网站计费系统怎么做杭州网络推广公司
交叉熵损失函数(Cross-Entropy Loss)
交叉熵损失函数,涉及两个概念,一个是损失函数,一个是交叉熵。
首先,对于损失函数。在机器学习中,损失函数就是用来衡量我们模型的预测结果与真实结果之间“差距”的函数。这个差距越小,说明模型的表现越好;差距越大,说明模型表现越差。我们训练模型的目标,就是通过不断调整模型的参数,来最小化这个损失函数。以一个生活化的例子举例,想象一下你在教一个孩子识别猫和狗。孩子每次猜对或猜错,你都会给他一个“评分”。如果他猜对了,评分就很高(损失很小);如果他猜错了,评分就可能很低(损失很大)。
在明白完损失函数后,就要理解交叉熵了,在理解交叉熵之前我们又要了解何为熵。熵在信息论中是衡量一个随机变量不确定性(或者说信息量)的度量。不确定性越大,熵就越大。根据信息论中的香农定理,我们可以得出熵的计算公式为:
![]()
其中,P(xi)是事件xi发生的概率。- log(P(xi)) 表示信息量,根据公式我们可以知道信息量大小与概率成负相关,概率越小的时间其信息量越大,如飞机失事;概率越大的时间其信息量越小,如太阳从东边升起。
谈完熵之后,我们来开始理解何为交叉熵?
交叉熵是衡量两个概率分布之间“相似性”的度量。更准确地说,它衡量的是,当我们使用一个非真实的概率分布 Q 来表示一个真实的概率分布 P 时,所需要付出的“代价”或“信息量”。交叉熵的计算公式为:
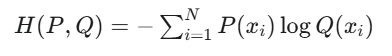
注意,这里的 P(xi) 通常是one-hot编码形式,即在分类问题中,只有真实类别对应的 P(xi) 为1,其他为0。
二分类交叉熵
在二分类问题中,当你的模型需要判断一个输入是A类还是B类(比如是猫还是狗,是垃圾邮件还是正常邮件)时,你会使用二分类交叉熵。
- 真实标签 (y): 通常用0或1表示。例如,猫是1,狗是0。
- 模型预测概率 (
): 模型输出的属于类别1的概率,通常通过Sigmoid激活函数得到,范围在0到1之间。
二分类交叉熵公式为:
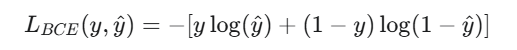
直观理解:
- 如果真实标签 y=1(比如是猫):损失函数变为 −log(
- 如果真实标签 y=0(比如是狗):损失函数变为 −log(1−
多分类交叉熵
当你的模型需要判断一个输入是N个类别中的哪一个(比如是猫、狗、还是鸟)时,你会使用多分类交叉熵。
- 真实标签 (y): 通常是one-hot编码。例如,猫是 [1,0,0],狗是 [0,1,0],鸟是 [0,0,1]。
- 模型预测概率 (
多分类交叉熵的公式为:
![]()
其中,N 是类别的数量,yi 是真实标签中第 i 个类别的指示(0或1),i 是模型预测第 i 个类别的概率。
直观理解:
- 由于真实标签 y 是one-hot编码,只有真实类别 k 对应的 yk 是1,其他 yi 都是0。所以,这个求和公式实际上只计算了真实类别对应的预测概率的负对数。
- 举例:如果真实标签是猫 [1,0,0],模型预测是 [0.8(猫),0.1(狗),0.1(鸟)]。 损失 =−(1⋅log(0.8)+0⋅log(0.1)+0⋅log(0.1))=−log(0.8)。 如果模型预测是 [0.1(猫),0.8(狗),0.1(鸟)]。 损失 =−(1⋅log(0.1)+0⋅log(0.8)+0⋅log(0.1))=−log(0.1)。 显然,−log(0.1) 比 −log(0.8) 要大很多,说明模型预测猫的概率很低时,损失会很大,这符合我们的直觉。
KL散度(Kullback-Leibler Divergence)
KL散度和交叉熵很像,只不过交叉熵是硬标签,KL散度是软标签,因此KL散度也称为相对熵,是衡量两个概率分布 P 和 Q 之间差异的非对称度量。它量化了当使用概率分布 Q 来近似概率分布 P 时所损失的信息量。KL散度主要用于拉近真实分布和近似分布的表达,去让近似分布尽可能接近真实分布,因为越近似,其除法越近于1,log()越接近于0。其计算公式为:
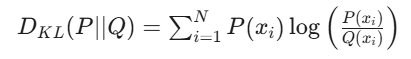
其中,P为真实分布 ,Q为近似分布 。我们将其展开,可得到以下公式:
![]()
可以看到当P(xi)为1时,这时就变成交叉熵了。
KL散度特性
- 非负性(涉及数学的非负性证明):KL(P∣∣Q)≥0(因为P和Q不相等的话,即P/Q>1),只有当 P 和 Q 是完全相同的分布时(此时P/Q = 1),KL(P∣∣Q)=0。
- 非对称性:KL(P∣∣Q) 不等于 KL(Q∣∣P) 。KL(P∣∣Q)是惩罚 Q 在 P 概率高的地方给出低概率。KL(Q∣∣P)惩罚 Q 在 P 概率低的地方给出高概率。
- 度量的是“信息损失”: 它衡量的是当你用 Q 来编码 P 时,额外需要多少比特的信息。
交叉熵损失函数和KL散度总结
- 交叉熵损失函数适用于分类任务,基于硬标签,目的是衡量模型预测的概率分布与真实标签的概率分布之间的“距离”。它的目标是让模型对真实类别的预测概率尽可能高。
- KL散度适用于衡量两个概率分布之间的差异,是非对称的,多用于概率模型,用于强制模型学习到的分布与某个先验分布接近,或衡量两个复杂分布之间的相似性。