采购需求网站建设友情链接交换工具
目录
一、表示/生成式LLM都可以用于分类任务
二、电影评论的情感分析
三、用表示模型进行文本分类
四、模型选择
五、使用任务特定模型
六、使用嵌入模型
6.1 监督分类
6.2 tip
七、如果没有样本怎么办
7.1 注意事项
7.2 tip
八、使用生成模型进行文本分类
九、使用Text-to-Text Transfer Transformer
十、ChatGPT用于分类
十一、总结
一、表示/生成式LLM都可以用于分类任务
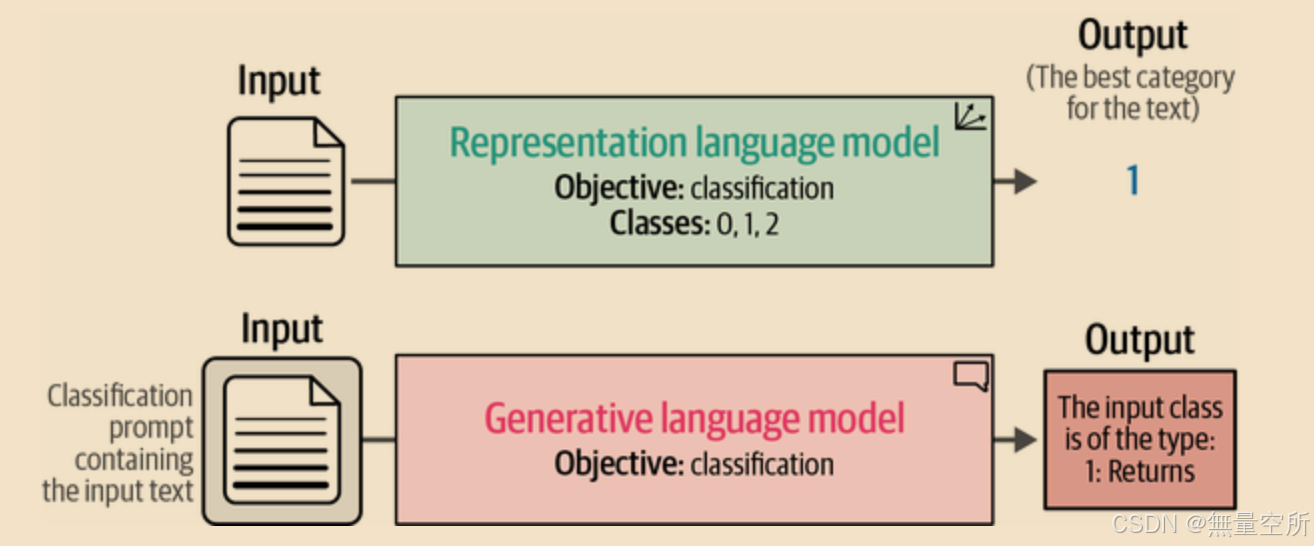
在本章中,我们将讨论几种使用语言模型进行文本分类的方法。由于文本分类领域广泛,我们将讨论几种技术,并用它们来探索语言模型的领域:
- “用表征模型进行文本分类”展示了非生成性模型在分类中的灵活性。我们将涵盖任务特定模型和嵌入模型。
- “用生成性模型进行文本分类”是对生成性语言模型的介绍,因为大多数生成性语言模型都可以用于分类。我们将涵盖开源和闭源语言模型。
二、电影评论的情感分析
你可以通过Hugging Face Hub找到我们用来探索文本分类技术的数据。我们将使用“rotten_tomatoes”数据集来训练和评估我们的模型。它包含了来自Rotten Tomatoes的5331条正面和5331条负面的电影评论。
为了加载这些数据,我们使用datasets包:
from datasets import load_dataset# 加载数据
data = load_dataset("rotten_tomatoes")
data>> 结果
DatasetDict({train: Dataset({features: ['text', 'label'],num_rows: 8530})validation: Dataset({features: ['text', 'label'],num_rows: 1066})test: Dataset({features: ['text', 'label'],num_rows: 1066})
})数据被分成了训练集、测试集和验证集。在本章中,我们将使用训练集来训练模型,并使用测试集来验证结果。需要注意的是,额外的验证集可以在你使用训练集和测试集进行超参数调整时,进一步验证模型的泛化能力。
让我们来看看训练集中的一些示例:
data["train"][0, -1]>> 结果
{'text': ['the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .','things really get weird , though not particularly scary : the movie is all portent and no content .'],'label': [1, 0]}这些简短的评论被标记为正面(1)或负面(0)。这意味着我们将专注于二元情感分类。
三、用表示模型进行文本分类
使用预训练表示模型进行分类通常有两种方式:
- 使用任务特定模型--一种表征模型,例如BERT,它被训练用于特定任务,如情感分析。;
- 使用嵌入模型--生成通用嵌入,这些嵌入可以用于多种任务,不仅限于分类,例如语义搜索(见第8章)。
正如我们在上一章中探讨的那样,这些模型是通过对基础模型(如BERT)进行微调而创建的,以适应特定的下游任务,如下图所示。
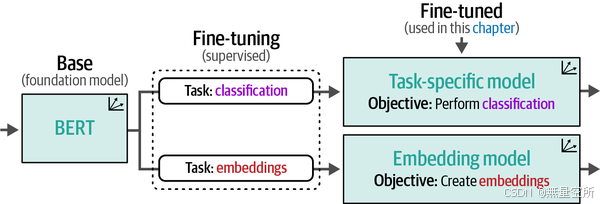
在第11章中,我们将介绍如何对BERT模型进行微调以用于分类,而在第10章中,我们将介绍如何创建嵌入模型。在本章中,我们将保持这两种模型冻结(不可训练),并仅使用它们的输出,如下图所示。
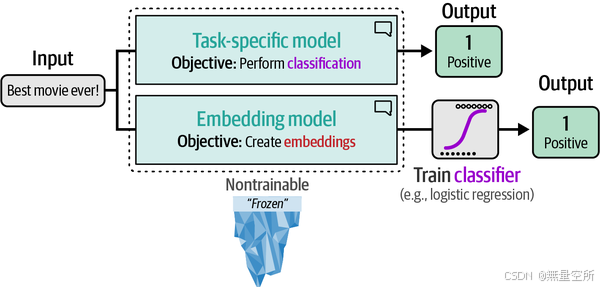
我们将利用已经微调好的预训练模型,探索它们如何用于对选定的电影评论进行分类。
四、模型选择
选择合适的模型并不像你想象的那么简单。在撰写本文时,Hugging Face Hub上有超过6万个用于文本分类的模型,以及超过8000个用于生成嵌入的模型。此外,选择一个适合你用例的模型至关重要,还需要考虑其语言兼容性、底层架构、大小和性能。
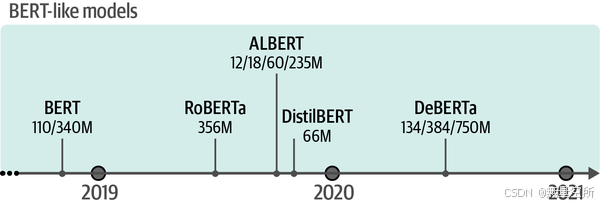
多年来,BERT的许多变体已经被开发出来,包括RoBERTa²、DistilBERT³、ALBERT⁴和DeBERTa⁵,它们在各种上下文中进行了训练。你可以在下图中找到一些著名BERT类模型的概览。
尝试Hugging Face Hub上数千个预训练模型是不现实的,因此我们需要高效地选择模型。有几个模型是很好的起点,它们可以让你了解这类模型的基础性能。可以将它们视为可靠的基线:
BERT基础模型(不区分大小写)
RoBERTa基础模型
DistilBERT基础模型(不区分大小写)
DeBERTa基础模型
bert-tiny
ALBERT基础版v2
任务特定模型选择Twitter-RoBERTa-base情感分析模型。这是一个在推文上针对情感分析进行微调的RoBERTa模型。尽管它并非专门为电影评论训练,但探索该模型的泛化能力是很有意思的。
在选择用于生成嵌入的模型时,MTEB排行榜是一个很好的起点。它包含了在多个任务上进行基准测试的开源和闭源模型。需要注意的是,不仅要考虑性能,推理速度在实际解决方案中的重要性也不容小觑。因此,嵌入模型使用sentence-transformers/all-mpnet-base-v2。它是一个小巧但性能出色的模型。
五、使用任务特定模型
让我们开始加载模型:
from transformers import pipeline# 模型路径
model_path = "cardiffnlp/twitter-roberta-base-sentiment-latest"# 将模型加载到pipeline中
pipe = pipeline(model=model_path,tokenizer=model_path,return_all_scores=True,device="cuda:0"
)在加载模型时,我们还加载了分词器(tokenizer),它负责将输入文本转换为单独的标记,如下图所示。这个参数不是必需的,因为它会自动加载。
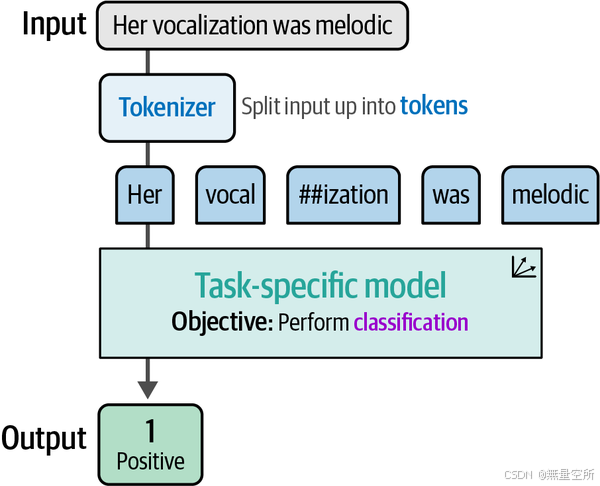
这些tokens是大多数语言模型的核心,我们在第2章中深入探讨了这一点。这些tokens的一个主要好处是,即使它们不在训练数据中,也可以组合生成表示,如下图所示。
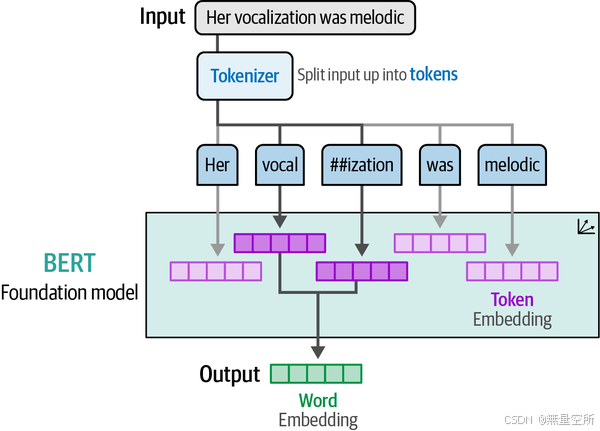
加载完所有必要的组件后,我们可以继续在数据的测试集上使用我们的模型:
import numpy as np
from tqdm import tqdm
from transformers.pipelines.pt_utils import KeyDataset# 运行推理
y_pred = []
for output in tqdm(pipe(KeyDataset(data["test"], "text")), total=len(data["test"])):negative_score = output[0]["score"]positive_score = output[2]["score"]assignment = np.argmax([negative_score, positive_score])y_pred.append(assignment)现在我们已经生成了预测结果,接下来就是评估。我们创建了一个小函数,可以在本章中方便地使用:
from sklearn.metrics import classification_reportdef evaluate_performance(y_true, y_pred):"""创建并打印分类报告"""performance = classification_report(y_true, y_pred,target_names=["Negative Review", "Positive Review"])print(performance)接下来,我们生成分类报告:
evaluate_performance(data["test"]["label"], y_pred)>> 结果precision recall f1-score supportNegative Review 0.76 0.88 0.81 533
Positive Review 0.86 0.72 0.78 533accuracy 0.80 1066macro avg 0.81 0.80 0.80 1066weighted avg 0.81 0.80 0.80 1066为了读懂生成的分类报告,我们先从如何识别正确和错误的预测开始。根据我们是否正确预测(True)与错误预测(False),以及我们是否预测了正确的类别(Positive)与错误的类别(Negative),有四种组合。我们可以用一个矩阵来表示这些组合,通常称为混淆矩阵,如下图所示。
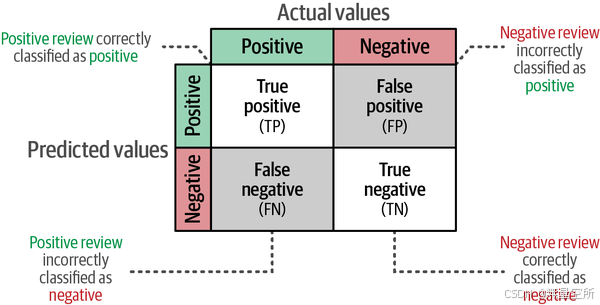
利用混淆矩阵,我们可以推导出几个公式来描述模型的质量。在之前生成的分类报告中,我们可以看到四种这样的方法,分别是精确率(precision)、召回率(recall)、准确率(accuracy)和F1分数(F1 score):
精确率(Precision):衡量找到的项目中有多少是相关的,表示相关结果的准确性。
召回率(Recall):衡量找到了多少相关类别,表示其找到所有相关结果的能力。
准确率(Accuracy):衡量模型在所有预测中做出正确预测的比例,表示模型的整体正确性。
F1分数(F1 score):平衡精确率和召回率,以评估模型的整体性能。
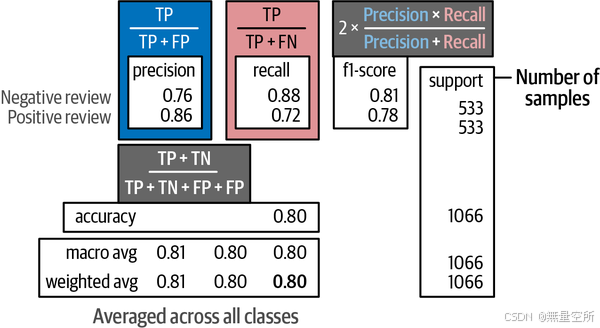
我们也将考虑F1分数的加权平均值,以确保每个类别都被平等地对待。我们预训练的BERT模型给出了0.80的F1分数(我们从加权平均行和F1分数列中读取),对于一个未在我们特定领域数据(电影评论)上训练的模型来说,这是一个很好的结果!
(了解上述评估指标可参考博客:分类问题常用评估指标_常用分类系统评价指标-CSDN博客)
为了提高我们选定模型的性能,我们可以做几件不同的事情,包括选择一个在我们领域数据(电影评论)上训练的模型,例如DistilBERT基础版(uncased)微调SST-2模型。
我们也可以将注意力转向另一种表征模型,即嵌入模型。
六、使用嵌入模型
在前面的例子中,我们使用了一个预训练的任务特定模型来进行情感分析。然而,如果我们找不到针对特定任务预训练的模型,是否需要自己微调一个表征模型呢?答案是:不需要!
如果你有足够的计算资源,可能会选择自己微调模型(见第11章)。然而,并非每个人都能获得大量的计算资源。这时,通用嵌入模型就派上用场了。
6.1 监督分类
与前面的例子不同,我们可以通过更传统的方式完成部分训练过程。我们不是直接使用表征模型进行分类,而是使用嵌入模型生成特征,然后将这些特征输入到分类器中,从而形成一个两步走的方法,如下图所示。
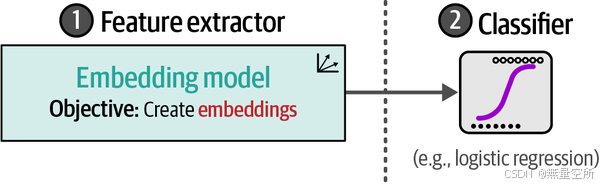
这种分离的一个主要好处是我们不需要微调我们的嵌入模型,因为这可能会非常耗时。相反,我们可以在CPU上训练一个分类器,例如逻辑回归。
在第一步中,我们使用嵌入模型将文本输入转换为嵌入,如下图所示。需要注意的是,这个模型同样保持冻结状态,在训练过程中不会更新。
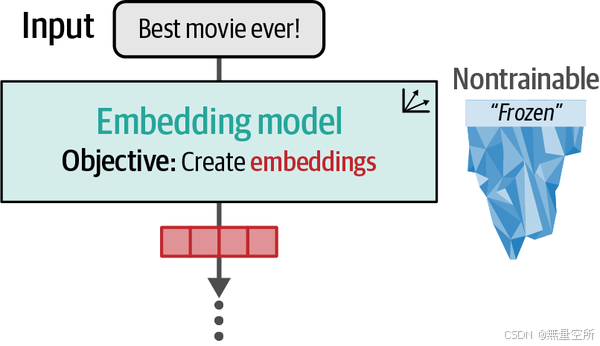
我们可以使用 sentence-transformers,这是一个流行的用于利用预训练嵌入模型的包,来完成这一步。生成嵌入的过程非常简单:
from sentence_transformers import SentenceTransformer# 加载模型
model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")# 将文本转换为嵌入
train_embeddings = model.encode(data["train"]["text"], show_progress_bar=True)
test_embeddings = model.encode(data["test"]["text"], show_progress_bar=True)正如我们在第1章中提到的,这些嵌入是输入文本的数值表示。嵌入的维度(即嵌入中的数值数量)取决于底层的嵌入模型。让我们探索一下我们模型的维度:
train_embeddings.shape
(8530, 768)这表明我们的8530个输入文档每个都有一个维度为768的嵌入,因此每个嵌入包含768个数值。
在第二步中,这些嵌入作为分类器的输入特征,如下图所示。分类器是可训练的,不仅限于逻辑回归,只要它能执行分类任务,就可以采用任何形式。
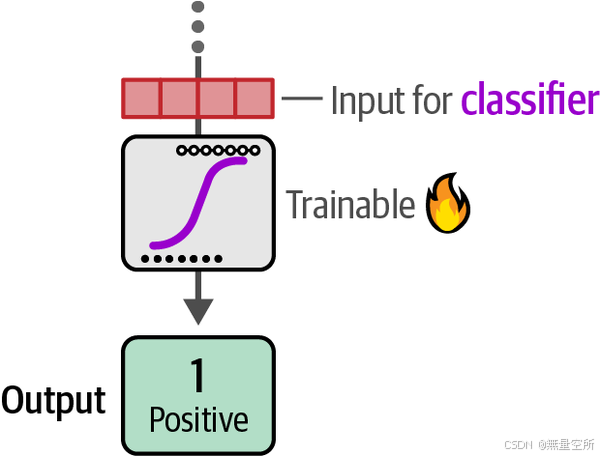
我们将这一步保持简单,使用逻辑回归作为分类器。为了训练它,我们只需要使用生成的嵌入和标签:
from sklearn.linear_model import LogisticRegression# 在训练嵌入上训练逻辑回归
clf = LogisticRegression(random_state=42)
clf.fit(train_embeddings, data["train"]["label"])接下来,我们评估我们的模型:
# 预测之前未见过的实例
y_pred = clf.predict(test_embeddings)
evaluate_performance(data["test"]["label"], y_pred)输出结果如下:
precision recall f1-score supportNegative Review 0.85 0.86 0.85 533
Positive Review 0.86 0.85 0.85 533accuracy 0.85 1066macro avg 0.85 0.85 0.85 1066weighted avg 0.85 0.85 0.85 1066通过在嵌入之上训练一个分类器,我们成功地得到了0.85的F1分数!这展示了在保持底层嵌入模型冻结的情况下,训练一个轻量级分类器的可能性。
6.2 tip
在本例中,我们使用 sentence-transformers 提取嵌入,这得益于GPU加速推理。然而,我们可以通过使用外部API来创建嵌入,从而消除对GPU的依赖。生成嵌入的流行选择包括 Cohere 和 OpenAI 提供的服务。因此,这将允许整个流程完全在CPU上运行。
七、如果没有样本怎么办
在前面的例子中,我们使用了标注数据来完成任务,但在实际应用中,我们可能并不总是能获得标注数据。获取标注数据是一项资源密集型的任务,可能需要大量的人力投入。此外,收集这些标签是否真的值得呢?
为了测试这一点,我们可以进行零样本分类(zero-shot classification),即在没有任何标注数据的情况下,探索任务是否可行。尽管我们知道标签的定义(它们的名称),但我们并没有标注数据来支持它们。零样本分类试图预测输入文本的标签,尽管它从未在这些标签上进行过训练,如下图所示。
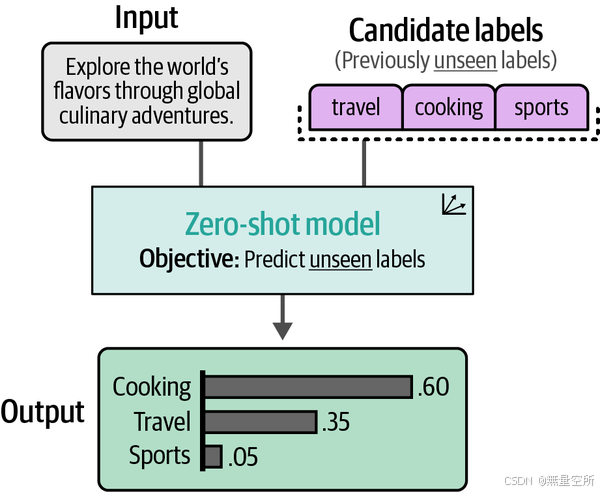
要使用嵌入进行零样本分类,我们可以使用一个巧妙的技巧。我们可以根据标签所代表的含义来描述它们。例如,对于电影评论的负面标签,可以描述为“这是一条负面的电影评论”。通过描述并嵌入标签和文档,我们就可以获得可以处理的数据。这个过程如下图所示,允许我们在没有任何标注数据的情况下生成自己的目标标签。
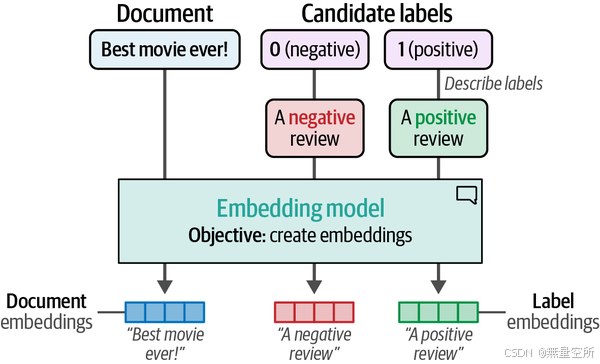
我们可以使用 .encode 函数为这些标签创建嵌入,就像我们之前所做的那样:
# 为我们的标签创建嵌入
label_embeddings = model.encode(["A negative review", "A positive review"])为了将标签分配给文档,我们可以对文档和标签应用余弦相似度。这是向量之间夹角的余弦值,通过嵌入的点积除以它们长度的乘积来计算,如下图所示。
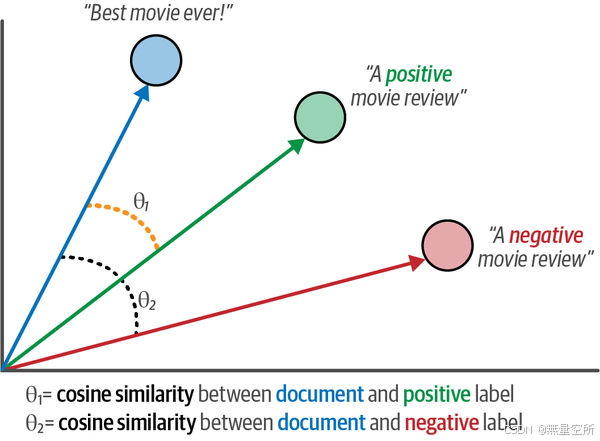
我们可以使用余弦相似度来检查给定文档与候选标签描述的相似度。与文档相似度最高的标签将被选中,如下图所示。
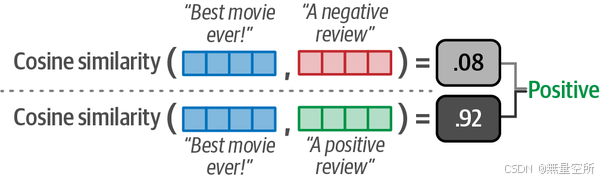
为了对嵌入执行余弦相似度,我们只需要比较文档嵌入和标签嵌入,并找到最佳匹配对:
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np# 为每个文档找到最佳匹配的标签
sim_matrix = cosine_similarity(test_embeddings, label_embeddings)
y_pred = np.argmax(sim_matrix, axis=1)就这样!我们只需要为标签起个名字就可以完成分类任务了。让我们看看这种方法的效果如何:
evaluate_performance(data["test"]["label"], y_pred)输出结果如下:
precision recall f1-score supportNegative Review 0.78 0.77 0.78 533
Positive Review 0.77 0.79 0.78 533accuracy 0.78 1066macro avg 0.78 0.78 0.78 1066weighted avg 0.78 0.78 0.78 10667.1 注意事项
如果你熟悉基于Transformer的零样本分类模型,你可能会好奇为什么我们选择用嵌入来说明这一点。尽管自然语言推理模型在零样本分类中表现出色,但这里的例子展示了嵌入在各种任务中的灵活性。
考虑到我们完全没有使用任何标注数据,F1分数达到0.78已经相当令人印象深刻了!这充分展示了嵌入的多功能性和实用性,尤其是当你在使用它们时发挥一点创造力时。
7.2 tip
让我们来测试一下这种创造力。我们选择了“A negative/positive review”作为标签的名称,但这可以进一步优化。相反,我们可以让它们更具针对性,更贴近我们的数据,例如使用“A very negative/positive movie review”。这样,嵌入就会捕捉到这是电影评论,并且会更多地关注这两个标签的极端情况。不妨尝试一下,看看它如何影响结果。
八、使用生成模型进行文本分类
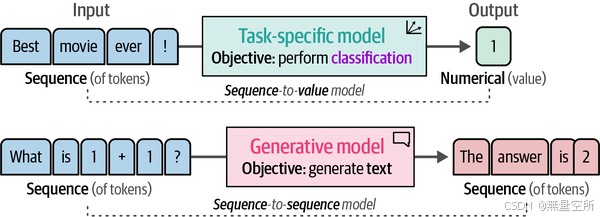
使用生成模型(如OpenAI的GPT模型)进行分类与我们之前的方法有所不同。这些模型输入文本并生成文本,因此被称为序列到序列(sequence-to-sequence)模型。这与我们的任务特定模型形成鲜明对比,任务特定模型输出的是类别,而不是生成文本,如下图所示。
这些生成性模型通常在多种任务上进行训练,但它们通常不能直接用于你的用例。例如,如果我们给一个生成性模型一个没有上下文的电影评论,它不知道该如何处理。
相反,我们需要帮助它理解上下文,并引导它得出我们想要的答案。如下图所示,这个引导过程主要通过prompt来完成。逐步改进prompt以获得期望的输出被称为提示工程(prompt engineering)。
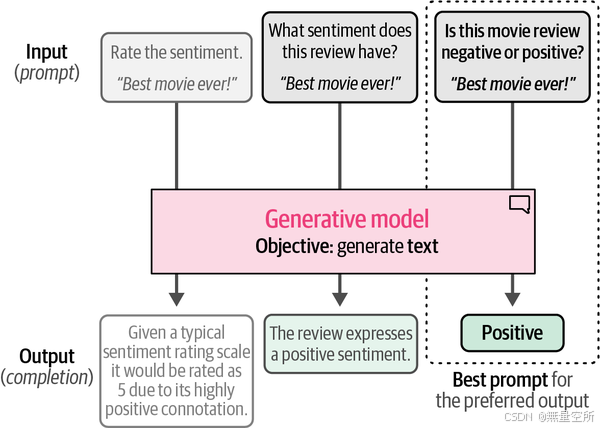
在本节中,我们将展示如何利用不同类型的生成性模型在我们的“Rotten Tomatoes”数据集上进行分类。
九、使用Text-to-Text Transfer Transformer
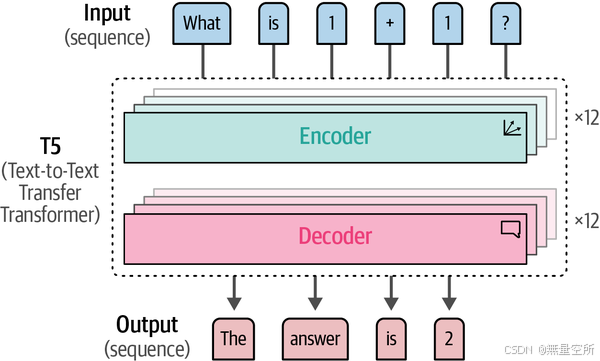
在本书中,我们将主要探索仅编码器(表征)模型(如BERT)和仅解码器(生成)模型(如ChatGPT)。然而,正如我们在第1章中讨论的,原始Transformer架构实际上是一个编码器-解码器架构。与仅解码器模型一样,这些编码器-解码器模型也是序列到序列模型,通常属于生成性模型。
一个利用这种架构的有趣模型家族是Text-to-Text Transfer Transformer(T5模型)。如下图所示,其架构类似于原始Transformer,12个解码器和12个编码器堆叠在一起。
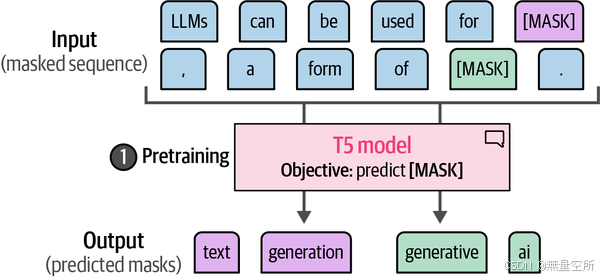
在训练的第一阶段,如下图所示,这些模型首先使用掩码语言建模进行预训练。与掩码单个标记不同,预训练期间掩码的是标记集合(或标记跨度)。
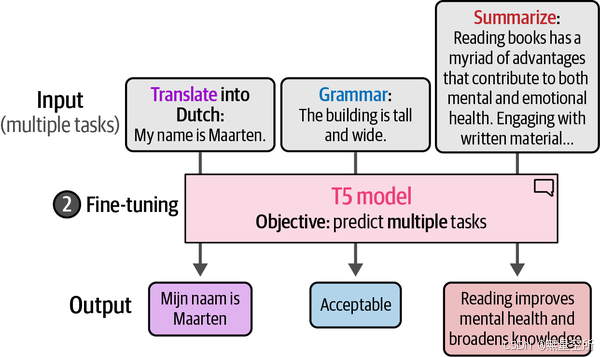
在训练的第二阶段,即微调基础模型时,真正的“魔法”发生了。如下图所示,不是为一个特定任务微调模型,而是将每个任务转换为序列到序列任务并同时进行训练。这使得模型能够在微调期间训练多种任务。
在论文《Scaling instruction-finetuned language models》中,这种微调方法得到了扩展,微调期间引入了超过一千种任务,这些任务更接近我们从GPT模型中所熟知的指令。这导致了Flan-T5模型家族的诞生,这些模型受益于这种多样化的任务。
为了使用预训练的Flan-T5模型进行分类,我们将从加载“text2text-generation”任务的模型开始,这通常适用于这些编码器-解码器模型:
# 加载模型
pipe = pipeline("text2text-generation", model="google/flan-t5-small", device="cuda:0"
)Flan-T5模型有多种大小(flan-t5-small/base/large/xl/xxl),我们将使用最小的模型以加快速度。但你可以尝试使用更大的模型,看看是否能改进结果。
与任务特定模型不同,我们不能仅仅给模型一些文本并希望它输出情感。相反,我们需要指导模型完成任务。
因此,我们在每个文档前添加提示:“Is the following sentence positive or negative?”(以下句子是正面的还是负面的?):
# 准备数据
prompt = "Is the following sentence positive or negative? "
data = data.map(lambda example: {"t5": prompt + example['text']})
print(data)>> 结果
DatasetDict({train: Dataset({features: ['text', 'label', 't5'],num_rows: 8530})validation: Dataset({features: ['text', 'label', 't5'],num_rows: 1066})test: Dataset({features: ['text', 'label', 't5'],num_rows: 1066})
})在创建了更新后的数据后,我们可以像任务特定的例子那样运行pipeline:
# 运行推理
y_pred = []
for output in tqdm(pipe(KeyDataset(data["test"], "t5")), total=len(data["test"])):text = output[0]["generated_text"]y_pred.append(0 if text == "negative" else 1)由于这个模型生成文本,我们需要将文本输出转换为数值。输出单词“negative”被映射为0,而“positive”被映射为1。
现在,这些数值允许我们像之前一样测试模型的质量:
evaluate_performance(data["test"]["label"], y_pred)输出结果如下:
precision recall f1-score supportNegative Review 0.83 0.85 0.84 533
Positive Review 0.85 0.83 0.84 533accuracy 0.84 1066macro avg 0.84 0.84 0.84 1066weighted avg 0.84 0.84 0.84 1066F1分数达到0.84,这表明Flan-T5模型是一个令人惊叹的生成性模型的初步展示。
十、ChatGPT用于分类
尽管本书主要关注开源模型,但语言人工智能领域还有另一个重要组成部分,即闭源模型,尤其是ChatGPT。
尽管原始ChatGPT模型(GPT-3.5)的底层架构没有公开,但从其名称可以推测,它基于我们之前看到的GPT模型中的解码器架构。
幸运的是,OpenAI分享了其训练过程的概述,其中涉及一个重要的组成部分,即偏好调整(preference tuning)。如下图所示,OpenAI首先手动创建输入提示(指令数据)的期望输出,并使用这些数据创建了模型的第一个版本。

OpenAI使用得到的模型生成多个输出,并手动对这些输出从最佳到最差进行排名。如下图所示,这种排名展示了对某些输出的偏好(偏好数据),并用于创建最终的模型——ChatGPT。
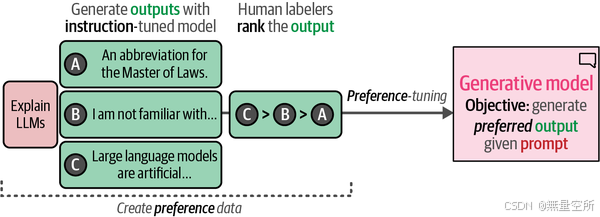
使用偏好数据而不是指令数据的一个主要好处是它所代表的细微差别。通过展示良好输出和更好输出之间的差异,生成模型学会了生成更符合人类偏好的文本。在第12章中,我们将探讨这些微调和偏好调整方法的工作原理以及如何自行实现。
使用闭源模型的过程与我们之前看到的开源模型示例有很大不同。我们不是加载模型,而是通过OpenAI的API访问模型。
在进入分类示例之前,您需要先在OpenAI官网创建一个免费账户,并在此处创建API密钥:https://oreil.ly/lrTXl。之后,您可以使用您的API与OpenAI的服务器进行通信。
我们可以使用此密钥创建一个客户端:
import openai# 创建客户端
client = openai.OpenAI(api_key="YOUR_KEY_HERE")使用此客户端,我们创建了一个名为chatgpt_generation的函数,该函数可以根据特定提示、输入文档和选定的模型生成一些文本:
def chatgpt_generation(prompt, document, model="gpt-3.5-turbo-0125"):"""根据提示和输入文档生成输出。"""messages=[{"role": "system","content": "You are a helpful assistant."},{"role": "user","content": prompt.replace("[DOCUMENT]", document)}]chat_completion = client.chat.completions.create(messages=messages,model=model,temperature=0)return chat_completion.choices[0].message.content接下来,我们需要创建一个模板,让模型执行分类任务:
# 定义一个提示模板作为基础
prompt = """预测以下文档是否为正面或负面的电影评论:[DOCUMENT]如果是正面的返回1,如果是负面的返回0。不要给出其他答案。
"""# 使用GPT预测目标
document = "unpretentious , charming , quirky , original"
chatgpt_generation(prompt, document)这个模板只是一个示例,可以根据需要进行修改。目前,我们尽量保持简单,以展示如何使用这种模板。
在将此方法应用于可能较大的数据集之前,重要的是始终跟踪您的使用情况。像OpenAI这样的外部API,如果执行大量请求,可能会很快变得昂贵。
提示
在处理外部API时,您可能会遇到速率限制错误。这些错误出现在您过于频繁地调用API时,因为某些API可能会限制您每分钟或每小时的使用频率。
为了防止这些错误,我们可以实现几种重试请求的方法,包括一种称为指数退避(exponential backoff)的方法。当遇到速率限制错误时,它会短暂休眠,然后重试失败的请求。如果再次失败,休眠时间会增加,直到请求成功或达到最大重试次数。
接下来,我们可以将此方法应用于测试数据集中的所有评论以获取其预测结果。
# 如果您想节省免费积分,可以跳过这一步
predictions = [chatgpt_generation(prompt, doc) for doc in tqdm(data["test"]["text"])
]与前面的例子一样,我们需要将输出从字符串转换为整数,以便评估其性能:
# 提取预测结果
y_pred = [int(pred) for pred in predictions]# 评估性能
evaluate_performance(data["test"]["label"], y_pred)| 类别 | 精度 | 召回率 | F1分数 | 支持 |
|---|---|---|---|---|
| 负面评论 | 0.87 | 0.97 | 0.92 | 533 |
| 正面评论 | 0.96 | 0.86 | 0.91 | 533 |
| 总体指标 | 值 |
|---|---|
| 准确率 | 0.91 |
| macro平均 | 0.92 |
| 加权平均 | 0.92 |
F1分数为0.91,已经让我们对将生成式人工智能推向大众的模型的性能有了初步了解。然而,由于我们不知道该模型是在什么数据上训练的,因此我们不能轻松地使用这些指标来评估模型。我们甚至不知道它是否是用我们的数据集训练的!
在第12章中,我们将探讨如何在更广泛的任务中评估开源和闭源模型。
十一、总结
在本章中,我们讨论了许多不同的技术,用于执行各种各样的分类任务,从对整个模型进行微调到完全不进行微调!对文本数据进行分类并不像表面上看起来那么简单,而且有许多富有创意的方法可以实现。
在本章中,我们探索了使用生成式语言模型和表示式语言模型进行文本分类。我们的目标是对输入文本分配一个标签或类别,以对评论的情感进行分类。
我们研究了两种类型的表示模型:1)针对特定任务的模型,2)嵌入模型。
- 特定任务的模型:在一个大型数据集上预训练的,专门用于情感分析,它向我们展示了预训练模型是分类文档的一个绝佳方法;
- 嵌入模型:生成多功能的嵌入向量,我们将这些向量作为输入来训练分类器。
同样,我们也研究了两种类型的生成式模型:1)开源的编码器-解码器模型(Flan-T5),2)闭源的仅解码器模型(GPT-3.5)。我们使用这些生成式模型进行文本分类,而无需在特定领域数据或标记数据集上进行额外的训练。
在下一章中,我们将继续探讨分类,但重点将转向无监督分类。如果我们有未经标记的文本数据,我们能做些什么?我们能提取什么信息?我们将专注于对数据进行聚类,并使用主题建模技术为聚类命名。