故城建设银行网站有了域名怎么建网站
一、什么是Transformer?
Transformer 是一种基于注意力机制(Attention Mechanism)的深度学习模型,最初由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。它彻底改变了自然语言处理(NLP)领域,并成为许多现代模型(如 BERT、GPT 等)的基础。
以下是对 Transformer 的详细解析,包括其架构、核心组件和工作原理。
1. Transformer 的架构
Transformer 是一个完全基于注意力机制的编码器-解码器架构,适用于序列到序列任务(如机器翻译)。其主要特点包括:
并行化训练:与 RNN 不同,Transformer 可以并行处理输入序列的所有位置。
自注意力机制(Self-Attention):捕捉输入序列中不同位置之间的关系。
位置编码(Positional Encoding):为模型引入序列的位置信息。
Input Sequence → [Embedding + Positional Encoding] → Encoder → Decoder → Output Sequence
2. 核心组件
2.1 输入表示
词嵌入(Word Embedding):
将输入序列中的每个词映射为固定维度的向量。
位置编码(Positional Encoding):
Transformer 没有显式的顺序信息,因此通过位置编码为每个词嵌入添加位置信息。
位置编码可以是固定的正弦函数或可学习的参数。
公式:
P E ( p o s , 2 i ) PE_{(pos,2i)} PE(pos,2i)= s i n ( p o s 1000 0 2 i / d ) sin(\frac{pos}{10000^{2i/d}}) sin(100002i/dpos) , P E ( p o s , 2 i + 1 ) PE_{(pos,2i+1)} PE(pos,2i+1)= c o s ( p o s 1000 0 2 i / d ) cos(\frac{pos}{10000^{2i/d}}) cos(100002i/dpos)
其中: p o s pos pos 是词在序列中的位置。 i i i 是维度索引。 d d d 是嵌入维度。
2.2 自注意力机制(Self-Attention)
自注意力机制允许模型关注输入序列中不同位置的相关性。
计算步骤
(1)线性变换:
对输入嵌入进行线性变换,生成查询(Query)、键(Key)和值(Value)矩阵:
Q Q Q= X X X W Q W_{Q} WQ, K K K= X X X W K W_{K} WK, V V V= X X X W V W_{V} WV,
其中 W Q W_{Q} WQ, W K W_{K} WK, W V W_{V} WV是可学习的权重矩阵。
(2)计算注意力分数:
使用点积计算注意力分数:
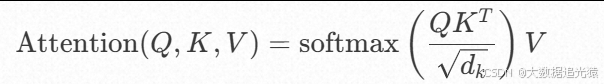 其中: d k d_{k} dk是 Key 向量的维度。
其中: d k d_{k} dk是 Key 向量的维度。
缩放因子, d k \sqrt{d_{k}} dk防止点积过大导致梯度消失。
(3)多头注意力(Multi-Head Attention):
将输入分成多个头(head),分别计算注意力,然后拼接结果。
公式:
M u l t i H e a d ( Q , K , V ) MultiHead(Q,K,V) MultiHead(Q,K,V)= C o n c a t ( h e a d 1 , . . . , h e a d h ) W o Concat(head_{1},...,head_{h})W_{o} Concat(head1,...,headh)Wo
其中, h e a d i head_{i} headi= A t t e n t i o n ( Q W Q i Attention(QW_{Qi} Attention(QWQi, K W K i KW_{Ki} KWKi, V W V i ) VW_{Vi}) VWVi), W o W_{o} Wo是输出权重矩阵。
2.3 前馈神经网络(Feed-Forward Network, FFN)
在每个注意力层之后,使用一个两层的前馈神经网络对特征进行非线性变换。
结构:
F F N ( x ) FFN(x) FFN(x)= m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 max(0,xW_{1}+b_{1})W_{2}+b_{2} max(0,xW1+b1)W2+b2
2.4 残差连接与层归一化
每个子层(如自注意力层、FFN 层)后都添加残差连接和层归一化:
L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x+Sublayer(x)) LayerNorm(x+Sublayer(x))
3. 编码器(Encoder)
编码器由多个相同的层堆叠而成,每层包含以下两个子层:
多头自注意力层:
计算输入序列的自注意力。
前馈神经网络层:
对注意力层的输出进行非线性变换。
4. 解码器(Decoder)
解码器也由多个相同的层堆叠而成,每层包含三个子层:
(1)掩码多头自注意力机制(Masked Multi-Head Self-Attention)
(2)编码器-解码器注意力机制(Encoder-Decoder Attention)
(3)前馈神经网络(Feed-Forward Network, FFN)
4.1 掩码多头自注意力机制
为了确保解码器在生成目标序列时只能看到当前位置及之前的单词,引入了掩码机制(Masking)。掩码会将未来位置的注意力分数置为负无穷,从而在 softmax 后变为零。
4.2 编码器-解码器注意力机制
这一层的作用是让解码器关注编码器的输出。查询矩阵来自解码器的上一层,而键和值矩阵来自编码器的输出。
5. 输出层
最终解码器的输出通过一个线性变换和 softmax 函数生成目标词汇的概率分布:
P ( y ) P(y) P(y)= s o f t m a x softmax softmax( W o z Woz Woz+ b o bo bo)
其中 z z z是解码器的输出, W o Wo Wo和 b o bo bo是可学习参数。
6. 训练与推理
(1)训练
使用交叉熵损失函数优化模型参数。
输入序列和目标序列同时提供,目标序列会右移一位作为解码器的输入。
(2)推理
使用贪心搜索或束搜索(Beam Search)生成目标序列。
7. 代码实现
以下是使用 PyTorch 实现的一个简化版 Transformer:
import torch
import torch.nn as nnclass TransformerModel(nn.Module):def __init__(self, input_dim, model_dim, num_heads, num_layers, output_dim):super(TransformerModel, self).__init__()self.embedding = nn.Embedding(input_dim, model_dim)self.positional_encoding = PositionalEncoding(model_dim)self.transformer = nn.Transformer(d_model=model_dim, nhead=num_heads, num_encoder_layers=num_layers,num_decoder_layers=num_layers)self.fc_out = nn.Linear(model_dim, output_dim)def forward(self, src, tgt):src = self.positional_encoding(self.embedding(src) * torch.sqrt(torch.tensor(self.embedding.embedding_dim)))tgt = self.positional_encoding(self.embedding(tgt) * torch.sqrt(torch.tensor(self.embedding.embedding_dim)))output = self.transformer(src, tgt)return self.fc_out(output)
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super(PositionalEncoding, self).__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0)) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)self.register_buffer('pe', pe.unsqueeze(0))def forward(self, x):return x + self.pe[:, :x.size(1)]
# 示例用法
input_dim = 1000 # 输入词汇表大小
model_dim = 512 # 模型维度
num_heads = 8 # 注意力头数
num_layers = 6 # 编码器/解码器层数
output_dim = 1000 # 输出词汇表大小
model = TransformerModel(input_dim, model_dim, num_heads, num_layers, output_dim)
src = torch.randint(0, input_dim, (10, 32)) # (序列长度, 批量大小)
tgt = torch.randint(0, input_dim, (20, 32)) # (序列长度, 批量大小)
output = model(src, tgt)
print(output.shape) # 输出形状: (目标序列长度, 批量大小, 输出维度)
二、 总结
Transformer 的核心思想是通过自注意力机制捕捉序列中不同位置的关系,并利用位置编码引入顺序信息。
它的优势在于:
- 并行化训练:相比 RNN 更高效。
- 长距离依赖建模:自注意力机制能够有效捕捉长距离依赖。
- 灵活性:可以应用于多种任务(如文本生成、分类、翻译等)。