赌博网站怎么做数字营销工具
以下部分引用台湾大学李宏毅教授的ppt 自己理解解释一遍(在youtobe 上可以搜索李宏毅即可)
首先先来看transformer的架构图
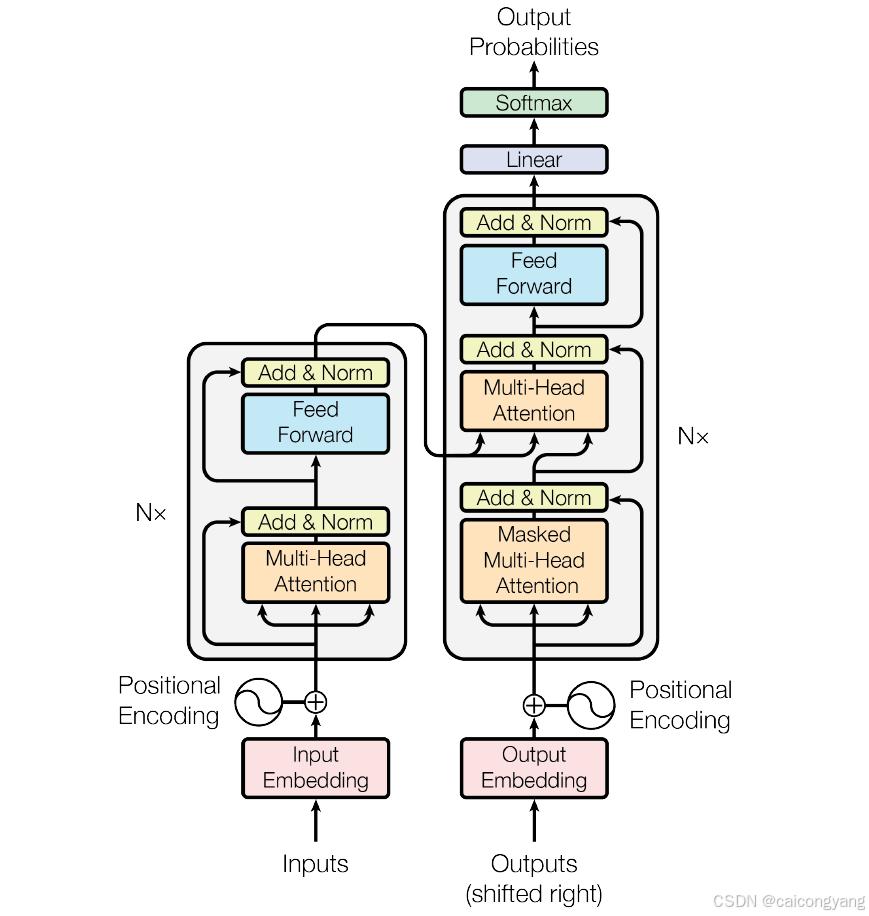
Embedding
我们先从Imput Embedding 跟 OutPutEmbedding 开始,让我们用 bert 模型来做一个解释
从huggingface上下载的bert-base-chinese模型中 有一个vocab.txt 放的是这个模型所有能认识的字;
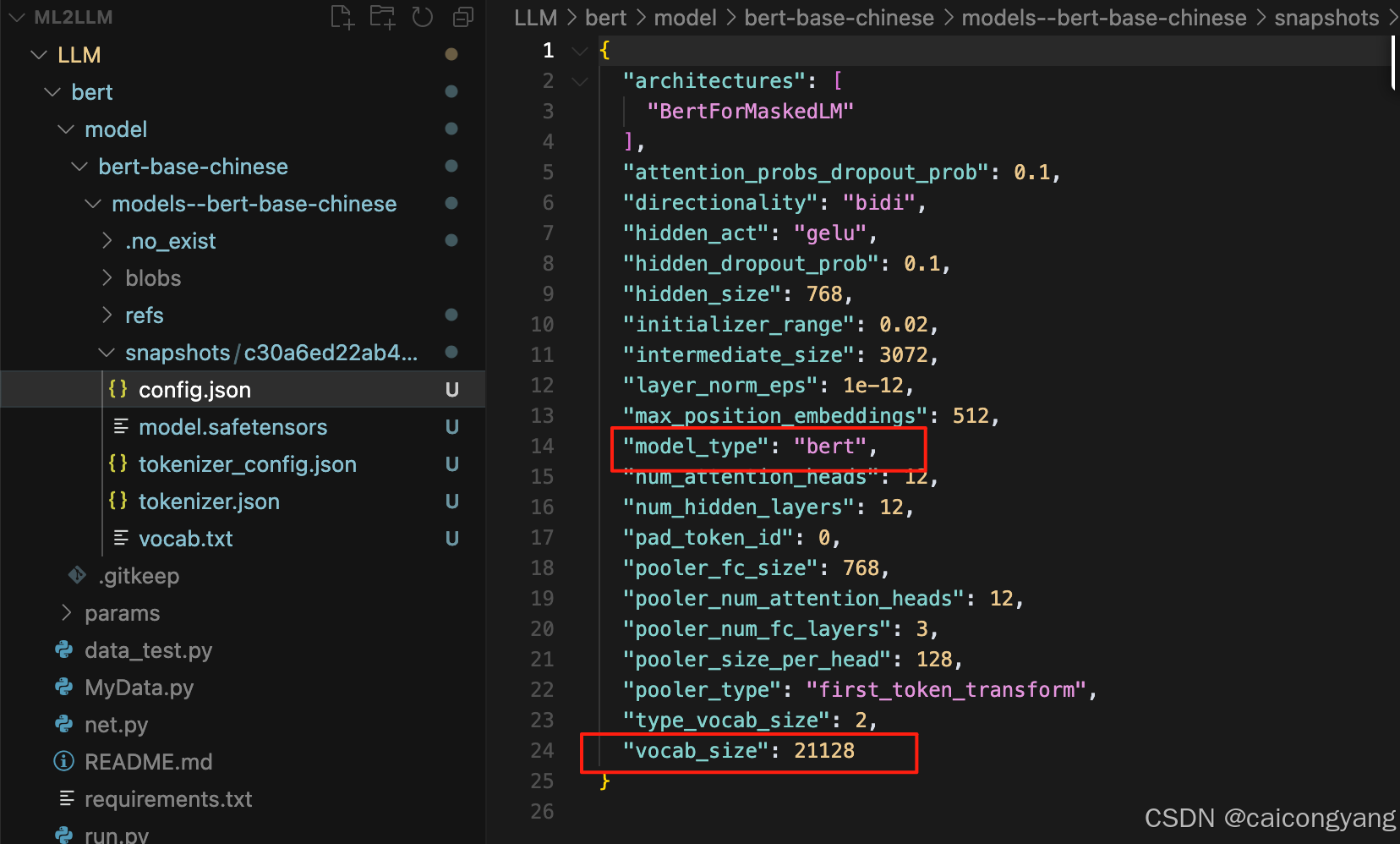
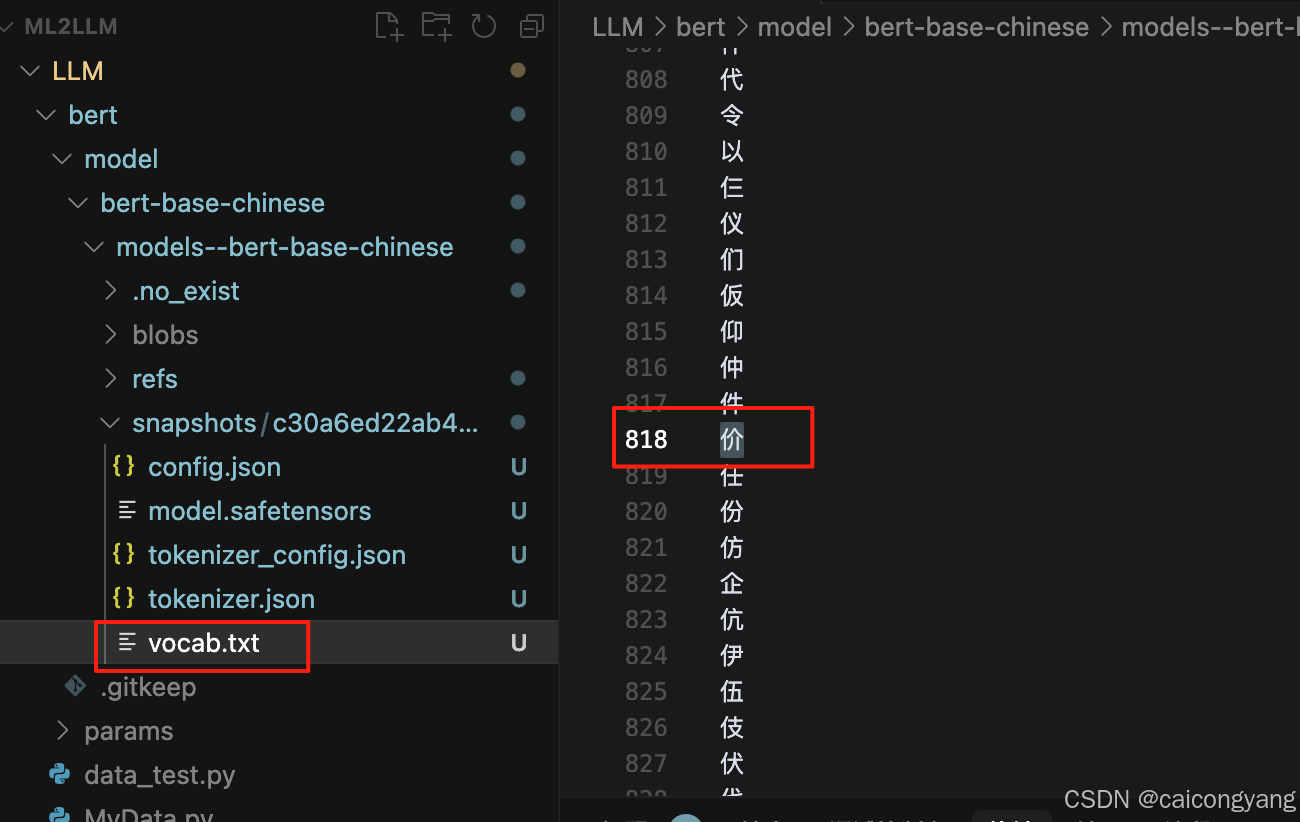 在config.json 中可以看到这个模型最大做事的vocab 是21128
在config.json 中可以看到这个模型最大做事的vocab 是21128
 让我们来写个py测试类来验证编码的过程
让我们来写个py测试类来验证编码的过程
from transformers import AutoTokenizer, BertTokenizer#加载字典和分词器
token = BertTokenizer.from_pretrained("bert-base-chinese")
# print(token)sents = ["价格在这个地段属于适中, 附近有早餐店,小饭店, 比较方便,无早也无所"]#批量编码句子
out = token.batch_encode_plus(batch_text_or_text_pairs=[sents[0]],add_special_tokens=True,#当句子长度大于max_length时,截断truncation=True,max_length=50,#一律补0到max_length长度padding="max_length",#可取值为tf,pt,np,默认为listreturn_tensors=None,#返回attention_maskreturn_attention_mask=True,return_token_type_ids=True,return_special_tokens_mask=True,#返回length长度return_length=True
)
#input_ids 就是编码后的词
#token_type_ids第一个句子和特殊符号的位置是0,第二个句子的位置1()只针对于上下文编码
#special_tokens_mask 特殊符号的位置是1,其他位置是0
print(out)
for k,v in out.items():print(k,";",v)#解码文本数据
# print(token.decode(out["input_ids"][0]),token.decode(out["input_ids"][1]))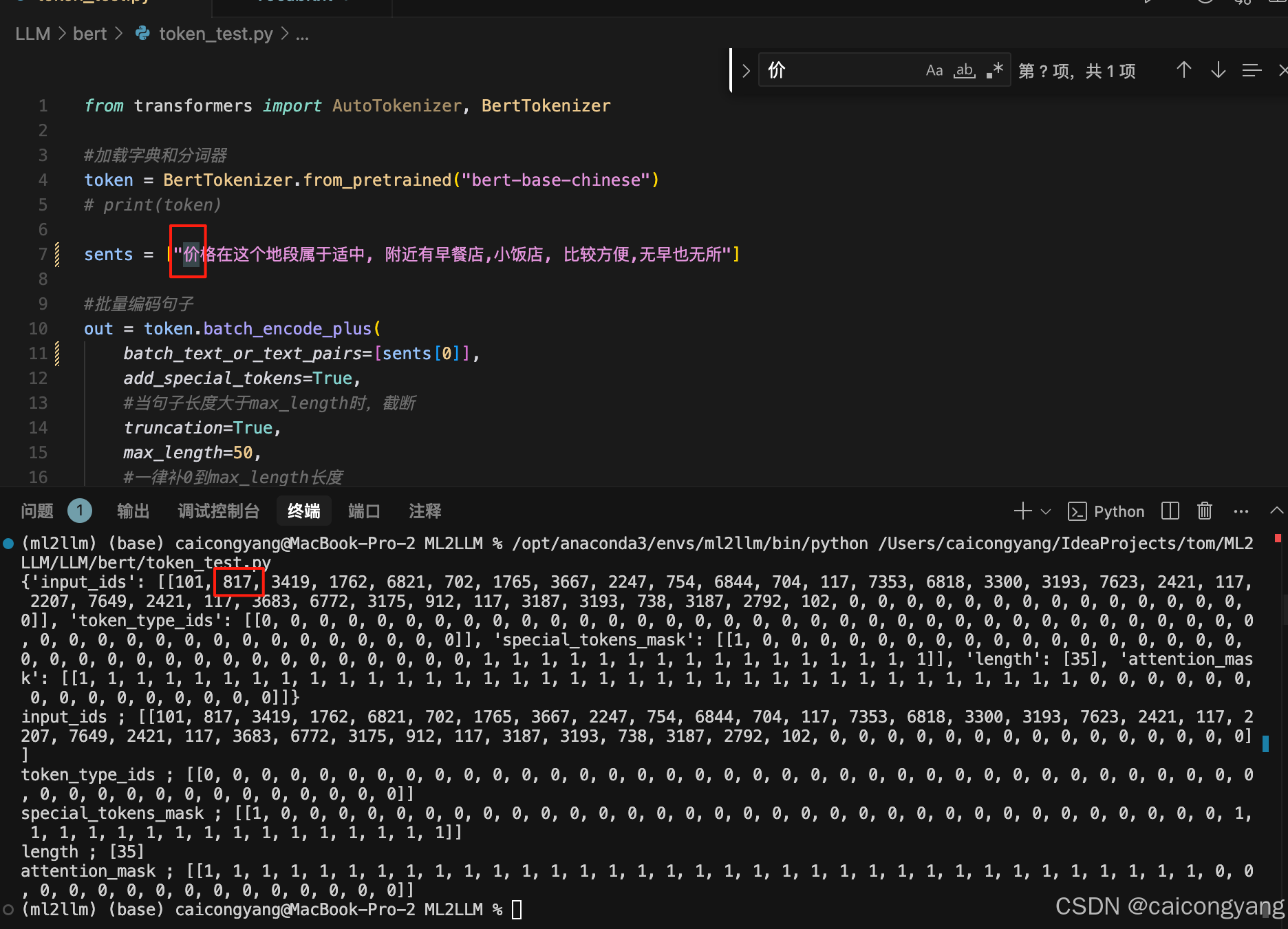
我们可以看到第一字价是字典的817的位置,第一张图已经展示了;整个流程简单的说明了transfomer的Embedding 过程,就是把文字变成 Token的过程;
当然后面的GPT3 这些其他的transfomer 都把这个词典vocab.txt 给隐藏起来了;
多头注意力机制
第一步 embding完后把相近的token 放到一个多维矩阵里面了;这样相近的词就靠的更近了
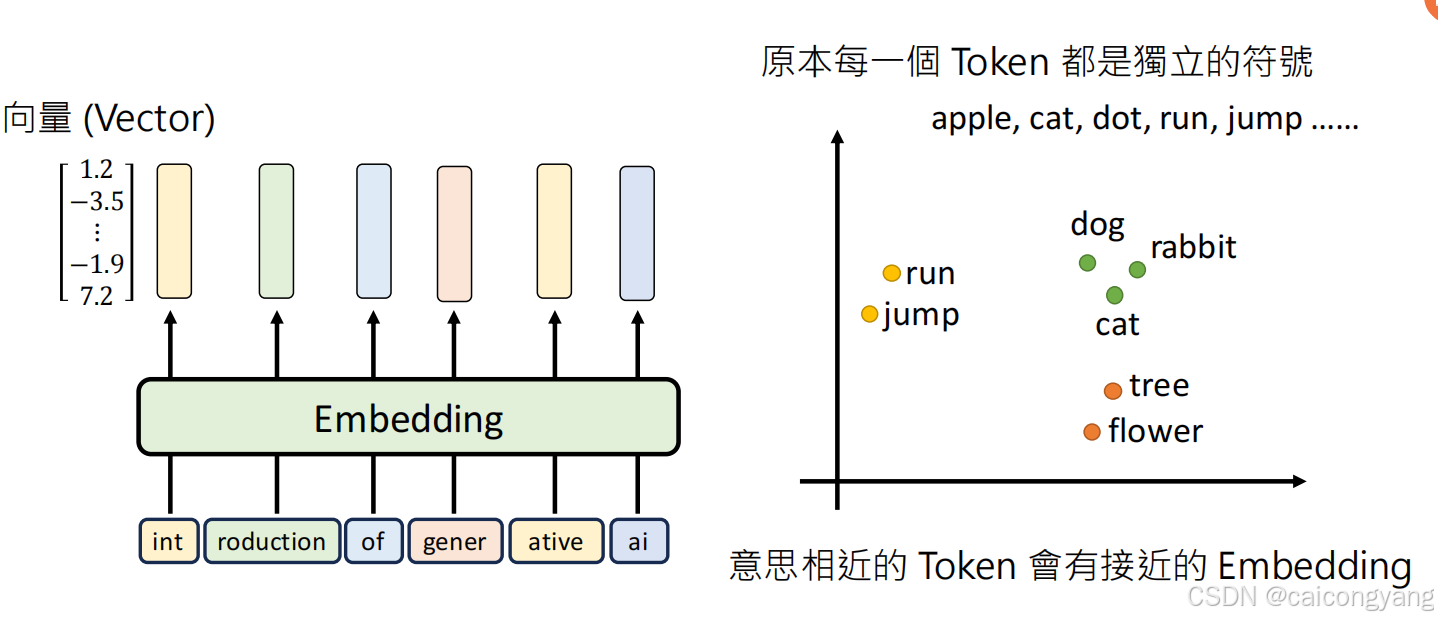
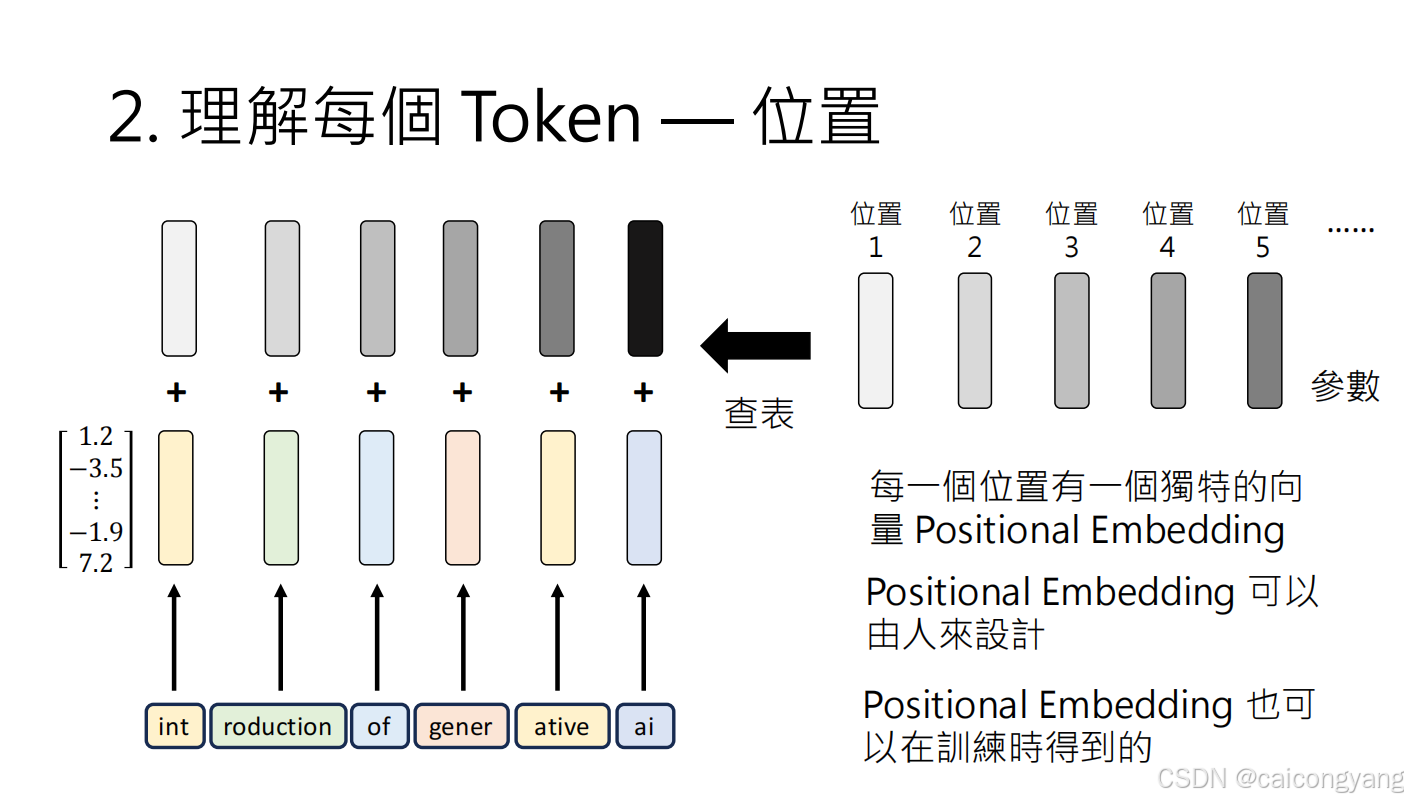
需要加入位置编码,这样矩阵才能感知句子的词的前后顺序
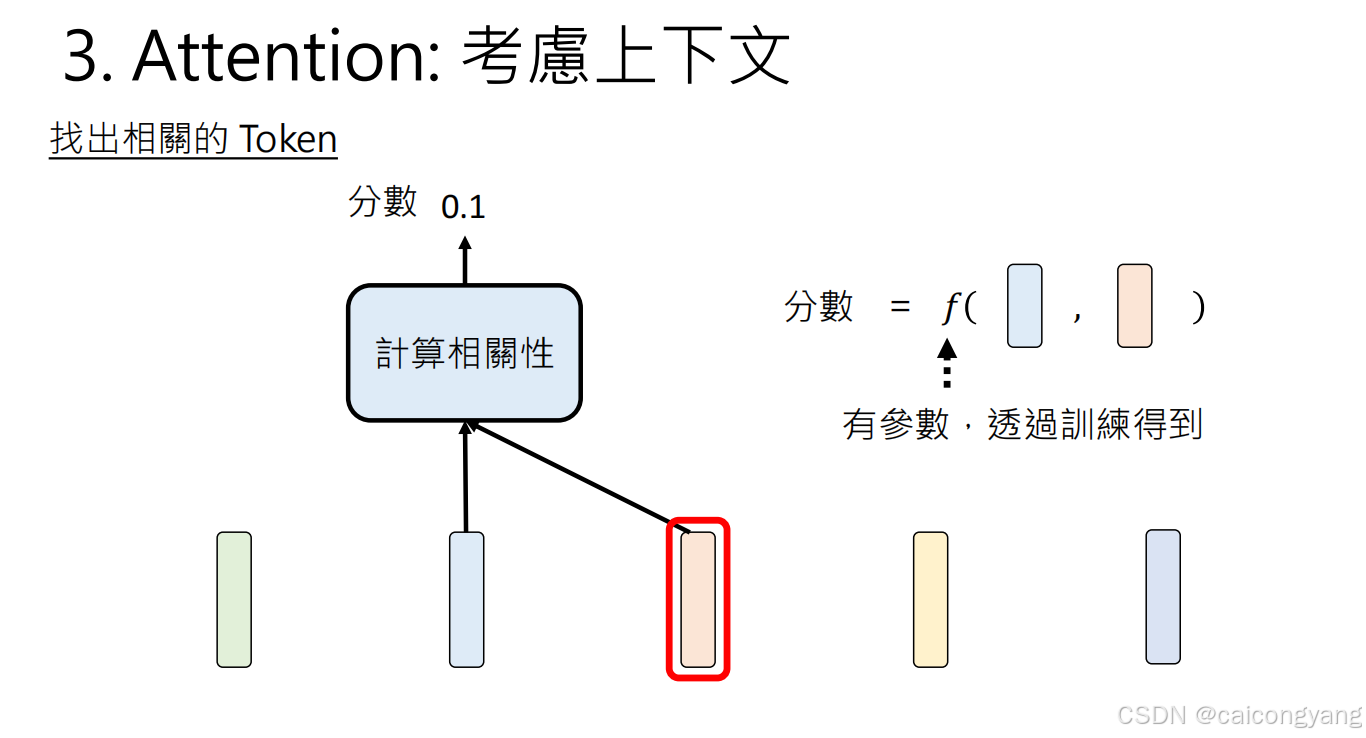
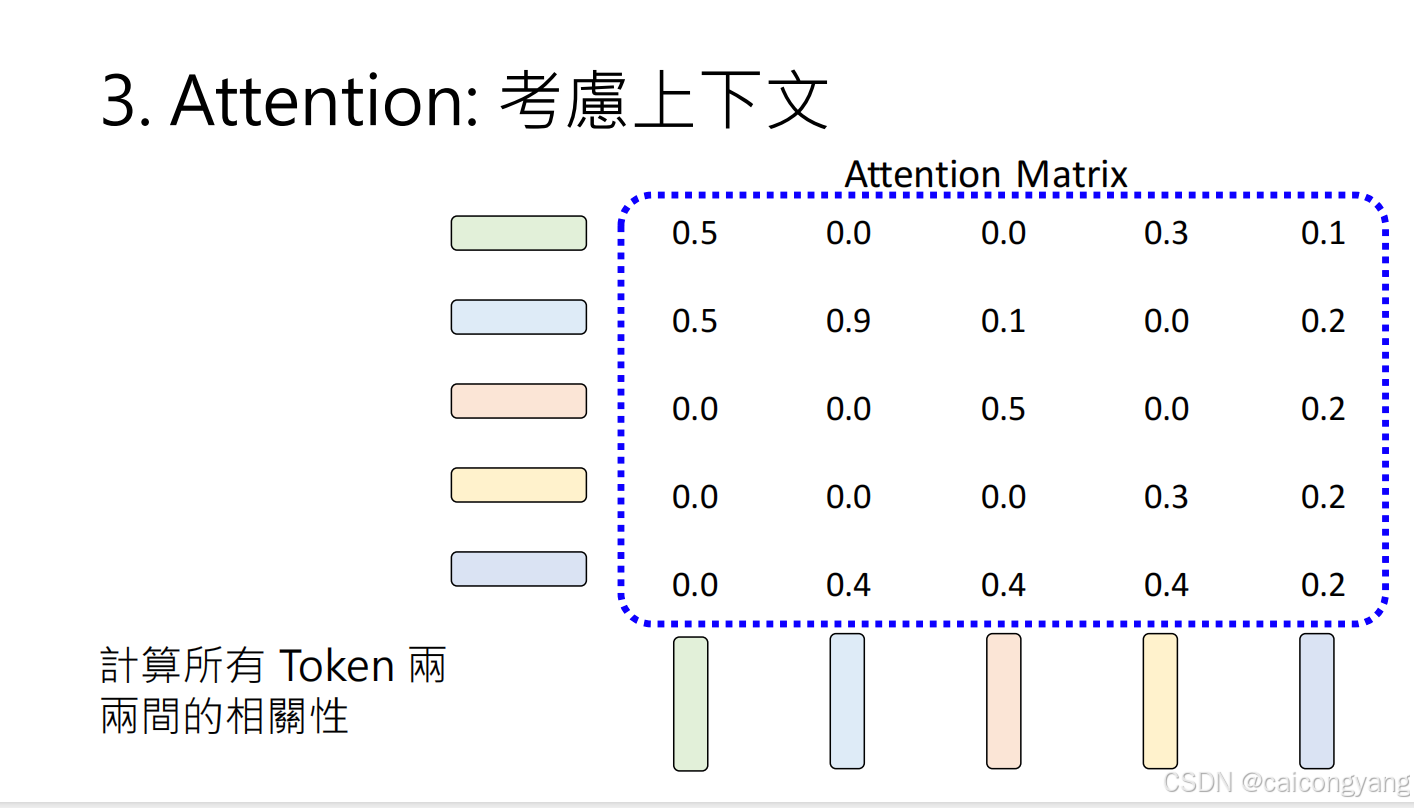
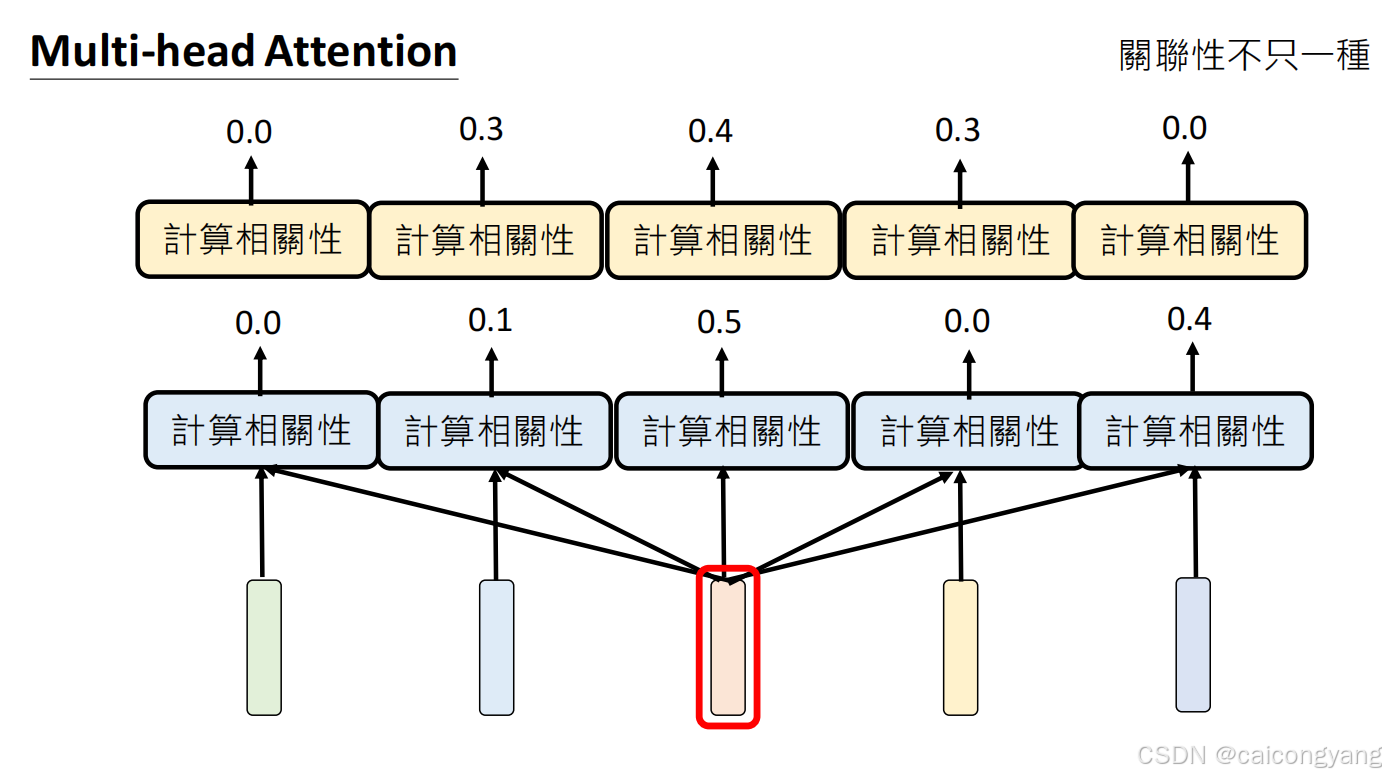
自注意力计算过程:
- 对每个输入token,GPT计算三个向量:查询(Q)、键(K)和值(V)
- 这些向量通过输入与学习到的权重矩阵相乘得到
- 然后计算Q与K的点积来确定注意力分数
- 最后将注意力分数用于对V进行加权求和
这块其实理解的不是很好
Feed Forward
前向传播是模型预测/推理的过程,如图右侧所示。它的步骤非常直观:
- 将数据输入到神经网络
- 数据在网络内部经过一系列数学计算
- 网络输出预测结果
这就像人类的思考过程:接收信息 → 思考处理 → 得出结论。
输出线性层与Softmax:
将解码器输出转换为概率分布
完整流程:
在完整的处理流程中:
- 输入经过嵌入层、位置编码和多层 Transformer 块处理
- 最终的隐藏状态通过一个线性层(通常是与输入嵌入共享权重的)
- 线性层输出经过 softmax 函数转换为概率分布
- 这个概率分布就是最终的输出,表示下一个 token 可能是词表中每个词的概率
对于像 GPT 这样的自回归模型,在每个位置上模型输出的是词表中所有可能 token 的概率分布,最高概率的 token 通常被选为该位置的预测结果。
这些概率是模型对"下一个 token 应该是什么"的预测,是用于实际生成文本或计算损失函数的关键输出。 注意GPT 只使用transformer 中的解码器部分
更多神经网络相关的学习笔记见我的github: https://github.com/caicongyang/ML2LLM/blob/main/LLM/neural_network_fundamentals_simplified.md