做招标网站 如何营销网站都有哪些
一、词向量技术背景
在自然语言处理(NLP)领域,如何有效地表示词语一直是核心问题。传统方法如one-hot编码虽然简单,但存在维度灾难和无法表达词语间相似性的问题。词向量(Word Embedding)技术的出现解决了这一难题。
词向量通过将词语映射到低维连续向量空间,使得语义相似的词语在向量空间中的位置也相近。这种分布式表示方法为NLP任务如文本分类、机器翻译等提供了强有力的基础。
二、CBOW模型原理
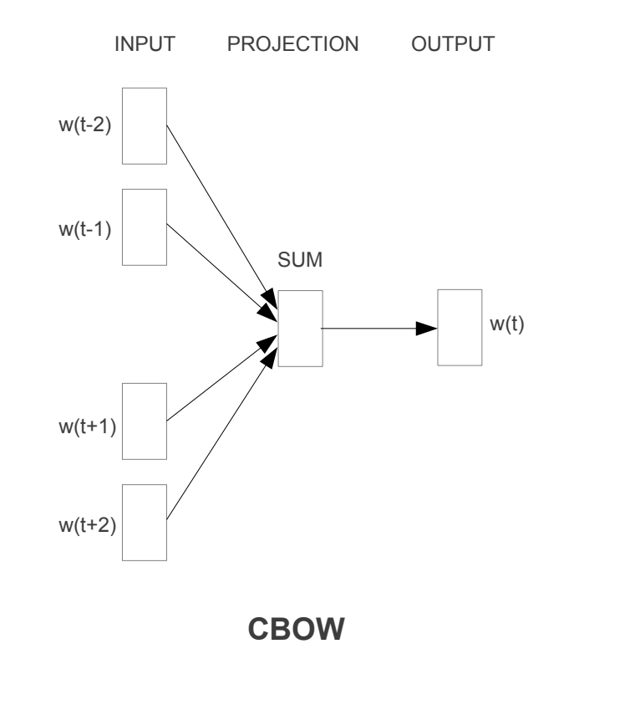
连续词袋模型(Continuous Bag-of-Words, CBOW)是一种经典的词向量训练模型,由Mikolov等人在2013年提出。其核心思想是通过上下文词语预测当前词语。
2.1 模型架构
CBOW模型包含三层结构:
1. 输入层:上下文词语的one-hot表示
2. 隐藏层:词嵌入层,学习词语的分布式表示
3. 输出层:预测目标词语的概率分布
class CBOW(nn.Module):def __init__(self, vocab_size, embedding_dim):super(CBOW, self).__init__()self.embeddings = nn.Embedding(vocab_size, embedding_dim)self.proj = nn.Linear(embedding_dim, 128)self.output = nn.Linear(128, vocab_size)
2.2 训练过程
1. 将上下文词语转换为one-hot向量
2. 通过嵌入层获取各词语的词向量
3. 对上下文词向量求平均或求和
4. 通过神经网络预测目标词语
5. 使用反向传播优化模型参数
def forward(self, input):embeds = sum(self.embeddings(input)).view(1,-1)out = F.relu(self.proj(embeds))out = self.output(out)nll_prob = F.log_softmax(out, dim=-1)return nll_prob
三、代码实现解析
3.1 数据准备
首先需要构建词汇表并将词语转换为索引:
vocab = set(raw_text)
word_to_idx = {word:i for i, word in enumerate(vocab)}
idx_to_word = {i: word for i, word in enumerate(vocab)}
3.2 构建训练数据
以窗口大小CONTEXT_SIZE=2为例,获取上下文-目标词对:
for i in range(CONTEXT_SIZE, len(raw_text) - CONTEXT_SIZE):context = ([raw_text[i-(2-j)] for j in range(CONTEXT_SIZE)]+ [raw_text[i + j + 1] for j in range(CONTEXT_SIZE)])target = raw_text[i]data.append((context, target))
3.3 模型训练
使用负对数似然损失函数和Adam优化器:
loss_function = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)for epoch in tqdm(range(200)):# 训练过程...loss.backward()optimizer.step()
四、词向量可视化与应用
训练完成后,可以从嵌入层提取词向量:
word_2_vec = {}
for word in word_to_idx.keys():word_2_vec[word] = w[word_to_idx[word],:]
这些词向量可以用于:
1. 计算词语相似度
2. 作为下游任务的输入特征
3. 词语聚类分析
五、总结与展望
CBOW模型通过预测目标词语学习词向量,具有训练速度快、对高频词效果好的特点。本文通过PyTorch实现了完整的CBOW模型,并展示了词向量的提取过程。
完整代码如下:
import torch
import torch.nn as nn#神经网络
import torch.nn.functional as F
import torch.optim as optim#
from IPython import embed
from tqdm import tqdm,trange#显示进度条
import numpy as np
#任务:已经有了语料库,1、构造训练数据集,(单词,词库,)#真实的单词模型,每一个单词的词性,你训练大量的输入文本,
CONTEXT_SIZE=2 #设置词左边和右边选择的个数(即上下文词汇个数)
raw_text ="""We are about to study the idea of a computational process.Computational processes are abstract beings that inhabit computers.As they evolve, processes manipulate other abstract things called data.The evolution of a process is directed by a pattern of rulescalled a program. People create programs to direct processes. In effectwe ,conjure the spirits of the computer with our spells.""".split()#语料库#中文的语句,你可以选择分词,也可以选择分字
vocab = set(raw_text)#集合。词库,里面内容独一无人
vocab_size = len(vocab)word_to_idx = {word:i for i, word in enumerate(vocab)}#for循环的复合写法,第1次循环,i得到的索引号,word 第1个年
idx_to_word = {i: word for i, word in enumerate(vocab)}data =[]#获取上下文词,将上下文词作为输入,目标词作为输出。构建训练数据集。
for i in range(CONTEXT_SIZE, len(raw_text) - CONTEXT_SIZE):#(2,60)context =([raw_text[i-(2-j)] for j in range(CONTEXT_SIZE)]+[raw_text[i + j+ 1 ]for j in range(CONTEXT_SIZE)]#获取上下文词(['we"'are"'to''study']))target = raw_text[i]#获取目标词'about'data.append((context,target))#将上下文词和目标词保存到data中[((['we"'are 'to''study'])'about')]
def make_context_vector(context,word_to_ix):#将上下文词转换为one-hotidxs =[word_to_idx[w] for w in context]return torch.tensor(idxs,dtype=torch.long)#print(make_context_vector(data[0][0],word_to_idx))class CBOW(nn.Module):def __init__(self,vocab_size,embedding_dim):super(CBOW,self).__init__()self.embeddings=nn.Embedding(vocab_size,embedding_dim)self.proj=nn.Linear(embedding_dim,128)self.output=nn.Linear(128,vocab_size)def forward(self,input):embeds = sum(self.embeddings(input)).view(1,-1)out = F.relu(self.proj(embeds))out=self.output(out)nll_prob =F.log_softmax(out,dim=-1)return nll_prob'''断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU。'''
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device") #字符串的格式化model =CBOW(vocab_size,10).to(device)optimizer=optim.Adam(model.parameters(),lr=0.001)losses=[]
loss_function=nn.NLLLoss()
model.train()
for epoch in tqdm(range(200)):total_loss=0for context,target in data:context_vector=make_context_vector(context,word_to_idx).to(device)target=torch.tensor([word_to_idx[target]]).to(device)train_predict=model(context_vector)loss=loss_function(train_predict,target)optimizer.zero_grad()loss.backward()optimizer.step()total_loss+=loss.item()losses.append(total_loss)print(losses)context=['People','create','to','direct']
context_vector=make_context_vector(context,word_to_idx).to(device)model.eval()
predict=model(context_vector)
max_idx=predict.argmax(1)
# 获取词向量,这个Embedding就是我们需要的词向量,他只是一个型的一个中间过程print('CBOW embedding weight=',model.embeddings.weight)
w=model.embeddings.weight.cpu().detach().numpy()print(w)word_2_vec={}
for word in word_to_idx.keys():# 词向量矩阵中某个词的索引所对应的那一列即为所该词的词向量word_2_vec[word]=w[word_to_idx[word],:]
print('jieshu')
# torch.save()np.savez('word2vec实现.npz', file_1=w)
data=np.load('word2vec实现.npz')
print(data.files)