网站开发测试过程企业网站推广可以选择哪些方法
自动微分
自动微分模块torch.autograd负责自动计算张量操作的梯度,具有自动求导功能。自动微分模块是构成神经网络训练的必要模块,可以实现网络权重参数的更新,使得反向传播算法的实现变得简单而高效。
1. 基础概念
-
张量
Torch中一切皆为张量,属性requires_grad决定是否对其进行梯度计算。默认是 False,如需计算梯度则设置为True。
-
计算图:
torch.autograd通过创建一个动态计算图来跟踪张量的操作,每个张量是计算图中的一个节点,节点之间的操作构成图的边。
在 PyTorch 中,当张量的 requires_grad=True 时,PyTorch 会自动跟踪与该张量相关的所有操作,并构建计算图。每个操作都会生成一个新的张量,并记录其依赖关系。当设置为
True时,表示该张量在计算图中需要参与梯度计算,即在反向传播(Backpropagation)过程中会自动计算其梯度;当设置为False时,不会计算梯度。 -
x 和 y 是输入张量,即叶子节点,z 是中间结果,loss 是最终输出。每一步操作都会记录依赖关系:
z = x * y:z 依赖于 x 和 y。
loss = z.sum():loss 依赖于 z。
这些依赖关系形成了一个动态计算图,如下所示:
x y
\ /
\ /
\ /
z
|
|
v
loss
detach():张量 x 从计算图中分离出来,返回一个新的张量,与 x 共享数据,但不包含计算图(即不会追踪梯度)。
特点:
-
返回的张量是一个新的张量,与原始张量共享数据。
-
对 x.detach() 的操作不会影响原始张量的梯度计算。
-
推荐使用 detach(),因为它更安全,且在未来版本的 PyTorch 中可能会取代 data。
-
反向传播
使用tensor.backward()方法执行反向传播,从而计算张量的梯度。这个过程会自动计算每个张量对损失函数的梯度。例如:调用 loss.backward() 从输出节点 loss 开始,沿着计算图反向传播,计算每个节点的梯度。
-
梯度
计算得到的梯度通过tensor.grad访问,这些梯度用于优化模型参数,以最小化损失函数。
2. 计算梯度
使用tensor.backward()方法执行反向传播,从而计算张量的梯度
2.1 标量梯度计算
参考代码如下:
import torchdef test001():# 1. 创建张量:必须为浮点类型x = torch.tensor(1.0, requires_grad=True)# 2. 操作张量y = x ** 2# 3. 计算梯度,也就是反向传播y.backward()# 4. 读取梯度值print(x.grad) # 输出: tensor(2.)if __name__ == "__main__":test001()向量梯度计算
# 1. 创建张量:必须为浮点类型
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
# 2. 操作张量
y = x ** 2
# 3. 计算梯度,也就是反向传播
y.backward()
# 4. 读取梯度值
print(x.grad)
我们也可以将向量 y 通过一个标量损失函数(如 y.mean())转换为一个标量,反向传播时就不需要提供额外的梯度向量参数了。这是因为标量的梯度是明确的,直接调用 .backward() 即可。
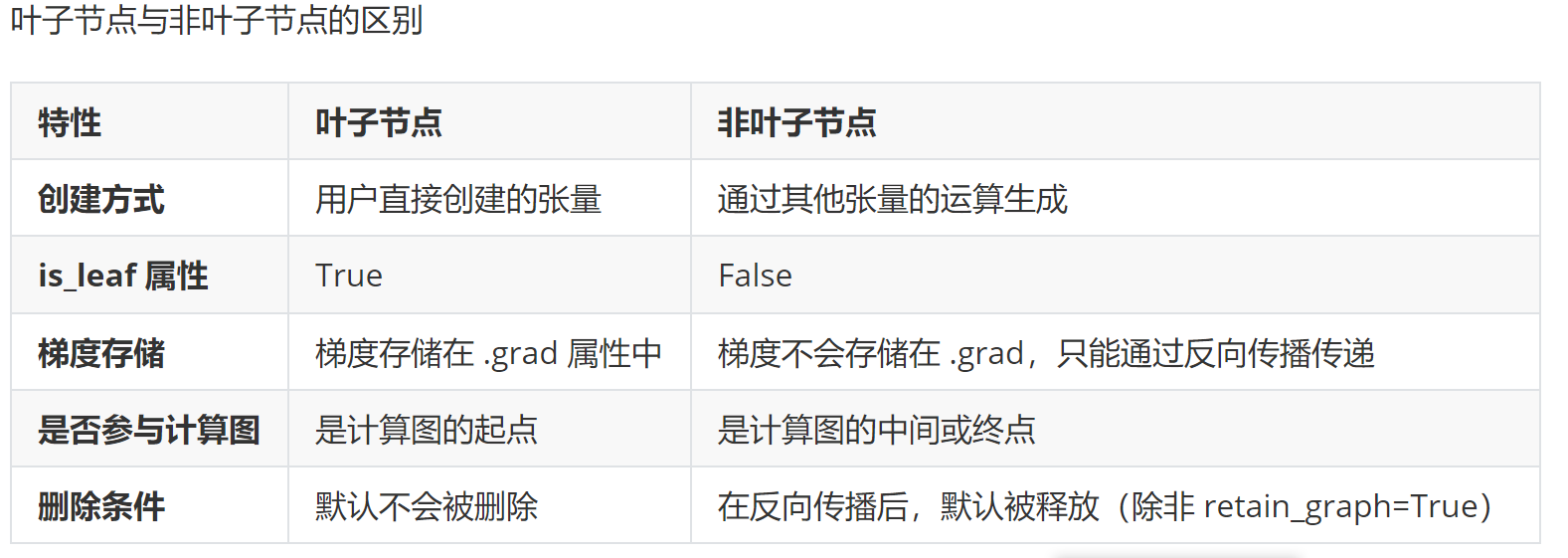
调用 loss.backward() 从输出节点 loss 开始,沿着计算图反向传播,计算每个节点的梯度。
损失函数loss=mean(y)=\frac{1}{n}∑_{i=1}^ny_i,其中 n=3。
对于每个 y_i,其梯度为 \frac{∂loss}{∂y_i}=\frac{1}{n}=\frac13。
对于每个 x_i,其梯度为:
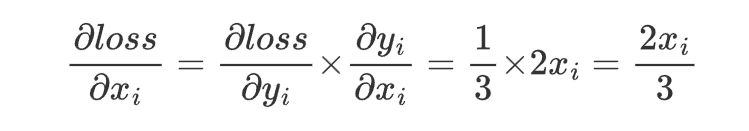
模型定义组件
模型(神经网络,深度神经网络,深度学习)定义组件帮助我们在 PyTorch 中定义、训练和评估模型等。
在进行模型训练时,有三个基础的概念我们需要颗粒度对齐下:

常用损失函数举例:
1.均方误差损失(MSE Loss)
-
函数: torch.nn.MSELoss
-
适用场景: 通常用于回归任务,例如预测连续值。
-
特点: 对异常值敏感,因为误差的平方会放大较大的误差。
2.L1 损失(L1 Loss)
也叫做MAE(Mean Absolute Error,平均绝对误差)
-
函数: torch.nn.L1Loss
-
适用场景: 用于回归任务,对异常值的敏感性较低。
-
特点: 比 MSE 更鲁棒,但计算梯度时可能不稳定。
3.交叉熵损失(Cross-Entropy Loss)
-
函数: torch.nn.CrossEntropyLoss
-
参数:reduction:mean-平均值,sum-总和
-
公式:
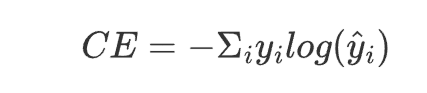
-
适用场景: 用于多分类任务,输入是未经 softmax 处理的 logits。
-
特点: 自带 softmax 操作,适合分类任务,能够有效处理类别不平衡问题。
4.二元交叉熵损失(Binary Cross-Entropy Loss)
-
函数: torch.nn.BCELoss 或 torch.nn.BCEWithLogitsLoss
-
参数:reduction:mean-平均值,sum-总和
-
公式:
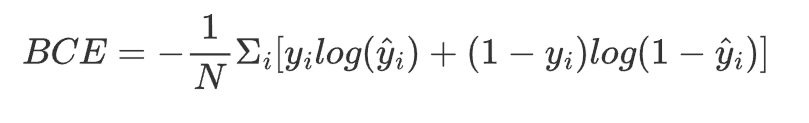
-
适用场景: 用于二分类任务。
-
特点: BCEWithLogitsLoss 更稳定,因为它结合了 Sigmoid 激活函数和 BCE 损失。