安徽建设厅网站打不开安卓优化大师官方下载
阿华代码,不是逆风,就是我疯
你们的点赞收藏是我前进最大的动力!!
希望本文内容能够帮助到你!!

目录
文章导读
零:项目结果展示
一:项目背景
二:项目功能实现准备
1:实现思路
2:解决方案
3:获取网页文档
三:模块划分
1:索引模块
2:搜索模块
3:web模块
四:考虑点
1:搜索内容为一句话
2:只解析html文件
五:功能实现
1:枚举文件
2:解析文件
(1)解析 标题
(2) 解析URL
(3)解析正文
文章导读
阿华将发布项目复盘系列的文章,旨在:
1:手把手细致带大家从0到1做一个完整的项目,保证每2~3行代码都有详细的注解
2:通过文字+画图的方式,对项目进行整个复盘,更好的理解以及优化项目
3:总结自己的优缺点,扎实java相关技术栈,增强文档编写能力
零:项目结果展示
简述:在我的搜索引擎网站,用户进行关键字搜索,就可以查询到与这个关键字相关的java在线文档,(包含标题,关键字附近的简述,url),用户点击标题,即可跳转到相关在线文档,适用于JDK17版本。

一:项目背景
在使用java在线文档的时候,官方自带的搜索功能不是很好使,搜索出来的结果不是很详细、简练、易读
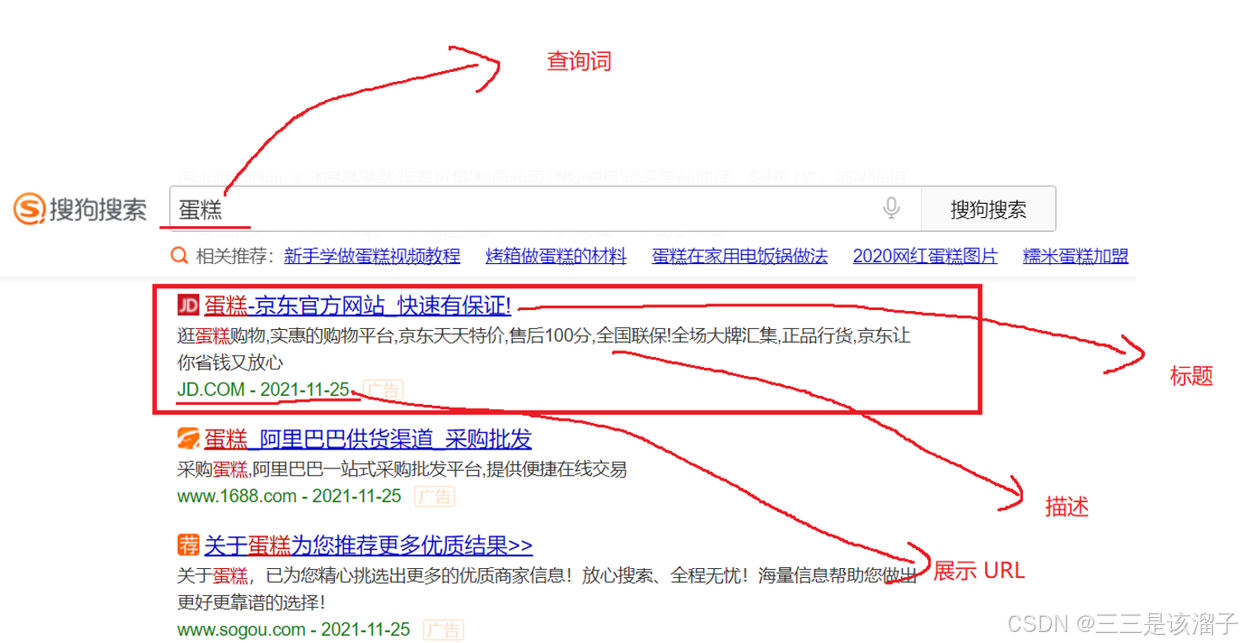
想做一款类似搜狗搜索这种界面的java在线文档搜索引擎 ,有查询框,标题,描述,url
二:项目功能实现准备
1:实现思路
对于搜索引擎来说,首先我们需要获取很多的网页,再根据查询词,在这些网页中查找匹配的。
问题①:网页怎么获取
问题②:查询词怎么跟网页匹配
2:解决方案
使用索引结构
①文档:充当每个待搜索的网页
②正排索引:文档id 对应 文档内容 1对1
③倒排索引 词 对应 文档id列表 1对多 (就是这个词在哪些文档中都出现过)
3:获取网页文档
这里我们通过下载jdk17官方文档压缩包,在本地基于离线文档来制作索引
下载网址如下
Java Development Kit 17 Documentation
三:模块划分
1:索引模块
(1)扫描下载的文档,分析文档的内容,构建正排和倒排索引,并且把索引内容保存到文件中
(2)加载正、倒排索引,提供API实现查正、倒排索引
2:搜索模块
调用索引模块,实现一个完整的搜索过程
(1)输入:用户查询词
(2)输出:完整搜索结果,如上项目结果展示(包含很多条记录,每条记录有标题,描述,URL的展示,点击进行页面跳转)
3:web模块
实现简单web程序,通过网页实现与用户进行交互
四:考虑点
1:搜索内容为一句话
考虑到查询词可能不是一个词,而是一句话,这个时候我们需要对这句话进行分词,还好不是分词中文(QWQ),比如:下雨/天天留我/不留~~~大家怎么分词的~!
这里我们使用一个库ansj
<dependency><groupId>org.ansj</groupId><artifactId>ansj_seg</artifactId><version>5.1.6</version></dependency>呈现结果是这样的嘿嘿~
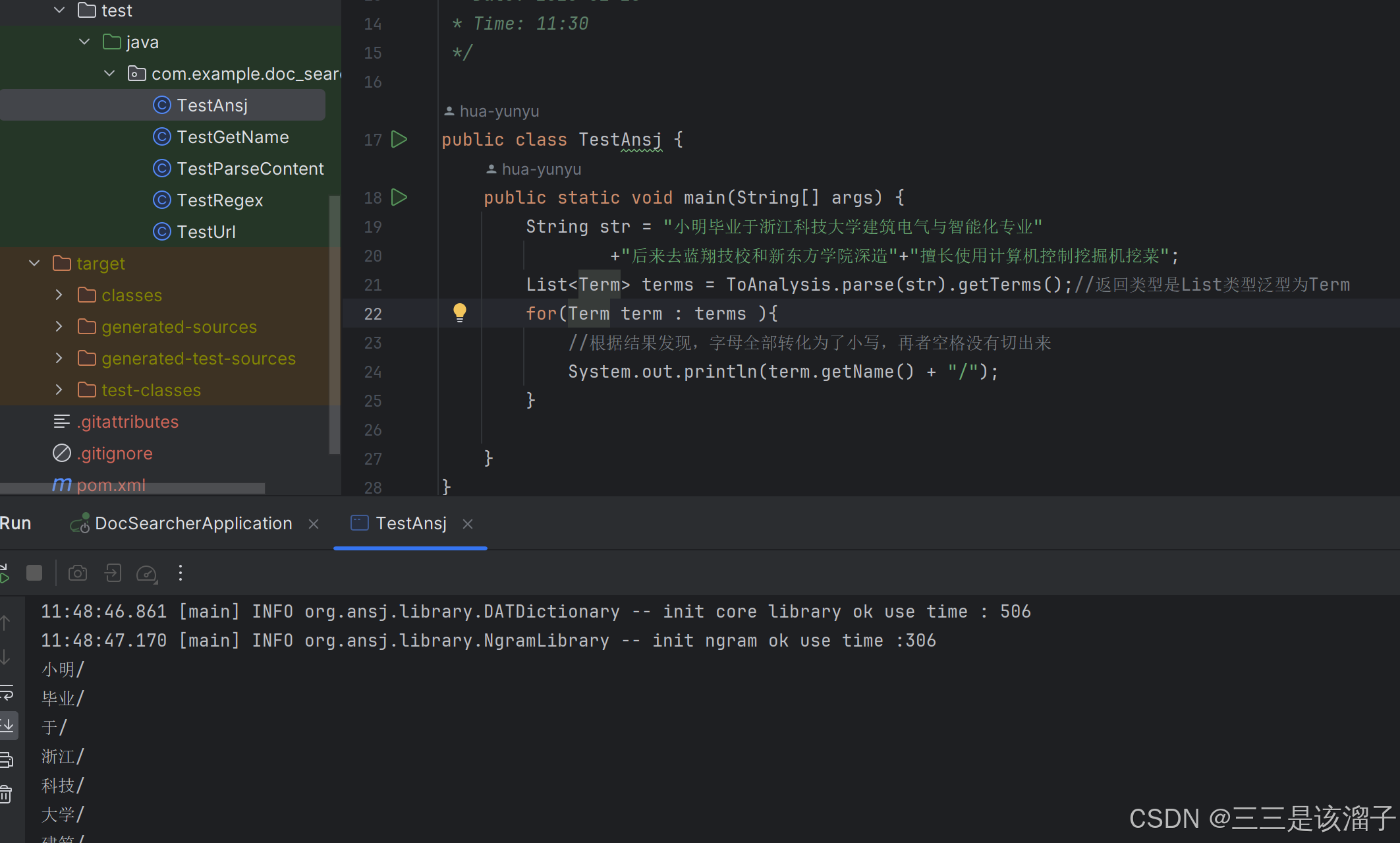
public class TestAnsj {public static void main(String[] args) {String str = "小明毕业于浙江科技大学建筑电气与智能化专业"+"后来去蓝翔技校和新东方学院深造"+"擅长使用计算机控制挖掘机挖菜";List<Term> terms = ToAnalysis.parse(str).getTerms();//返回类型是List类型泛型为Termfor(Term term : terms ){//根据结果发现,字母全部转化为了小写,再者空格没有切出来System.out.println(term.getName() + "/");}}
}2:只解析html文件
下载的离线文档中我们只需要解析HTMl文档就可以了,其它文档过滤掉
五:功能实现
1:枚举文件
逻辑思路:递归+过滤非html文件
public void enumFile(String inputPath, ArrayList<File> fileList) {File rootPath = new File(inputPath);//实例化一个该指定路径的目录,用来操作该目录下的文件//listFiles方法获取到该api目录中所有的(目录/文件)File[] files = rootPath.listFiles();for (File f : files) {
// System.out.println(f);//这些文件不全是我们需要的html文件,可能还是个文件夹,这里就直接递归进去if (f.isDirectory()) {enumFile(f.getAbsolutePath(), fileList);//是目录就递归,始终用List集合是同一个} else if (f.getAbsolutePath().endsWith(".html")) {fileList.add(f);//是html文件就把它添加进去//就排除掉了大概200个文件}}}2:解析文件
核心功能:实现解析标题,解析url,解析正文
其它代码是我的测试代码,用于代码时间优化
public void parseHTML(File f) {//1:TODO 解析出HTML的标题String title = parseTitle(f);//2:TODO 解析出HTML的URLlong beg = System.nanoTime();//纳秒计时String url = parseUrl(f);long mid = System.nanoTime();//3:TODO 解析出HTML对应的正文(有了正文才有后续的描述)
// String content = parseContent(f);String content = parseContentByRegex(f);long end = System.nanoTime();//用累加,sout的话本身也会耗时很多//4:把解析出来的信息加入到索引当中index.addDoc(title, url, content);t1.addAndGet(mid - beg);t2.addAndGet(end - mid);}(1)解析 标题
用的文件标题
private String parseTitle(File f) {String name = f.getName();return name.substring(0, name.length() - ".html".length());//左闭右开区间}(2) 解析URL
固定访问路径+本地的离线文档路径,项目上线后,修改一下本地离线路径即可
public String parseUrl(File f) {String part1 = "https://docs.oracle.com/en/java/javase/17/docs/api/";String part2 = f.getAbsolutePath().substring(INPUT_PATH.length());//长度作为起始下标,一直截取到末尾return part1 + part2;}(3)解析正文
这里我们实现的逻辑,搞一个拷贝开关<>里面的就不拷贝,只拷贝内容,如红括号,小伙伴们可以自己用记事本打开一个html文档进行查看
public String parseContent(File f) {//try (BufferedReader bufferedReader = new BufferedReader(new FileReader(f), 1024 * 1024)) {//缓冲区设置为1M,默认的为8192字节太小
// FileReader fileReader = new FileReader(f);//这里是从硬盘读,我们改成提前读好,之后从内存中读效率会更高//是否拷贝的开关boolean isCopy = true;//用StringBuilder来保存结果,StringBuilder content = new StringBuilder();while (true) {
// int ret = fileReader.read();//读取文件,一个字符一个字符的读,不是字符返回-1;int ret = bufferedReader.read();if (ret == -1) {break;//读完了}//是字符执行以下逻辑char c = (char) ret;if (isCopy) {if (c == '<') {isCopy = false;continue;}if (c == '\n' || c == '\r') {//换行的两种方式注意回车键c = ' ';//换成空格}content.append(c);//其它字符直接进行拷贝到StringBuilder中} else {//直到遇见'>'这个字符我们才打开拷贝的开关if (c == '>') {isCopy = true;}}}
// fileReader.close();return content.toString();} catch (IOException e) {e.printStackTrace();}return "";}