微博内网站怎么做的新闻头条今日要闻国内新闻最新
本文介绍带训练参数的self-attention,即在transformer中使用的self-attention。
首先引入三个可训练的参数矩阵Wq, Wk, Wv,这三个矩阵用来将词向量投射(project)到query, key, value三个向量上。下面我们再定义几个变量:
import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)x_2 = inputs[1] # second input element
d_in = inputs.shape[1] # the input embedding size, d=3
d_out = 2 # the output embedding size, d=2
d_in是输入维度,d_out是输出维度,在transformer模型中d_in和d_out通常是相同的,但是为了更好地理解其中的计算过程,这里我们选择不同的d_in=3和d_out=2。
下面我们初始化三个参数矩阵:
torch.manual_seed(123)W_query = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
W_key = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
W_value = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
这里为了介绍方便,我们设置requires_grad=False, 如果是训练的话,我们要设置requires_grad=True。
下面我们计算第二个单词的query, key, value:
# @ 是矩阵乘法
query_2 = x_2 @ W_query
key_2 = x_2 @ W_key
value_2 = x_2 @ W_value
print(query_2)
# tensor([0.4306, 1.4551])
可以看到,经过参数矩阵project之后,query, key, value的维度已经转变成2。
下面我们通过计算第二个单词的上下文向量来介绍整个过程。
keys_2 = keys[1] # Python starts index at 0
attn_score_22 = query_2.dot(keys_2)
print(attn_score_22)
# tensor(1.8524)attn_scores_2 = query_2 @ keys.T # All attention scores for given query
print(attn_scores_2)
# tensor([1.2705, 1.8524, 1.8111, 1.0795, 0.5577, 1.5440])d_k = keys.shape[1]
attn_weights_2 = torch.softmax(attn_scores_2 / d_k**0.5, dim=-1)
print(attn_weights_2)
# tensor([0.1500, 0.2264, 0.2199, 0.1311, 0.0906, 0.1820])context_vec_2 = attn_weights_2 @ values
print(context_vec_2)
# tensor([0.3061, 0.8210])
self-attention又叫做scaled-dot product attention,正是因为在求attention weight的时候对attention score做了除以向量维度的平方根来做缩放(scale)。
为什么要除以向量维度的平方根?
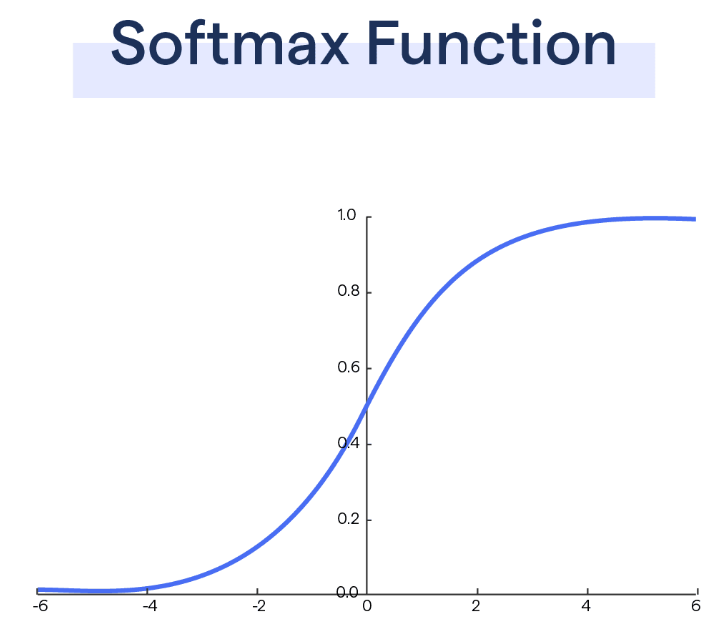
除以向量维度的平方根主要是避免太小的梯度以提升训练性能。对于像GPT这样的大型LLM模型,它的向量维度通常会超过上千,那么向量和向量之间的点乘结果就会非常大。而我们知道,对于Softmax函数,如果输入值很大或者很小的话,它是非常平缓的,非常平缓也就意味着梯度很小以至于接近于0。这就导致训练中的反向传播时,会出现非常小的梯度,从而引发梯度消失问题,极大地降低了模型学习的速度,引发训练停滞。下面是Softmax的函数图像:
怎么理解query, key, value?
query, key, value是借用数据库信息提取领域的概念。query用来搜索信息,key用来存储信息,value用来提取信息。
query:类似于数据库中的查找。它代表着当前模型关心的单词。query用来探测输入序列中的其他单词,去决定当前单词和其他单词的相关性。
key:类似于数据库中的索引。attention机制中,每个单词都有自己的key,这些key用来和query匹配。
value:类似于数据库中key-value对中的值。它代表着输入序列中单词的实际内容或者单词的实际表示。当query探测发现和某些key最相关,它就会提取跟这些key关联的value。
下面实现一个self-attention类:
import torch.nn as nnclass SelfAttention_v1(nn.Module):def __init__(self, d_in, d_out):super().__init__()self.W_query = nn.Parameter(torch.rand(d_in, d_out))self.W_key = nn.Parameter(torch.rand(d_in, d_out))self.W_value = nn.Parameter(torch.rand(d_in, d_out))def forward(self, x):keys = x @ self.W_keyqueries = x @ self.W_queryvalues = x @ self.W_valueattn_scores = queries @ keys.T # omegaattn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)context_vec = attn_weights @ valuesreturn context_vectorch.manual_seed(123)
sa_v1 = SelfAttention_v1(d_in, d_out)
print(sa_v1(inputs))# 输出:
# tensor([[0.2996, 0.8053],
# [0.3061, 0.8210],
# [0.3058, 0.8203],
# [0.2948, 0.7939],
# [0.2927, 0.7891],
# [0.2990, 0.8040]], grad_fn=<MmBackward0>)
可以看到,输出结果的第二行和上面单独计算第二个单词的上下文向量是一致的。
我们可以使用nn.Linear来改进上面的self-attention类。相比于手动实现nn.Parameter(torch.rand(...)),nn.Linear会优化权重的初始化,因此会使模型训练更稳定有效。
class SelfAttention_v2(nn.Module):def __init__(self, d_in, d_out, qkv_bias=False):super().__init__()self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)def forward(self, x):keys = self.W_key(x)queries = self.W_query(x)values = self.W_value(x)attn_scores = queries @ keys.Tattn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)context_vec = attn_weights @ valuesreturn context_vectorch.manual_seed(789)
sa_v2 = SelfAttention_v2(d_in, d_out)
print(sa_v2(inputs))# 输出:
# tensor([[-0.0739, 0.0713],
# [-0.0748, 0.0703],
# [-0.0749, 0.0702],
# [-0.0760, 0.0685],
# [-0.0763, 0.0679],
# [-0.0754, 0.0693]], grad_fn=<MmBackward0>)
由于SelfAttention_v1 和 SelfAttention_v2使用了不同的权重初始化方法,因此它们的输出结果是不一样的。
参考资料:
《Build a Large Language Model from Scratch》