高端网站设计新鸿儒学it什么培训机构好
论文标题
Efficient Reinforcement Finetuning via Adaptive Curriculum Learning
论文地址
https://arxiv.org/pdf/2504.05520
代码地址
https://github.com/uscnlp-lime/verl
作者背景
南加州大学,马里兰大学
前言
当前针对大模型的强化学习仍然具有较大的计算开销,其中一个重要原因在于学习信号不稳定,需要反复采样。
此工作利用了由易到难的课程学习思想来提高学习效率,在任务难度分布不均匀或不稳定的场景下效果尤为明显(最多提效106%),使人们构造训练数据时的质量要求不再严苛,对工业实践非常有帮助
研究动机
大模型在数学推理等任务上,通过强化微调 (Reinforcement Finetuning, RFT)可以更好地对齐任务目标,提高解题准确性。这种方法利用奖励信号(例如解答正确与否)来优化模型策略,相比纯监督微调能更有针对性地提升模型的推理能力(有明确的分数与负反馈)。然而,现有的RFT训练过程效率很低,对算力和数据要求极高,原因在于RFT需要反复执行生成模型输出、计算奖励、更新策略 的循环,每一步都涉及大量算力开销。对此,研究人员迫切希望找到更高效的RFT方法,在提升模型推理性能的同时,大幅降低训练样本量和计算需求。
面临挑战
-
效率瓶颈 :标准的RFT流程由于反复采样和更新,样本效率低下,直接应用在数学推理等复杂任务上会消耗海量算力。近年来一些改进方法被提出来缓解这一问题,但各有局限:
-
算法简化 (如 RAFT、GRPO、REINFORCE++、ReMax): 这类方法通过简化底层强化学习算法来降低计算成本。例如,GRPO 通过成组比较策略输出来估计优势值,省去了价值函数(critic)的计算,从而简化了PPO算法。这些方法在一定程度上提高了训练效率和稳定性,但这样的简化往往导致梯度估计噪声增大、方差提高,训练过程可能变得不稳定,甚至需要更多样本来达到同等效果。
-
数据筛选 (如 LIMO、LIMR): 这类方法从数据层面出发,过滤训练样本来减少低效数据造成的浪费。例如,LIMO(Less is More for reasoning)主张精选少量高质量的监督微调数据,也能取得与海量数据相当的效果。LIMR(Less is More for RL scaling)则预先对训练样本进行学习影响力(LIM)评分,只挑选高分样本进行强化微调,从而减少所需样本数量。这些数据驱动方法缺陷很明显:预处理数据开销大(例如计算LIM分数需要在整个数据集上先训练一遍模型,代价不菲)、筛选策略对模型和任务高度依赖(换一个场景,甚至换一种难易分布时都需要重新计算)、需要做大量数据清洗的脏活累活。
解决方案
本文提出了自适应课程强化微调(Adaptive Curriculum RFT,AdaRFT),主要借鉴了课程学习(Curriculum Learning)的理念:根据模型当前能力动态调整训练样本的难度,使模型始终在“跳一跳就能够着”的任务上训练。正如作者形象地类比:让小学生直接解IMO奥赛难题几乎无法学到东西,而学习任务过于简单又无法推动能力提升。如果让训练任务的难度始终与模型水平保持匹配,模型便能保持进步。AdaRFT通过以下方式实现这个过程:
- 难度评分与目标难度维护 :预先为训练数据集中的每道题目赋予一个“难度分数”,并引入一个动态变化的“目标难度值” T T T ,表示模型当前训练希望聚焦的难度水平;这个难度分数可以由人工评估,也可以使用一个小一点的模型进行多次推理并统计准确率得到。本文使用了Qwen 2.5 MATH 7B模型自动地对问题集进行难度打分,并简单验证了这种自动打分方式的有用性

-
动态课程采样机制 :在每个训练步骤,从数据集中选取难度最接近当前目标难度 T T T 的若干样本组成训练批次,避免挑选过易或过难的样本。这一机制让模型始终在略高于自身水平但又不是完全无解的挑战中学习,确保学习信号保持稳定。
-
策略更新 :利用标准的PPO算法对策略模型参数进行更新
-
目标难度调整 :在每次策略模型更新之后,根据该批次的平均奖励 R avg R_{\text{avg}} Ravg 来调整 T T T:如果模型在当前难度的题目上表现很好(例如 R avg R_{\text{avg}} Ravg 接近1,说明大部分都答对了),则说明这些题对模型来说偏容易,需要提高目标难度;反之,如果平均奖励很低(模型大多答错),说明当前题目太难了,应降低目标难度。为防止 T T T 波动过大,算法使用了一个平滑的更新规则:例如通过 T ← T + η ⋅ tanh [ α ⋅ ( R avg − β ) ] T \leftarrow T + \eta \cdot \tanh[\alpha \cdot (R_{\text{avg}} - \beta)] T←T+η⋅tanh[α⋅(Ravg−β)] 并限制 T T T 在预定最小/最大难度范围内。这里 β \beta β 可以视为目标平均奖励(如0.5), η \eta η 是步长, α \alpha α 控制敏感度。这样的设计保证了目标难度的变化是连续且适度的,不会因一两次异常表现导致难度剧烈跳变,从而维持训练的稳定推进。
值得注意的是,由于AdaRFT只是改变了每步训练样本的选取方式,所以也可以与其他RL算法相结合。
实验效果
作者在多个竞赛级别的数学题集(AMC、AIME等)上对AdaRFT进行了评估,实验使用了两个规模的 Qwen 2.5 模型:一个是专门微调过数学的1.5B模型(Qwen 2.5 MATH 1.5B),另一个是通用的7B模型(Qwen 2.5 7B)。为测试AdaRFT对不同数据难度分布的适应性,作者设计了三种训练数据取样设置:
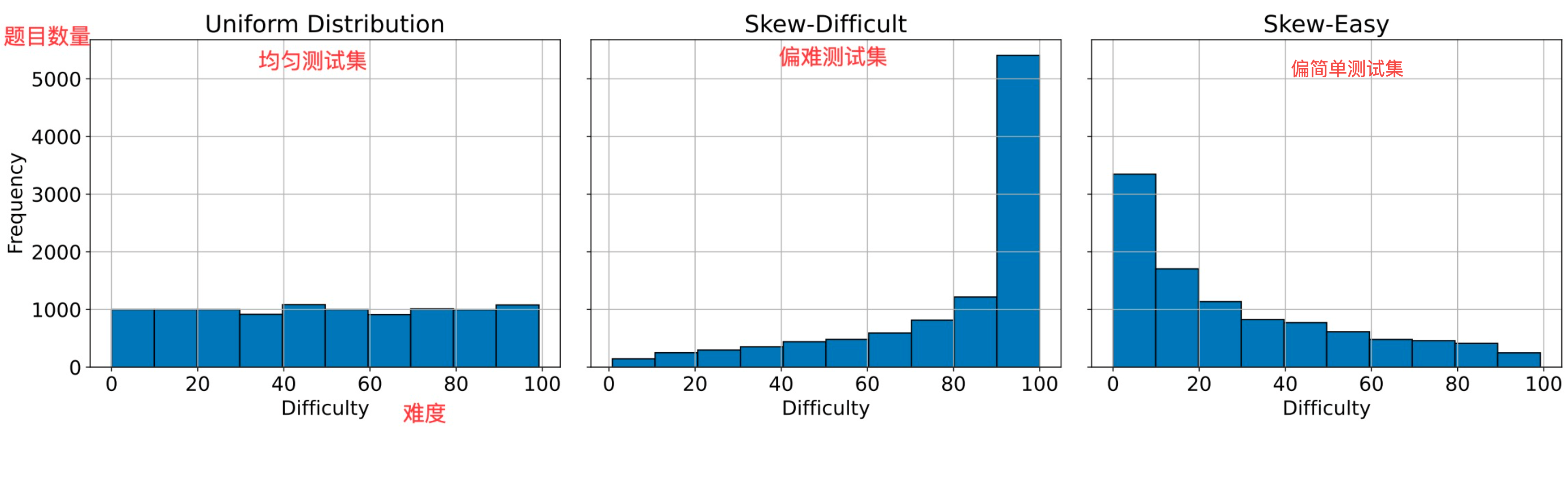
- 均匀分布(uniform) :从简单到困难的题目均匀采样,训练集中各难度的问题比例相对平衡。
- 易题偏多(skew-easy) :训练数据以简单题为主,模拟模型训练遇到大量低难度案例的情形。
- 难题偏多(skew-difficult) :训练数据以高难度题为主,模拟训练数据整体偏难的极端情形。
在每种数据设置下,分别比较了标准PPO强化微调与加入AdaRFT调度后的效果:
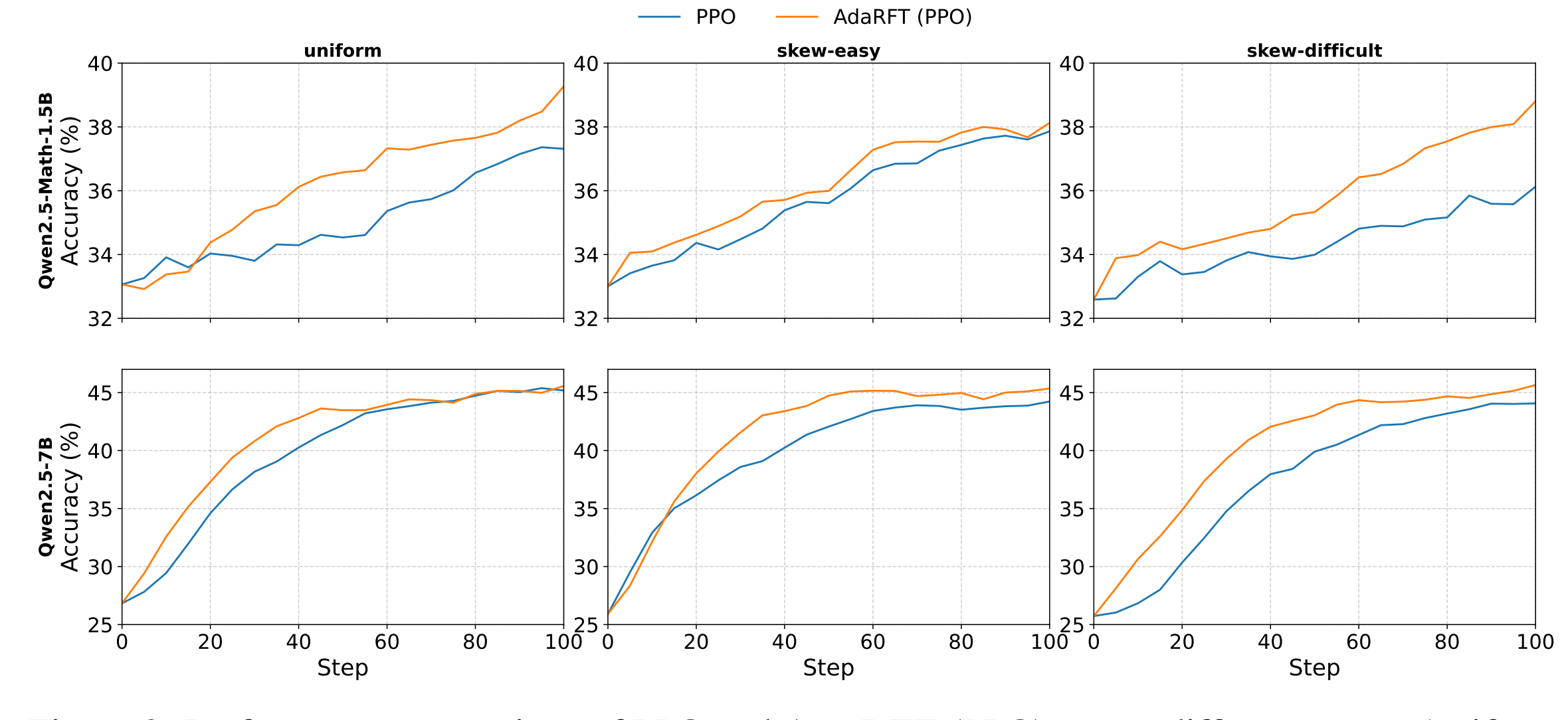
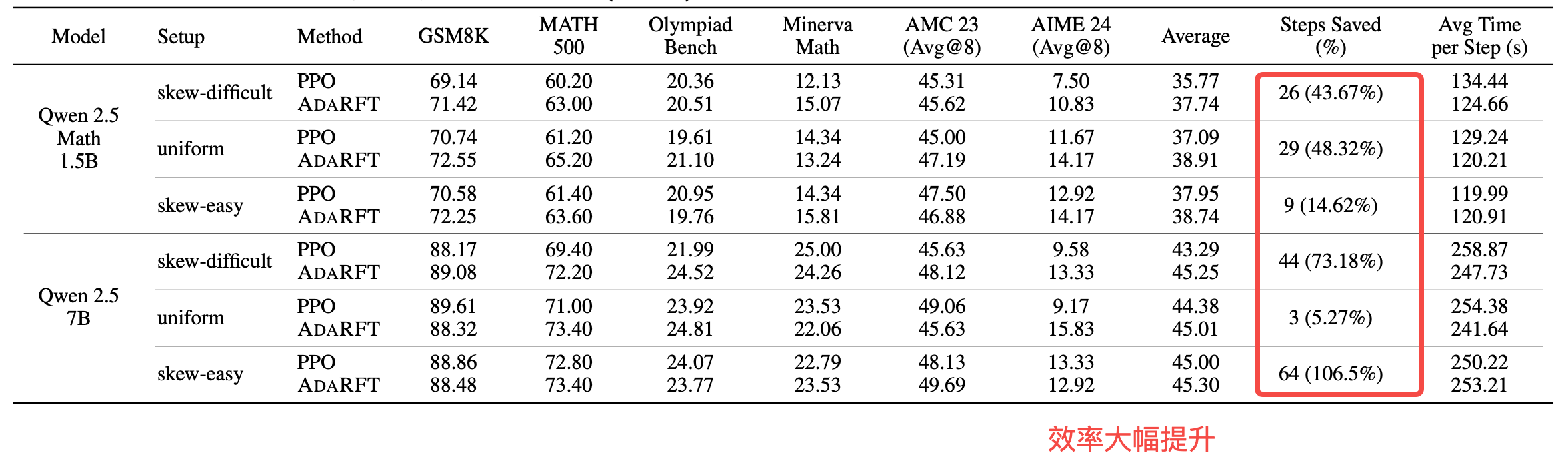
相同采样步数下,标准PPO与AdaRFT在各任务上的准确性:
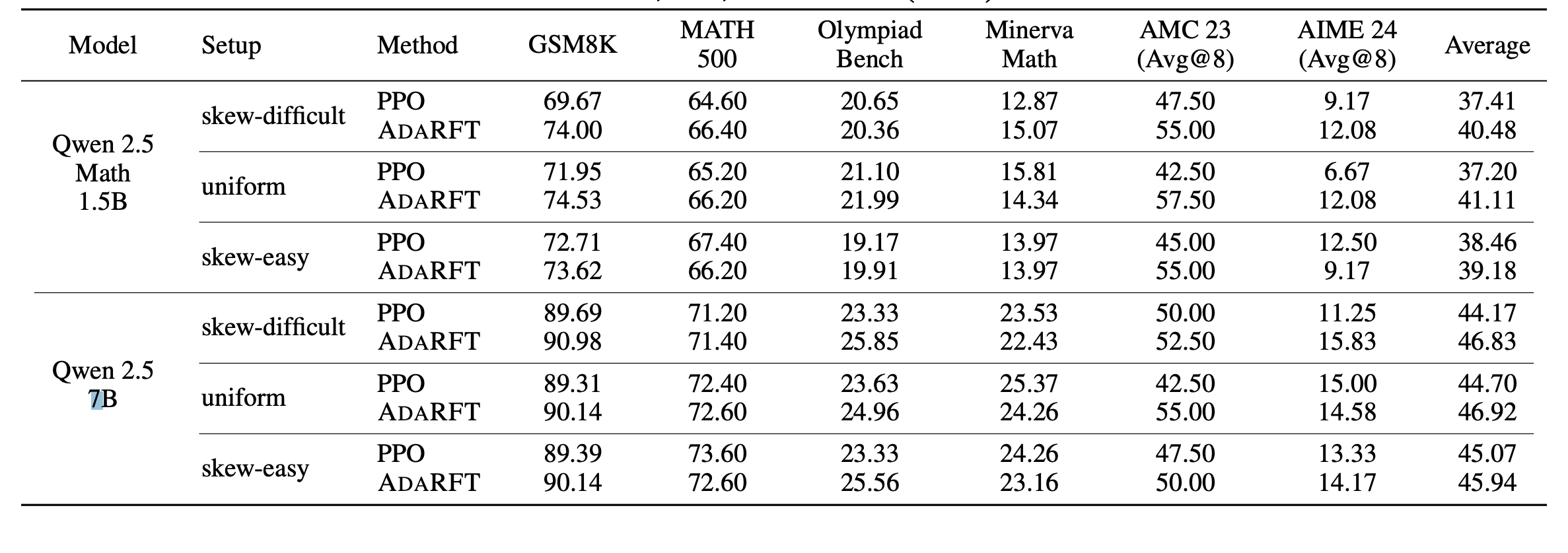
实验结果显示,AdaRFT在训练效率和最终性能上均明显优于基线 PPO,尤其是在数据分布不均衡、难度跨度较大的情况下优势更为突出