烟台商机互联做网站吗谷歌关键词搜索
目录
摘要
Abstract
DINOv2
背景与动机
核心贡献
高质量数据集构建LVD-142M
改进的自监督学习框架
高效训练与模型蒸馏
实验
代码
总结
摘要
DINOv2 是一种基于 DINO 的大规模视觉模型,采用 Vision Transformer 架构,并在数据构建、训练策略和特征学习机制上进行了优化。该模型解决了传统视觉模型依赖监督学习、数据规模与质量受限以及特征鲁棒性不足的问题,通过自监督学习、构建高质量数据集和多尺度特征融合等改进提升了性能。DINOv2 在跨任务泛化能力、训练与推理效率以及医学与遥感应用方面表现出色,其教师-学生架构、多尺度特征融合和正则化技术等设计增强了模型性能和稳定性。此外,DINOv2 还通过模型蒸馏降低了计算成本。它为通用视觉模型的发展提供了无需微调的解决方案,其开源代码和预训练模型进一步推动了应用探索。
Abstract
DINOv2 is a large-scale visual model based on DINO, utilizing the Vision Transformer architecture and optimized in terms of data construction, training strategies, and feature learning mechanisms. The model addresses the issues of traditional visual models, such as dependence on supervised learning, limitations in data scale and quality, and insufficient feature robustness. It enhances performance through improvements like self-supervised learning, the construction of high-quality datasets, and multi-scale feature fusion. DINOv2 excels in cross-task generalization, training and inference efficiency, as well as applications in medical imaging and remote sensing. Its teacher-student architecture, multi-scale feature fusion, and regularization techniques contribute to improved model performance and stability. Additionally, DINOv2 reduces computational costs through model distillation. It provides a solution for the development of universal visual models without the need for fine-tuning, and its open-source code and pre-trained models further promote application exploration.
DINOv2
代码链接:GitHub - facebookresearch/dinov2: PyTorch code and models for the DINOv2 self-supervised learning method.

背景与动机
自然语言处理通过大规模预训练模型(如BERT、GPT)实现了通用特征学习,而计算机视觉领域长期依赖监督学习或文本引导的预训练,如:CLIP。但文本监督可能忽略图像局部信息(如物体位置、纹理细节),且人工标注成本高昂,限制了模型的扩展性。
自监督方法仅依赖图像自身信息学习特征,理论上能捕获更丰富的视觉语义。然而,现有方法受限于小规模数据集或低质量数据,难以扩展到更大规模。
核心贡献
高质量数据集构建LVD-142M
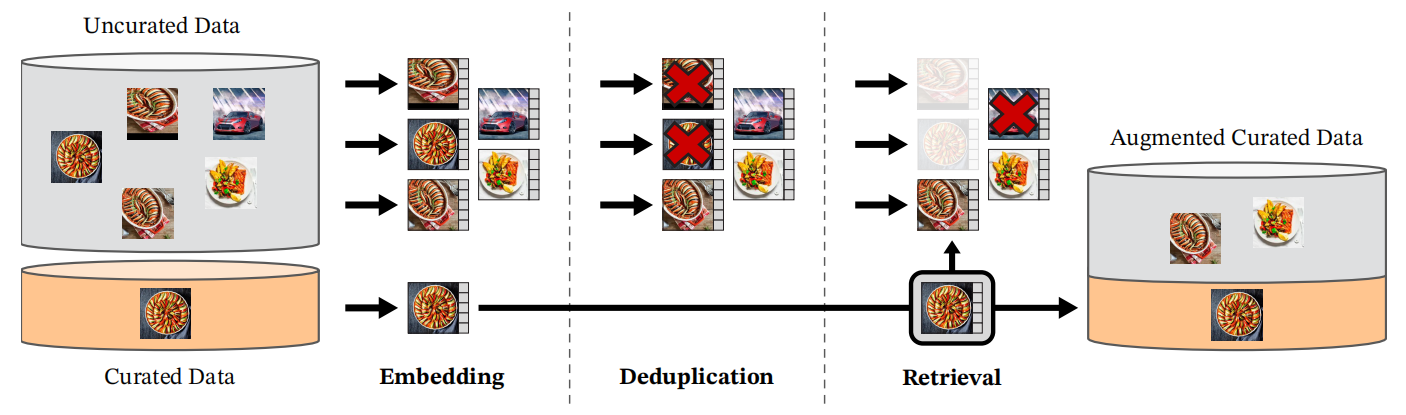
DINOv2通过自动化流水线构建了包含1.42亿张图像的大规模数据集LVD-142M,关键步骤包括:
- 数据源整合:结合公开数据集(如ImageNet)和网络爬取数据,后者经过安全过滤、NSFW内容剔除及人脸模糊处理。
- 去重与清洗:使用Meta的《A self-supervised descriptor for image copy detection》方法进行图像相似度检测,去除重复和低质量样本。
- 自监督检索增强:通过ViT-H/16模型计算图像嵌入,利用k-means聚类和Faiss库高效检索相似图像,结合人工视觉检查确保多样性。
- 硬件加速:基于20节点计算集群,整个数据处理仅需两天完成。
改进的自监督学习框架
DINOv2融合多种自监督方法,优化特征学习过程:
多目标损失函数
- 图像级目标(DINO损失):通过教师-学生网络架构,最大化同一图像不同裁剪视图的特征一致性,使用交叉熵损失优化。
- Patch级目标(iBOT损失):随机遮盖部分图像块,要求学生网络预测教师网络对应块的特征,增强局部建模能力。
- 解绑头权重:实验发现,图像级与Patch级任务共享投影头会导致欠拟合,分离两者参数可提升性能。
正则化与优化
- Sinkhorn-Knopp中心化:替代传统softmax,提升教师网络输出的稳定性。
- KoLeo正则化:基于Kozachenko-Leonenko熵估计器,鼓励特征在批次内均匀分布,避免特征坍塌。
- 高分辨率训练阶段:预训练末期短暂提升图像分辨率至518×518,增强对小目标的捕捉能力。
高效训练与模型蒸馏
训练加速技术
- FlashAttention优化:减少注意力层显存占用,提升计算效率。
- 序列打包 Sequence Packing:合并不同分辨率图像的词符序列,通过掩码机制实现并行计算,加速训练。
- 全分片数据并行 FSDP:分布式训练策略,降低显存需求。
模型蒸馏
从11亿参数的ViT-g/14大模型蒸馏出更小的ViT模型,保留大模型性能的同时降低推理成本。
实验
性能优势:DINOv2在ImageNet分类、ADE20K分割、细粒度分类等任务上超越OpenCLIP和iBOT等基线模型,接近监督学习性能。
扩展性验证:模型性能随数据规模和参数量的增加持续提升,证明自监督学习的可扩展性。
跨任务泛化:特征可直接用于单目深度估计、生物医学图像分析等任务,无需微调即达到SOTA结果。
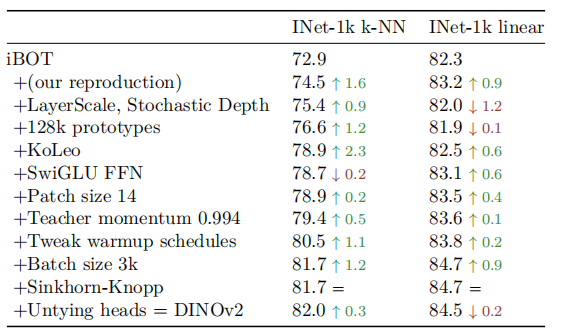
iBOT和DINOv2差异训练消融实验:
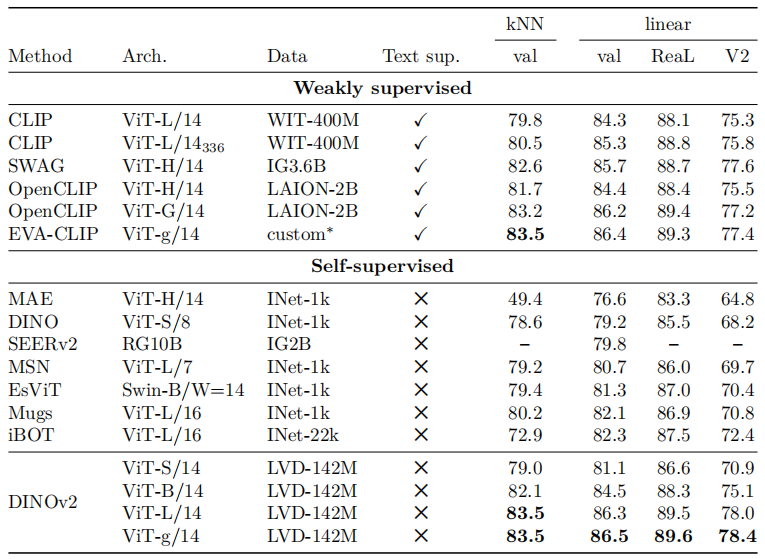
预训练数据集的消融:

ImageNet-1K上评估:
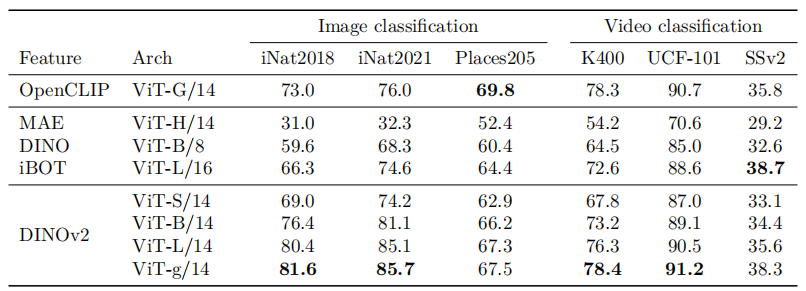
其他数据集评估:
代码
from functools import partial
import math
import logging
from typing import Sequence, Tuple, Union, Callableimport torch
import torch.nn as nn
import torch.utils.checkpoint
from torch.nn.init import trunc_normal_from dinov2.layers import Mlp, PatchEmbed, SwiGLUFFNFused, MemEffAttention, NestedTensorBlock as Blocklogger = logging.getLogger("dinov2")def named_apply(fn: Callable, module: nn.Module, name="", depth_first=True, include_root=False) -> nn.Module:if not depth_first and include_root:fn(module=module, name=name)for child_name, child_module in module.named_children():child_name = ".".join((name, child_name)) if name else child_namenamed_apply(fn=fn, module=child_module, name=child_name, depth_first=depth_first, include_root=True)if depth_first and include_root:fn(module=module, name=name)return moduleclass BlockChunk(nn.ModuleList):def forward(self, x):for b in self:x = b(x)return xclass DinoVisionTransformer(nn.Module):def __init__(self,img_size=224,patch_size=16,in_chans=3,embed_dim=768,depth=12,num_heads=12,mlp_ratio=4.0,qkv_bias=True,ffn_bias=True,proj_bias=True,drop_path_rate=0.0,drop_path_uniform=False,init_values=None, # for layerscale: None or 0 => no layerscaleembed_layer=PatchEmbed,act_layer=nn.GELU,block_fn=Block,ffn_layer="mlp",block_chunks=1,num_register_tokens=0,interpolate_antialias=False,interpolate_offset=0.1,):"""Args:img_size (int, tuple): input image sizepatch_size (int, tuple): patch sizein_chans (int): number of input channelsembed_dim (int): embedding dimensiondepth (int): depth of transformernum_heads (int): number of attention headsmlp_ratio (int): ratio of mlp hidden dim to embedding dimqkv_bias (bool): enable bias for qkv if Trueproj_bias (bool): enable bias for proj in attn if Trueffn_bias (bool): enable bias for ffn if Truedrop_path_rate (float): stochastic depth ratedrop_path_uniform (bool): apply uniform drop rate across blocksweight_init (str): weight init schemeinit_values (float): layer-scale init valuesembed_layer (nn.Module): patch embedding layeract_layer (nn.Module): MLP activation layerblock_fn (nn.Module): transformer block classffn_layer (str): "mlp", "swiglu", "swiglufused" or "identity"block_chunks: (int) split block sequence into block_chunks units for FSDP wrapnum_register_tokens: (int) number of extra cls tokens (so-called "registers")interpolate_antialias: (str) flag to apply anti-aliasing when interpolating positional embeddingsinterpolate_offset: (float) work-around offset to apply when interpolating positional embeddings"""super().__init__()norm_layer = partial(nn.LayerNorm, eps=1e-6)self.num_features = self.embed_dim = embed_dim # num_features for consistency with other modelsself.num_tokens = 1self.n_blocks = depthself.num_heads = num_headsself.patch_size = patch_sizeself.num_register_tokens = num_register_tokensself.interpolate_antialias = interpolate_antialiasself.interpolate_offset = interpolate_offsetself.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)num_patches = self.patch_embed.num_patchesself.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))assert num_register_tokens >= 0self.register_tokens = (nn.Parameter(torch.zeros(1, num_register_tokens, embed_dim)) if num_register_tokens else None)if drop_path_uniform is True:dpr = [drop_path_rate] * depthelse:dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay ruleif ffn_layer == "mlp":logger.info("using MLP layer as FFN")ffn_layer = Mlpelif ffn_layer == "swiglufused" or ffn_layer == "swiglu":logger.info("using SwiGLU layer as FFN")ffn_layer = SwiGLUFFNFusedelif ffn_layer == "identity":logger.info("using Identity layer as FFN")def f(*args, **kwargs):return nn.Identity()ffn_layer = felse:raise NotImplementedErrorblocks_list = [block_fn(dim=embed_dim,num_heads=num_heads,mlp_ratio=mlp_ratio,qkv_bias=qkv_bias,proj_bias=proj_bias,ffn_bias=ffn_bias,drop_path=dpr[i],norm_layer=norm_layer,act_layer=act_layer,ffn_layer=ffn_layer,init_values=init_values,)for i in range(depth)]if block_chunks > 0:self.chunked_blocks = Truechunked_blocks = []chunksize = depth // block_chunksfor i in range(0, depth, chunksize):# this is to keep the block index consistent if we chunk the block listchunked_blocks.append([nn.Identity()] * i + blocks_list[i : i + chunksize])self.blocks = nn.ModuleList([BlockChunk(p) for p in chunked_blocks])else:self.chunked_blocks = Falseself.blocks = nn.ModuleList(blocks_list)self.norm = norm_layer(embed_dim)self.head = nn.Identity()self.mask_token = nn.Parameter(torch.zeros(1, embed_dim))self.init_weights()def init_weights(self):trunc_normal_(self.pos_embed, std=0.02)nn.init.normal_(self.cls_token, std=1e-6)if self.register_tokens is not None:nn.init.normal_(self.register_tokens, std=1e-6)named_apply(init_weights_vit_timm, self)def interpolate_pos_encoding(self, x, w, h):previous_dtype = x.dtypenpatch = x.shape[1] - 1N = self.pos_embed.shape[1] - 1if npatch == N and w == h:return self.pos_embedpos_embed = self.pos_embed.float()class_pos_embed = pos_embed[:, 0]patch_pos_embed = pos_embed[:, 1:]dim = x.shape[-1]w0 = w // self.patch_sizeh0 = h // self.patch_sizeM = int(math.sqrt(N)) # Recover the number of patches in each dimensionassert N == M * Mkwargs = {}if self.interpolate_offset:# Historical kludge: add a small number to avoid floating point error in the interpolation, see https://github.com/facebookresearch/dino/issues/8# Note: still needed for backward-compatibility, the underlying operators are using both output size and scale factorssx = float(w0 + self.interpolate_offset) / Msy = float(h0 + self.interpolate_offset) / Mkwargs["scale_factor"] = (sx, sy)else:# Simply specify an output size instead of a scale factorkwargs["size"] = (w0, h0)patch_pos_embed = nn.functional.interpolate(patch_pos_embed.reshape(1, M, M, dim).permute(0, 3, 1, 2),mode="bicubic",antialias=self.interpolate_antialias,**kwargs,)assert (w0, h0) == patch_pos_embed.shape[-2:]patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)return torch.cat((class_pos_embed.unsqueeze(0), patch_pos_embed), dim=1).to(previous_dtype)def prepare_tokens_with_masks(self, x, masks=None):B, nc, w, h = x.shapex = self.patch_embed(x)if masks is not None:x = torch.where(masks.unsqueeze(-1), self.mask_token.to(x.dtype).unsqueeze(0), x)x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1)x = x + self.interpolate_pos_encoding(x, w, h)if self.register_tokens is not None:x = torch.cat((x[:, :1],self.register_tokens.expand(x.shape[0], -1, -1),x[:, 1:],),dim=1,)return xdef forward_features_list(self, x_list, masks_list):x = [self.prepare_tokens_with_masks(x, masks) for x, masks in zip(x_list, masks_list)]for blk in self.blocks:x = blk(x)all_x = xoutput = []for x, masks in zip(all_x, masks_list):x_norm = self.norm(x)output.append({"x_norm_clstoken": x_norm[:, 0],"x_norm_regtokens": x_norm[:, 1 : self.num_register_tokens + 1],"x_norm_patchtokens": x_norm[:, self.num_register_tokens + 1 :],"x_prenorm": x,"masks": masks,})return outputdef forward_features(self, x, masks=None):if isinstance(x, list):return self.forward_features_list(x, masks)x = self.prepare_tokens_with_masks(x, masks)for blk in self.blocks:x = blk(x)x_norm = self.norm(x)return {"x_norm_clstoken": x_norm[:, 0],"x_norm_regtokens": x_norm[:, 1 : self.num_register_tokens + 1],"x_norm_patchtokens": x_norm[:, self.num_register_tokens + 1 :],"x_prenorm": x,"masks": masks,}def _get_intermediate_layers_not_chunked(self, x, n=1):x = self.prepare_tokens_with_masks(x)# If n is an int, take the n last blocks. If it's a list, take themoutput, total_block_len = [], len(self.blocks)blocks_to_take = range(total_block_len - n, total_block_len) if isinstance(n, int) else nfor i, blk in enumerate(self.blocks):x = blk(x)if i in blocks_to_take:output.append(x)assert len(output) == len(blocks_to_take), f"only {len(output)} / {len(blocks_to_take)} blocks found"return outputdef _get_intermediate_layers_chunked(self, x, n=1):x = self.prepare_tokens_with_masks(x)output, i, total_block_len = [], 0, len(self.blocks[-1])# If n is an int, take the n last blocks. If it's a list, take themblocks_to_take = range(total_block_len - n, total_block_len) if isinstance(n, int) else nfor block_chunk in self.blocks:for blk in block_chunk[i:]: # Passing the nn.Identity()x = blk(x)if i in blocks_to_take:output.append(x)i += 1assert len(output) == len(blocks_to_take), f"only {len(output)} / {len(blocks_to_take)} blocks found"return outputdef get_intermediate_layers(self,x: torch.Tensor,n: Union[int, Sequence] = 1, # Layers or n last layers to takereshape: bool = False,return_class_token: bool = False,norm=True,) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]]]:if self.chunked_blocks:outputs = self._get_intermediate_layers_chunked(x, n)else:outputs = self._get_intermediate_layers_not_chunked(x, n)if norm:outputs = [self.norm(out) for out in outputs]class_tokens = [out[:, 0] for out in outputs]outputs = [out[:, 1 + self.num_register_tokens :] for out in outputs]if reshape:B, _, w, h = x.shapeoutputs = [out.reshape(B, w // self.patch_size, h // self.patch_size, -1).permute(0, 3, 1, 2).contiguous()for out in outputs]if return_class_token:return tuple(zip(outputs, class_tokens))return tuple(outputs)def forward(self, *args, is_training=False, **kwargs):ret = self.forward_features(*args, **kwargs)if is_training:return retelse:return self.head(ret["x_norm_clstoken"])def init_weights_vit_timm(module: nn.Module, name: str = ""):"""ViT weight initialization, original timm impl (for reproducibility)"""if isinstance(module, nn.Linear):trunc_normal_(module.weight, std=0.02)if module.bias is not None:nn.init.zeros_(module.bias)def vit_small(patch_size=16, num_register_tokens=0, **kwargs):model = DinoVisionTransformer(patch_size=patch_size,embed_dim=384,depth=12,num_heads=6,mlp_ratio=4,block_fn=partial(Block, attn_class=MemEffAttention),num_register_tokens=num_register_tokens,**kwargs,)return modeldef vit_base(patch_size=16, num_register_tokens=0, **kwargs):model = DinoVisionTransformer(patch_size=patch_size,embed_dim=768,depth=12,num_heads=12,mlp_ratio=4,block_fn=partial(Block, attn_class=MemEffAttention),num_register_tokens=num_register_tokens,**kwargs,)return modeldef vit_large(patch_size=16, num_register_tokens=0, **kwargs):model = DinoVisionTransformer(patch_size=patch_size,embed_dim=1024,depth=24,num_heads=16,mlp_ratio=4,block_fn=partial(Block, attn_class=MemEffAttention),num_register_tokens=num_register_tokens,**kwargs,)return modeldef vit_giant2(patch_size=16, num_register_tokens=0, **kwargs):"""Close to ViT-giant, with embed-dim 1536 and 24 heads => embed-dim per head 64"""model = DinoVisionTransformer(patch_size=patch_size,embed_dim=1536,depth=40,num_heads=24,mlp_ratio=4,block_fn=partial(Block, attn_class=MemEffAttention),num_register_tokens=num_register_tokens,**kwargs,)return model输入图像:

输出特征:

总结
DINOv2是Meta AI基于自监督ViT模型DINO和iBOT改进的大规模视觉预训练模型,通过构建1.42亿张图像的LVD-142M数据集并采用创新的多尺度特征融合和混合分辨率训练策略,显著提升了视觉特征的泛化能力。该模型在图像分类、分割和深度估计等任务上接近监督学习性能,同时通过FlashAttention和模型蒸馏技术实现了高效训练与推理。DINOv2的成功验证了大规模自监督学习的潜力,为减少对标注数据的依赖提供了可行方案,其数据构建方法和特征学习机制为未来通用视觉模型的发展指明了方向,特别是在医疗影像和遥感等专业领域的应用展现了强大的跨任务迁移能力。