手机访问pc网站跳转百度指数分析工具
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
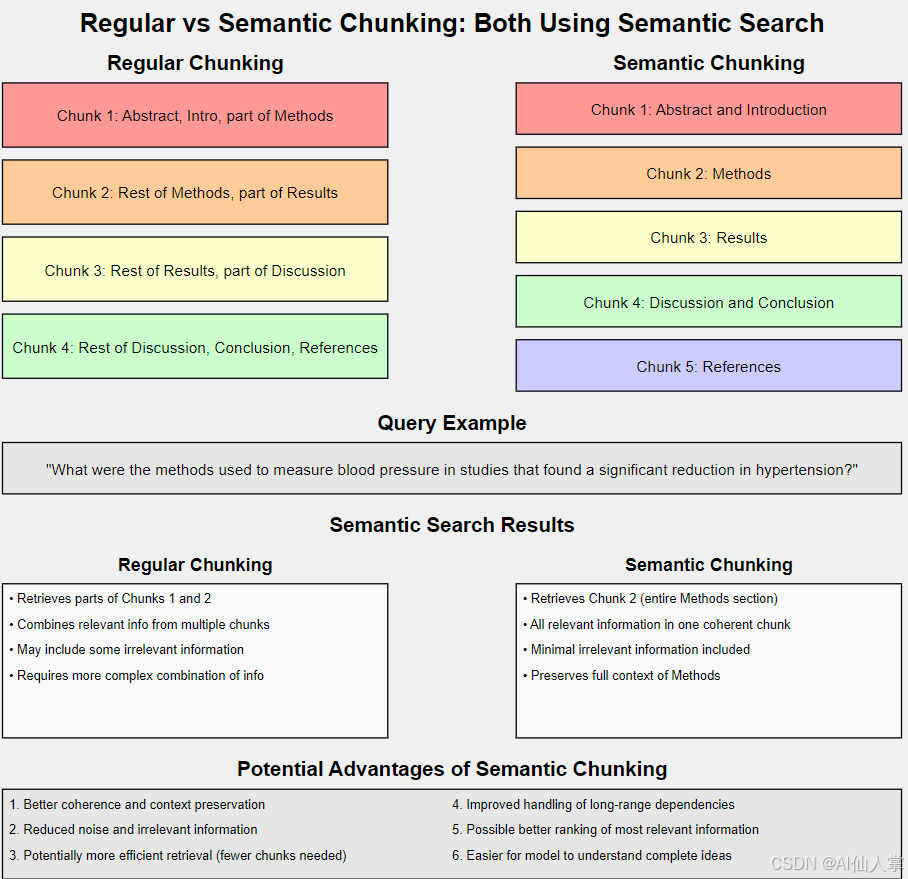
本文将实现一种针对PDF文档处理的语义分块方法,该方法最初由Greg Kamradt提出,后由LangChain团队实现。与传统基于固定字符或单词数量的文本分割方式不同,语义分块旨在创建更具意义且上下文感知的文本片段。
设计动机
传统文本分割方法常在任意位置切断文档,可能破坏信息流的连贯性和上下文关联。语义分块通过尝试在更自然的断点处分割文本来解决这个问题,从而保持每个文本块内部的语义连贯性。
核心组件
- PDF处理与文本提取
- 使用LangChain的SemanticChunker进行语义分块
- 基于FAISS和OpenAI嵌入向量的向量存储库构建
- 面向文档查询的检索器配置
方法详解
pip install --quiet langchain_experimental langchain_openai
文档预处理
- 通过自定义的
read_pdf_to_string函数读取PDF并将其转换为字符串格式。
语义分块
- 使用LangChain的
SemanticChunker结合OpenAI嵌入向量 - 提供三种断点检测类型:
- ‘percentile’(百分位):在差异超过X百分位处分割
- ‘standard_deviation’(标准差):在差异超过X个标准差处分割
- ‘interquartile’(四分位距):使用四分位间距确定分割点
- 本实现采用’percentile’方法,阈值设置为90
向量存储库构建
- 使用OpenAI嵌入向量为语义分块创建向量表示
- 基于这些嵌入向量构建FAISS向量存储库以实现高效相似性搜索
检索器配置
- 检索器设置为针对给定查询返回最相关的2个文本块
核心特性
- 上下文感知分割:保持文本块内部的语义连贯性
- 灵活配置:支持不同的断点类型和阈值设置
- 先进NLP工具集成:在分块和检索阶段均使用OpenAI嵌入向量
技术优势
- 更强的连贯性:文本块更可能包含完整的思想或观点
- 更高的检索相关性:通过保持上下文提升检索准确率
- 良好的适应性:可根据文档特性和检索需求调整分块方法
- 潜在的理解提升:LLM或下游任务可能因更连贯的文本片段而表现更好
实现细节
- 使用OpenAI嵌入向量同时处理语义分块和最终向量表示
- 采用FAISS构建高效的可搜索分块索引
- 检索器默认返回最相关的2个文本块(可根据需求调整)
使用示例
代码包含测试查询:“What is the main cause of climate change?”(气候变化的主要原因是什么?),展示了如何使用语义分块和检索系统从处理后的文档中查找相关信息。
结论
语义分块代表了面向检索系统的文档处理高级方法。通过保持文本片段的语义连贯性,它有望提升检索信息质量并增强下游NLP任务性能。该技术特别适用于处理需要保持上下文完整性的长文档和复杂文档,如科研论文、法律文书或综合性报告等。

库文件导入
import os
import sys
from dotenv import load_dotenvsys.path.append(os.path.abspath(os.path.join(os.getcwd(), '..'))) # 将父目录加入路径(适用于notebook环境)
from helper_functions import *
from evaluation.evalute_rag import *from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings# 从.env文件加载环境变量
load_dotenv()# 设置OpenAI API密钥环境变量
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
定义文件路径
path = "../data/Understanding_Climate_Change.pdf"
将PDF读取为字符串
content = read_pdf_to_string(path)
断点类型说明:
- ‘percentile’(百分位):计算所有句子间差异,在超过X百分位的差异处分割;在此方法中,计算句子之间的所有差异,然后拆分任何大于X百分位数的差异。X的默认值为95.0,可以通过关键字参数breakpoint_threshold_amount进行调整,该参数期望一个介于0.0和100.0之间的数字。
- ‘standard_deviation’(标准差):在超过X个标准差的差异处分割;X的默认值为3.0,可以通过关键字参数breakpoint_threshold_amount进行调整。
- ‘interquartile’(四分位距):使用四分位间距进行分块;四分位范围可以通过关键字参数breakpoint_threshold_amount缩放,默认值为1.5。
- 'Gradient’ (渐变) :在该方法中,距离梯度与百分位数方法一起用于分割块。当块彼此高度相关或特定于领域(例如法律或医学)时,该方法很有用。这个想法是在梯度数组上应用异常检测,以便分布变得更宽,并且易于识别高度语义数据中的边界。与百分位数方法类似,可以通过关键字参数breakpoint_threshold_amount来调整分割,该参数期望一个介于0.0和100.0之间的数字,默认值为95.0。
text_splitter = SemanticChunker(OpenAIEmbeddings(), breakpoint_threshold_type='percentile', breakpoint_threshold_amount=90) # 选择嵌入模型、断点类型及阈值
将原始文本分割成语义分块
docs = text_splitter.create_documents([content])
创建向量存储库和检索器
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)
chunks_query_retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
测试检索器
test_query = "What is the main cause of climate change?"
context = retrieve_context_per_question(test_query, chunks_query_retriever)
show_context(context)