企业网站界面优化搜狗排名
一、摘要
本文介绍2018年的一篇推荐领域经典论文《Self-Attentive Sequential Recommendation》,这篇论文借鉴了当时大热的Transformer架构,在推荐模型中融入自注意力机制,提出了SASRec模型。

译文:
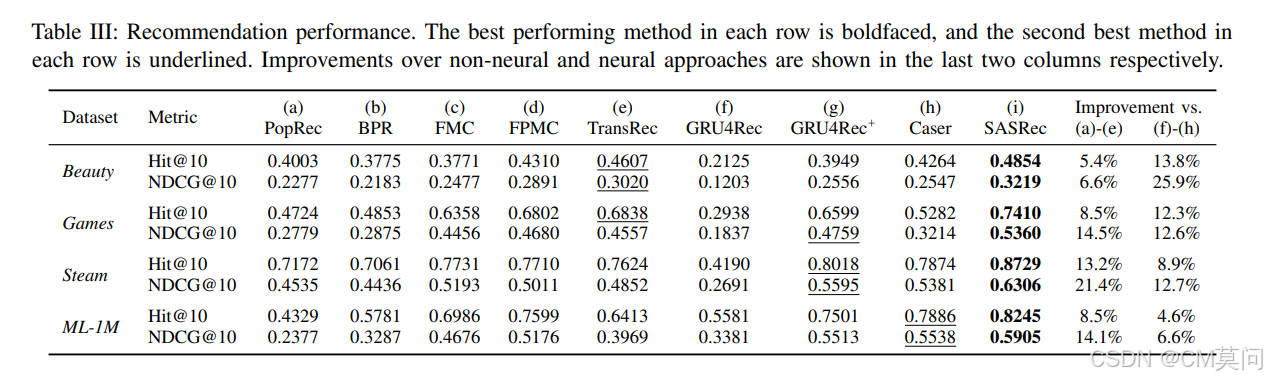
序列动态是许多现代推荐系统的一个关键特征,这些系统试图根据用户最近执行的操作来捕捉其活动的 “上下文”。为了捕捉这种模式,两种方法得到了广泛应用:马尔可夫链(MCs)和循环神经网络(RNNs)。马尔可夫链假设可以仅根据用户的最后一个(或最后几个)操作来预测其下一个操作,而循环神经网络原则上可以揭示更长期的语义。一般来说,基于马尔可夫链的方法在极其稀疏的数据集上表现最佳,在这种数据集中模型的简洁性至关重要,而循环神经网络在更密集的数据集上表现更好,在这种数据集中更高的模型复杂度是可以接受的。我们工作的目标是平衡这两个目标,提出一种基于自注意力的序列模型(SASRec),它使我们能够捕捉长期语义(类似于循环神经网络),但通过使用注意力机制,基于相对较少的操作进行预测(类似于马尔可夫链)。在每个时间步,SASRec试图从用户的操作历史中识别哪些项目是 “相关的”,并利用它们来预测下一个项目。大量实证研究表明,我们的方法在稀疏和密集数据集上均优于各种最先进的序列模型(包括基于MC/CNN/RNN的方法)。此外,该模型比类似的基于CNN/RNN的模型效率高出一个数量级。注意力权重的可视化也展示了我们的模型如何自适应地处理不同密度的数据集,并揭示活动序列中有意义的模式。
二、核心创新点
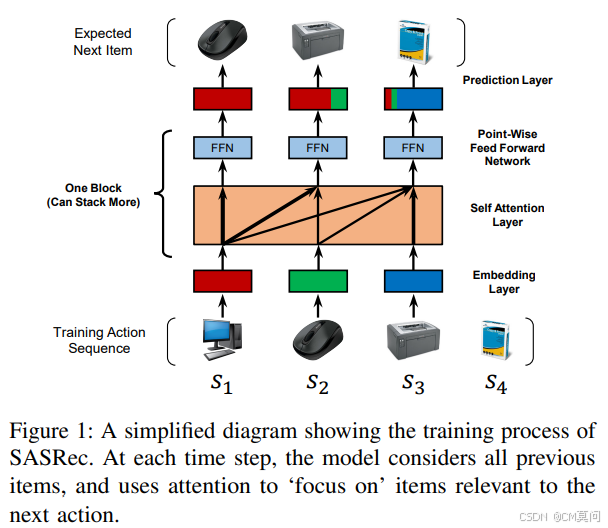
序列推荐系统的目标是基于用户的近期行为,将用户行为的个性化模型(基于历史活动)与某种“上下文”概念相结合。但作者指出,由于输入空间的维度会随着上下文规模而呈指数增长,所以在其中捕捉有用的模式具有挑战性。受当时的Transformer架构影响,作者试图将自注意力机制应用于序列推荐问题,因此提出了SASRec模型,并取得了较好的表现。下面由下至上介绍模型架构
1、嵌入层
首先,作者将训练序列转换为固定长度的序列 s,并设置最大处理长度 n,如果序列长度大于n,则考虑最近n个用户行为,如果序列长度小于n则重复在左侧添加一个“padding”项(附0值),直到长度为n。由此,作者创建了一个item嵌入矩阵 M,并检索输入的嵌入矩阵 E。由于自注意力机制不包含任何递归或者卷积模块,作者认为这样的机制无法得知先前item的位置信息,因此增加了一个可学习的位置嵌入向量P到输入的embedding中(即E)。
2、自注意力模块
标准的注意力机制定义如下:
其中,Q代表查询值,K代表键值,V代表注意力值(每行代表一个item)。直观地说,注意力层计算所有注意力值的加权和,其中查询值 i 和注意力值 j 之间的权重与查询值 i 和键值 j 之间的交互有关。缩放因子是为了避免内积的值过大,尤其是维度较高的情况下。在机器翻译等NLP任务中,注意力机制通常在K=V的情况下使用。例如在使用编码器-解码器架构进行翻译时,编码器的隐藏状态既是键也是值,而解码器的隐藏状态是查询。
自注意力机制则是将相同的对象用作查询、键和值。在论文的例子中,自注意力操作将带可学习位置参数的输入嵌入作为输入,通过线性投影将其转换为三个矩阵,并输入到注意力层:
由于序列的性质,模型在预测第(t+1)个元素时应当仅考虑前 t 个元素。但自注意力机制的第 t 个输入会包含后续元素的嵌入信息。为了解决这个问题,作者通过禁止和
之间的所有连接来修改注意力计算方式。
作者认为,尽管自注意力机制能够通过自适应权重来聚合所有历史item的嵌入,但它仍然是个线性模型。为了赋予模型非线性,并考虑不同潜在维度之间的相互作用,作者对所有的嵌入应用相同的point-wise两层前馈神经网络(参数共享):
其中,和
之间没有相互作用,因此可以防止从后向前的信息泄露。
3、堆叠自注意力模块
为了增强模型的表达能力,作者将多个自注意力模块进行堆叠。同时,为了缓解由于网络变深而导致的容易过拟合、梯度消失等问题,作者执行以下操作:
其中,g(x)代表自注意力层或者前馈网络。这意味着,对于每个模块中的 g 层,都在输入 x 被喂入 g 层之前应用一个层归一化策略,并对 g 层的输出应用dropout机制,在最后的输出上在加上原始输入x。
4、预测层
经过 b 个自注意力模块之后,模型已经具备较好的表达能力。因此,给出前 t 个item,可以基于模型进行下一个item的预测。作者在预测层加入了矩阵分解等策略实现最终的item预测,具体可参考源文。