天猫秘券网站怎么做微信朋友圈广告投放收费标准
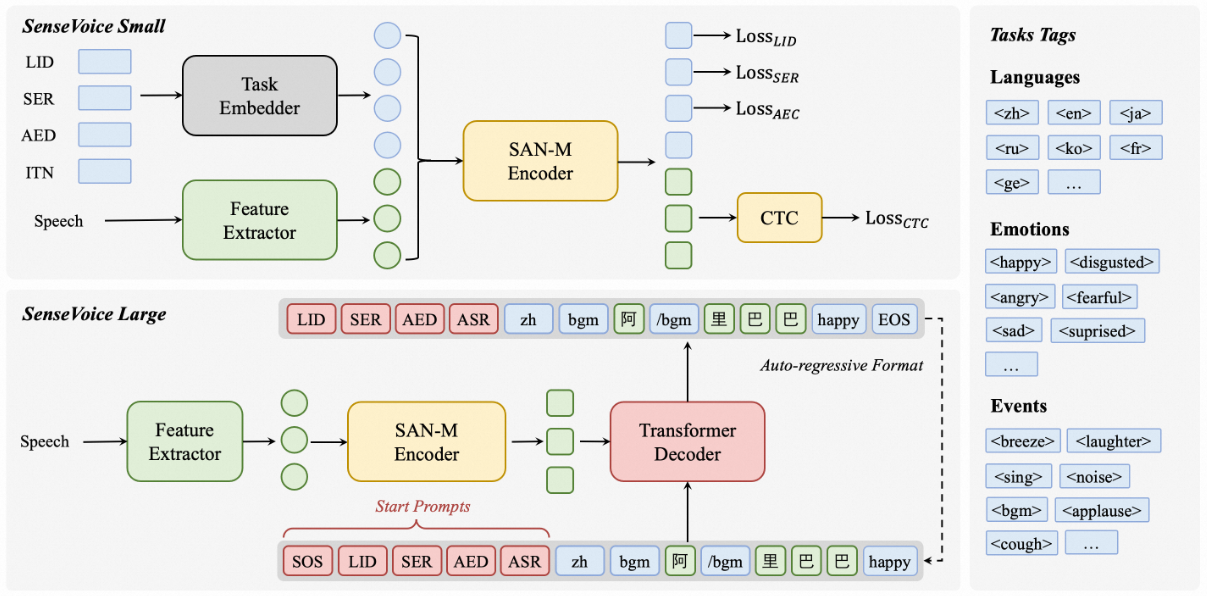
SenseVoiceSmall阿里开源大模型,SenseVoice 是具有音频理解能力的音频基础模型,包括语音识别(ASR)、语种识别(LID)、语音情感识别(SER)和声学事件分类(AEC)或声学事件检测(AED)。经过超过40万小时的数据训练,支持50多种语言
SenseVoice 专注于高精度多语言语音识别、情感辨识和音频事件检测
- 多语言识别: 采用超过 40 万小时数据训练,支持超过 50 种语言,识别效果上优于 Whisper 模型。
- 富文本识别:
- 具备优秀的情感识别,能够在测试数据上达到和超过目前最佳情感识别模型的效果。
- 支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件进行检测。
- 高效推理: SenseVoice-Small 模型采用非自回归端到端框架,推理延迟极低,10s 音频推理仅耗时 70ms,15 倍优于 Whisper-Large。
- 微调定制: 具备便捷的微调脚本与策略,方便用户根据业务场景修复长尾样本问题。
- 服务部署: 具有完整的服务部署链路,支持多并发请求,支持客户端语言有,python、c++、html、java 与 c# 等。
项目地址:https://github.com/FunAudioLLM/SenseVoice
以下为模型调用方法,输出的文字可能会包括一些表情,可以通过正则化的方式移除这些表情:
import pyaudio
import numpy as np
import wave
import osfrom funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocessmodel = AutoModel(model=r"D:\Downloads\SenseVoiceSmall",trust_remote_code=True,remote_code="./model.py", vad_model="fsmn-vad",vad_kwargs={"max_single_segment_time": 30000},device="cpu",use_itn=True,disable_update=True,disable_pbar = True,disable_log = True
)# 利用语音识别模型将音频数据转换为文本
def sound2text(audio_file):"""利用语音识别模型将音频数据转换为文本"""# enres = model.generate(input=audio_file,cache={},language="zh", # "zh", "en", "yue", "ja", "ko", "nospeech"use_itn=True,batch_size_s=60,merge_vad=True, #merge_length_s=15,)text = rich_transcription_postprocess(res[0]["text"])return textif __name__ == "__main__":# 读取音频文件audio_file = r"C:\Users\lvkong\Desktop\temp_wave\waving_20250513_135512_嗯鹅.wav"# 如果音频文件存在,直接读取if os.path.exists(audio_file):with wave.open(audio_file, 'rb') as wf:audio_data = wf.readframes(wf.getnframes())else:# 否则录制一段音频print("请开始说话(录音5秒钟)...")CHUNK = 1024FORMAT = pyaudio.paInt16CHANNELS = 1RATE = 16000RECORD_SECONDS = 5p = pyaudio.PyAudio()stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK)frames = []for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):data = stream.read(CHUNK)frames.append(data)stream.stop_stream()stream.close()p.terminate()# 保存录音with wave.open(audio_file, 'wb') as wf:wf.setnchannels(CHANNELS)wf.setsampwidth(p.get_sample_size(FORMAT))wf.setframerate(RATE)wf.writeframes(b''.join(frames))audio_data = b''.join(frames)print(f"录音已保存为 {audio_file}")# 利用语音识别模型将音频数据转换为文本text = sound2text(audio_file)# 输出文本print("识别结果:")print(text)正则化移除除中文外的其他内容:
# 提取字符串中的汉字
def extract_chinese(input_string):"""提取字符串中的汉字:param input_string: 原始字符串:return: 转换后的中文字符串"""# 使用正则表达式提取所有汉字chinese_characters = re.findall(r'[\u4e00-\u9fa5]', input_string)# 将汉字列表合并为字符串chinese_text = ''.join(chinese_characters)# 返回中文字符串return chinese_text此外,SenseVoiceSmall模型还支持pipeline的方式加载调用
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasksinference_pipeline = pipeline(task=Tasks.auto_speech_recognition,model=r'D:\Downloads\SenseVoiceSmall',model_revision="master",device="cuda:0",use_itn=True,disable_update=True)rec_result = inference_pipeline(r"D:\Project\Chat_Project\output_5.wav")
print(rec_result)