济南网站推广效果厦门网站制作全程服务
在前文《存储调研:云原生文件系统JuiceFS,第01篇》中已经初步了解了JuiceFS的背景,发展演进、基础架构、核心功能、主要优势和应用场景。
本文将帮助理解JuiceFS文件系统的技术架构、源码框架、程序初始化等内容,可以清晰了解JuiceFS的技术内涵和实现。
关注“渡江客涂鸦板”,技术文章抢先看。
一、框架设计
在分布式文件系统中有核心三要素:元数据、数据、客户端。在Google File System(GFS)的论文中给出了经典的基础架构,如下图所示。

GFS的技术架构示意图
JuiceFS是一款面向云原生设计的高性能分布式文件系统,采用数据和元数据分离存储的技术架构。技术架构如下图所示,同样包括客户端、数据存储引擎和元数据引擎三部分。

其中:
客户端,所有文件读写,以及碎片合并、回收站文件过期删除等后台任务,均在客户端中发生。客户端需要同时与对象存储和元数据引擎打交道。客户端支持多种接入方式:
-
通过FUSE,JuiceFS文件系统能够以POSIX兼容的方式挂载到服务器,将海量云端存储直接当做本地存储来使用。
-
通过Hadoop Java SDK,JuiceFS文件系统能够直接替代HDFS,为Hadoop提供低成本的海量存储。
-
通过Kubernetes CSI驱动,JuiceFS文件系统能够直接为Kubernetes提供海量存储。
-
通过S3网关,使用S3作为存储层的应用可直接接入,同时可使用AWS CLI、s3cmd、MinIO Client 等工具访问JuiceFS文件系统。
-
通过WebDAV服务,以HTTP协议,以类似RESTful API 的方式接入 JuiceFS 并直接操作其中的文件。
数据存储引擎,文件将会被切分上传至对象存储服务。JuiceFS 支持几乎所有的公有云对象存储,同时也支持OpenStack Swift、Ceph、MinIO 等私有化的对象存储。
元数据引擎,用于存储文件元数据(metadata),包含以下内容:
-
常规文件系统的元数据:文件名、文件大小、权限信息、创建修改时间、目录结构、文件属性、符号链接、文件锁等。
-
文件数据的索引:文件的数据分配和引用计数、客户端会话等。
JuiceFS 采用多引擎设计,目前已支持 Redis、TiKV、MySQL/MariaDB、PostgreSQL、SQLite 等作为元数据服务引擎,也将陆续实现更多元数据存储引擎。
JuiceFS同样采用核心三要素架构,同时也实现了创新:
首先,在数据存储方面,架构图下面的对象存储对应GFS的ChunkServer的角色,是JuiceFS的存储层。JuiceFS没有再重新设计一个数据存储层,而是借助了已经被广泛使用的对象存储技术,有效利用对象存储在扩展性、持久性安全、低成本等方面的优势。因此,JuiceFS选择站在对象存储的肩膀上来构建文件系统。
然后,在元数据管理方面,JuiceFS在元数据管理上做了分析和抽象之后,明确了管理元数据的引擎所需要的能力,包括数据结构、事务能力、效率、扩展性和成本等。实现或寻找满足所有要求的引擎是非常困难的。因此,JuiceFS选择支持多引擎的元数据管理服务。目前社区版已支持Redis、TKV、SQL等作为元数据服务引擎,后续也将陆续实现更多元数据存储引擎,用户可以综合业务需求选择合适的元数据存储引擎。
最后,在客户端方面,实现完全兼容Posix协议的文件系统,规避对象存储的不足。同时提供S3网关实现S3协议兼容的访问接口,并且可以通过Kubernetes CSI驱动集成轻松地在Kubernetes中使用。
二、分层框架
JuiceFS在软件设计上是一个可灵活扩展的分层框架,JuiceFS的每个模块都以软件包的形式组件,每个模块都依赖于其下层的模块,如图所示:

JuiceFS社区版的分层架构示意图
JuiceFS这样设计的好处是框架的模块与模块之间的关系都变得逻辑清晰,而模块是与源码中软件包一一对应。作为一个跨平台的软件,对复用和移植到其他平台非常有效率。
接下来,对照源码中软件包,对JuiceFS的组件一一介绍。
JuiceFS Client Core
Object模块:源码目录pkg/object,实现多种数据存储的统一抽象,适配不同协议,如file、S3、HDFS等,同时也适配不同厂商的存储,如阿里云存储OSS,华为云存储OBS等,并与具体的数据存储设备进行通信和交互,屏蔽底层数据存储的差异。
Chunk模块:源码目录pkg/chunk,负责进行数据分片和数据组装,同时通过调用object模块实现分片数据的上传下载。
meta:源码目录pkg/meta,实现多种元数据存储的统一抽象,适配不同的数据库,如TiKV、MySQL、Redis等,并与具体的数据库设备进行通信和交互,屏蔽底层数据库的差异。
vfs模块:源码目录pkg/vfs,负责POSIX语义实现,数据操作会进行chunk粒度的拆分,调用chunk模块接口,元数据操作调用meta模块接口。
fuse模块:源码目录pkg/fuse,负责与GO语言的libfuse库进行交互,是Linux内核VFS层调用方法的具体实现。即,将所有VFS定义的调研方法实现转换为JuiceFS文件系统的实现。通过调用vfs模块及下层模块来实现。
fs模块:源码目录pkg/fs,负责与APIs层gateway、Java SDK、winfsp模块的交互,提供文件系统和文件操作能力,使得APIs层的三个无需通过fuse和linux内核VFS 而直接JuiceFS数据存储和元数据存储交互。
utils模块:源码目录pkg/utils,负责共性能力提供,如内存池、日志等。
version模块:源码目录pkg/version,负责JuiceFS客户端的版本管理。
JuiceFS Client APIs
Posix:JuiceFS支持标准的Posix协议,支持Posix访问的各类应用均可通过挂载JuiceFS文件系统来访问该文件存储。
Gateway模块:源码目录pkg/gateway,负责JuiceFS的S3协议网关实现,S3网关以守护进程的形式运行,各类支持S3 API的客户端、桌面程序、Web程序等都可以访问JuiceFS S3网关。
winfsp模块:源码目录pkg/winfsp,由于Windows没有原生支持FUSE接口,需要WinFsp才能实现对FUSE的支持。WinFsp是一个开源的Windows文件系统代理,提供了一个FUSE仿真层,JuiceFS Windows客户端通过winfsp模块实现Windows WinFsp的接口调用,可以将文件系统挂载到Windows系统中使用。winfsp模块调用下层fs、vfs、meta、utils模块实现。
Java SDK模块:源码目录sdk,负责实现与HDFS接口高度兼容的Java 客户端,为Hadoop生态提供存储。
WebDAV:在cmd模块中实现,支持JuiceFS通过WebDAV协议挂载访问。
JuiceFS Client Tools
cmd模块:源码目录cmd,负责JuiceFS客户端命令工具的实现,提供文件系统管理、健康和服务能力。
metric模块:源码目录pkg/metric,负责实现JuiceFS的监控功能,提供友好便捷的可观测能力。
usage模块:源码目录pkg/usage,提供匿名数据上报能力,协助JuiceFS官方理解社区如何使用这个项目。
三、数据布局
与传统文件系统只能使用本地磁盘存储数据和对应的元数据的模式不同,JuiceFS 会将数据格式化以后存储在对象存储,同时会将文件的元数据存储在元数据引擎。在这个过程中,Chunk、Slice、Block是三个重要的概念:
-
chunk:每一个文件都由 1 或多个「Chunk」组成,每个Chunk最大64M。
-
slice:每个chunk可以由一个或者多个变长的slice组成,考虑到覆盖写的支持,slice之间是可以有数据逻辑地址重叠的情况。
-
block:每一个slice,又会拆分成固定大小的block,默认为 4 MiB(文件系统格式化后就不可以修改)。最后block会被压缩或加密保存到对象存储中,压缩/加密可选。

JuiceFS文件组织示意图
(一)数据拆分规则
假设有个文件的inode为100,size为160MiB,那么该文件一共有 (size-1) / 64 MiB + 1 = 3 个 Chunks。

文件的chunk划分示意图
每个chunk都维护一组slice列表,slice主要在数据写入时生成,可能互相之间有覆盖,也可能未完全填充满 chunk,因此,访问chunk数据需要遍历slice列表,并重新构建出最新的slice列表,规则如下:
-
有多个 slice覆盖的部分以最后加入的 slice为准
-
没有被 slice覆盖的部分自动补零,用 sliceId = 0 来表示
-
根据文件 size 截断 Chunk
现假设 Chunk 0 中有 3 个 slice,分别为:
Slice{pos: 10M, id: 10, size: 30M, off: 0, len: 30M}Slice{pos: 20M, id: 11, size: 16M, off: 0, len: 16M}Slice{pos: 16M, id: 12, size: 10M, off: 0, len: 10M}
图示如下(每个 '_' 表示 2 MiB):

重构后的slice新列表:
Slice{pos: 0, id: 0, size: 10M, off: 0, len: 10M}Slice{pos: 10M, id: 10, size: 30M, off: 0, len: 6M}Slice{pos: 16M, id: 12, size: 10M, off: 0, len: 10M}Slice{pos: 26M, id: 11, size: 16M, off: 6M, len: 10M}Slice{pos: 36M, id: 10, size: 30M, off: 26M, len: 4M}Slice{pos: 40M, id: 0, size: 24M, off: 0, len: 24M}
(二)Block命名规则
Block 是 管理数据的基本单元,默认为 4 MiB,且可在文件系统格式化时配置,允许调整的区间范围为 [64 KiB, 16 MiB]。
每个 Block 上传后即为对象存储中的一个对象,命名格式如下:
${fsname}/chunks/${hash}/${basename}其中:
-
fsname 是文件系统名称
-
“chunks”为固定字符串,代表 JuiceFS 的数据对象
-
hash 是根据 basename 算出来的哈希值,起到一定的隔离管理的作用
-
basename 是对象的有效名称,格式为 ${sliceId}_${index}_${size},其中:
-
-
sliceId 为该对象所属slice的 ID,JuiceFS 中每个 slice 都有一个全局唯一的 ID
-
index 是该对象在所属slice中的序号,默认一个 slice 最多能拆成 16 个 Blocks,因此其取值范围为 [0, 16)
-
size是该 Block 的大小,默认情况下其取值范围为 (0, 4 MiB]
-
命名规则实现函数key()
func (s *rSlice) key(indx int) string {if s.store.conf.HashPrefix {return fmt.Sprintf("chunks/%02X/%v/%v_%v_%v",s.id%256, s.id/1000/1000, s.id, indx, s.blockSize(indx))}return fmt.Sprintf("chunks/%v/%v/%v_%v_%v",s.id/1000/1000, s.id/1000, s.id, indx, s.blockSize(indx))}
其中,HashPrefix是文件系统的格式化配置,表示是否为对象名称设置一个散列的前缀,默认关闭。
文件经过分片后,block写入到对象存储,未开启HashPrefix时,对象名命名规则如下:
fsname/chunks/(sliceId/1000/1000)/(sliceId/1000)/sliceId_blockIndex_blockSize开启HashPrefix,对象名命名规则如下:
fsname/chunks/(sliceId%256)/(sliceId/1000/1000)/(sliceId/1000)/sliceId_blockIndex_blockSize四、程序初始化
JuiceFS基于Go程序语言实现,在客户端程序启动时会按照Go语言的初始化次序进行包的初始化。
(一)数据存储引擎初始化
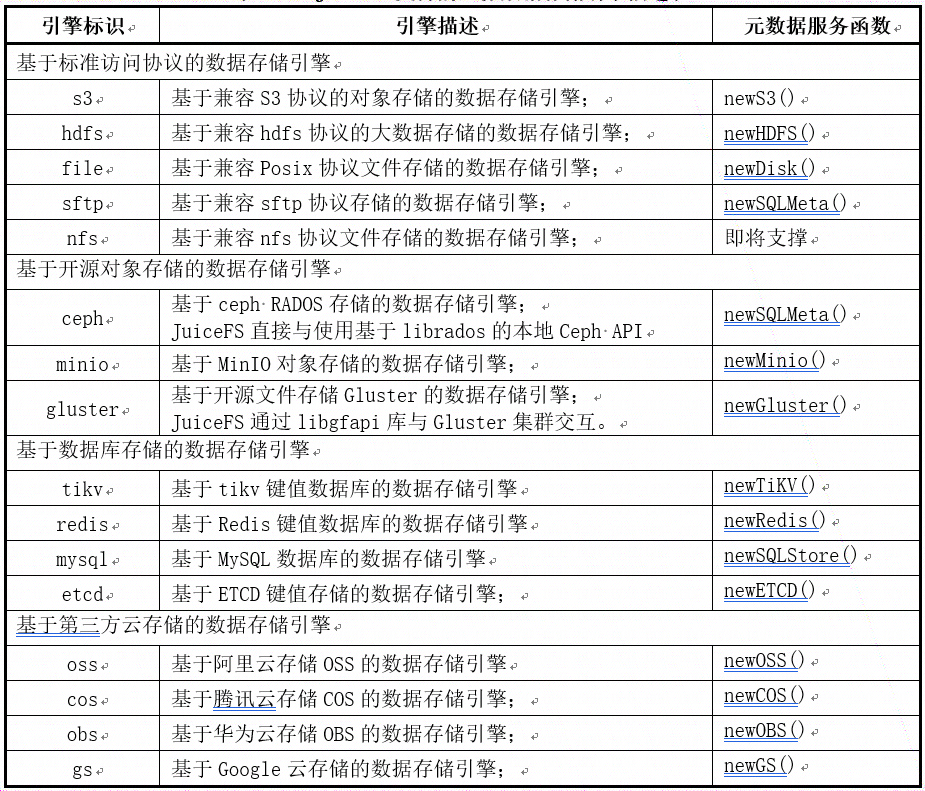
JuiceFS支持多种数据存储引擎,如S3、HDFS、File等标准协议,OSS、COS、OBS等第三方存储、CEPH、MinIO等开源存储。为了统一管理所有数据存储引擎,在object软件包定义了全局变量storages。
storages定义与赋值函数代码片段(pkg/object/object_storage.go)
type Creator func(bucket, accessKey, secretKey, token string) (ObjectStorage, error)var storages = make(map[string]Creator)func Register(name string, register Creator) {storages[name] = register
}首先,定义函数类型Creator,有三个传入参数,分别表示:
第一个参数bucket,string类型,表示数据存储位置,以兼容S3协议的对象存储为例,该参数为http://192.168.80.101:9000/myjfs-%d/;
第二、三个参数accessKey和secretKey,string类型,表示数据存储访问公钥和私钥;
第四个参数token,string类型,表示用来访问对象存储的session token,
有两个返回值者,分别表示:
-
ObjectStorage:数据存储服务对象,描述数据存储引擎的属性信息;
-
error:操作结果,如果失败则返回错误码
然后,定义storages键值对集合,以数据存储引擎标识为键,以Creator为值;
最后,定义函数Register(),实现storages变量的赋值。
在object包中的各数据引擎实现中均有定义init初始化函数,在程序启动初始阶段被执行。以数据引擎S3的初始化为例,定义如下:
S3对象存储的数据存储引擎初始化代码片段(pkg/object/s3.go)
func init() {Register("s3", newS3)
}其他数据存储引擎的初始化定义不再赘述。
经过init函数的初始化,最终完成storages的定义,建立了数据存储引擎标识(如S3、HDFS、File等)与数据服务new###的映射关系。下表是已经支持的主流数据存储引擎。
JuiceFS支持的主流数据存储引擎描述表:
未完待续……
关注“渡江客涂鸦板”,技术文章抢先看。
参考资料:
[01] JuiceFS官网:https://juicefs.com/docs/zh/community/introduction
[02] github社区:https://github.com/juicedata/juicefs