宣城网站建设百度电脑版网页版入口
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章地址: 365天深度学习训练营-第P5周:运动鞋分类
- 🍖 作者:K同学啊
一、前期准备
1. 设置GPU
import torch
from torch import nn
import torchvision
from torchvision import transforms,datasets,models
import matplotlib.pyplot as plt
import os,PIL,pathlibdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
devicedevice(type='cuda')
2. 导入数据
data_dir = './data/'
data_dir = pathlib.Path(data_dir)image_count = len(list(data_dir.glob('*/*/*.jpg')))
print("图片总数为:",image_count)图片总数为: 578
classNames = [str(path).split('\\')[2] for path in data_dir.glob('train/*/')]
classNames['adidas', 'nike']
roses= list(data_dir.glob('train/nike/*.jpg'))
PIL.Image.open(str(roses[0]))
3. 数据增强 解决过拟合
train_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
# transforms.CenterCrop(224),#从中心开始裁剪transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
# transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
# transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
# transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=Btransforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差])test_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])batch_size = 32train_dataset = datasets.ImageFolder('./data/train/', transform = train_transforms)
test_dataset = datasets.ImageFolder('./data/test/', transform = test_transforms)train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size, shuffle=True, num_workers=1)classNames = train_dataset.classestrain_dataset.class_to_idx{'adidas': 0, 'nike': 1}
4. 数据可视化
imgs, labels = next(iter(train_dl))
imgs.shapeimport numpy as np# 指定图片大小,图像大小为20宽、5高的绘图(单位为英寸inch)
plt.figure(figsize=(20, 5))
for i, imgs in enumerate(imgs[:20]):npimg = imgs.numpy().transpose((1,2,0))npimg = npimg * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))npimg = npimg.clip(0, 1)# 将整个figure分成2行10列,绘制第i+1个子图。plt.subplot(2, 10, i+1)plt.imshow(npimg)plt.axis('off')
for X,y in test_dl:print('Shape of X [N, C, H, W]:', X.shape)print('Shape of y:', y.shape)breakShape of X [N, C, H, W]: torch.Size([32, 3, 224, 224]) Shape of y: torch.Size([32])
二、构建CNN网络
2.1 搭建简单网络
搭建简单网络后发现由于数据量少导致过拟合,数据增强后最高准确率84%,说明模型不够好,选择改用Resnet18+迁移学习:
2.2 迁移学习
2.2.1 调用resnet18和预训练模型、冻结参数
feature_extract = True# 冻结参数
def set_parameter_requires_grad(model, feature_extracting):if feature_extracting:for param in model.parameters():param.requires_grad = False# 修改输出层
def initialize_model(num_classes, feature_extract, use_pretrained=True):model_ft = models.resnet18(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.fc.in_featuresmodel_ft.fc = nn.Linear(num_ftrs, num_classes)input_size = 32return model_ft, input_sizemodel_ft, input_size = initialize_model(2, feature_extract, use_pretrained=True)
model_ft = model_ft.to(device)
model_ft略
2.2.2 取出输出层参数
取出输出层参数 后面用于训练更新
# 设置训练哪些层
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract: # 自己只训练输出层params_to_update = []for name,param in model_ft.named_parameters():if param.requires_grad == True:params_to_update.append(param)print("\t",name)
else:for name,param in model_ft.named_parameters():if param.requires_grad == True:print("\t",name)Params to learn:fc.weightfc.bias
三、训练模型
3.1 设置超参数
动态学习率
# 优化器设置
optimizer = torch.optim.Adam(params_to_update, lr=1e-4)#要训练啥参数,你来定
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.92)#学习率每7个epoch衰减成原来的1/10
loss_fn = nn.CrossEntropyLoss()# def adjust_learning_rate(optimizer, epoch, start_lr):
# # 每2个 epoch衰减到原来的0.98
# lr = start_lr * (0.92 ** (epoch //2))
# for param_group in optimizer.param_groups:
# param_group['lr'] = lr# optimizer = torch.optim.Adam(params_to_update,lr=1e-4)3.2 编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小,一共900张图片num_batches = len(dataloader) # 批次数目,29(900/32)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss3.3 编写测试函数
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,8(255/32=8,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss3.4 正式训练
3.4.1 训练输出层
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0
filename='checkpoint.pth'for epoch in range(epochs):model_ft.train()epoch_train_acc, epoch_train_loss = train(train_dl, model_ft, loss_fn, optimizer)scheduler.step()#学习率衰减model_ft.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model_ft, loss_fn)# 保存最优模型if epoch_test_acc > best_acc:best_acc = epoch_test_accstate = {'state_dict': model_ft.state_dict(),#字典里key就是各层的名字,值就是训练好的权重'best_acc': best_acc,'optimizer' : optimizer.state_dict(),}torch.save(state, filename)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
print('best_acc:',best_acc)Epoch:17, Train_acc:65.9%, Train_loss:0.630, Test_acc:67.1%,Test_loss:0.615 Epoch:18, Train_acc:66.1%, Train_loss:0.613, Test_acc:64.5%,Test_loss:0.599 Epoch:19, Train_acc:63.7%, Train_loss:0.636, Test_acc:65.8%,Test_loss:0.579 Epoch:20, Train_acc:66.3%, Train_loss:0.612, Test_acc:65.8%,Test_loss:0.583 Done best_acc: 0.6593625498007968
3.4.2 训练所有层
for param in model_ft.parameters():param.requires_grad = True# 再继续训练所有的参数,学习率调小一点
optimizer = torch.optim.Adam(model_ft.parameters(), lr=1e-4)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.92)# 损失函数
criterion = nn.CrossEntropyLoss()# 加载之前训练好的权重参数
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model_ft.load_state_dict(checkpoint['state_dict'])epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0
filename='best_resnet18.pth'for epoch in range(epochs):model_ft.train()epoch_train_acc, epoch_train_loss = train(train_dl, model_ft, loss_fn, optimizer)scheduler.step()#学习率衰减model_ft.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model_ft, loss_fn)# 保存最优模型if epoch_test_acc > best_acc:best_acc = epoch_test_accstate = {'state_dict': model_ft.state_dict(),#字典里key就是各层的名字,值就是训练好的权重'best_acc': best_acc,'optimizer' : optimizer.state_dict(),}torch.save(state, filename)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
print('best_acc:',best_acc)Epoch:18, Train_acc:99.8%, Train_loss:0.010, Test_acc:86.8%,Test_loss:0.398 Epoch:19, Train_acc:99.0%, Train_loss:0.031, Test_acc:93.4%,Test_loss:0.203 Epoch:20, Train_acc:99.2%, Train_loss:0.019, Test_acc:93.4%,Test_loss:0.184 Done best_acc: 0.9342105263157895
四、结果可视化
加载训练好的模型
model_ft, input_size = initialize_model(2, feature_extract, use_pretrained=True)# GPU模式
model_ft = model_ft.to(device)# 保存文件的名字
filename='best_resnet18.pth'# 加载模型
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model_ft.load_state_dict(checkpoint['state_dict'])结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()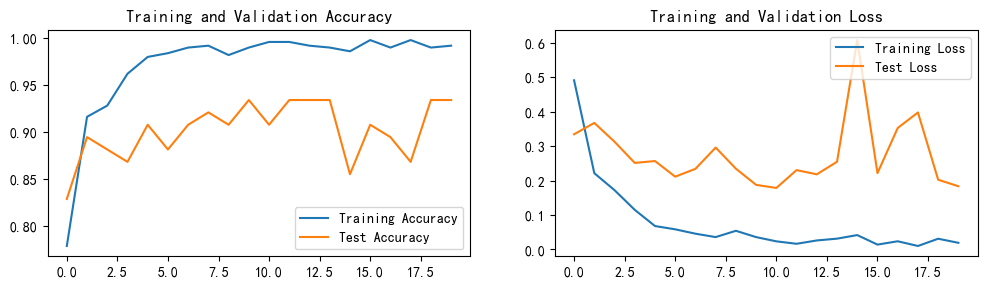
测试模型
train_on_gpu = True# 得到一个batch的测试数据
imgs, labels = next(iter(train_dl))# 进行预测
model_ft.eval()if train_on_gpu:output = model_ft(imgs.cuda())
else:output = model_ft(imgs)# 获得预测结果(概率最大的)
_, preds_tensor = torch.max(output, 1)preds = np.squeeze(preds_tensor.numpy()) if not train_on_gpu else np.squeeze(preds_tensor.cpu().numpy())
predsarray([0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1,0, 0, 0, 0, 1, 0, 1, 0, 0, 1], dtype=int64)
import numpy as np# 指定图片大小,图像大小为20宽、5高的绘图(单位为英寸inch)
plt.figure(figsize=(20, 10))
for idx, imgs in enumerate(imgs[:10]):#ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])npimg = imgs.numpy().transpose((1,2,0))npimg = npimg * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))npimg = npimg.clip(0, 1)# 将整个figure分成2行10列,绘制第i+1个子图。ax = plt.subplot(2, 5, idx+1)ax.set_title("{} ({})".format(classNames[preds[idx]], classNames[labels[idx]]),color=("green" if classNames[preds[idx]]==classNames[labels[idx]] else "red"))plt.imshow(npimg)plt.axis('off')