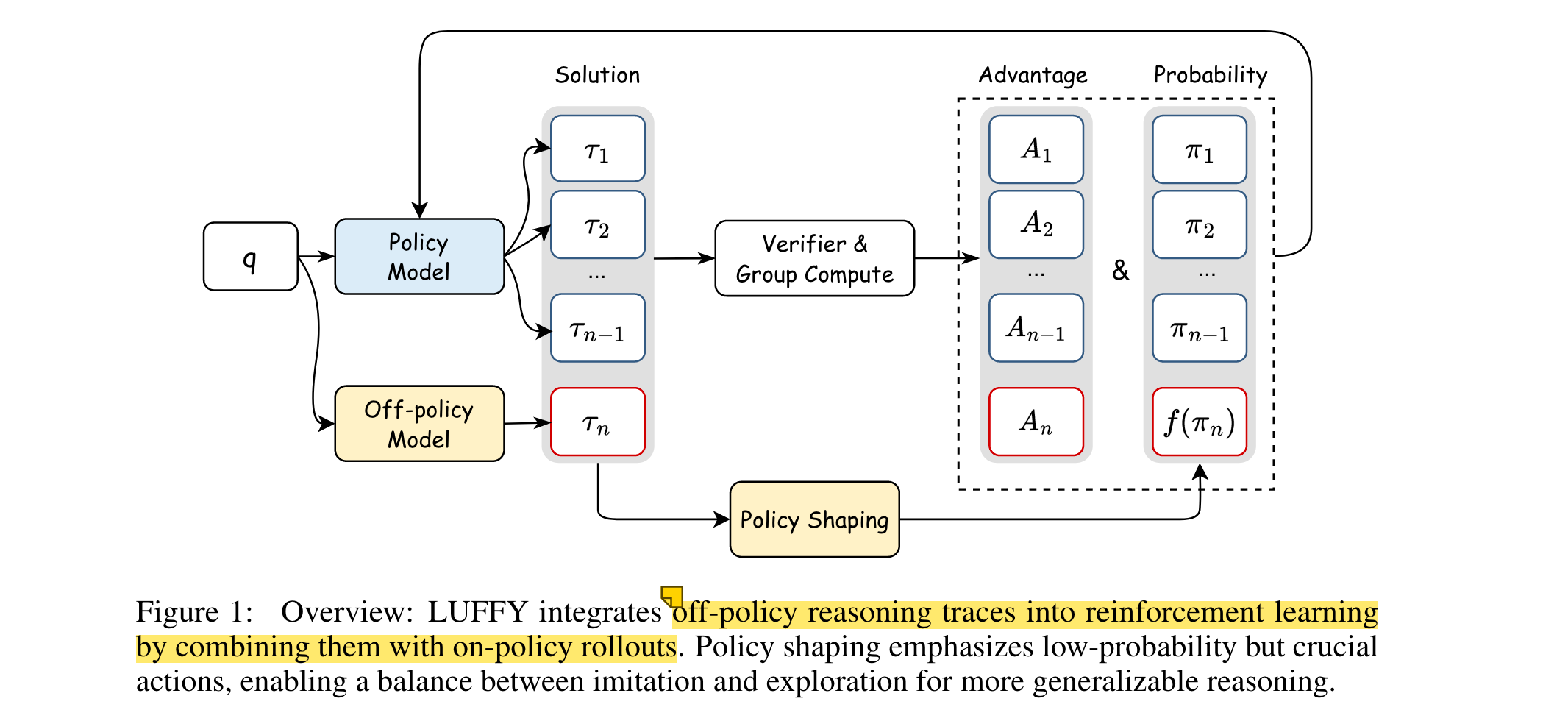
1. 提出LUFFY框架:将离线策略推理轨迹集成到zero-RL范式中,通过结合离线策略演示和在线策略滚动(rollouts),动态平衡模仿和探索,有效利用外部推理轨迹,提升模型推理能力。
2. 引入策略塑造技术:通过正则化重要性采样进行policy shape,避免混合策略训练中的表面和僵化的模仿,增强对低概率但关键动作的学习信号,鼓励模型在训练中持续探索,内化更深入、更具泛化性的推理行为。
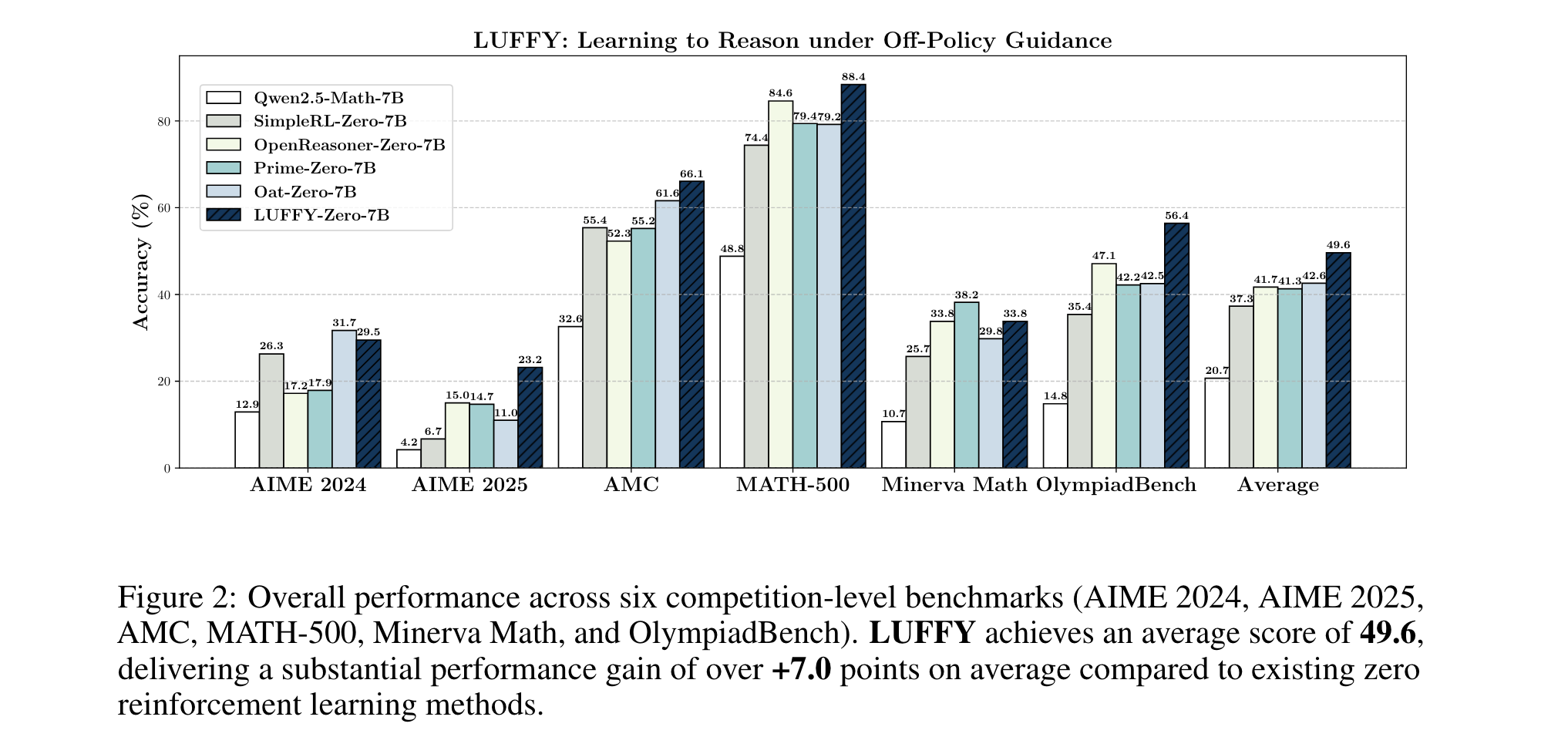
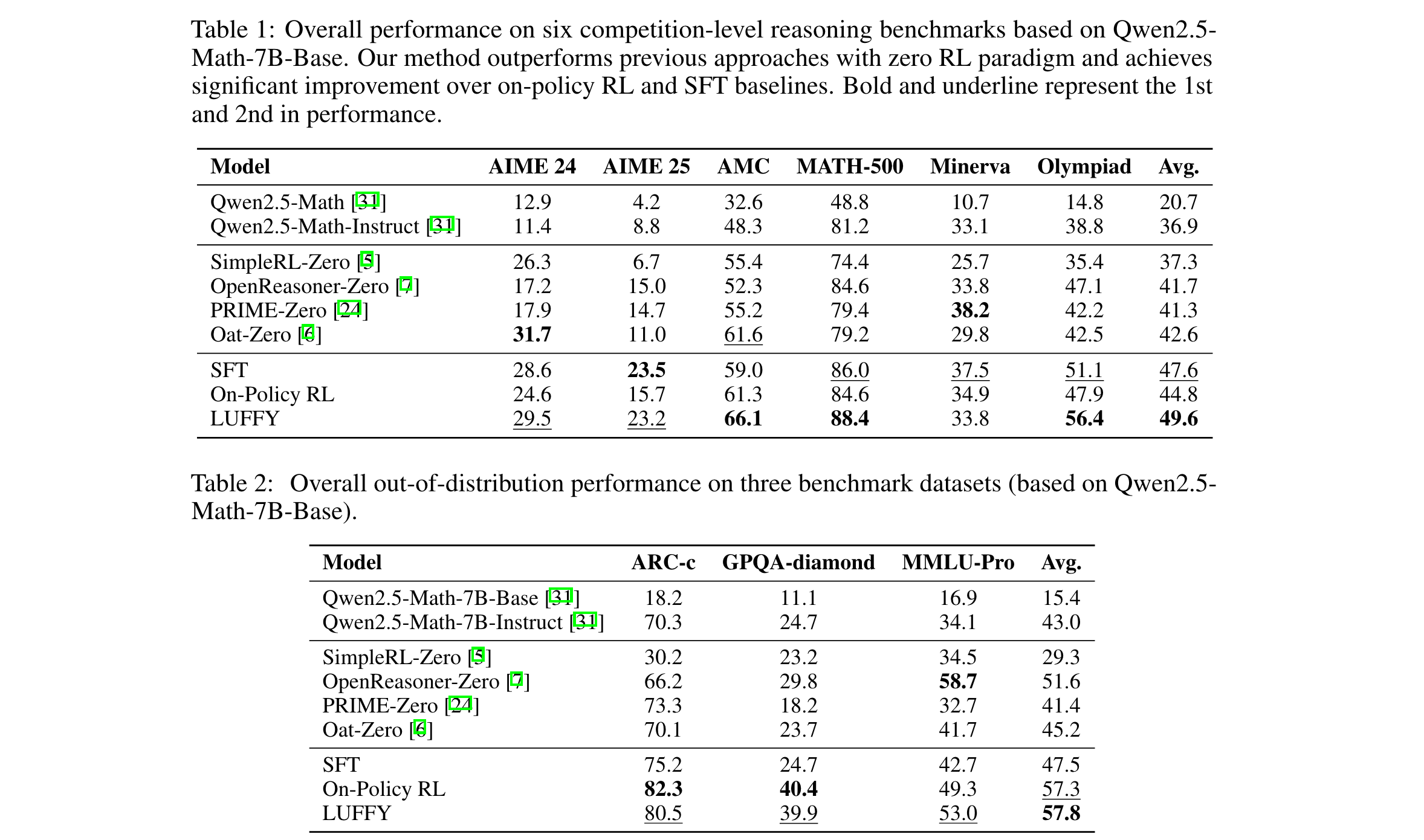
3. 超越基线方法:在六个数学基准测试中,LUFFY平均得分比现有零RL方法高出7.0分以上;在分布外任务中优势超过6.2分,显著超越基于模仿的监督微调(SFT),在泛化能力上表现出色。
方法论精要
1. 核心算法/框架:基于传统零RL方法GRPO,引入离线策略推理轨迹,形成混合策略GRPO,并在此基础上通过正则化重要性采样进行policy shaping,构建LUFFY框架。
2. 关键参数设计原理:在GRPO中,通过采样N个解决方案的奖励分数估计优势,去除额外价值模型需求。在混合策略GRPO中,调整优势计算方式,将离线策略滚动结果纳入计算。策略塑造时,使用 f ( x ) = x / ( x + γ ) f(x)=x /(x+\gamma) f(x)=x/(x+γ)( γ \gamma γ设为0.1)作为塑造函数,重新加权离线策略分布的梯度,增强对低概率动作的学习。
3. 创新性技术组合:将离线策略推理轨迹与在线策略滚动相结合,同时运用正则化重要性采样的策略塑造技术,以及去除在线策略clip的操作,提升模型学习效果。
4. 实验验证方式:使用包含94k提示的OpenR1 - Math - 220k子集作为训练集,经过筛选得到45k提示和离线策略推理轨迹。选择Qwen2.5 - Math - 7B等模型进行实验,对比Simple - RL、Oat - Zero等多种零RL方法,以及On - Policy RL和SFT等基线方法。在六个数学推理基准测试(如AIME 2024、AIME 2025等)和三个分布外基准测试(ARC - c、GPQA - diamond、MMLU - Pro)上进行评估,使用规则基奖励函数,通过Math - Verify验证。
实验洞察
1. 性能优势:在六个数学推理基准测试中,LUFFY平均得分49.6,比现有零RL方法平均提升7.0分以上。例如在AIME 2025测试集中,比其他零RL方法优势明显(如比SimpleRL - Zero高16.5分)。在分布外任务中,LUFFY平均得分57.8,比零RL方法有显著提升,且在MMLU - Pro基准测试上大幅超越On - Policy RL。
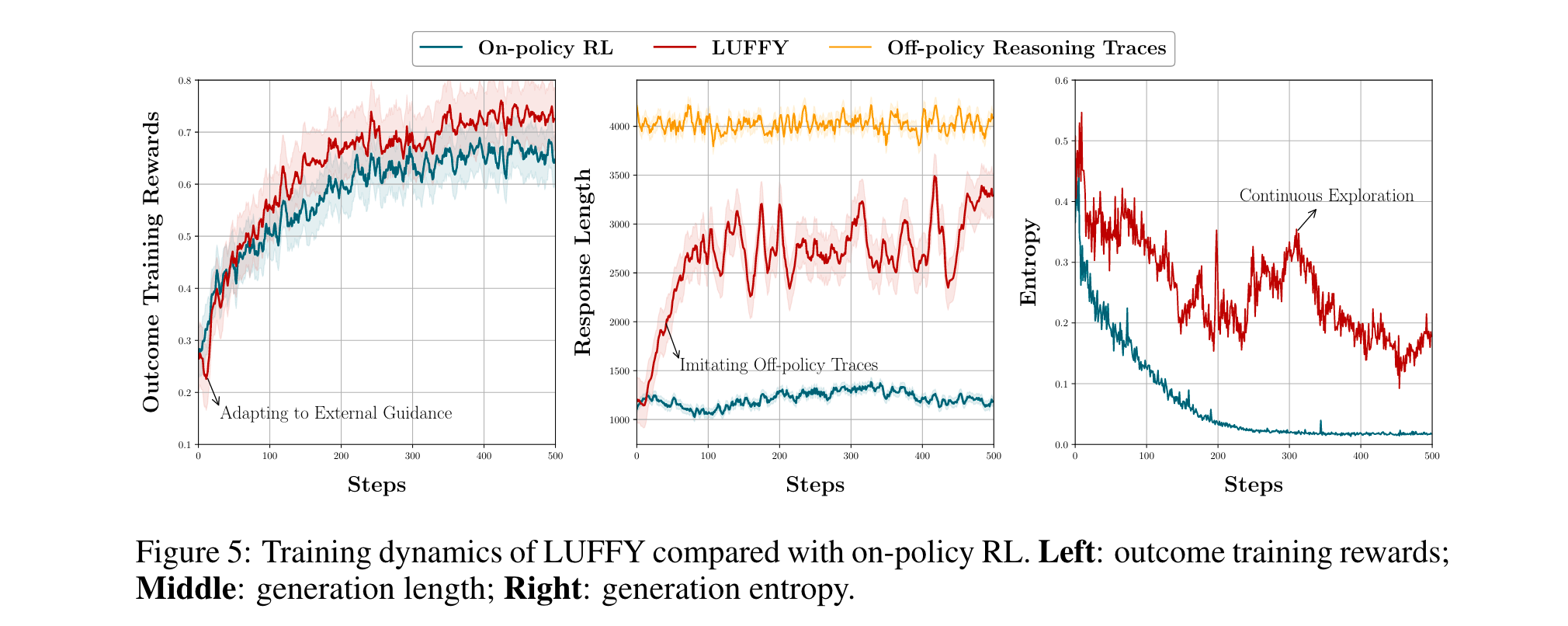
2. 训练动态分析: 在训练动态方面,LUFFY 展现出独特且高效的学习过程。起初,LUFFY 主要模仿离线策略轨迹,模型生成长度逐渐与离线策略推理轨迹对齐,这一阶段模仿主导,使得模型性能出现短暂下降,因为它需要适应外部指导。但随着训练推进,在线策略rollout逐渐发挥更大作用,模型在自身采样空间内进行独立探索,同时有效保留从离线策略演示中获得的经验。这种引导式探索为模型带来了比纯在线策略强化学习(RL)更大的优势,训练奖励不断增加,最终使 LUFFY 在模仿和探索之间达到动态平衡,实现更有效的离线策略学习。从训练熵值变化来看,LUFFY 在整个训练过程中始终保持比在线策略 RL 更高的熵值。在线策略 RL 的生成熵在约 200 步后迅速收敛至接近零,表明其策略趋于确定,探索潜力受限。而 LUFFY 较高的熵值使其能够持续探索那些虽不太确定但可能更优的策略,有助于发现和学习新的认知行为。在训练过程中,LUFFY 的熵值还会出现波动甚至偶尔增加,比如在 200 - 250 步之间,这反映了模型对低概率但关键动作(即关键令牌)的持续探索,使其能够跳出局部最优解,朝着更全局最优的方向收敛。
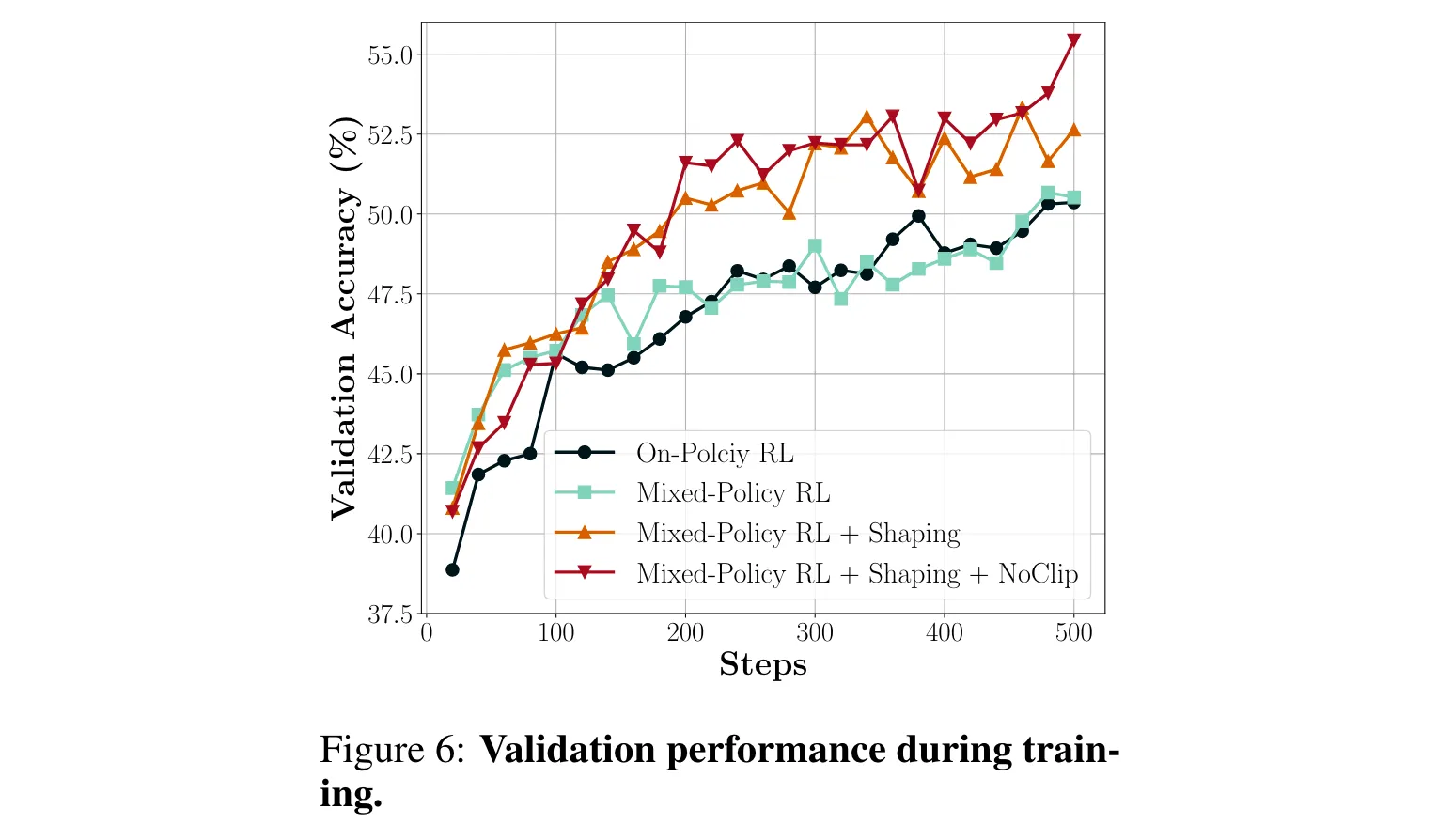
3. 消融研究:对LUFFY组件进行消融研究发现,策略塑造(policy shaping)和去除在线策略clip(NoClip)都对混合策略训练的最终性能有积极贡献。例如,同时使用这两个改进的模型比仅使用混合策略RL的模型在多个基准测试中有更高的平均得分(如在AIME 24、AIME 25等测试集中),而在没有离线策略指导下应用这些改进则无法提升性能。