网站建设与管理难学吗百度url提交
Linux安装部署百度飞桨3.0
- 1.官方文档指引
- 2.确认服务器型号
- 2.1 确认Python版本
- 2.2 确认pip是否安装
- 2.3 确认计算平台
- 3.本机安装(基于通过 pip 安装)
- 3.1 下载安装 PaddlePaddle
- 3.2 安装PaddleX
- 3.2.1 安装PaddleX
- 3.2.2 命令行规范
- 3.2.3 运行示例
- 3.2.4 查看python安装的包所在位置
- 3.3 安装高性能推理插件
- 3.4 卸载pip安装的paddlepaddle和paddlex
- 4.docker安装(基于 Docker 安装飞桨)
- 4.1 检查docker版本
- 4.2 安装飞桨 PaddlePaddle
- 4.2.1 Docker 版本 >= 19.03
- 4.2.1.1 各版本命令
- 4.2.1.2 执行
- 4.2.2 Docker 版本 <= 19.03 但 >= 17.06
- 4.3 基于Docker获取PaddleX
- 4.3.1 Docker 版本 >= 19.03
- 4.3.1.1各版本命令
- 4.3.1.2 运行
- 4.3.2 Docker 版本 <= 19.03 但 >= 17.06
- 5.PaddleX 服务化部署(基于pip部署,基础服务化部署)
- 5.1 官方部署文档
- 5.2 安装服务化部署插件
- 5.3 与 服务化部署相关的命令行选项
- 5.4 安装一条产线
1.官方文档指引
PaddleX 3.0 是基于飞桨框架构建的低代码开发工具,它集成了众多开箱即用的预训练模型,可以实现模型从训练到推理的全流程开发,支持国内外多款主流硬件,助力AI 开发者进行产业实践。
Python 运行环境:目前支持 Python 3.8 至 Python 3.12。PaddleX 3.0-rc0 版本依赖的 PaddlePaddle 版本为 3.0.0rc0以上版本。
飞桨:开始使用
PaddleX:PaddleX 文档
【注:本文使用Linux系统、pip方式安装、英伟达芯片】
2.确认服务器型号
2.1 确认Python版本
确认Python版本是否满足框架最低版本要求
python --version

2.2 确认pip是否安装
- 什么是 pip ?
pip 是 Python 中的标准库管理器。它允许你安装和管理不属于 Python标准库 的其它软件包。 - 查看是否安装
pip --version

- 安装pip(如未安装pip)
sudo apt install python3-pip
2.3 确认计算平台
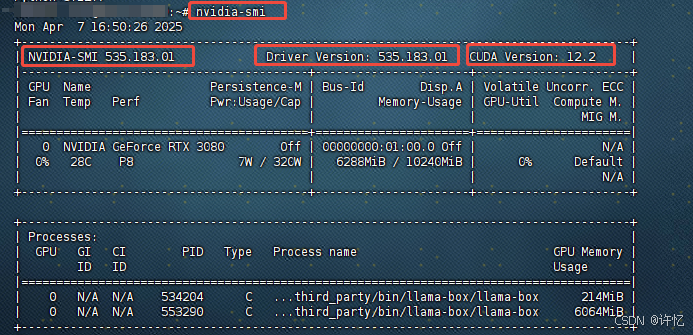
- 查看显卡驱动程序版本
nvidia-smi
“Driver Version” 后面的数字就是当前 NVIDIA 显卡驱动的版本号
3.本机安装(基于通过 pip 安装)
3.1 下载安装 PaddlePaddle
根据自己服务器的版本信息,选择合适的paddle进行安装
# cpu
python -m pip install paddlepaddle==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/# gpu,该命令仅适用于 CUDA 版本为 11.8 的机器环境
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/# gpu,该命令仅适用于 CUDA 版本为 12.3 的机器环境
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu123/
我们这里选择450.80.02+(cu118)版本
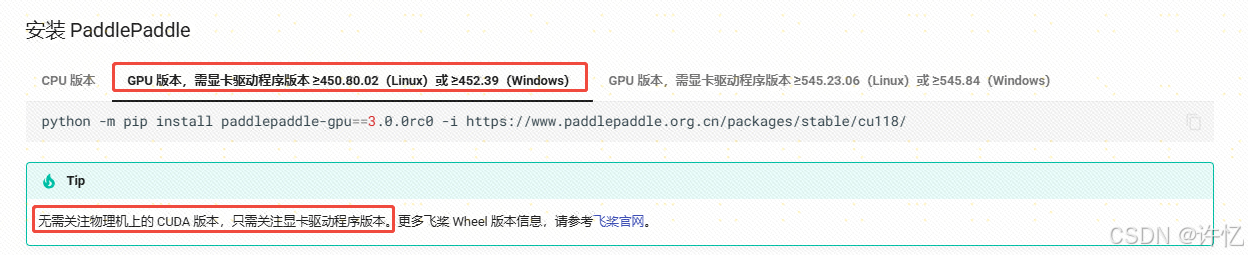
# gpu,该命令仅适用于 CUDA 版本为 11.8 的机器环境
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
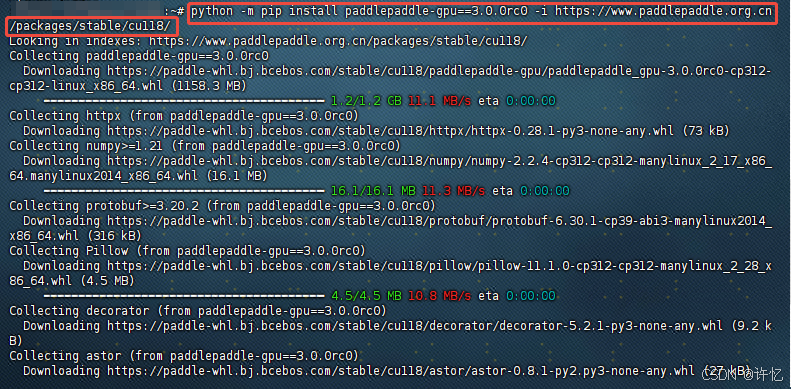
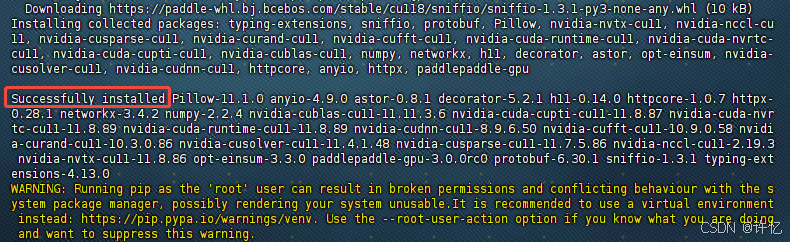
显示Successfully installed,即表示成功。
3.2 安装PaddleX
3.2.1 安装PaddleX
pip install paddlex==3.0rc0
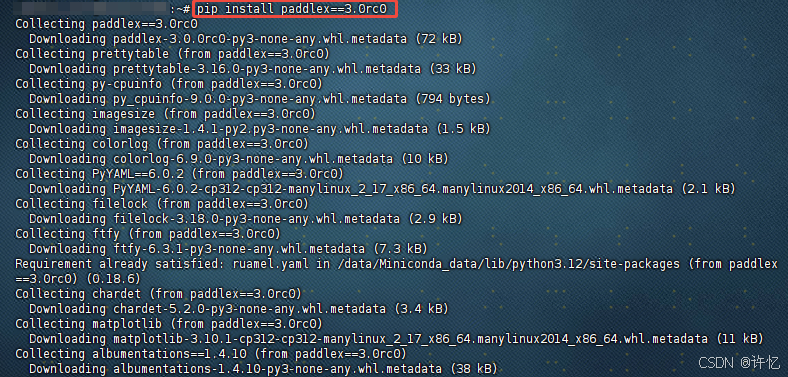
安装时间有点长,需要耐心等待,出现如下页面即表示安装成功。
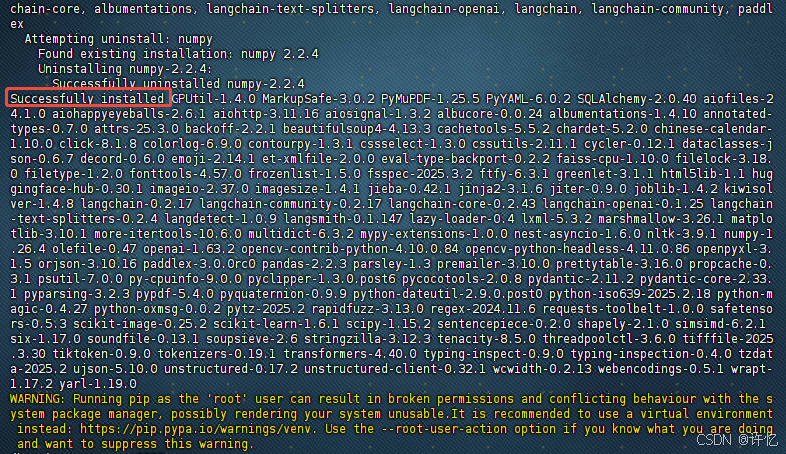
3.2.2 命令行规范
统一的命令行格式为:
paddlex --pipeline [产线名称] --input [输入图片] --device [运行设备]
PaddleX的每一条产线对应特定的参数,您可以在各自的产线文档中查看具体的参数说明。每条产线需指定必要的三个参数:
- pipeline:产线名称或产线配置文件
- input:待处理的输入文件(如图片)的本地路径、目录或 URL
- device: 使用的硬件设备及序号(例如gpu:0表示使用第 0 块 GPU),也可选择使用 NPU(npu:0)、 XPU(xpu:0)、CPU(cpu)等
3.2.3 运行示例
# 通用OCR
paddlex --pipeline image_classification --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg --device gpu:0
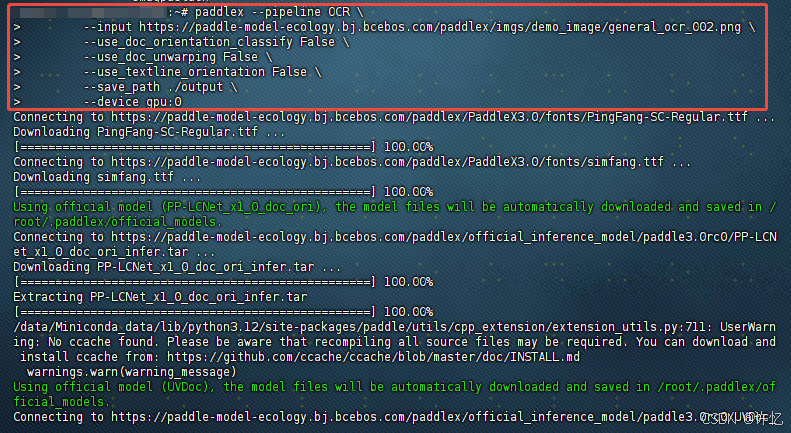

运行结果示例
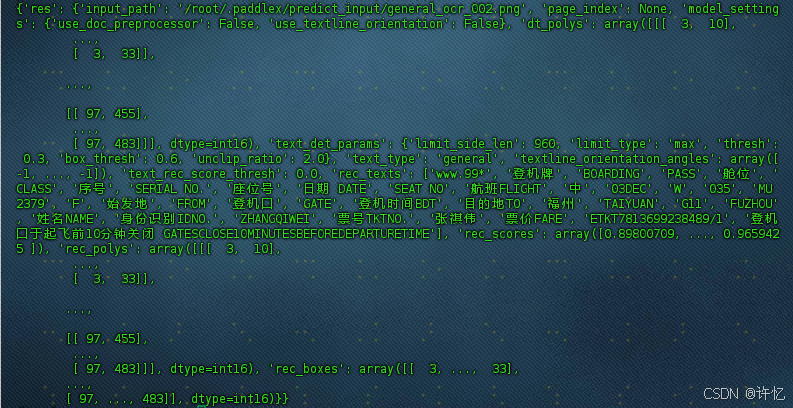
3.2.4 查看python安装的包所在位置
进入python命令行

import site
print(site.getsitepackages())
3.3 安装高性能推理插件
如果你的设备是 CPU,请使用以下命令安装 PaddleX 的 CPU 版本:
paddlex --install hpi-cpu
如果你的设备是 GPU,请使用以下命令安装 PaddleX 的 GPU 版本。请注意,GPU 版本包含了 CPU 版本的所有功能,因此无需单独安装 CPU 版本:
paddlex --install hpi-gpu# 或者(使用清华源)paddlex --install hpi-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple
我这里是gpu,所以使用的是第二个

目前高性能推理支持的处理器架构、操作系统、设备类型和 Python 版本如下表所示:
| 处理器架构 | 操作系统 | 设备类型 | Python 版本 |
|---|---|---|---|
| x86-64 | Linux | CPU | 3.8–3.12 |
| x86-64 | Linux | GPU (CUDA 11.8 + cuDNN 8.6) | 3.8–3.12 |
3.4 卸载pip安装的paddlepaddle和paddlex
- 查看已安装的paddlepaddle paddlex
pip list | grep paddle

- 卸载
# paddlepaddle-gpu paddlex 根据上述查询出来的决定
pip uninstall paddlepaddle-gpu paddlex


4.docker安装(基于 Docker 安装飞桨)
4.1 检查docker版本
docker --version

4.2 安装飞桨 PaddlePaddle
我的docker版本是24.0.7,所以选择第一个安装方案。
4.2.1 Docker 版本 >= 19.03
4.2.1.1 各版本命令
# 对于 cpu 用户:
docker run --name paddlex -v $PWD:/paddle --shm-size=8G --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.0.0rc0 /bin/bash# 对于 gpu 用户:
# GPU 版本,需显卡驱动程序版本 ≥450.80.02(Linux)或 ≥452.39(Windows)
docker run --gpus all --name paddlex -v $PWD:/paddle --shm-size=8G --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.0.0rc0-gpu-cuda11.8-cudnn8.6-trt8.5 /bin/bash# GPU 版本,需显卡驱动程序版本 ≥545.23.06(Linux)或 ≥545.84(Windows)
docker run --gpus all --name paddlex -v $PWD:/paddle --shm-size=8G --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.0.0rc0-gpu-cuda12.3-cudnn9.0-trt8.6 /bin/bash
4.2.1.2 执行
使用飞桨官方 Docker 镜像,创建一个名为 paddlepaddle 的容器,并将当前工作目录映射到容器内的 /paddle 目录
docker run --gpus all --name paddlepaddle -v $PWD:/paddle --shm-size=8G --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.0.0rc0-gpu-cuda11.8-cudnn8.6-trt8.5 /bin/bash
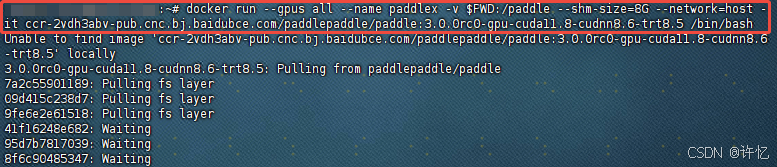
安装成功
若想暂时退出容器但保留其运行状态,使用 Ctrl + P 再按 Ctrl + Q 组合键;若要完全退出并停止容器,在容器内使用 exit 命令 。后续还可使用 docker start 命令重新启动已停止的容器。
4.2.2 Docker 版本 <= 19.03 但 >= 17.06
# 对于 cpu 用户:
docker run --name paddlex -v $PWD:/paddle --shm-size=8G --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.0.0rc0 /bin/bash# 对于 gpu 用户:
# CUDA11.8 用户
nvidia-docker run --name paddlex -v $PWD:/paddle --shm-size=8G --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.0.0rc0-gpu-cuda11.8-cudnn8.6-trt8.5 /bin/bash# CUDA12.3 用户
nvidia-docker run --name paddlex -v $PWD:/paddle --shm-size=8G --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.0.0rc0-gpu-cuda12.3-cudnn9.0-trt8.6 /bin/bash
4.3 基于Docker获取PaddleX
4.3.1 Docker 版本 >= 19.03
4.3.1.1各版本命令
# 对于 CPU 用户
docker run --name paddlex -v $PWD:/paddle --shm-size=8g --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0rc0-paddlepaddle3.0.0rc0-cpu /bin/bash# 对于 GPU 用户
# GPU 版本,需显卡驱动程序版本 ≥450.80.02(Linux)或 ≥452.39(Windows)
docker run --gpus all --name paddlex -v $PWD:/paddle --shm-size=8g --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0rc0-paddlepaddle3.0.0rc0-gpu-cuda11.8-cudnn8.6-trt8.5 /bin/bash# GPU 版本,需显卡驱动程序版本 ≥545.23.06(Linux)或 ≥545.84(Windows)
docker run --gpus all --name paddlex -v $PWD:/paddle --shm-size=8g --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0rc0-paddlepaddle3.0.0rc0-gpu-cuda12.3-cudnn9.0-trt8.6 /bin/bash
4.3.1.2 运行
使用 PaddleX 官方 Docker 镜像,创建一个名为 paddlex 的容器,并将当前工作目录映射到容器内的 /paddle 目录
docker run --gpus all --name paddlex -v $PWD:/paddle --shm-size=8g --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0rc0-paddlepaddle3.0.0rc0-gpu-cuda11.8-cudnn8.6-trt8.5 /bin/bash
- 安装成功
如需映射端口可使用
docker run --gpus all --name paddlex -v $PWD:/paddle --shm-size=8g --network=host -p 6666:6666 -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0rc0-paddlepaddle3.0.0rc0-gpu-cuda11.8-cudnn8.6-trt8.5 /bin/bash
- 进入容器
docker exec -it paddlex /bin/bash
这里的 -i 选项表示保持标准输入打开,-t 选项为终端分配一个伪终端,/bin/bash 是要在容器内执行的 shell 命令。
4.3.2 Docker 版本 <= 19.03 但 >= 17.06
# 对于 CPU 用户
docker run --name paddlex -v $PWD:/paddle --shm-size=8g --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0rc0-paddlepaddle3.0.0rc0-cpu /bin/bash# 对于 GPU 用户
# 对于 CUDA11.8 用户
nvidia-docker run --name paddlex -v $PWD:/paddle --shm-size=8g --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0rc0-paddlepaddle3.0.0rc0-gpu-cuda11.8-cudnn8.6-trt8.5 /bin/bash# 对于 CUDA12.3 用户
nvidia-docker run --name paddlex -v $PWD:/paddle --shm-size=8g --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0rc0-paddlepaddle3.0.0rc0-gpu-cuda12.3-cudnn9.0-trt8.6 /bin/bash
5.PaddleX 服务化部署(基于pip部署,基础服务化部署)
针对用户的不同需求,PaddleX 提供多种产线服务化部署方案:
- 基础服务化部署:简单易用的服务化部署方案,开发成本低。
- 高稳定性服务化部署:基于 NVIDIA Triton Inference Server 打造。与基础服务化部署相比,该方案提供更高的稳定性,并允许用户调整配置以优化性能。
注意:PaddleX 对产线而不是模块进行服务化部署。当前部署使用基础服务化部署。
5.1 官方部署文档
服务化部署:PaddleX 服务化部署指南
5.2 安装服务化部署插件
paddlex --install serving
5.3 与 服务化部署相关的命令行选项
| 名称 | 说明 |
|---|---|
| –pipeline | 产线名称或产线配置文件路径。 |
| –device | 产线部署设备。默认为 cpu(如 GPU 不可用)或 gpu(如 GPU 可用)。 |
| –host | 服务器绑定的主机名或 IP 地址。默认为 0.0.0.0。 |
| –port | 服务器监听的端口号。默认为 8080。 |
| –use_hpip | 如果指定,则启用高性能推理插件。 |
5.4 安装一条产线
测试运行,安装一条产线(通用图像分类产线:image_classification )
# 以图像分类产线为例,使用方式如下:
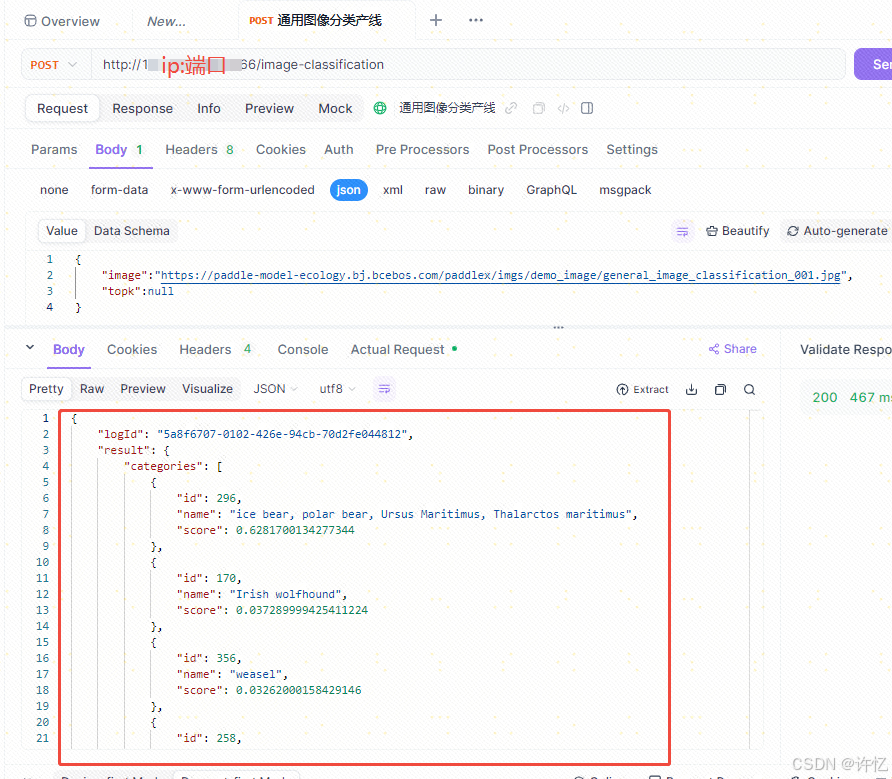
paddlex --pipeline image_classification \--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg \--device gpu:0 \--save_path ./output/ \--topk 5
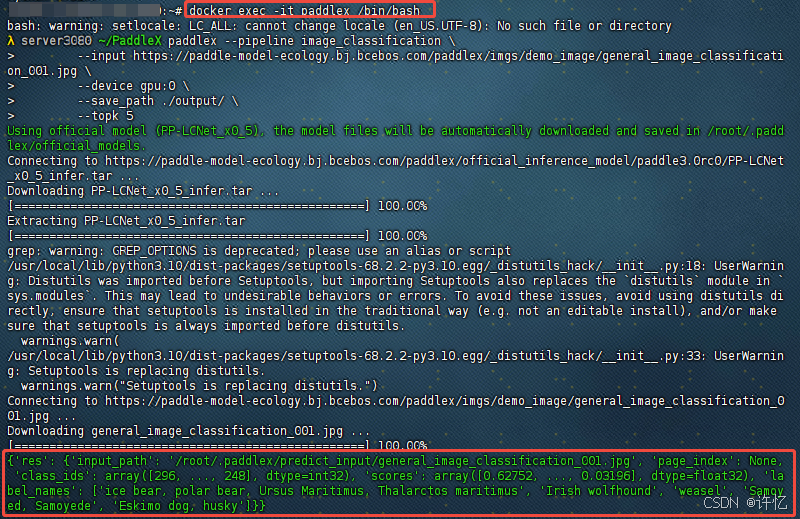
若想暂时退出容器但保留其运行状态,使用 Ctrl + P 再按 Ctrl + Q 组合键;若要完全退出并停止容器,在容器内使用 exit 命令 。后续还可使用 docker start 命令重新启动已停止的容器。
- 测试远程接口调用
判断服务器网络和端口 是否可访问
【注意】这里的端口是服务器暴露到外部访问的端口,通常需要做服务器端口和容器端口的映射,一般两者端口都保持一致,方便管理。如果出现端口冲突,可以修改,但最好做好记录。
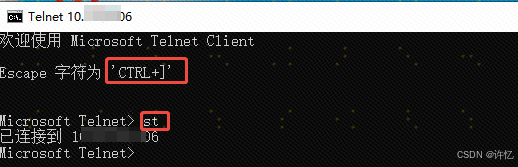
# Windows操作系统 telnet [服务器IP] [服务器端口]
telnet xxx.xxx.xx.xxx 6666
弹出黑色空白界面,按下CTRL + ] 键,即可进入如下页面,表示网络状态是连通的。