网站建设设如何推广好一个产品
一、联邦平均(FedAvg):基础聚合范式
1. 原理
- 核心逻辑:将所有客户端的模型更新按数据量或客户端数量加权平均。假设客户端
的更新为
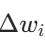 ,对应数据量为
,对应数据量为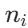 ,总数据量为
,总数据量为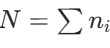 ,则联邦平均的聚合结果为:
,则联邦平均的聚合结果为: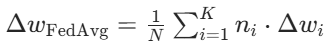
- 本质:通过加权平均整合各客户端的局部优化结果,推动全局模型向 “平均最优” 方向迭代。
2. 作用
- 加速收敛:利用多客户端数据的统计特性,减少单一客户端的噪声影响,提升模型泛化能力。
- 适配数据异构:数据量越大的客户端对全局更新的贡献越大,符合 “数据驱动” 的优化逻辑。
3. 在联邦学习中的应用场景
- 常规联邦学习任务:如图像分类、自然语言处理等,当客户端数据分布相对均衡或不存在恶意攻击时,FedAvg是最常用的聚合方式。
- 强调效率的场景:FedAvg的计算复杂度低,通信开销小,适合对实时性要求高的应用(如手机端模型更新)。
4. 与数据隐私的联系
- 隐私保护的局限性:FedAvg 直接聚合原始梯度或参数更新,若恶意服务器或客户端记录更新值,可能通过梯度反演等手段推断原始数据特征(如图像像素、文本内容)。
- 需结合隐私增强技术:通常需搭配差分隐私(DP)、同态加密(HE)等技术,对更新值添加噪声或加密后再聚合,避免隐私泄露。
二、中位数聚合:抗攻击的鲁棒性方案
1、原理
2. 作用
- 抵御恶意攻击:有效防范拜占庭攻击、梯度投毒等恶意行为,避免模型被少数异常更新误导。
- 减少离群值影响:对良性客户端因数据异质性产生的离群更新也有一定过滤作用。
3. 在联邦学习中的应用场景
- 不可信环境下的联邦学习:如跨机构合作(医疗、金融),参与方可能存在恶意行为或数据质量参差不齐。
- 对模型安全性要求高的场景:如自动驾驶、工业控制,模型被攻击可能导致严重后果。
4. 与数据隐私的联系
- 隐私保护的间接增强:中位数聚合通过过滤极端更新,减少了恶意客户端利用异常梯度反推原始数据的可能性(极端更新可能包含更多数据特征偏差)。
- 与隐私技术的互补性:可与差分隐私结合,进一步降低更新值的可追溯性 —— 例如,先对更新添加噪声,再取中位数,既能抗攻击又能保护隐私。
三、两者对比:原理、作用与隐私特性
| 维度 | 联邦平均(FedAvg) | 中位数聚合(Median Aggregation) |
|---|---|---|
| 核心原理 | 加权平均,强调数据量权重 | 排序取中位数,依赖多数良性更新的数量优势 |
| 抗攻击能力 | 易受少数恶意更新污染(如梯度投毒) | 鲁棒性强,当 f < 50%时可过滤恶意更新 |
| 数据隐私保护 | 需依赖外部隐私技术(如 DP、HE) | 天然过滤极端更新,降低隐私泄露风险,但仍需结合 DP 等技术 |
| 适用场景 | 数据分布均衡、信任度高的场景 | 存在恶意参与者或数据异质性强的场景 |
| 计算与通信开销 | 低(线性加权计算) | 高(需传输所有更新并排序) |
| 对数据异构的适应性 | 数据量大的客户端主导更新,可能忽略小数据客户端 | 平等对待所有客户端更新,可能保留小数据客户端的有效信息 |
四、与联邦学习数据隐私的深层联系
-
联邦学习的隐私困境: 联邦学习的核心目标是 “数据不动模型动”,但模型更新(如梯度)仍可能隐含数据隐私信息。FedAvg(联邦平均)和中位数聚合作为聚合层技术,需与底层隐私保护手段(如差分隐私、安全多方计算)结合,形成完整的隐私保护体系。
-
抗攻击与隐私的协同:
- 恶意攻击(如梯度投毒)可能通过注入虚假更新间接获取或破坏隐私,中位数聚合通过抗攻击间接维护隐私安全。
- 差分隐私等技术通过添加噪声保护更新隐私,但可能引入噪声导致模型偏差,中位数聚合可作为后处理手段,在保护隐私的同时提升模型鲁棒性。