南昌做网站开发的公司收录排名好的发帖网站
背景:
我有这样一个需要审核的飞书题目表,按日期分成多个sheet,有初审——复核——质检三个环节,这三个环节是不同的同学在作业,并且领到同一个题目的人选是随机的,也就是说,完成一道题的三个人之间完全是没有任何联系。
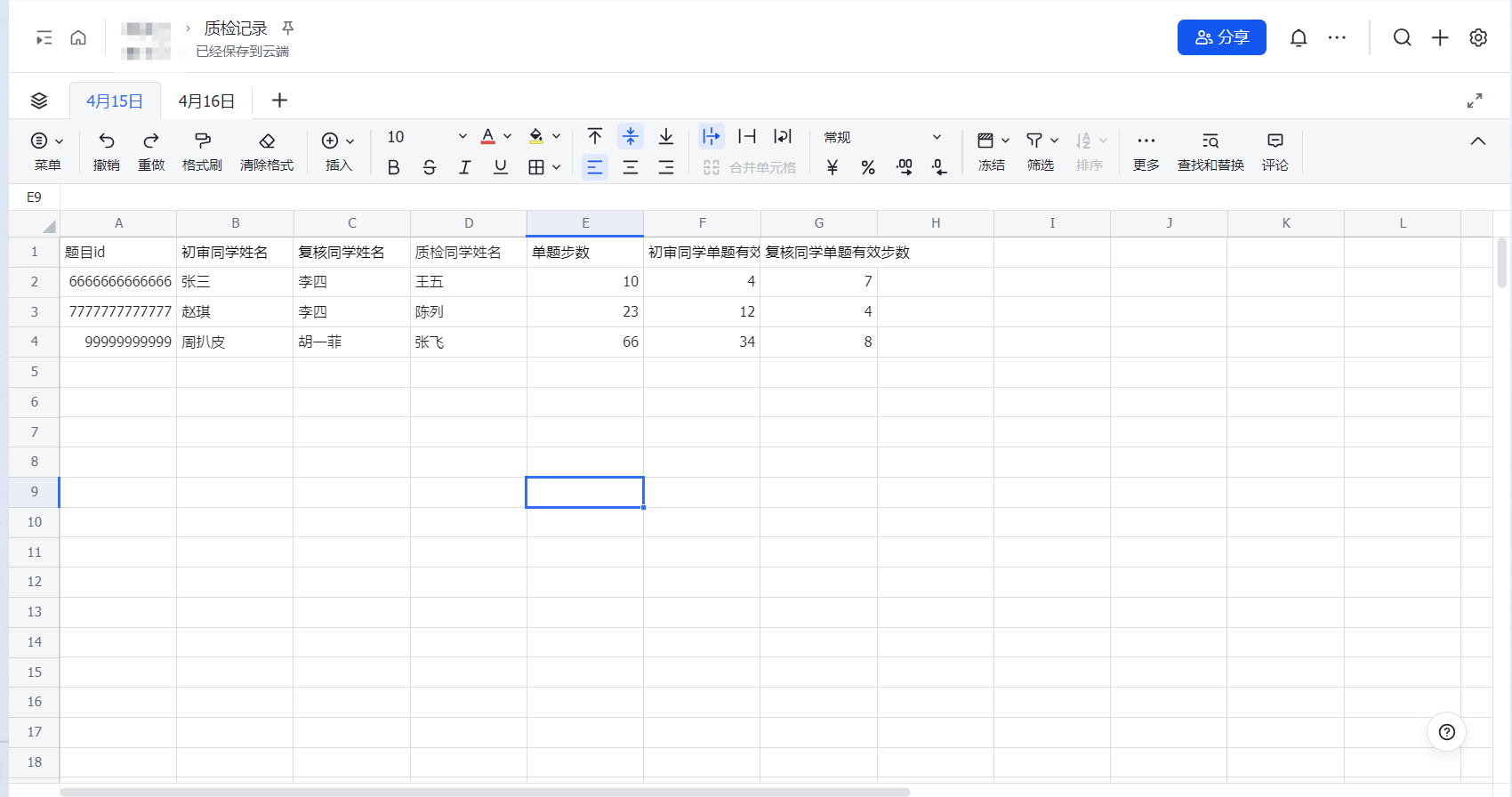
我现在需要指定sheet表的范围,统计一段时间内各环节的数据指标:
初审同学,需要统计每个同学的做题总步数,有效做题步数,还有合格率。
复核同学,需要统计每个同学的做题总步数,有效做题步数,还有合格率。
质检同学,需要统计每个质检同学的检查题目数量。一行就是一道题目,所以质检同学只需要看写着他名字的共有几行就可以。
其中,有效做题步数是指质检同学检查后判定为正确的步数,比如一道题共25步,如果质检认为初审同学做对15步,复核同学做对18步,那么初审有效步数 = 15,复核有效步数 = 18.
初审合格率 = 总初审有效步数 / 初审做题总步数;
复核合格率= 总复核有效步数 / 复核做题总步数;
编写代码:
理清上述逻辑之后,下面的工作直接交给GPT:
import pandas as pddef analyze_qc_records(file_path, sheet_names):initial_stats = {}relabel_stats = {}checker_counts = {}for sheet in sheet_names:df = pd.read_excel(file_path, sheet_name=sheet)for _, row in df.iterrows():# 初审init_name = row.get('初审同学姓名') # 取该行“初审同学姓名”,若是空值 (NaN) 则跳过。total_steps = row.get('单题步数', 0) or 0 # 当题目总步数(“单题步数”)缺失或为 NaN 时,设置为 0;否则读取数值。init_valid = row.get('初审同学单题有效步数', 0) or 0 # 读取该行“初审同学单题有效步数”if pd.notna(init_name):st = initial_stats.setdefault(init_name, {'总步数': 0, '有效步数': 0}) # 用 setdefault 保证 initial_stats[姓名] 一定存在,并初始化为 { '总步数':0, '有效步数':0 }st['总步数'] += total_steps # 每行累加“总步数”和“有效步数”st['有效步数'] += init_valid# 复核relabel_name = row.get('复核同学姓名')relabel_valid = row.get('复核同学单题有效步数', 0) or 0if pd.notna(relabel_name): # 如果不是缺失值st = relabel_stats.setdefault(relabel_name, {'总步数': 0, '有效步数': 0}) # 不管 relabel_name 之前在不在 relabel_stats 字典里,调用 setdefault 后,relabel_stats[relabel_name] 一定存在st['总步数'] += total_steps # 总步数依然用当行的 total_steps —— 即复核同学也「认定」原题的总步数与初审相同st['有效步数'] += relabel_valid# 质检checker = row.get('质检同学姓名')if pd.notna(checker): # 每遇到一行有“质检同学姓名”,就让对应姓名的计数 +1checker_counts[checker] = checker_counts.get(checker, 0) + 1# 构建 DataFrame(保留数值合格率)initial_df = pd.DataFrame([{'初审同学姓名': name,'总步数': stats['总步数'],'有效步数': stats['有效步数'],'合格率': stats['有效步数'] / stats['总步数'] if stats['总步数'] else 0} # 用“有效步数 ÷ 总步数” 得到一个 0–1 之间的小数;若总步数为 0 则直接赋 0,避免除零错误。for name, stats in initial_stats.items()])relabel_df = pd.DataFrame([{'复核同学姓名': name,'总步数': stats['总步数'],'有效步数': stats['有效步数'],'合格率': stats['有效步数'] / stats['总步数'] if stats['总步数'] else 0}for name, stats in relabel_stats.items()])checker_df = pd.DataFrame([{'质检同学姓名': name, '检查题目数': count}for name, count in checker_counts.items()])# 百分比格式化initial_df['合格率'] = initial_df['合格率'].map(lambda x: f"{x:.2%}")relabel_df['合格率'] = relabel_df['合格率'].map(lambda x: f"{x:.2%}")# 排序 初审/复核 按姓名字母序;质检按检查量从高到低。initial_df = initial_df.sort_values(by='初审同学姓名').reset_index(drop=True)relabel_df = relabel_df.sort_values(by='复核同学姓名').reset_index(drop=True)checker_df = checker_df.sort_values(by='检查题目数', ascending=False).reset_index(drop=True)return initial_df, relabel_df, checker_dfif __name__ == '__main__':# 示例:读取文件并指定 sheet 范围file_path = '目录/质检记录.xlsx'xls = pd.ExcelFile(file_path)# 假如想统计第 1 到第 3 张 sheet(索引从 0 开始)selected_sheets = xls.sheet_names[0:3]init_df, relabel_df, checker_df = analyze_qc_records(file_path, selected_sheets)# 打印结果print("初审同学统计:")print(init_df)print("\n复核同学统计:")print(relabel_df)print("\n质检同学统计:")print(checker_df)# 如需导出到 Excel:with pd.ExcelWriter('目录/质检统计结果.xlsx') as writer:init_df.to_excel(writer, sheet_name='初审统计', index=False)relabel_df.to_excel(writer, sheet_name='复核统计', index=False)checker_df.to_excel(writer, sheet_name='质检统计', index=False)print("统计已导出到 质检统计结果.xlsx")输出结果:
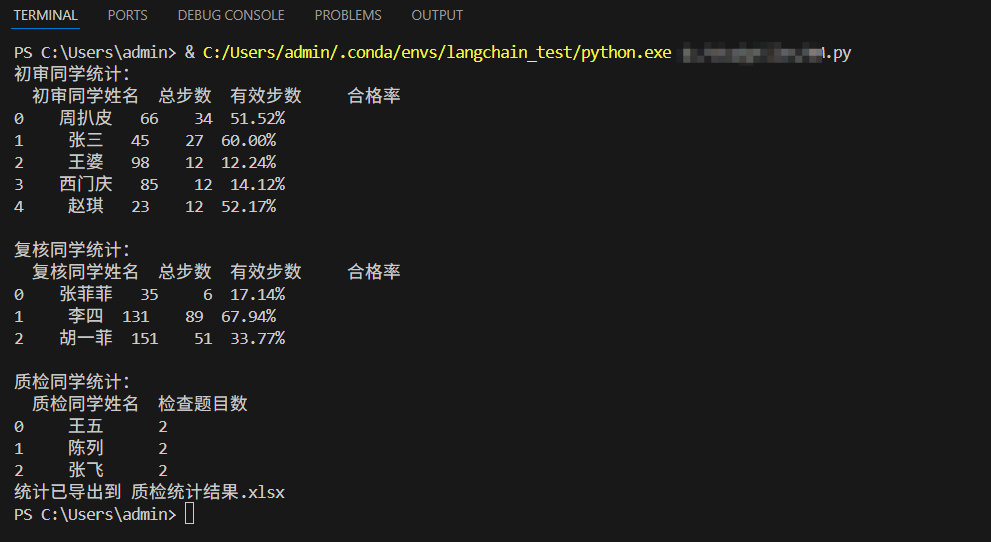
结果会直接写入XLSX文件保存。
并且初审/复核 按姓名字母序排列;质检按检查量从高到低排序。
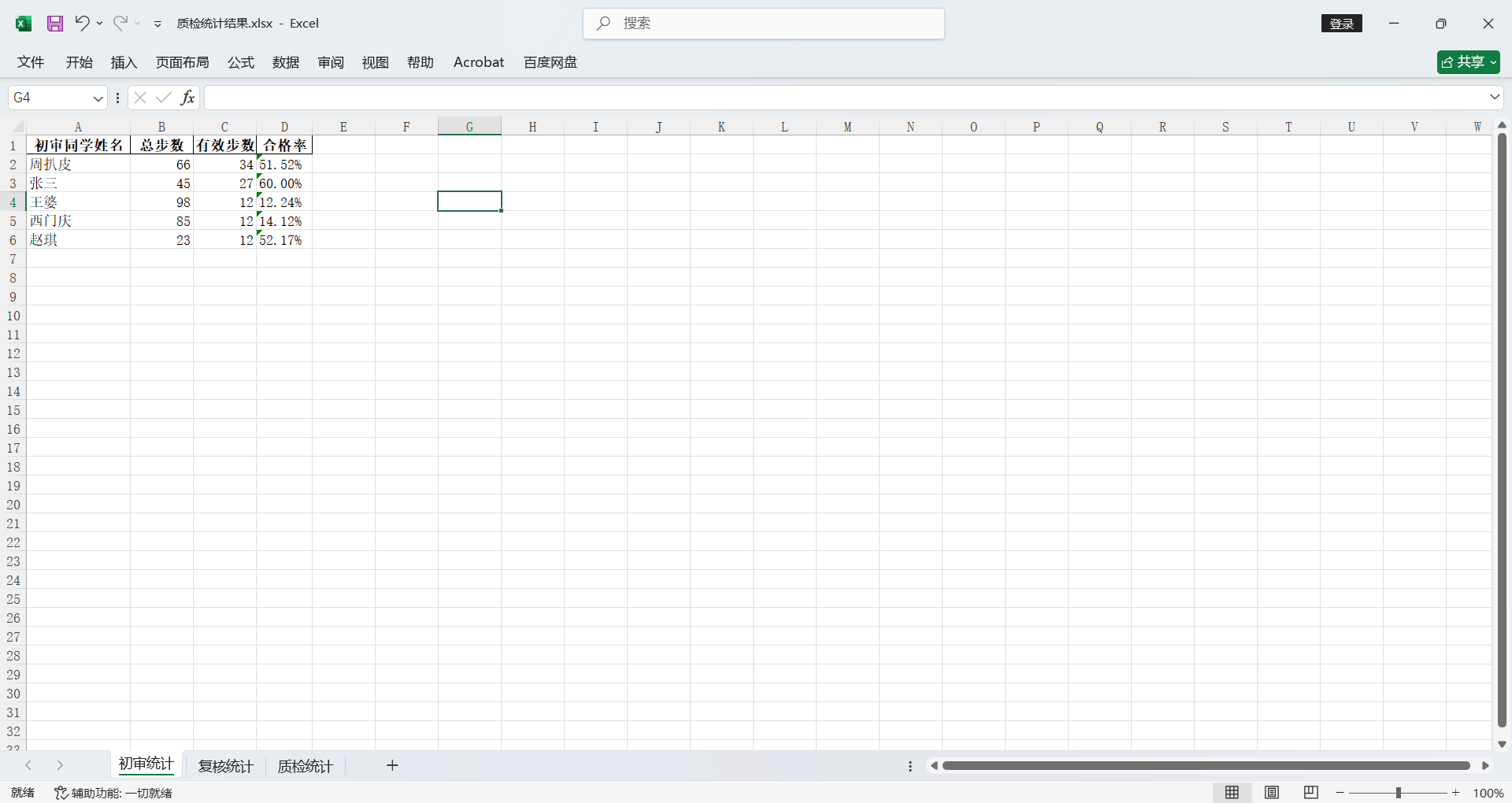
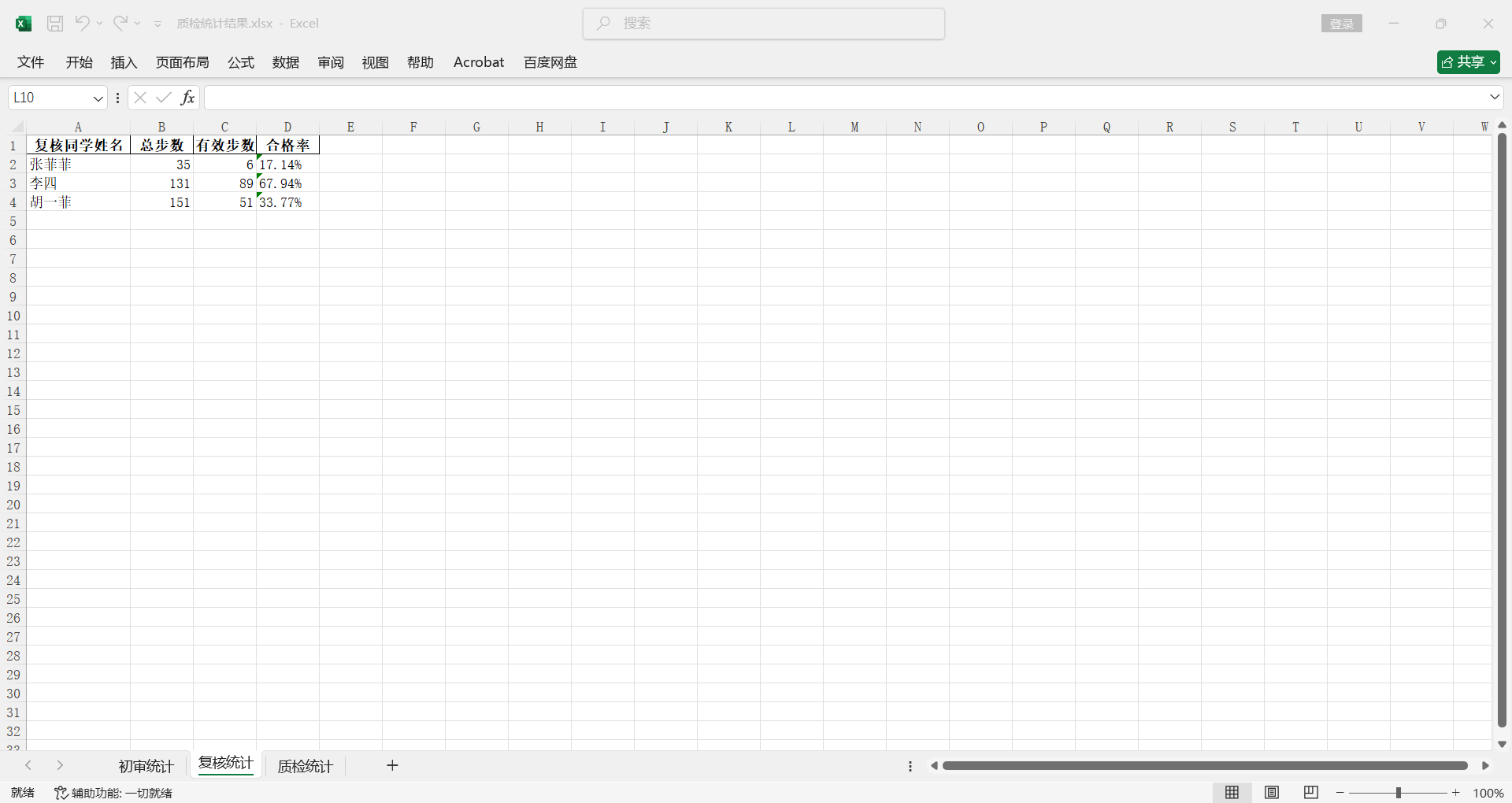
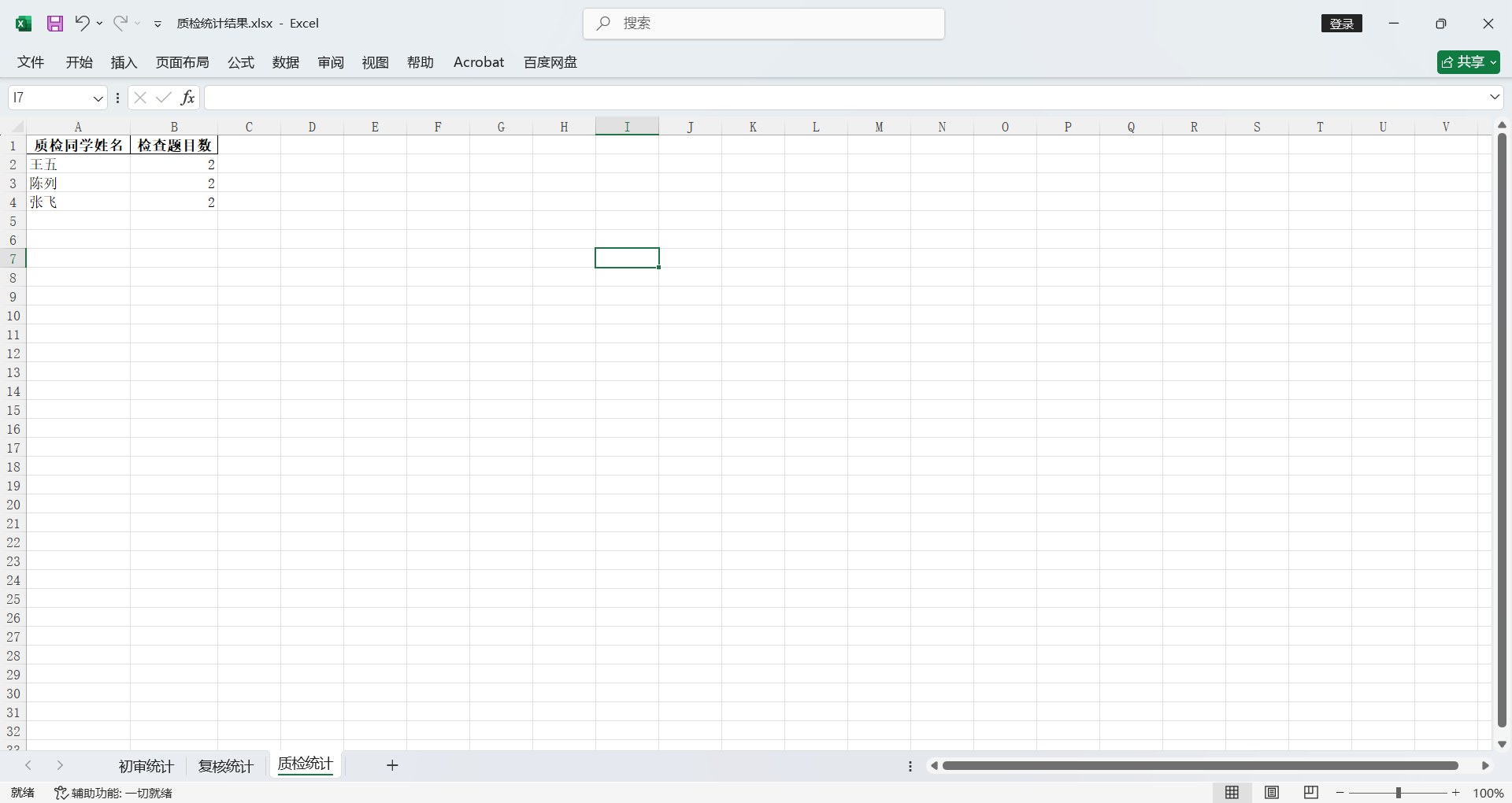
截至目前圆满实现了我的需求,完美!!
需要注意的点&容易困惑的代码片段:
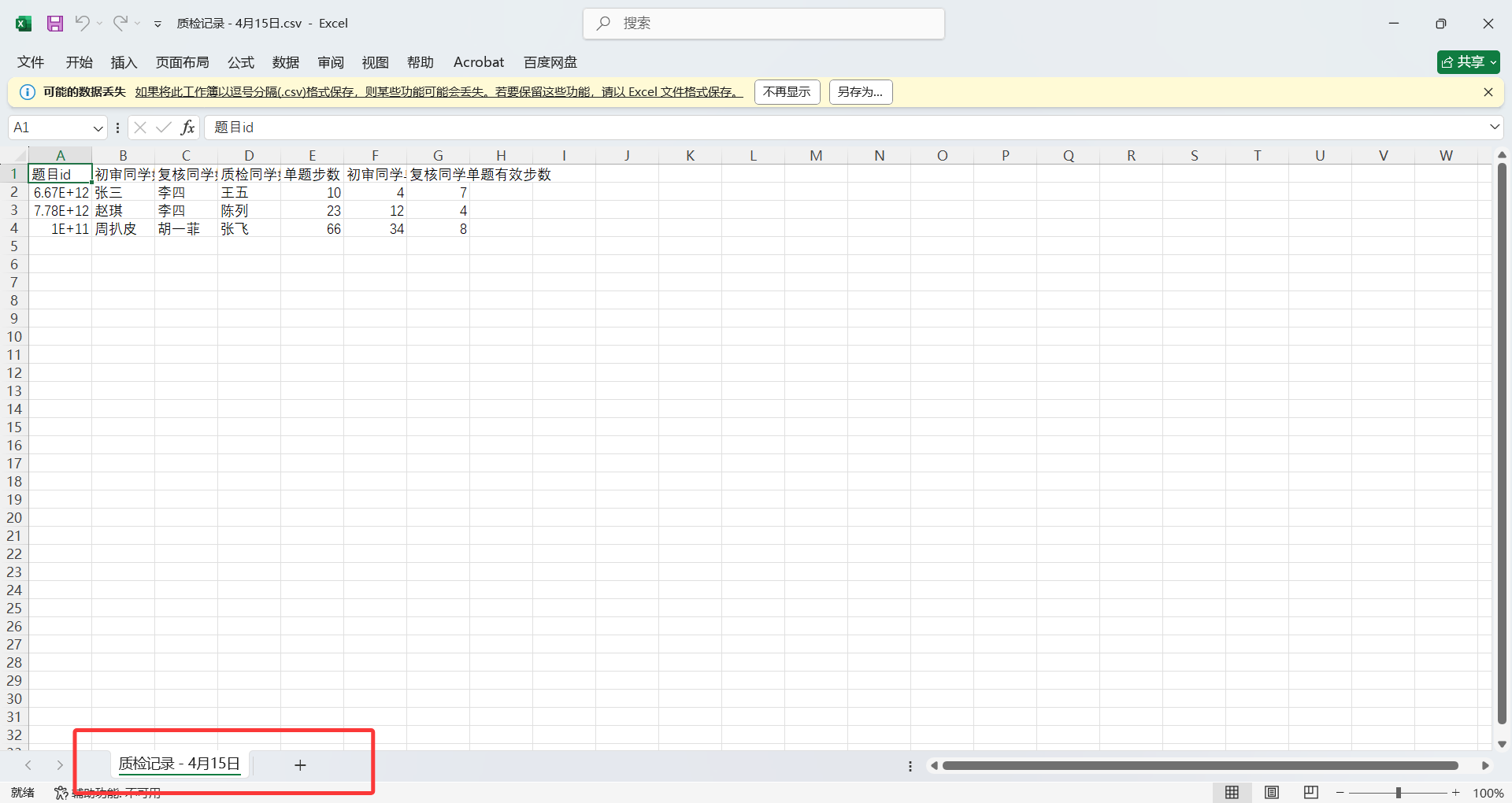
1.飞书必须导出为XLSX
因为CSV没有多个sheet,无法实现跨多张表统计。如果导出成了CSV,你会惊喜地发现只剩下第一张表,后面的数据全丢了。
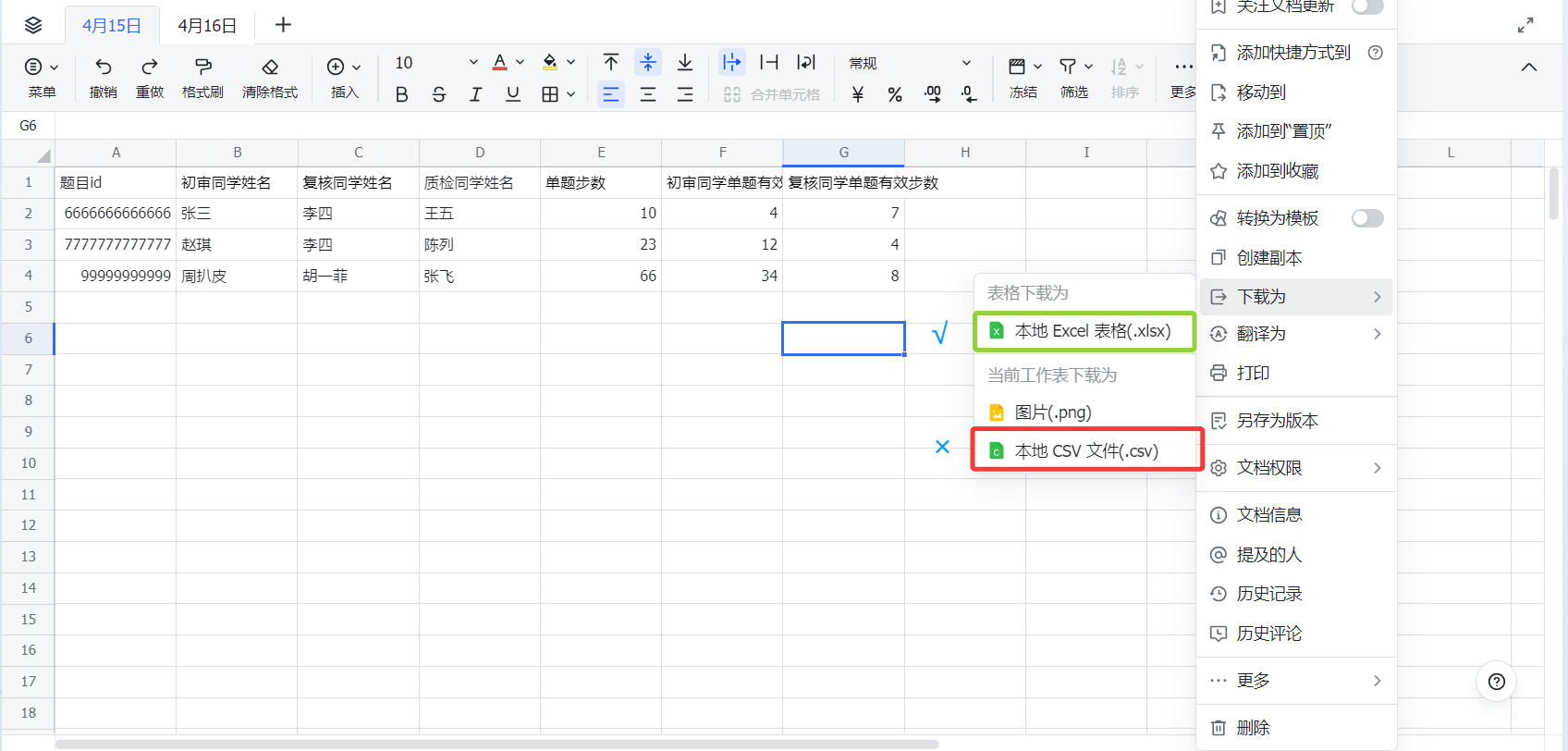
下载为CSV的后果…
2.if pd.notna(relabel_name),pd.notna是什么意思?
pd.notna(…) 的作用:
功能:判断一个值是否 不是 “缺失值”(NaN / None / NaT 等)。
返回:布尔值——如果传入的 relabel_name 既不是 NaN 也不是 None,则返回 True;否则返回 False。
为什么要用:在读取 Excel 时,空单元格会被 Pandas 识别为 NaN。只有当姓名字段确实有值时,才要执行后续的统计操作;如果是空的,就跳过这一行,避免在字典里注册一个空字符串或 NaN 作为键。
示例代码:
import pandas as pdprint(pd.notna("Alice")) # True,说明 "Alice" 是个有效字符串
print(pd.notna(None)) # False,说明 None 是缺失值
print(pd.notna(float('nan'))) # False,NaN 也是缺失值
这点确实很好用,有的同学填表容易漏项,没有把信息写全,留出一些空值在表里,会导致统计数据出现异常,非常的棘手。
3.dict.setdefault(key, default) 的用法?
所属类型:这是 Python 内置字典 (dict) 的一个方法。
功能:
如果字典中已经有了 key,就直接返回 dict[key];
如果没有 key,就先把 key: default 这对键值对插入字典,然后返回这个 default。
为什么要用:
这样写可以保证:不管 relabel_name 之前在不在 relabel_stats 字典里,调用 setdefault 后,relabel_stats[relabel_name] 一定存在,且是一个形如 {‘总步数’: 0, ‘有效步数’: 0} 的初始结构。
之后就可以安心地做 st[‘总步数’] += total_steps、st[‘有效步数’] += relabel_valid这样步数统计的操作,不用每次都写一大段 “如果 key 不在,就先赋值” 的逻辑。
示例代码:
d = {}
x = d.setdefault('张三', {'总步数': 0, '有效步数': 0})
# 这时 d == {'张三': {'总步数': 0, '有效步数': 0}}
# 变量 x 就是 {'总步数': 0, '有效步数': 0}# 再次调用
y = d.setdefault('张三', {'总步数': 100, '有效步数': 50})
# 因为 '张三' 已存在,d 不变,y 仍是原来的 {'总步数': 0, '有效步数': 0}print(d) # {'张三': {'总步数': 0, '有效步数': 0}}那么回到我们解决问题的代码:
结合第二点,这段代码的作用是:
先用 pd.notna 确保 relabel_name 真有值。
再用 setdefault 拿到或初始化统计结构,省去了手写“键不存在就先赋值”的繁琐。
最后在 st 上累加步数,就完成了该同学在“初审”或者”复核“环节的统计。
这样写既简洁又安全,不用担心 KeyError 或把空姓名也算进去。
4.for name, stats in initial_stats.items() ])这个stats是什么?
initial_stats 是你在前面遍历所有行时累积的一个字典,形如:
{"张三": {"总步数": 120, "有效步数": 110},"李四": {"总步数": 95, "有效步数": 90},...
}
initial_stats.items() 会返回一个由 (key, value) 对组成的可迭代对象,这里 key 就是每个同学的姓名,value 就是对应的那个小字典(包含 “总步数” 和 “有效步数” 两个字段)。
所以在列表推导里:
for name, stats in initial_stats.items()
name —— 对应同学姓名(例如 “张三”)
stats —— 对应该同学的那个子字典(例如 {“总步数”: 120, “有效步数”: 110})
接下来你就可以用 stats[‘总步数’]、stats[‘有效步数’] 来取出这两个值,计算合格率:
'合格率': stats['有效步数'] / stats['总步数'] if stats['总步数'] else 0
如果觉得 stats 这个名字不直观,也可以任意改成别的,比如 data、counts、vals,逻辑完全一样:它只是“每个同学对应的那份统计数据”的一个变量名。