建站公司有哪些服务营销战略
Key-Value类型:
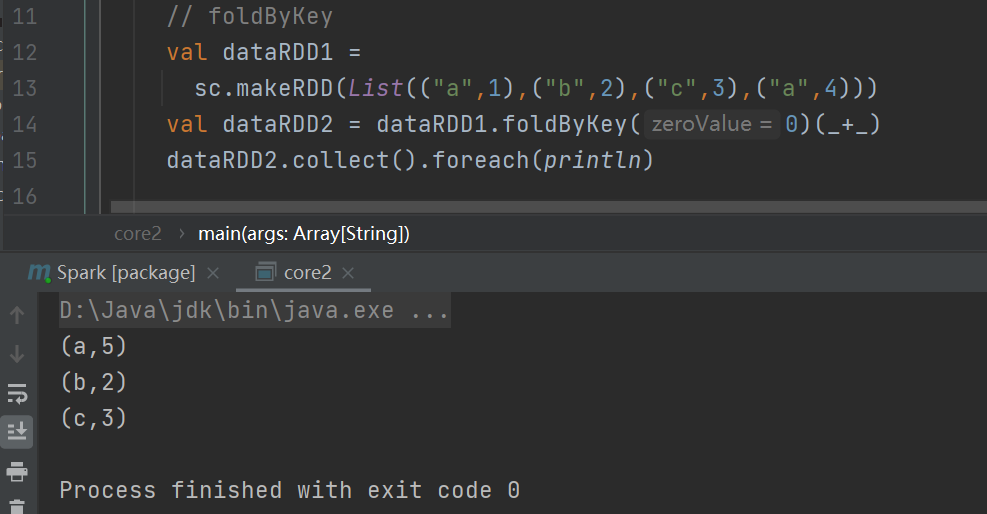
foldByKey
当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey
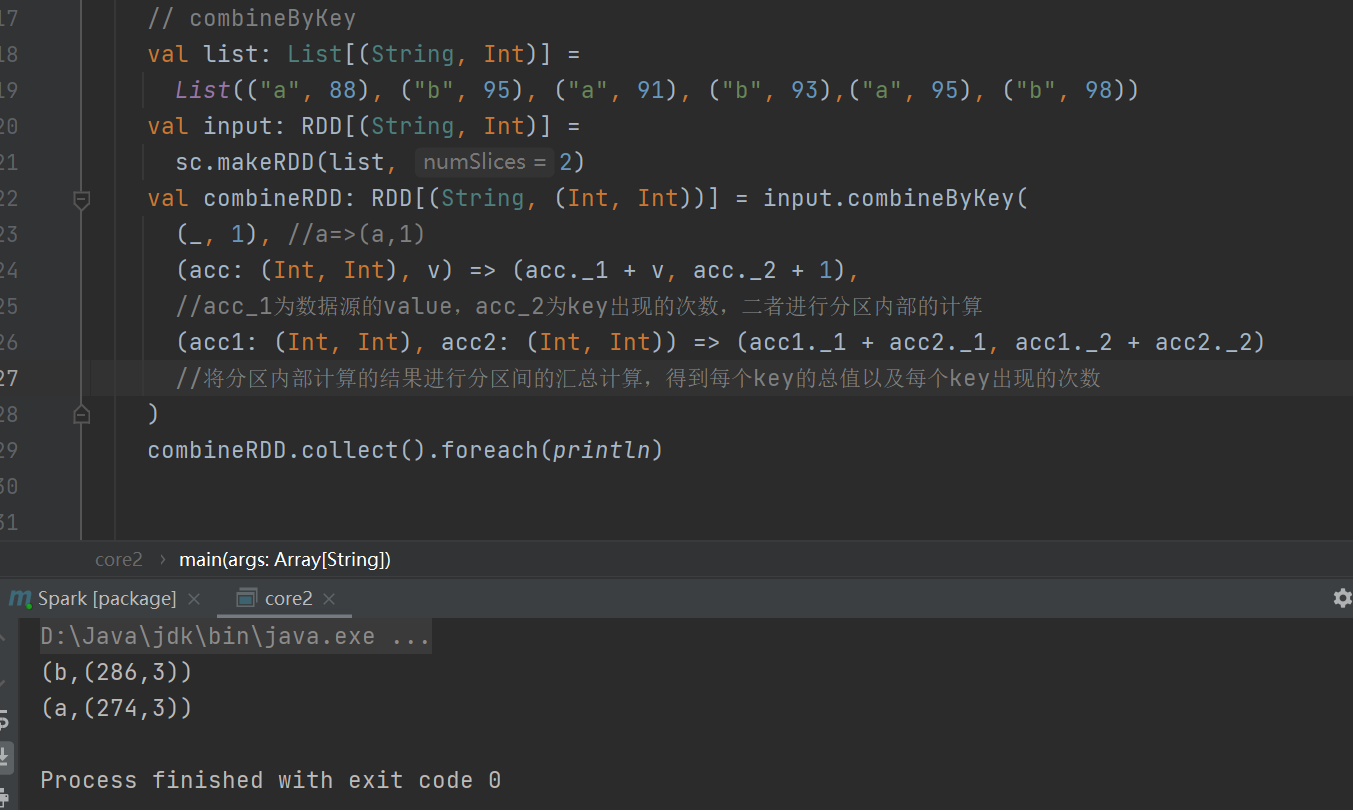
combineByKey
最通用的对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。类似于aggregate(),combineByKey()允许用户返回值的类型与输入不一致。
示例:现有数据 List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)),求每个key的总值及每个key对应键值对的个数
reduceByKey、foldByKey、aggregateByKey、combineByKey 的区别:
reduceByKey: 相同 key 的第一个数据不进行任何计算,分区内和分区间计算规则相同
FoldByKey: 每一个key 对应的数据和初始值进行分区内计算,分区内和分区间计算规则相同
AggregateByKey:每一个 key 对应的数据和初始值进行分区内计算,分区内和分区间计算规则可以不相同
CombineByKey:当计算时,发现数据结构不满足要求时,可以让第一个数据转换结构。分区
内和分区间计算规则不相同。
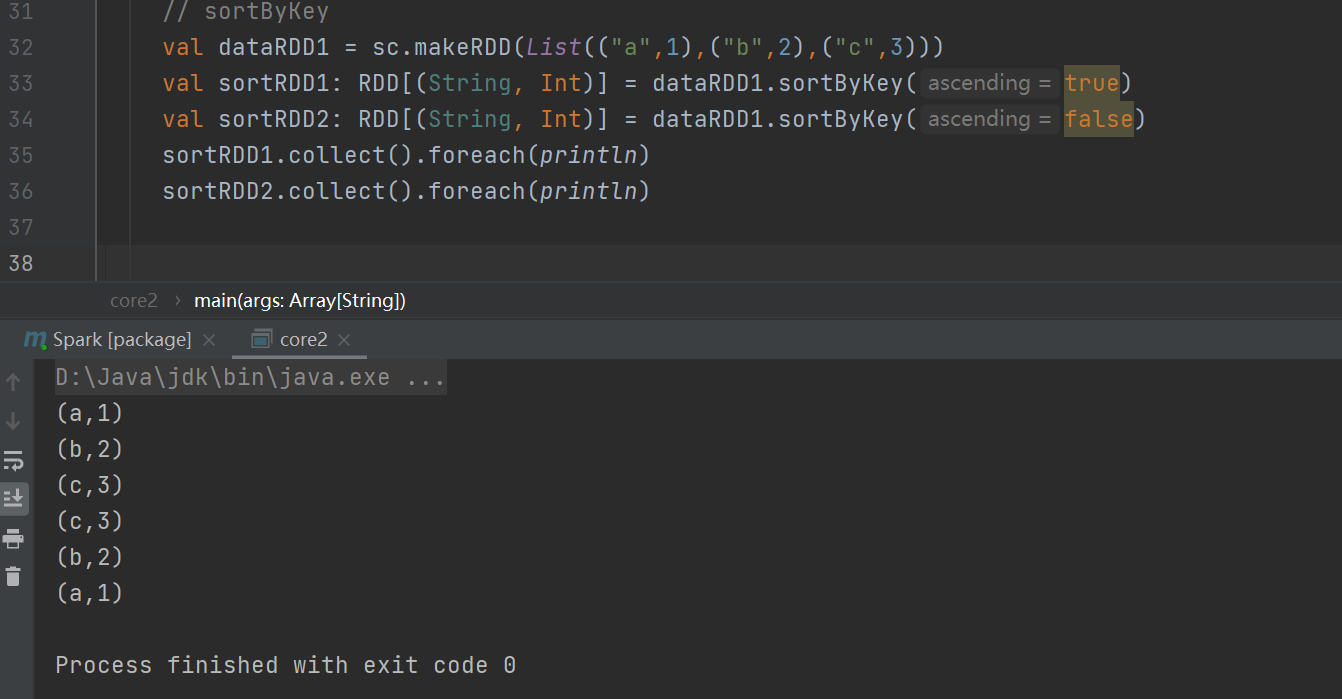
sortByKey
根据键值对中的键进行排序,支持升序和降序排列。(布尔值决定升序(true)或降序(false)。)
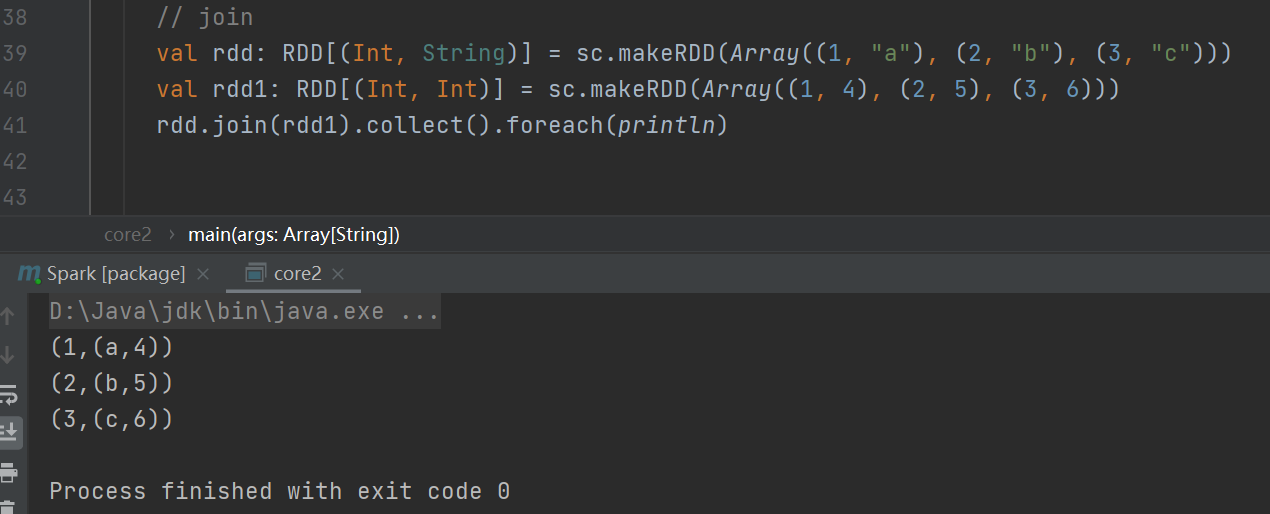
join
join操作:返回两个RDD中相同键对应的所有元素连接在一起,结果以键开头,右边是嵌套的值。
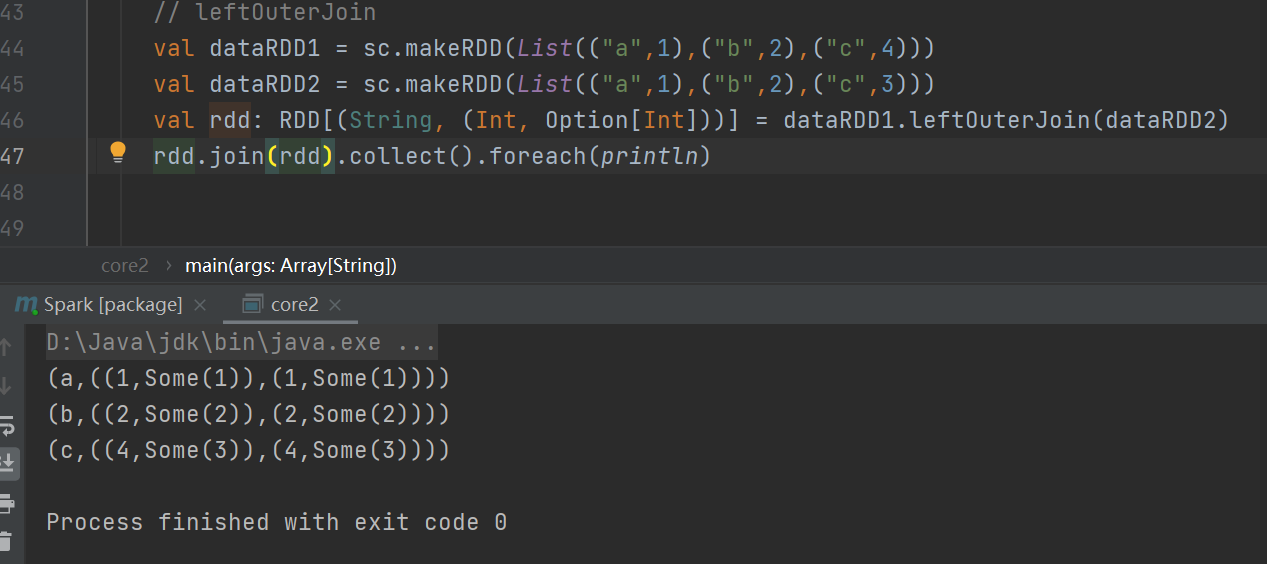
leftOuterJoin
类似于 SQL 语句的左外连接
左外连接和右外连接:
leftOuterJoin操作:类似于SQL中的左外连接,以元RDD为主。
rightOuterJoin操作:类似于SQL中的右外连接,以参数RDD为主。
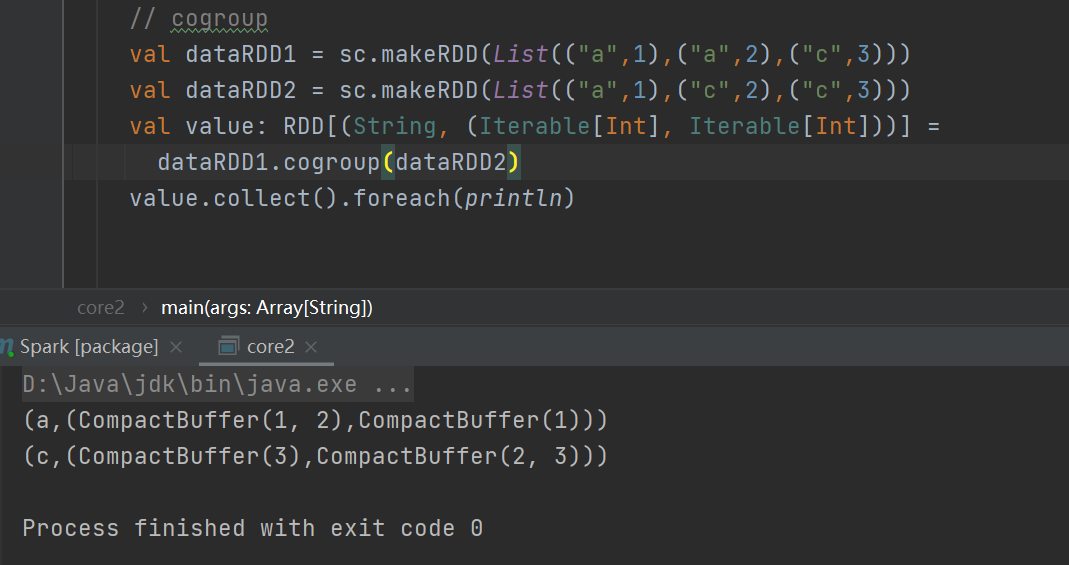
cogroup
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的 RDD
RDD行动算子
行动算子就是会触发action的算子,触发action的含义就是真正的计算数据。
转换算子与行动算子的区别:
转换算子:不立即执行,只有在遇到行动算子时才会触发计算。
行动算子:立即执行计算,返回具体值或触发实际的计算过程
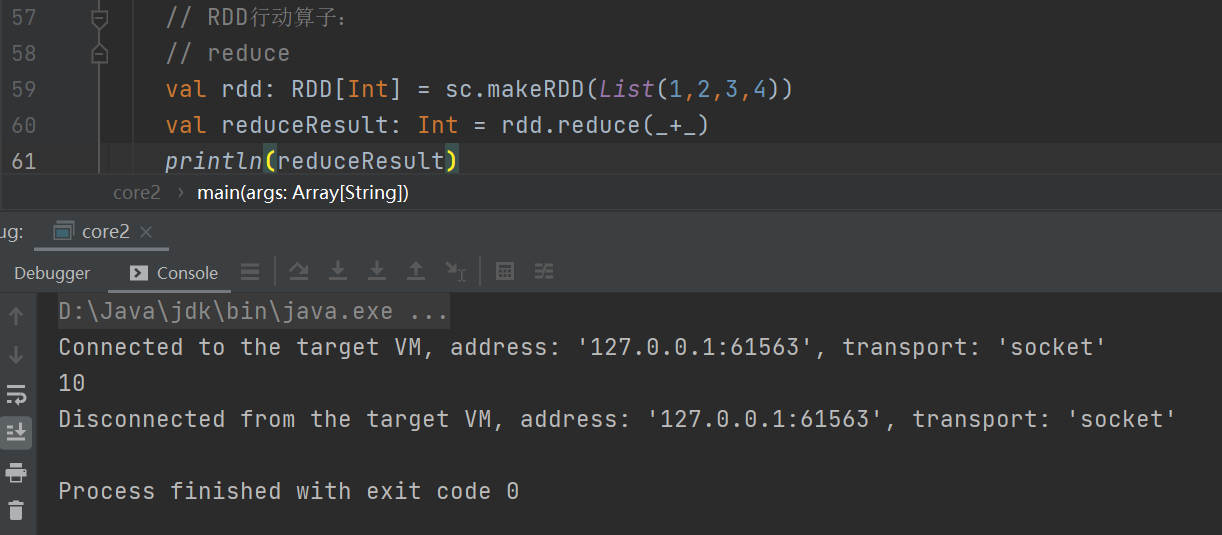
reduce
聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据
collect
函数签名
def collect(): Array[T]
函数说明
在驱动程序中,以数组 Array 的形式返回数据集的所有元素
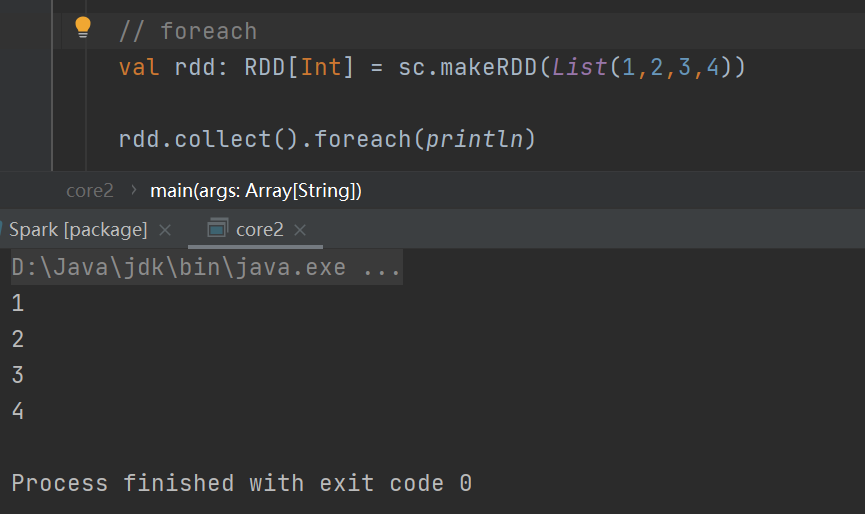
foreach
分布式遍历 RDD 中的每一个元素,调用指定函数
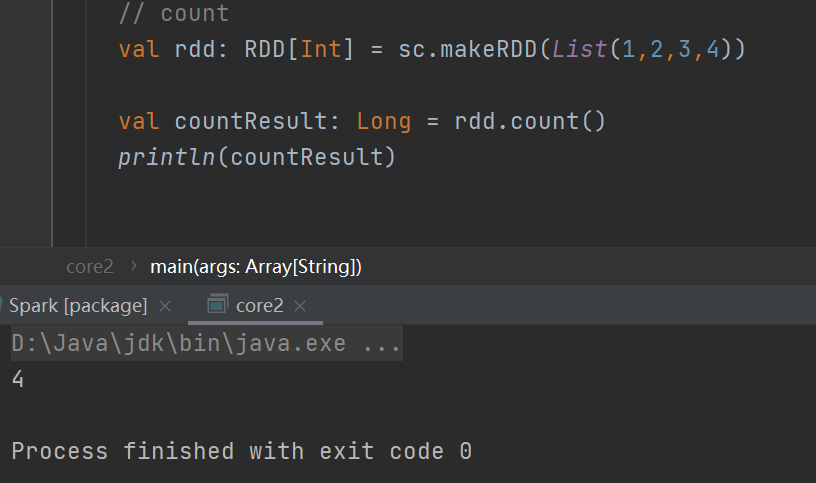
count
返回 RDD 中元素的个数
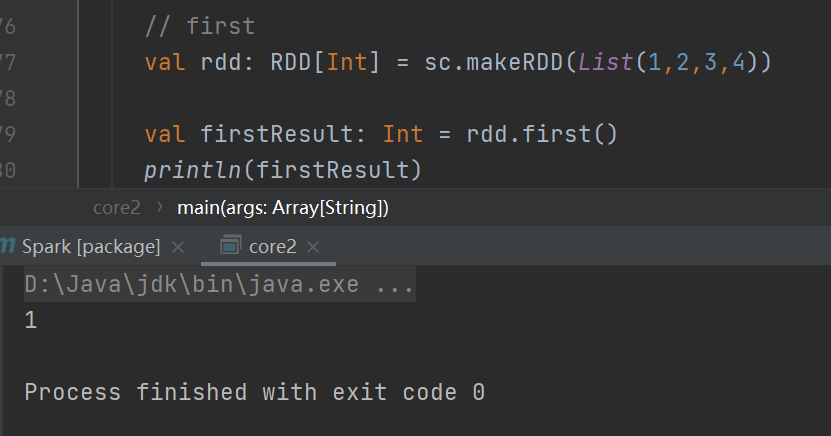
first
返回 RDD 中的第一个元素
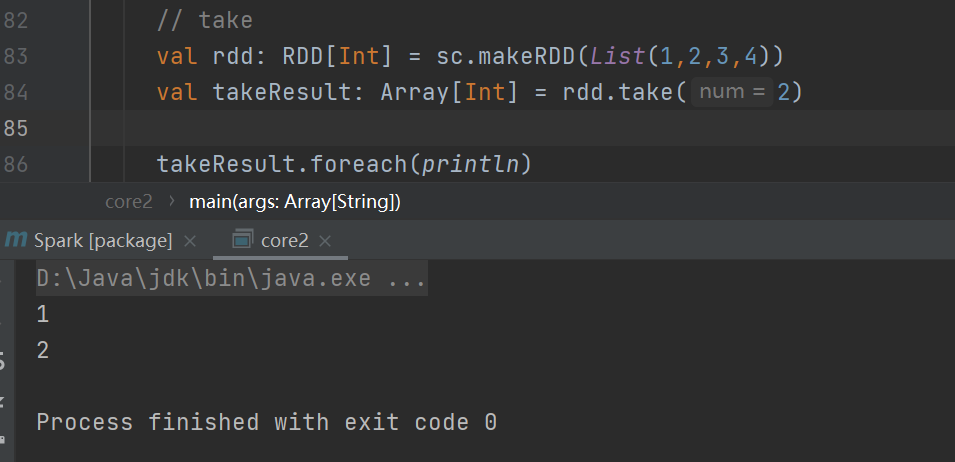
take
返回一个由 RDD 的前 n 个元素组成的数组
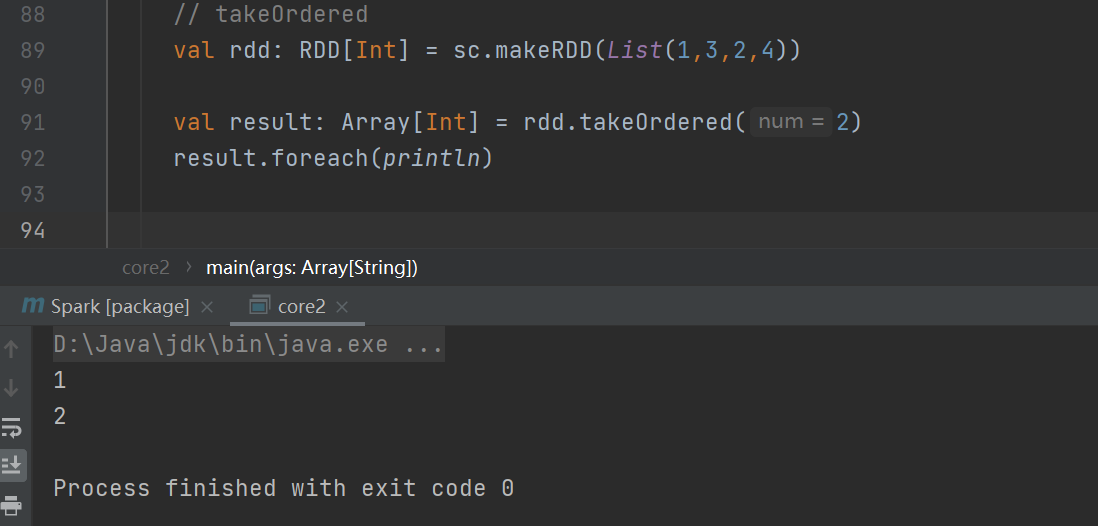
takeOrdered
返回该 RDD 排序后的前 n 个元素组成的数组
aggregate
分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
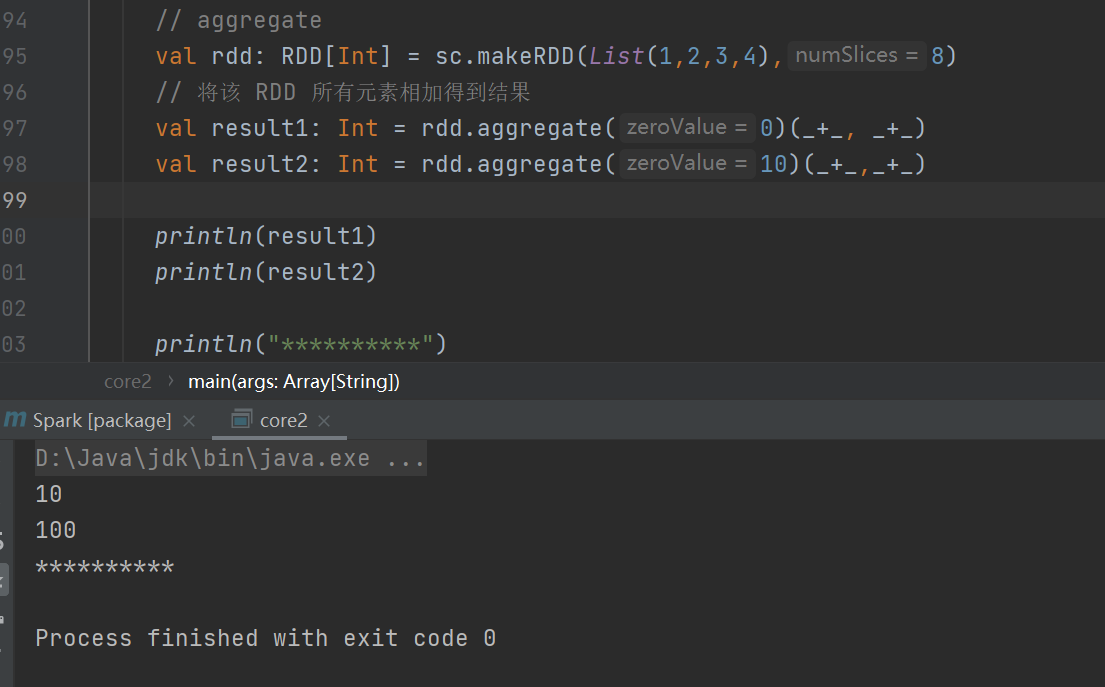
如果图片中rdd中numSlices那个地方不写数字的话,是根据CPU来算的,如下图所示:
(分区计算与CPU核数的关系。
通过任务管理器查看CPU核数,并以此为基础进行分区计算。)
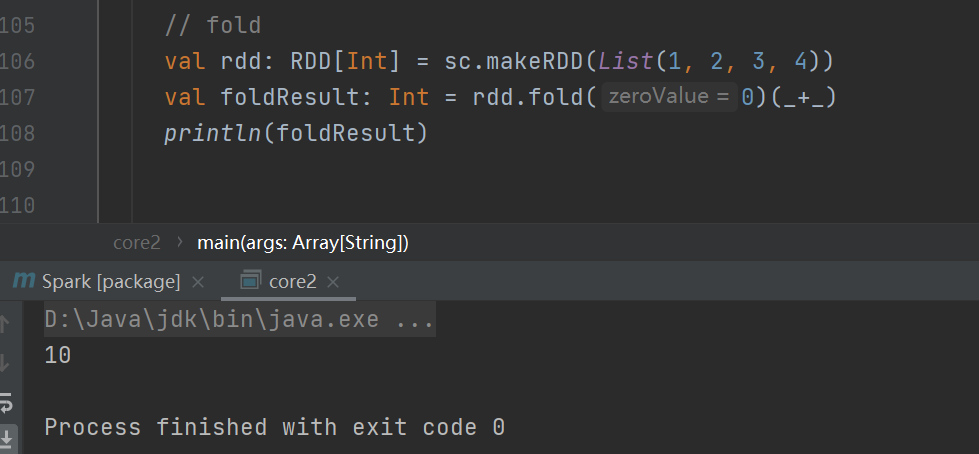
fold
折叠操作,aggregate 的简化版操作
countByKey
统计每种 key 的个数

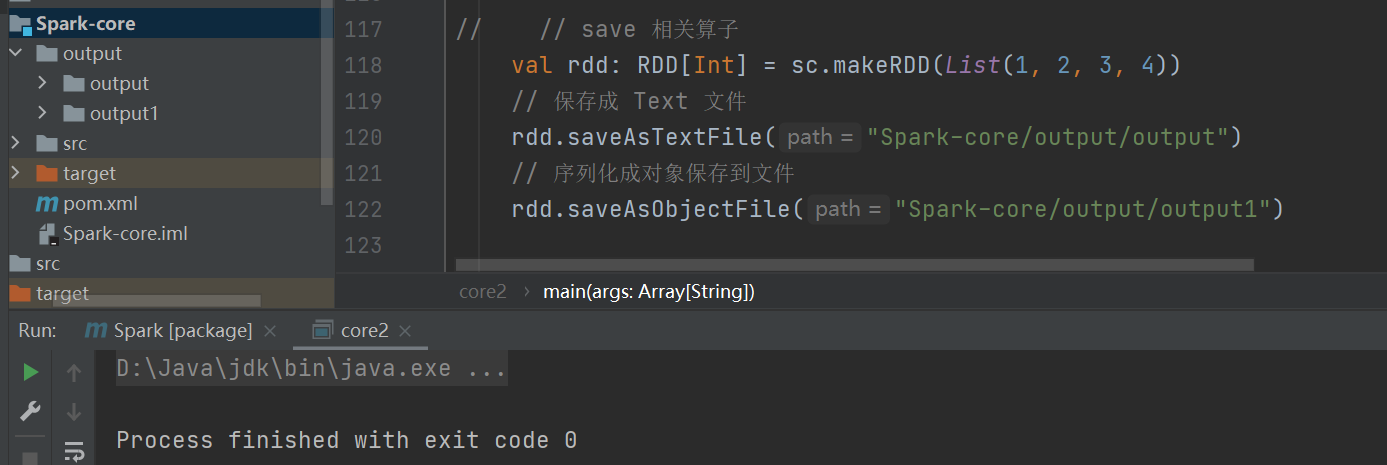
save 相关算子
将数据保存到不同格式的文件中
Spark的三大数据结构
1. RDD
转换算子和行动算子
2.累加器
用于将executor端的变量信息聚合到driver端。
每个task得到变量副本并更新,传回driver端。
展示了相关代码,强调可自定义创建和调用。
3.广播变量
用于高效分发较大只读值。
是只读变量,在多个并行操作中使用同一变量。
展示了与RDD进行数据关联操作的代码