分销系统设计泉州seo代理商
1.阅读论文LLM-KT
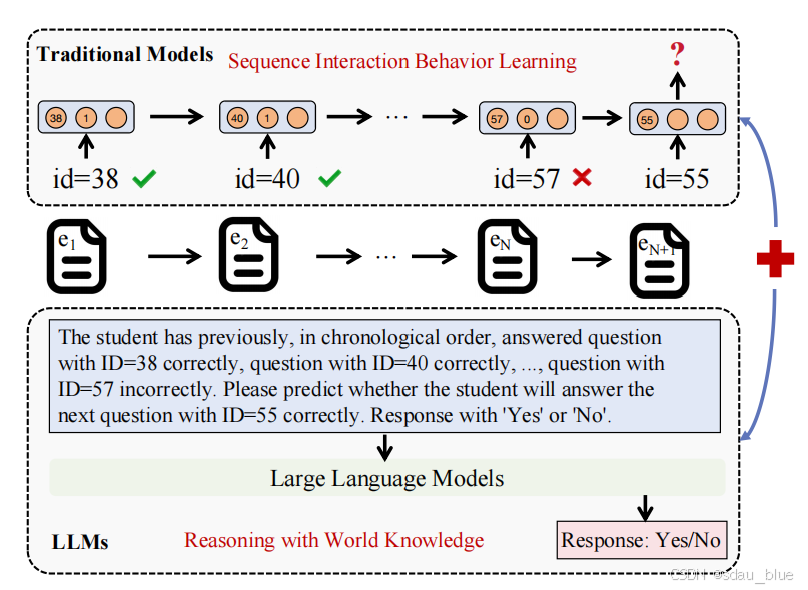
**Context Adapter(上下文适配器)**的作用是:
- 对齐文本表示,使其与大模型的语义空间兼容,从而提升知识追踪模型的效果。
- 通过 MLP 进行映射,将原始的文本表示 rQTtext,rCTtextr_{QT_{text}}, r_{CT_{text}}rQTtext,rCTtext 转换为适配后的表示 hQTtext,hCTtexth_{QT_{text}}, h_{CT_{text}}hQTtext,hCTtext。
- 最终目标是让模型更有效地利用大模型的语义能力,捕捉问题与知识概念的关系
llm只能处理语言序列问题,对id序列的问题处理并不好,用传统dkt方法进行qid和cid的编码,然后于llm进行对齐,解决这一问题
论文2:CLST: Cold-Start Mitigation in Knowledge Tracing by Aligning a Generative Language Model as a Students’ Knowledge Tracer
llm在生成各种教育材料方面表现出了有效的表现,包括多项选择题[33]、阅读理解评估的故事[5]和测验[11]。此外,还对自适应课程设计[42]、自动评分[28]和自动反馈生成进行了研究。
上述由[31]进行的研究的局限性在于,因为它没有充分利用生成性llm的能力,因为练习只是简单地使用id来表示。
学习者解决问题的顺序在KT任务中是至关重要的,而有问题的研究只考虑了每个学习者的正确和错误答案的数量。
关于KT的研究是在NLP的背景下进行的,利用了问题中的文本数据。例如,运动增强递归神经网络(EERNN)[44]利用每个练习的文本来预测学生利用马尔可夫属性或注意机制的反应。Word2vec [29]用于将每个练习的单词转换为单词嵌入,练习嵌入随后通过双向长短期记忆(LSTM)网络学习。运动意识知识追踪(EKT)[24]是EERNN的一个扩展版本,其中部署了一个记忆网络来量化每个练习对学生掌握多个知识成分的贡献
此外,[46]利用BERT [10]嵌入练习中文本数据之间的相似性来构建一个图,从而使用分层GNN和两种注意机制来预测学生的反应。然而,这些方法并不依赖于生成语言模型,而是仅仅利用自然语言处理来获得运动表征。换句话说,基于广义的llm的KT模型的有效性仍有很多进一步研究的潜力。在本研究中,我们通过在自然语言中表达KT任务来检验生成性llm与KT对齐的有效性。

搞了半天就这样生成了个格式???
3.多模态大模型中的图片文本对齐
详见博客:
多模态大模型中的图片文本对齐_图像文本对齐-CSDN博客
论文11:Large Language Model with Graph Convolution for Recommendation
向用户推荐top_n个项目;
方法:我们提出的GacLLM的总体体系结构如图3所示。它有四个主要模块。首先,我们对LLM进行了监督微调(SFT),以激活其在任务相关领域中的功率。其次,我们提出了一种基于llm的图感知卷积推理策略,以逐步增强对用户和项目的描述。第三,我们将生成的描述对齐并融合到基于图形的用户和项目嵌入中。最后,我们介绍了该方法的目标函数和学习过程。
4.1具体流程
首先微调一下llm
我们使用了提示模板:“查询:给定一个项目的描述,生成一个适合它的用户描述。”项目的描述为“项目描述”。答:“,其中[项目描述]被替换为项目的实际描述.
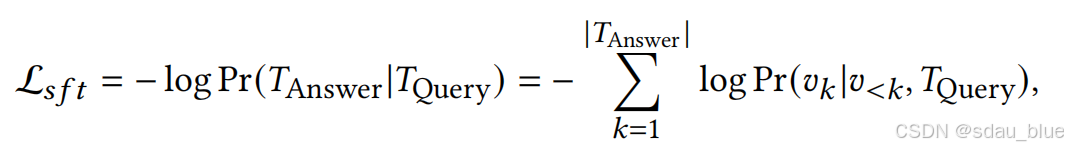
利用lora策略进行参数学习。
4.2基于llm的卷积推理
4.2.1 图构造
图的节点有item和user构成,图中的每个节点都有一个文本描述,比如电影的摘要、社交网络上用户的个人资料和求职者的简历。
4.2.2 基于llm的卷积推理策略
提出了一种基于llm的卷积推理策略来探索图中描述的高阶关系
利用llm来重写用户的原始描述T𝑢,PROMPTuser表示用户描述生成(重写)的模板。
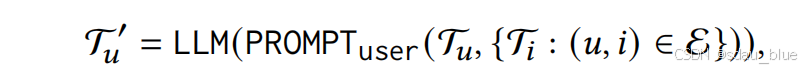
对称地,我们利用llm来重写该项目的原始描述T𝑖的描述。
然后进行层层迭代。

语言直观理解:
把这个方法想象成 逐步“扩散”信息,让每个节点(用户 & 物品)更好地理解整个图结构:
- 第一层:用户的描述只包含自己的原始文本,物品的描述也只包含自己的原始文本。
- 第二层:用户的描述不仅包含自己的信息,还融合了与之连接的物品的文本信息;同样,物品的描述也融合了与之连接的用户信息。
- 更多层次后:用户可以获取到更远距离(L-hop)的邻居信息,比如 朋友的朋友喜欢的物品,或者 相似用户的行为数据。
最终,LLM 通过逐步整合图中的关系,增强每个节点的语义理解能力,提升知识推理的效果。
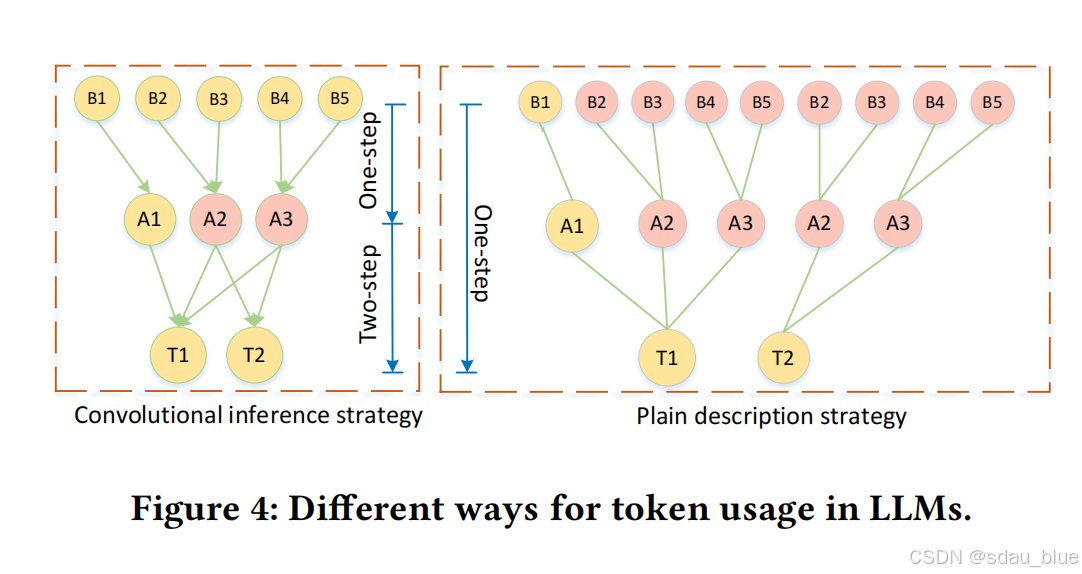
4.2.3 基于llm的卷积策略的优势
1.最少到最多的推理:llm在其迭代聚合过程中采用了一种顺序的方法,以最少到最多的方式逐步构建对用户和项目的高质量描述。该策略将图分割成一个如图2所示的层次结构,突出了llm对复杂的基于图的知识的适应性
2.更有效(Effectiveness):利用 LLM 有限的上下文长度,逐步提取重要信息,而不是一次性输入所有内容。
更高效(Efficiency):减少冗余信息的计算,降低 token 数量,提高计算速度,使方法更适用于真实世界任务。
4.3Aligning GCN-based Embeddings for Recommendation -对基于 GCN(图神经网络)的嵌入进行对齐,以用于推荐任务。
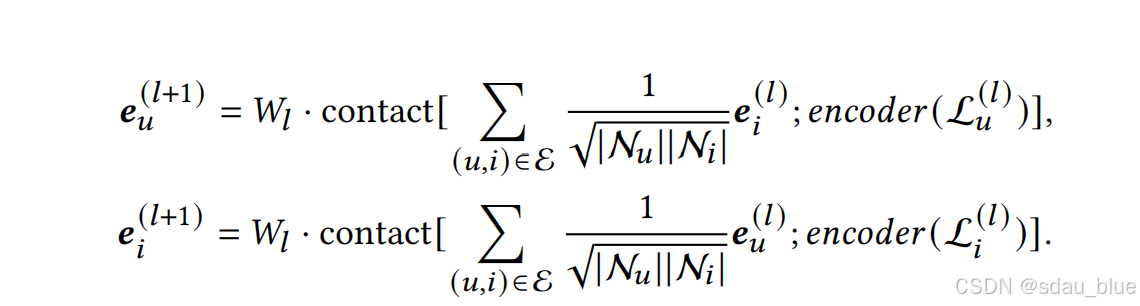




-
引入文本信息对齐(Text Alignment)
- 传统 GCN 只利用图结构信息,该方法额外引入文本描述信息,使嵌入更加丰富。
- 采用
simbert-base-chinese2编码文本,并与 GCN 生成的嵌入融合。
-
逐层信息整合(Multi-Layer Aggregation)
- 结合多层 GCN 计算结果,避免单层表示能力不足的问题。
-
高效的推荐计算(Efficient Matching via Inner Product)
- 采用内积计算用户-物品的匹配分数,提高计算效率。
-
优化目标设计(Pairwise Loss)
- 采用成对损失,使模型能够更准确地学习用户的偏好。